NLP-Beginner 任务三:基于注意力机制的文本匹配+pytorch
NLP-Beginner 任务三:基于注意力机制的文本匹配
- 传送门
- 一. 介绍
-
- 1.1 任务简介
- 1.2 数据集
- 二. 特征提取——Word embedding(词嵌入)
- 三. 神经网络
-
- 3.1 Input Encoding层
- 3.2 Local Inference Modeling层
- 3.3 Inference Composition层
- 3.4 Output层
- 3.5 训练神经网络
- 四. 代码及实现
-
- 4.1 实验设置
- 4.2 结果展示
-
- 4.2.1 Part 1
- 4.2.1 Part 2
- 4.3 代码
- 五. 总结
- 六. 自我推销
本次实战先初步介绍+贴代码,更多细节以后会补充。
传送门
NLP-Beginner 任务传送门
我的代码传送门
数据集传送门
特征提取预训练模型
参考论文:Enhanced LSTM for Natural Language Inference
一. 介绍
1.1 任务简介
本次的NLP(Natural Language Processing)任务是论文提出的中的ESIM模型文本进行匹配。
1.2 数据集
数据集传送门
训练集共有55万余项,语言为英文,匹配关系共有四种:蕴含(Entailment),矛盾(Contradiction),中立/不冲突(Neutral),未知(-)(注:未知关系在数据里出现得很少)。
例子:
输入文本: A man inspects the uniform of a figure in some East Asian country.
输入假设: The man is sleeping.
输出: 矛盾(C)
输入文本: An older and younger man smiling.
输入假设: Two men are smiling and laughing at the cats playing on the floor.
输出: 中立(N)
输入文本: A black race car starts up in front of a crowd of people.
输入假设: A man is driving down a lonely road.
输出: 矛盾(C)
输入文本: A soccer game with multiple males playing.
输入假设: Some men are playing a sport.
输出: 蕴含(E)
输入文本: A smiling costumed woman is holding an umbrella.
输入假设:A happy woman in a fairy costume holds an umbrella.
输出: 中立(N)
二. 特征提取——Word embedding(词嵌入)
请参考NLP任务二
三. 神经网络
本部分详细内容可以参考论文:Enhanced LSTM for Natural Language Inference
3.1 Input Encoding层

3.2 Local Inference Modeling层

3.3 Inference Composition层

3.4 Output层

3.5 训练神经网络
采用交叉熵损失函数进行神经网络训练。
交叉熵损失函数定义可参考NLP任务二。
四. 代码及实现
4.1 实验设置
- 样本个数:约550000
- 训练集:测试集 : 7:3
- 模型:ESIM
- 初始化:随机初始化,GloVe预训练模型初始化
- 学习率:10-3
- l h , l f l_h,\ l_f lh, lf:50
- Batch 大小:1000
4.2 结果展示
4.2.1 Part 1
先对文本句子的长度排序,使一个batch内的句子长短大致相同,防止长句子的存在使短句子需要padding过长的现象发生。
注意:但不保证“假设句子”的长度在同一个batch内一致。
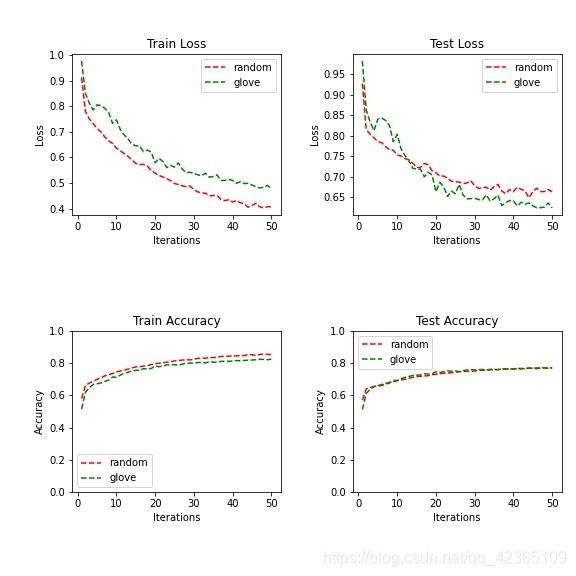
最终测试集正确率有78%。
4.2.1 Part 2
不对文本句子进行排序,只保证同一个batch内句子padding到同一个长度。
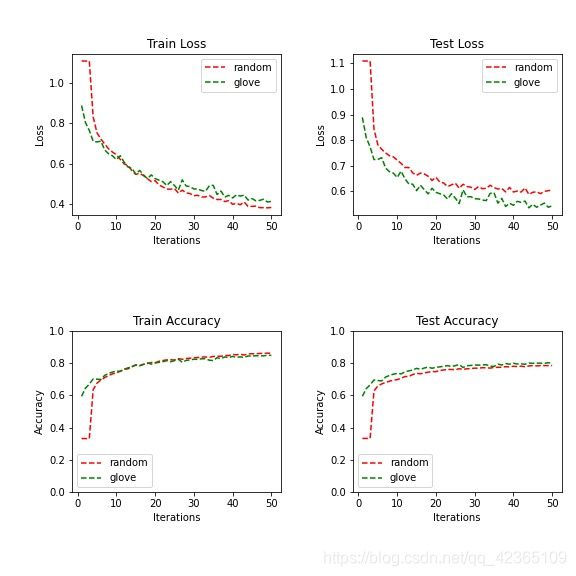
最终测试集正确率反而比较高,有80%。
4.3 代码
本次使用了Python中的torch库,并使用了cuda加速。
若不想要GPU加速,只需要把comparison_plot_batch.py和Neural_Network_batch.py中所有的.cuda()和.cpu()删去即可。
注:可能在comparison_plot_batch.py中的所有.item()也要删去。
请移步至Github
五. 总结
本次实验跑完了55万数据,推荐用Google的Colab(需要科学上网),或者Kaggle(不需要科学上网)的GPU来跑代码,速度会快很多,比纯CPU快多了。
测试集准确率最高只有80%,不是特别高,把 l h 和 l f l_h和l_f lh和lf都设置成更大的数字可能会效果更好(比如,300和100),能到84%~87%,但是这样会训练更久,对算力要求比较高。
以上就是本次NLP-Beginner的任务三,更多的细节后面会补充,谢谢各位的阅读,欢迎各位对本文章指正或者进行讨论,希望可以帮助到大家!
六. 自我推销
-
我的代码&其它NLP作业传送门
-
LeetCode练习