ICML2021论文笔记《Self-supervised Graph-level Representation Learning with Local and Global Structure》
ICML2021论文笔记《Self-supervised Graph-level Representation Learning with Local and Global Structure》
摘要
本文研究了无监督/自监督的全图表示学习,这在药物和材料发现中的分子性质预测等许多任务中都是至关重要的。现有的方法主要集中在保留不同图实例之间的局部相似性结构,但没有发现整个数据集的全局语义结构。在本文中,我们提出了一个统一的框架,称为局部实例和全局语义学习(GraphLoG),用于自监督的全图表示学习。具体来说,除了保留局部相似性外,GraphLoG还引入了分层原型来捕获全局语义集群。进一步开发了一种有效的 online expectation-maximization(EM)算法来学习该模型。我们评估GraphLoG时是对大量未标记图进行预训练,然后对下游任务进行微调。在化学和生物基准数据集上进行的大量实验证明了所提方法的有效性。
2. Problem Definition and Preliminaries
2.1. Problem Definition

一个理想的表示应该保留各种数据实例之间的局部结构。更具体地说,我们对其定义如下:
- Definition 1 (Local-instance Structure):
局部结构的目的是在从高维输入空间映射到低维潜在空间后,保持不同实例之间的成对相似性。对于一对相似的图/子图, G \mathscr{G} G 和 G ′ \mathscr{G}' G′,它们的嵌入预计会be nearby in the latent space,如图1(a)所示。而不同的对应该被映射到很远的距离。
仅追求 local-instance 结构通常不足以捕获整个数据集底层的语义。因此,发现数据的全局语义结构是很重要的,其具体定义如下:
-
Definition 2 (Global-semantic Structure):
真实世界的数据集通常可以组织为各种语义集群,特别是以分层方式。在映射到潜在空间后,一组图的嵌入有望形成一些反映原始数据聚类模式的全局结构。图示如图1(b)所示。 -
Problem Definition.
自监督图表示学习问题考虑了一组未标记的图 G = { G 1 , G 2 , ⋅ ⋅ ⋅ , G M } G=\{\mathscr{G}_1,\mathscr{G}_2,···,\mathscr{G}_M\} G={G1,G2,⋅⋅⋅,GM},我们的目标是在数据本身的指导下,为每个图 G M ∈ G \mathscr{G}_M∈G GM∈G学习一个低维向量 h G M ∈ R δ h_{\mathscr{G}_M}∈\mathbb{R}^δ hGM∈Rδ。具体来说,我们期望图嵌入 H = { h G 1 、 h G 2 、 ⋅ ⋅ ⋅ 、 h G M } H=\{h_{\mathscr{G}_1}、h_{\mathscr{G}_2}、···、h_{\mathscr{G}_M}\} H={hG1、hG2、⋅⋅⋅、hGM}同时遵循局部实例和全局语义结构。
2.2. Preliminaries
- Graph Neural Networks (GNNs).
一个典型的图可以表示为 G = ( V 、 ε 、 X V 、 X ε ) G=(V、\varepsilon、X_V、X_\varepsilon) G=(V、ε、XV、Xε),其中 V V V是点集, ε \varepsilon ε表示边集, X V = { X v ∣ v ∈ V } X_V=\{X_v|v∈V\} XV={Xv∣v∈V}表示所有节点的属性, X ε = { X u v ∣ ( u , v ) ∈ ε } X_\varepsilon=\{X_{uv}|(u,v)∈\varepsilon\} Xε={Xuv∣(u,v)∈ε}表示边属性。GNN的目的是学习每个节点 v ∈ V v∈V v∈V的嵌入向量 h v ∈ R δ h_v∈\mathbb{R}^δ hv∈Rδ,以及整个图 G \mathscr{G} G的向量 h G ∈ R δ h_\mathscr{G}∈\mathbb{R}^δ hG∈Rδ。对于 L L L层GNN,执行邻域聚合方案来捕获每个节点周围的 L L L跳信息。一个GNN的第 l l l层可以形式化如下:
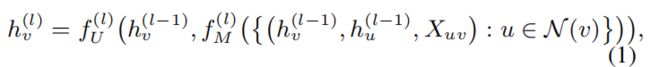
其中 N ( v ) N(v) N(v)为 v v v的相邻节点集, h v ( l ) h^{(l)}_v hv(l)表示第 l l l层节点 v v v的representation, h v ( 0 ) h^{(0)}_v hv(0)初始化为节点属性 X v X_v Xv, f M ( l ) f^{(l)}_M fM(l)和 f U ( l ) f^{(l)}_U fU(l)分别代表第 l l l层的消息传递和更新函数。由于 h v h_v hv总结了以节点 v v v为中心的子图的信息,因此我们将 h v h_v hv称为子图嵌入来强调这一点。整个图的嵌入情况可以如下所示:

其中, f R f_R fR是一个permutation-invariant readout函数,例如,平均池化或更复杂的图级池化函数。 - General EM Algorithm.
EM算法的基本目标是为一个包含潜在变量的模型找到最大似然解。在这种问题中,我们将所有观测数据的集合表示为 X X X,将所有潜在变量的集合表示为 Z Z Z,将所有模型参数的集合表示为 θ θ θ。
在 E E E步中,利用数据 X X X和最后一个 E M EM EM周期估计的模型参数 θ t − 1 θ_{t−1} θt−1,推导出潜在变量的后验分布为 p ( Z ∣ X , θ t − 1 ) p(Z|X,θ_{t−1}) p(Z∣X,θt−1),这也可以被认为是用一组特定的潜在变量来解释观察结果。
在 M M M步中,采用 E E E步给出的后验分布,对一般模型参数 θ θ θ的 complete-data log-likelihood 求期望,记为 Q ( θ ) Q(θ) Q(θ),计算如下:

模型参数被更新,以最大化这个期望,它输出:

E M EM EM的每个周期都可以增加当前模型所期望的 complete-data likelihood,并且考虑到整个进展, E M EM EM算法已被证明能够最大化边际似然函数 p ( X ∣ θ ) p(X|θ) p(X∣θ)
3. GraphLoG: Self-supervised Graph-level Representation Learning with Local and Global Structure
本节将介绍被称为 Local-instance and Global-semantic Learning(GraphLoG)的自监督图表示学习方法。GraphLoG的主要目的是发现和提炼潜在空间中图嵌入的局部和全局结构,这样我们就可以学习有用的图表示来做下游任务。具体来说,GraphLoG通过对齐相关图/子图的嵌入来构造一个局部平滑的潜在空间。在此基础上,利用hierarchical prototypes对图嵌入的全局结构进行建模,并通过online E M EM EM算法使数据似然值最大化。接下来,我们将详细阐明GraphLoG框架。
3.1. Learning Local-instance Structure of Graph Representations
根据现有的降维方法,局部结构学习的目标是在映射到低维潜在空间之前和之后保持数据的局部相似性。具体来说,我们期望相似的图或子图彼此紧密地嵌入,而不同的图被映射到很远的距离。利用在潜在空间中定义的相似度度量,我们将这个问题表述为最大化相关图/子图对的相似性,同时最小化负图对的相似性。
具体来说,给定从数据分布 P G P_\mathscr{G} PG中采样的图 G = ( V 、 ε 、 X V 、 X ε ) \mathscr{G}=(V、\varepsilon、X_V、X_\varepsilon) G=(V、ε、XV、Xε),通过随机屏蔽图中的部分节点/边缘属性,得到其相关对应的图 G ′ = ( V ′ 、 ε ′ 、 X V ′ 、 X ε ′ ) \mathscr{G}'=(V'、\varepsilon'、X_{V'}、X_{\varepsilon'}) G′=(V′、ε′、XV′、Xε′)。另外,对于图 G \mathscr{G} G中由节点 v v v及其 L − h o p L-hop L−hop邻域组成的子图 G v \mathscr{G}_v Gv,我们将图 G ′ \mathscr{G}' G′中对应的子图 G v ′ \mathscr{G}'_v Gv′视为其相关的对应物。通过在图 G \mathscr{G} G和 G ′ \mathscr{G}' G′上应用 L L L层GNN模型 G N N θ GNN_θ GNNθ( θ θ θ代表GNN的参数),推导出图和子图的嵌入如下:

其中, h V = { h G v ∣ v ∈ V } h_V=\{h_{\mathscr{G}_v}|v∈V\} hV={hGv∣v∈V}和 h V ′ = { h G v ′ ∣ v ∈ V ′ } h_{V'}=\{h_{\mathscr{G}'_v}|v∈V'\} hV′={hGv′∣v∈V′}分别表示图 G \mathscr{G} G和图 G ′ \mathscr{G}' G′中的子图嵌入集。
在这个阶段,学习的目的是增强相关图/子图对的相似性,同时减少负图对的相似性。使用一个特定的相似度度量(例如余弦相似度 s ( x , y ) = x T y / ∣ ∣ x ∣ ∣ ∣ ∣ y ∣ ∣ ) s(x,y)=x^Ty/||x||||y||) s(x,y)=xTy/∣∣x∣∣∣∣y∣∣),我们寻求优化以下两个目标函数分别为了图和子图:

其中, p n ( G , G ′ ) p_n(\mathscr{G},\mathscr{G}') pn(G,G′) 和 p n ( G v , G v ′ ) p_n(\mathscr{G}_v,\mathscr{G}'_v) pn(Gv,Gv′)表示对 negative pairs 进行采样的噪声分布。在实际应用中,对于相关图对 ( G , G ′ ) (\mathscr{G},\mathscr{G}') (G,G′)或相关子图对 ( G v , G v ′ ) (\mathscr{G}_v,\mathscr{G}'_v) (Gv,Gv′),我们用数据集中的另一个图(以同一图中的另一个节点为中心的子图)随机替换 G ( G v ) \mathscr{G}(\mathscr{G}_v) G(Gv)来构造 negative pairs。
为了学习图表示的局部实例结构,我们的目标是最小化这两个目标函数(公式6和7)。关于GNN的参数:
3.2. Learning Global-semantic Structure of Graph Representations
值得注意的是,数据集中的图可能具有层次化的语义信息。例如,在解剖治疗化学(ATC)分类系统中,药物(即分子图)由五个层次表示(Chenetal.,2012b)。在映射到潜在空间后,数据集中所有图的嵌入也有望形成一些与原始数据的层次语义结构相对应的全局结构。
然而,由于在自监督的图表示学习中缺乏显式的语义标签,这种全局结构无法通过标签诱导的监督来获得。为了解决这一限制,我们引入了一组额外的模型参数,即分层原型,以分层的方式表示潜在空间中的特征簇。它们被正式定义为 C = { c i l } i = 1 M l ( l = 1 , 2 , . . . , L p ) C=\{c^l_i\}^{M_l}_{i=1}(l=1,2,...,L_p) C={cil}i=1Ml(l=1,2,...,Lp),其中 c i l ∈ R δ c^l_i∈\mathbb{R}^δ cil∈Rδ代表第 l l l层的第 i i i个prototype, L p L_p Lp是hierarchical prototypes的深度, M l M_l Ml表示第 l l l层原型的数量。这些原型被构造为一组树(图1(b)),其中每个节点对应一个原型,除了叶节点外,每个原型都拥有一组子节点,表示为 C ( c i l ) ( 1 ≤ i ≤ M l , l = 1 , 2 , . . . , L p − 1 ) \mathbb{C}(c^l_i)(1\leq i\leq M_l,l=1,2,...,L_p−1) C(cil)(1≤i≤Ml,l=1,2,...,Lp−1)。
全局语义学习的目标是鼓励图形紧凑地嵌入到相应的原型中,同时,细化层次原型以更好地表示数据。我们将这个问题形式化为优化一个潜在变量模型。观测数据集 G = { G 1 、 G 2 、 ⋅ ⋅ ⋅ 、 G M } G=\{\mathscr{G}_1、\mathscr{G}_2、···、\mathscr{G}_M\} G={G1、G2、⋅⋅⋅、GM},我们考虑一个潜在变量集,即所有图 Z = { z G 1 , z G 2 , ⋅ ⋅ ⋅ , z G M } Z=\{z_{\mathscr{G}_1},z_{\mathscr{G}_2},···,z_{\mathscr{G}_M}\} Z={zG1,zG2,⋅⋅⋅,zGM}( z G m z_{\mathscr{G}_m} zGm是一组最能代表潜在空间中 G m \mathscr{G}_m Gm的原型)。本问题中的模型参数为GNN参数 θ θ θ和层次原型 C C C。由于没有给出每个图对应的潜在变量,因此很难直接最大化全数据似然函数 p ( G , Z ∣ θ , C ) p(G,Z|θ,C) p(G,Z∣θ,C)。因此,我们寻求通过EM算法来最大化 complete-data likelihood 的期望。
普通的EM算法(Dempsteter等人,1977;Krishnan等人,1997)需要在每次参数更新之前完全 through the data set,当数据集的大小像我们的例子一样大时,计算效率很低的。因此,我们考虑一个online EM变体(Sato & Ishii, 2000; Capp´e& Moulines, 2009; Liang & Klein, 2009),它对小批量的数据进行操作。这种方法是基于数据集服从独立同分布的假设,其中,潜在变量的 complete-data likelihood 和后验概率都可以对每个观测到的潜在变量对进行分解:

首先,我们介绍了模型参数的初始化方案。
Initialization of model parameters.
在触发全局结构探索之前,我们首先通过最小化 L l o c a l L_{local} Llocal对GNN进行预训练,并使用导出的GNN模型作为初始化,建立一个局部光滑的潜在空间。然后,我们利用这个预先训练好的GNN模型来提取数据集中所有图的嵌入,并对这些图嵌入应用K-means聚类,初始化底层原型(即 { c i L p } i = 1 M L p \{c^{L_p}_i\}^{M_{L_p}}_{i=1} {ciLp}i=1MLp)。通过迭代地应用K-means聚类来初始化上层的原型。对于每一次聚类,我们丢弃分配给小于两个样本的输出聚类中心,以避免简单的解决方案。
接下来,我们陈述了在我们的方法中应用的E步和M步的细节。
E-step.
在这一步中,我们首先从数据集 G G G中随机抽取一个小批量图 G ~ = { G 1 , G 2 , . . . , G N } \widetilde{G}=\{\mathscr{G}_1,\mathscr{G}_2,...,\mathscr{G}_N\} G ={G1,G2,...,GN}( N N N表示批大小), Z ~ = { z G n } n = 1 N \widetilde{Z}=\{z_{\mathscr{G}_n}\}^N_{n=1} Z ={zGn}n=1N代表这些采样图对应的潜在变量。每个潜在变量 z G n = { z G n 1 , z G n 2 , . . . , z G n L p } z_{\mathscr{G}_n}=\{z^1_{\mathscr{G}_n},z^2_{\mathscr{G}_n},...,z^{L_p}_{\mathscr{G}_n}\} zGn={zGn1,zGn2,...,zGnLp}都是一条从顶层到底层的原型链,它们最好地表示潜在空间中的图 G n \mathscr{G}_n Gn, z G n l + 1 z^{l+1}_{\mathscr{G}_n} zGnl+1是 z G n l z^{l}_{\mathscr{G}_n} zGnl在相应的树结构中的子节点,即, z G n l + 1 ∈ C ( z G n l ) ( l = 1 , 2 , . . . , L p − 1 ) z^{l+1}_{\mathscr{G}_n}∈ \mathbb{C}(z^{l}_{\mathscr{G}_n}) (l = 1, 2,..., L_p − 1) zGnl+1∈C(zGnl)(l=1,2,...,Lp−1)。由于独立同分布的假设, Z ~ \widetilde{Z} Z 的后验分布可以用分解的方式求得:

其中, θ t − 1 θ_{t−1} θt−1和 C t − 1 C_{t−1} Ct−1是最后一个EM周期的模型参数。直接计算每个后验分布 p ( z G n ∣ G n , θ t − 1 , C t − 1 ) p(z_{\mathscr{G}_n}|\mathscr{G}_n,θ_{t−1},C_{t−1}) p(zGn∣Gn,θt−1,Ct−1)是不重要的,这需要在分层原型中遍历所有可能的链。相反,我们采用随机EM算法的思想(Celeux&Govaert,1992;Nielsen et al., 2000),并绘制一个样本 z ^ G n ∼ p ( z G n ∣ G n , θ t − 1 , C t − 1 ) \hat{z}_{\mathscr{G}_n}∼p(z_{\mathscr{G}_n}|\mathscr{G}_n,θ_{t−1},C_{t−1}) z^Gn∼p(zGn∣Gn,θt−1,Ct−1)进行蒙特卡罗估计。具体来说,我们以自上而下的方式从每一层依次采样一个原型,所有采样的原型在分层原型中形成一个从顶层到底层的连接链。
在形式上,我们首先根据所有顶层原型的分类分布,从顶层采样一个原型,即 z ^ G n 1 ∼ C a t ( z G n 1 ∣ { α i } i = 1 M 1 ) ( α i = s o f t m a x ( s ( c i 1 , h G n ) ) ) \hat z^1_{\mathscr{G}_n} ∼ Cat(z^1_{\mathscr{G}_n}|\{α_i\}^{M_1}_{i=1}) (α_i = softmax(s(c^1_i, h_{\mathscr{G}_n}))) z^Gn1∼Cat(zGn1∣{αi}i=1M1)(αi=softmax(s(ci1,hGn))),其中s表示余弦相似度度量;
对于第 l l l层 ( l ≥ 2 ) (l\geq 2) (l≥2)的采样,我们根据从上一层采样的原型 z ^ G n l − 1 \hat z^{l-1}_{\mathscr{G}_n} z^Gnl−1的子节点上的分类分布,从这一层中抽取了一个原型,即 z ^ G n l ∼ C a t ( z G n l ∣ { α c } ) ( α c = s o f t m a x ( s ( c , h G n ) ) ) , ∀ c ∈ C ( z ^ G n l − 1 ) ) \hat z^l_{\mathscr{G}_n} ∼ Cat(z^l_{\mathscr{G}_n}|\{α_c\}) (α_c = softmax(s(c, h_{\mathscr{G}_n}))), ∀c ∈ \mathbb{C}(\hat z^{l−1}_{\mathscr{G}_n} )) z^Gnl∼Cat(zGnl∣{αc})(αc=softmax(s(c,hGn))),∀c∈C(z^Gnl−1)),这样我们抽样一个潜在变量 z ^ G n = { z ^ G n 1 , z ^ G n 2 , . . . , z ^ G n L p } \hat z_{\mathscr{G}_n}=\{\hat z_{\mathscr{G}_n}^1,\hat z_{\mathscr{G}_n}^2,...,\hat z_{\mathscr{G}_n}^{L_p}\} z^Gn={z^Gn1,z^Gn2,...,z^GnLp}这是层次化原型中的一个连接链。利用上述推断的潜在变量,我们寻求在 M M M步中最大化 complete-data log-likelihood 的期望。
M-step.
在这一步中,我们的目标是最大化关于潜在变量后验分布的 complete-data log-likelihood 的期望,其定义如下:

这个期望需要对所有的数据点进行计算,而这在online设置中是无法实现的。作为替代,我们建议最大化小批量 G ~ \widetilde{G} G 的期望对数似然,这可以使用在E-步骤中抽样的潜在变量 Z ~ e s t = { z ^ G n } n = 1 N \widetilde{Z}_{est}=\{\hat z_{\mathscr{G}_n}\}^N_{n=1} Z est={z^Gn}n=1N来估计:

我们想指出的是, Q ~ ( θ , C ) \widetilde{Q}(θ,C) Q (θ,C)是 Q ( θ , C ) Q(θ,C) Q(θ,C)的一个很好的代替,其中它们之间大约存在一个比例关系(证明见附录):

我们进一步扩展了 Q ~ ( θ , C ) \widetilde{Q}(θ,C) Q (θ,C),以推导出在计算方面更稳定的对数似然函数 L ( θ , C ) L(θ,C) L(θ,C):

为了估计 L ( θ , C ) L(θ,C) L(θ,C),我们需要定义一个图 G \mathscr{G} G和一个潜在变量 z G z_{\mathscr{G}} zG的联合似然,这在我们的方法中用一个 energy-based 的公式表示:

其中, Z ( θ , C ) Z(θ,C) Z(θ,C)表示配分函数。我们通过测量 graph embedding h G h_{\mathscr{G}} hG 和 the prototypes in z G z_{\mathscr{G}} zG的相似性,以及测量 z G z_{\mathscr{G}} zG中连续层原型之间的相似性来形式化 negative energy 函数 f f f:

直观地说, f f f评估了潜在变量 z G z_{\mathscr{G}} zG在潜在空间中代表图 G {\mathscr{G}} G的程度,它还测量了分层原型中从顶层到底层的连续原型之间的近似度。
由于 p ( G , z G ∣ θ , C ) p(\mathscr{G},z_{\mathscr{G}}|θ,C) p(G,zG∣θ,C)的优化是很重要的。受Noise-Contrastive Estimation (NCE)的启发,我们寻求优化 unnormalized likelihoods,即 p ~ ( G , z G ∣ θ , C ) = e x p ( f ( h G , z G ) ) \widetilde{p}(\mathscr{G},z_{\mathscr{G}}|θ,C)=exp(f(h_{\mathscr{G}},z_{\mathscr{G}})) p (G,zG∣θ,C)=exp(f(hG,zG)),通过将positive observed-latent variable pair与从某些噪声分布采样的negative pairs进行对比,它定义了一个很好地近似 L ( θ , C ) L(θ,C) L(θ,C)的目标函数:

其中, p n ( G , z G ) p_n(\mathscr{G},z_{\mathscr{G}}) pn(G,zG)为噪声分布。在实践中,我们计算了小批量中所有 positive pairs 的outer期望,即 ( G , z ^ G ) ( 1 ≤ n ≤ N ) (\mathscr{G},\hat z_{\mathscr{G}})(1 \leq n\leq N) (G,z^G)(1≤n≤N)。为了计算 inner 期望,我们为了正对 ( G , z ^ G ) (\mathscr{G},\hat z_{\mathscr{G}}) (G,z^G)构造 L p L_p Lp负对,方法是固定图 G n \mathscr{G}_n Gn,每次随机将 z ^ G n \hat z_{\mathscr{G}_n} z^Gn中的 L p L_p Lp原型中的一个替换为同一层的另一个原型。对于全局语义学习,我们的目标是最小化关于GNN参数 θ θ θ和层次原型 C C C的全局目标函数 L g l o b a l L_{global} Lglobal: 一般来说,所提出的在线EM算法寻求最大化由模型参数 θ θ θ和 C C C控制的联合似然 p ( G , Z ∣ θ , C ) p(G,Z|θ,C) p(G,Z∣θ,C)。更进一步,我们提出以下命题,即该算法确实可以最大化边际似然函数 p ( G ∣ θ , C ) p(G|θ,C) p(G∣θ,C)。
一般来说,所提出的在线EM算法寻求最大化由模型参数 θ θ θ和 C C C控制的联合似然 p ( G , Z ∣ θ , C ) p(G,Z|θ,C) p(G,Z∣θ,C)。更进一步,我们提出以下命题,即该算法确实可以最大化边际似然函数 p ( G ∣ θ , C ) p(G|θ,C) p(G∣θ,C)。
- Proposition 1.
对于每个EM周期,除非在mini-batch log-likelihood 函数 Q ~ ( θ , C ) \widetilde{Q}(θ,C) Q (θ,C)上达到一个局部最大值的时候,模型参数 θ θ θ和 C C C的更新方式增加了边际似然函数 p ( G ∣ θ , C ) p(G|θ,C) p(G∣θ,C)。
3.3. Model Optimization and Downstream Application
GraphLoG框架试图在未标记的图数据集 G G G学习graph representations,来保持local-instance和global-semantic结构。对于该框架下的模型优化,我们首先通过最小化局部目标函数 L l o c a l L_{local} Llocal来对GNN进行预训练,然后用预训练的GNN初始化模型参数。
之后,对于每个学习步骤,我们从数据集中抽取一个小批量 G ~ \widetilde{G} G ,并进行一个EM循环。在 E E E步中,从当前模型定义的后验分布中采样与mini-batch对应的潜在变量,即 Z e s t Z_{est} Zest。在 M M M步中,对模型参数进行更新,使期望对数似然最大化,并在M步优化中加入local objective函数,保证了在追求全局语义结构(global-semantic structure)时的局部平滑性,在实践中表现良好。我们在Alg.1中总结了最优化算法。

在对大量无标记图进行自监督预训练后,推导出的GNN模型可以应用于各种下游任务,以生成不同图的有效嵌入向量。例如,我们可以首先用GraphLoG对大量未标记的分子(即分子图)预训练一个GNN模型。然后,对于有一小组标记分子的分子性质预测的下游任务,我们可以在预先训练好的GNN模型上学习一个线性分类器来执行特定的图分类任务。