Multi-branch and Multi-scale Attention Learning for Fine-Grained Visual Categorization 论文学习
Abstract
ILSVRC(ImageNet大规模视觉识别挑战赛)是计算机视觉领域最权威的学术竞赛之一。直接将 ILSVRC 每年的冠军方案应用在细粒度视觉分类(FGVC)任务上无法取得很好的表现。对于 FGVC 任务而言,类间差异小而类内差异大的特点使这个问题变得很有挑战性。本文的注意力目标定位模块(AOLM)可以预测目标的位置,注意力局部提议模块(APPM)可以发现信息丰富的局部区域,无需边框或部分标注信息的帮助。得到的目标图像不仅包含目标的全部结构,也包含更多的细节信息,局部图像有多个不同的尺度和更多的细粒度特征,原始图像则包括目标的全部。通过本文的多分支网络来监督这三种训练图像。因此,该多分支和多尺度学习网络(MMAL-Net)有着良好的分类能力,对不同尺度的图像都有鲁棒性。该方法可以端到端地训练,且推理时间很短。通过大量的实验,作者证明了该方法可以在 CUB200-2011、FGVC-Aircraft 和 Stanford Cars 数据集上取得 SOTA 的表现。代码位于:https://github.com/ZF1044404254/MMAL-Net。
1. Introduction
如何分辨狗的品种?这是一个经常问到的问题,因为狗有着相似的特征。FGVC 研究针对这类问题,也被叫做子类别识别。近些年,它在计算机视觉、模式识别等领域非常流行。它的目的就是对于粗粒度大类别(比如分类鸟、飞机、汽车的种类)做出更细致的子类别区分。
论文[4,5,6,7]认为细粒度图像识别的关键就在于如何构建出有效的模型来准确识别图像中信息丰富的区域。它们利用边框和局部标注的额外信息来定位重要区域。但是,要得到这些密集的边框标注和局部标注信息是非常消耗人工的,这就制约了其规模性和真实世界中的应用范围。其它方法[8,9,10,11]则利用非监督学习来定位信息丰富的区域。它们省去了昂贵的标注成本,但是如何关注在对的区域以及如何利用它们仍值得研究。
MMAL-Net 的结构如图1所示。该方法训练阶段有3个分支,raw 分支主要学习目标的总体特征,AOLM 则在原始图像特征图的帮助下得到目标的边框信息。作为目标分支的输入,更细小尺度的目标图像对于分类非常有用,因为它包含着目标的结构特征和细粒度特征。然后 APPM 会根据目标图像的特征图,提出多个判别度最高、冗余度较低的局部区域。局部分支将原始图像上裁剪出的局部图像送进网络去训练。它使得网络可以学习不同尺度下不同部分的细粒度特征。与RA-CNN不同,三个分支的卷积网络和全连接层的参数共享。因此,该模型对于不同的尺度和目标局部都有着不错的分类能力。在测试时,与RA-CNN和NTS-Net不同,它们需要计算多个局部区域图像的特征向量,然后将这些向量 concat 起来进行分类。作者做了多个重复实验,发现目标分支输出的结果就是最佳的分类结果,因此该方法能够减少一些计算量和推理时间,而取得的准确率很高。
本文主要贡献如下:
- 多分支网络能够端到端地训练,有效地学习目标的判别区域,用于识别。
- AOLM 不会增加参数量,所以我们无需训练一个候选区域网络,像RA-CNN一样。只使用类别标签就可得到准确的目标定位。
- 作者提出了一个注意力局部提议方法(APPM),无需局部标注信息。它可以选择多个具有判别力的有序局部图像,这样该方法能够有效地学习不同尺度局部图像的细粒度特征。
- 作者在多个基准数据集上报告了SOTA的性能,本文方法超越了其它SOTA 方法和基线模型。

图1. 训练阶段中 MMAL-Net 的概括,红色分支是 raw 分支,橙色分支是目标分支,蓝色分支是局部分支。绿色虚线边框内的是测试时的网络结构。CNN和全连接层颜色相同,表示它们参数共享。该多分支结构全部使用交叉熵损失,作为分类损失。
2. Related Work
在过去几年,基于深度学习和细粒度分类方法,人们在公开数据集上得到了准确性提升。它们大致可以分为下面几类:1)通过端到端的特征编码,2) 通过定位-分类的子网络。
2.1 端到端的特征编码
这类方法通过更加强大的深度模型,直接学习一个更具判别力的特征表示,从而进行细粒度识别。最具代表性的方法就是双线性 CNN,它从2个双线性模型中得到特征,然后求该特征池化后的外积来表示图像,因此它编码了卷积激活值更高阶的统计信息,增强中间层级的学习能力。得益于其优异的建模能力,它在许多视觉任务上都取得了显著的提升。但是双线性特征的高维度束缚了其泛化性。为了解决这个问题,[13,14]则通过张量概述(tensor sketching)来聚合低维度embeddings。它们可以降低双线性特征的维度,实现更高的分类准确率。
2.2 定位-分类子网络
这类方法利用监督或弱监督信息训练一个定位子网络,定位关键局部区域。然后分类子网络使用定位子网络得到的细粒度区域的信息来进一步增强其分类能力。早期的工作[5,6,7]属于全监督方法,利用图像层级的标注信息来定位语义关键区域。[7]训练了一个区域提议网络来生成信息丰富的图像区块,将多个局部层级的特征 concat 起来,作为整张图像的表示,最后进行细粒度识别。但是,这些密集的局部标注信息会增加额外的标注成本。所以,[8,9,10,11]利用了注意力机制来避免这个问题。除了图像层级的标注,无需边框标注和局部标注信息。
3. 方法
3.1 注意力目标定位模块(AOLM)
这个方法是受SCDA[15]启发而来。SCDA 利用一个预训练模型来提取图像特征,用于细粒度图像提取任务。作者通过多个手段尽可能地改进了其定位性能。首先如图2所示,通过对CNN特征图做处理,介绍目标位置坐标的产生过程。

图2. AOLM 的流程。首先我们聚合通道维度上的特征图,得到一个激活图,然后根据该激活图产生边框。
我们使用 F ∈ R C × H × W F\in R^{C\times H\times W} F∈RC×H×W来表示 C C C通道的特征图,空间大小是 H × W H\times W H×W,最为最后一个卷积层的输出,输入是 X X X,其中 f i f_i fi是对应通道的第 i i i个特征图。如等式1所示,
A = ∑ i = 0 C − 1 f i A=\sum_{i=0}^{C-1} f_i A=i=0∑C−1fi
将特征图 F F F聚合起来,就可以得到激活图 A A A。我们可以通过可视化,发现网络关注在哪个位置,然后从 A A A中准确地定位到该目标区域。如等式2, a ‾ \overline a a是 A A A的平均值。
a ‾ = ∑ x = 0 W − 1 ∑ y = 0 H − 1 A ( x , y ) H × W \overline a = \frac{\sum_{x=0}^{W-1} \sum_{y=0}^{H-1} A(x,y)}{H\times W} a=H×W∑x=0W−1∑y=0H−1A(x,y)
a ‾ \overline a a作为阈值来判断 A A A中 ( x , y ) (x,y) (x,y)位置的元素是否属于目标物体, ( x , y ) (x,y) (x,y)是 H × W H\times W H×W激活图上的特定位置。然后根据等式3,我们从ResNet-50的最后一个卷积层 c o n v _ 5 c conv\_5c conv_5c得到了一个粗糙的 mask 图 M ~ c o n v _ 5 c \tilde M_{conv\_5c} M~conv_5c。
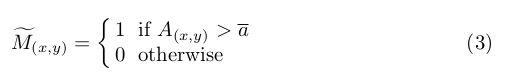
基于实验结果,作者发现目标通常位于 M ~ c o n v _ 5 c \tilde M_{conv\_5c} M~conv_5c中最大的连接部分,所以包含最大连接区域的最小边框就用作为目标定位的结果。仅使用一个SCDA中的VGG16预训练模型,就可以取得不错的定位精度,但是作者的ResNet50预训练模型就没法达到相似的精度,下降得很厉害。所以作者用训练集来训练 ResNet-50,提升目标定位精度,4.5节的实验验证了该方法的有效性。然后,受[15]和[18]启发,它们的模型都受益于多个网络层的 ensemble。所以作者根据等式1也得到了 c o n v _ 5 b conv\_5b conv_5b的输出激活图,它位于 c o n v _ 5 c conv\_5c conv_5c一个block之前。然后根据等式3得到了 M ~ c o n v _ 5 b \tilde M_{conv\_5b} M~conv_5b,最终取 M ~ c o n v _ 5 c \tilde M_{conv\_5c} M~conv_5c和 M ~ c o n v _ 5 b \tilde M_{conv\_5b} M~conv_5b的交集,得到了一个更加准确的mask M M M。如等式4所示,
M = M ~ c o n v _ 5 c ∩ M ~ c o n v _ 5 b M=\tilde M_{conv\_5c} \cap \tilde M_{conv\_5b} M=M~conv_5c∩M~conv_5b
后续实验结果证明了这些方法的有效性,提升了目标定位的准确率。该弱监督目标定位方法能够实现比 ACOL、ADL和SCDA 更高的定位准确率,不会增加训练参数。
3.2 注意力局部提议模块(APPM)
尽管AOLM能够得到较高的定位精度,但是一些定位结果只部分属于目标物体。作者通过APPM和局部分支来提升模型的鲁棒性,解决这个问题。下一章节中会做介绍。观察激活图 A A A,作者发现激活图上高激活值的区域通常是定位的关键部分,如例图中的头部区域。使用目标检测中的滑动窗来找到信息丰富的窗口区域,作为局部图像使用。此外,作者通过全卷积网络实现了传统的滑动窗方法,降低计算量,如Overfeat一样,从上一个分支的特征图输出中得到不同窗口的特征图。然后作者将通道维度中的每个窗口激活图 A w A_w Aw聚合,根据等式5得到它的激活均值 a ‾ w \overline a_w aw。
a ‾ w = ∑ x = 0 W w − 1 ∑ y = 0 H w − 1 A w ( x , y ) H w × W w \overline a_w = \frac{\sum_{x=0}^{W_w-1}\sum^{H_w-1}_{y=0}A_w(x,y)}{H_w \times W_w} aw=Hw×Ww∑x=0Ww−1∑y=0Hw−1Aw(x,y)
H w , W w H_w,W_w Hw,Ww是窗口特征图的高度和宽度。我们对所有窗口的 a ‾ w \overline a_w aw值排序。 a ‾ w \overline a_w aw值越大,该局部区域的信息就越丰富,如图3所示。但是,我们不能直接选择前几个窗口,因为它们通常毗邻着 a ‾ w \overline a_w aw最大的窗口,所包含的信息几乎一样,作者希望选择尽可能多的不同局部区域。为了降低区域冗余,作者采取了NMS来选择固定个数的窗口,作为局部图像,它们的尺度不同。在图4中作者可视化了该模块的输出,我们可以看到该方法输出的是排序后的、不同重要程度的局部区域。

图3. APPM 的简单流程。作者用红色、橙色、黄色、绿色来表示窗口 a ‾ w \overline a_w aw的顺序。
3.3 MMAL-Net 结构
为了让模型能够通过AOLM和APPM模块,充分有效地学习图像。在训练阶段,作者构建了一个三分支网络,包含raw分支、目标分支和局部分支,如图1所示。这三个分支共享一个用于特征提取的CNN和用于分类的全连接层。这三个分支都使用交叉熵损失作为分类损失。如下面等式所示,

其中 c c c是输入图片的ground truth标签, P r , P o P_r,P_o Pr,Po是raw分支和目标分支最后一个softmax层输出的类别概率, P p ( n ) P_{p(n)} Pp(n)是局部分支 softmax层的输出,对应着第 n n n个局部图像, N N N是局部图像的个数。总的损失定义为:
L t o t a l = L r a w + L o b j e c t + L p a r t s L_{total}=L_{raw}+L_{object} + L_{parts} Ltotal=Lraw+Lobject+Lparts
总的损失是三个分支损失的和,它们一起工作,通过反向传播来优化模型的性能。基于目标整体的结构特征或局部细粒度特征,最终的收敛模型来做分类预测。该模型有着良好的目标尺度适应能力,即便AOLM定位出错了,它也能提升鲁棒性。在测试阶段,作者去除了局部分支,降低计算量,所以该方法不会耗费太多时间来做推理。MMAL-Net 能够实现 SOTA 的性能表现。
4. Experiments
Pls read paper for more details.