1.词云图(已知词频)
1.1不加背景图层
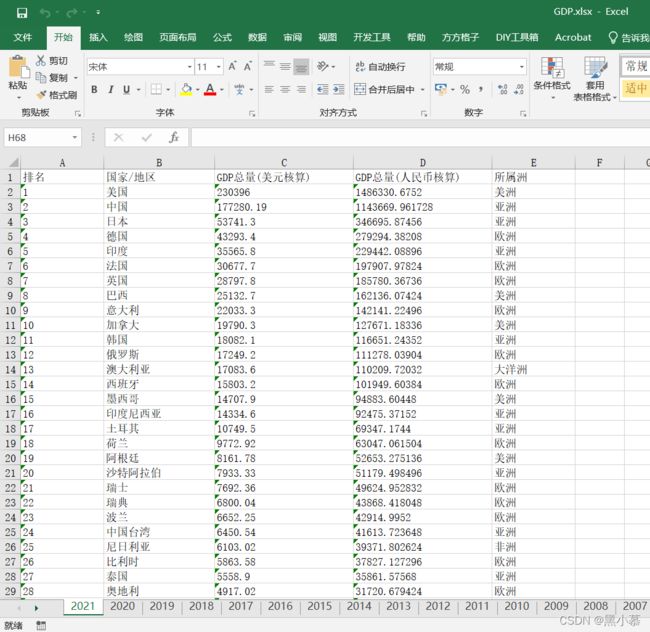
1.1.1原始数据
1.1.2程序
import pandas as pd
from wordcloud import WordCloud
from matplotlib import pyplot as plt
pd.set_option('display.float_format', lambda x: '%.4f' % x)
data=pd.read_excel('./GDP.xlsx',sheet_name='2021',usecols=['国家/地区','GDP总量(人民币核算)'])
print(data.head())
list_country=data['国家/地区'].tolist()
list_gdp=data['GDP总量(人民币核算)'].tolist()
dic=dict(zip(list_country,list_gdp))
print(dic)
font=r'C:\Windows\Fonts\simhei.ttf'
wordcloud=WordCloud(background_color='black',width=800,height=800,margin=1,font_path=font).generate_from_frequencies(dic)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
1.1.3效果

1.2加背景图层
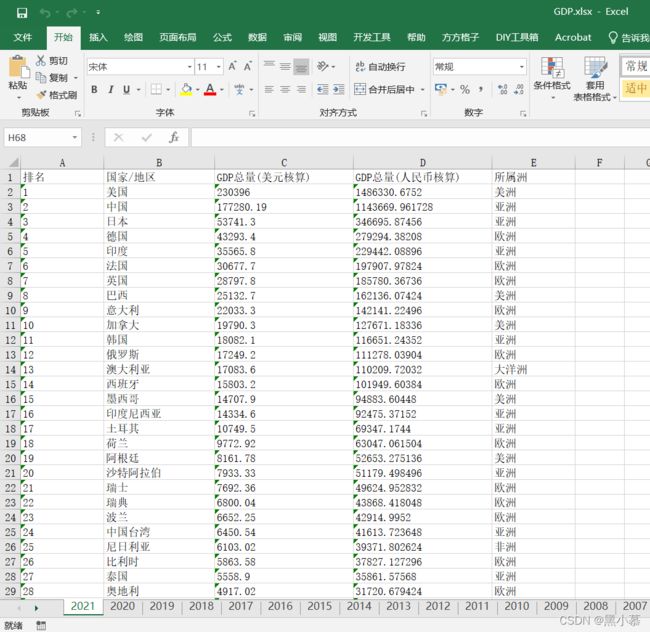
1.2.1原始数据
1.2.2程序
import pandas as pd
import numpy as np
from wordcloud import WordCloud
from matplotlib import pyplot as plt
from PIL import Image
pd.set_option('display.float_format', lambda x: '%.4f' % x)
data=pd.read_excel('./GDP.xlsx',sheet_name='2021',usecols=['国家/地区','GDP总量(人民币核算)'])
print(data.head())
list_country=data['国家/地区'].tolist()
list_gdp=data['GDP总量(人民币核算)'].tolist()
dic=dict(zip(list_country,list_gdp))
print(dic)
font=r'C:\Windows\Fonts\simhei.ttf'
MASK=np.array(Image.open('./rmb.jpg'))
wordcloud=WordCloud(background_color='white',scale=1,max_words=500,max_font_size=100,font_path=font,mask=MASK,repeat=False,mode='RGB',colormap='winter').generate_from_frequencies(dic)
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off')
plt.show()
1.2.3效果

2.词云图(未知词频)
2.1不加背景图层
2.1.1原始数据

2.1.2程序
import re
import jieba
import pandas as pd
from wordcloud import WordCloud
from matplotlib import pyplot as plt
text=pd.read_csv('zfgzbg.txt',index_col=0)
print(text)
text2=str(text)
text3=re.sub("[a-zA-Z0-9'!""#$%&\'()*+,-./:;<=>?@,。?★、…【】《》:?“”‘'![\\]^_`{|}~\s]+","",text2)
print(text3)
text4=jieba.lcut(text3)
print(text4)
text5=' '.join(text4)
print(text5)
stopwords=['我','和','你','的','地','得','了','都','对','向','在','可','能','为','要','再','是','等','一','二','三','四','五','六','七','八','九','十','各位','代表','一年','请予']
font=r'C:\Windows\Fonts\simhei.ttf'
wordcloud=WordCloud(background_color='white',scale=1,max_words=500,max_font_size=100,font_path=font,stopwords=stopwords).generate_from_text(text5)
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off')
plt.show()
2.1.3效果

2.2加背景图层
2.2.1原始数据

2.2.2程序
import re
import jieba
import pandas as pd
import numpy as np
from PIL import Image
from wordcloud import WordCloud
from matplotlib import pyplot as plt
text=pd.read_csv('zfgzbg.txt',index_col=0)
print(text)
text2=str(text)
text3=re.sub("[a-zA-Z0-9'!""#$%&\'()*+,-./:;<=>?@,。?★、…【】《》:?“”‘'![\\]^_`{|}~\s]+","",text2)
print(text3)
text4=jieba.lcut(text3)
print(text4)
text5=' '.join(text4)
print(text5)
stopwords=['我','和','你','的','地','得','了','都','对','向','在','可','能','为','要','再','是','等','一','二','三','四','五','六','七','八','九','十','各位','代表','一年','请予']
font=r'C:\Windows\Fonts\simhei.ttf'
MASK=np.array(Image.open('./map.jpg'))
wordcloud=WordCloud(background_color='white',scale=2,max_words=500,max_font_size=150,font_path=font,stopwords=stopwords,mask=MASK,colormap='brg').generate_from_text(text5)
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off')
plt.show()
2.2.3效果
