利用Python分析文章词频,并生成词云图
利用Python分析文章词频,并生成词云图
使用request模块获取文章数据
import jieba
import requests
import csv
from bs4 import BeautifulSoup
import re
# 字符集
r = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+'
# 文章链接:在中国日报网,选取了一篇新闻作为本次案例的分析
url = 'http://www.chinadaily.com.cn/a/202008/20/WS5f3db65da31083481726171e.html' #英语新闻URL
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 QIHU 360SE'
}
response = requests.get(url=url, headers=headers) #获取响应内容
print(response) #
使用BeautifulSoup模块解析所需的文章内容和词频统计
基本思路
- 使用BeautifulSoup模块获取文章内容
- 去除文章中的字符集
- 消除大小写字母的影响
- 把英文文章的每个单词放到列表里,并统计列表长度;
- 遍历列表,对每个单词出现的次数进行统计,并将结果存储在字典中;
- 求出每个单词出现的频率,并将结果存储在频率字典中;
- 以字典键值对的“值”为标准,对字典进行排序,输出结果
# 转化为Beatifulsoup格式
bs = BeautifulSoup(response.text, 'html.parser')
print(type(bs)) #
Life as we know it has changed, possibly forever
26
[('the', 83), ('to', 65), ('of', 51), ('and', 39), ('in', 33), ('a', 33), ('said', 23), ('people', 21), ('that', 19), ('be', 18), ('for', 16), ('are', 15), ('from', 15), ('they', 15), ('have', 14)]
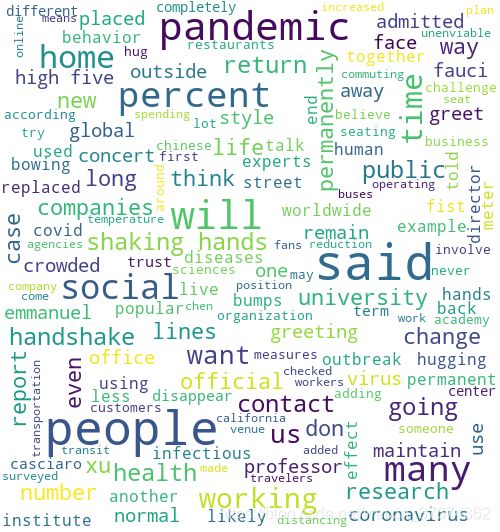
制作词云图
1、词云图 制作前,需要先准备几个东西:
(1)下载python wordcloud库,也是词图库制作的关键库;
(2)numpy库,用于图片处理,将图片读取后解析成数组;
(3)如果要对中文句子进行分词,那么需要jieba库;如果是英文分词,那可以不下载;
(4)如果要在界面上直接展示词云图 ,那么需要matlplotlib来画图;
(5)要处理图片,根据少不了PIL,毕竟它可是官方的图像处理库;
# 生成词云图
import matplotlib as plt
from wordcloud import wordcloud
from PIL import Image
import numpy as np
cut_text = jieba.cut(text)
result = ' '.join(cut_text)
# print(result)
mask = np.array(Image.open('./运动.jpg')) #解析图片
wc = wordcloud.WordCloud(
background_color='white', # 背景颜色
width=1000,
height=600,
max_font_size=50, # 字体大小
min_font_size=10,
mask=mask, # 背景图片
max_words=1000)
wc.generate(result)
image = wc.to_image()
image.show() # 显示词云
# 保存图片
wc.to_file('jiab_englist11.png')