Pytorch深度学习实战教程(一):语义分割基础与环境搭建
Pytorch的基本使用&&语义分割算法讲解
先从最简单的语义分割基础与开发环境搭建开始讲解。
二、语义分割
语义分割是什么?
语义分割(semantic segmentation) : 就是按照“语义”给图像上目标类别中的每一点打一个标签,使得不同种类的东西在图像上被区分开来。可以理解成像素级别的分类任务,直白点,就是对每个像素点进行分类。
简而言之,我们的目标是给定一幅RGB彩色图像(高x宽x3)或一幅灰度图像(高x宽x1),输出一个分割图谱,其中包括每个像素的类别标注(高x宽x1)。具体如下图所示:

注意:为了视觉上清晰,上面的预测图是一个低分辨率的图。在实际应用中,分割标注的分辨率需要与原始图像的分辨率相同。
这里对图片分为五类:Person(人)、Purse(包)、Plants/Grass(植物/草)、Sidewalk(人行道)、Building/Structures(建筑物)。
与标准分类值(standard categorical values)的做法相似,这里也是创建一个one-hot编码的目标类别标注——本质上即为每个类别创建一个输出通道。因为上图有5个类别,所以网络输出的通道数也为5,如下图所示:
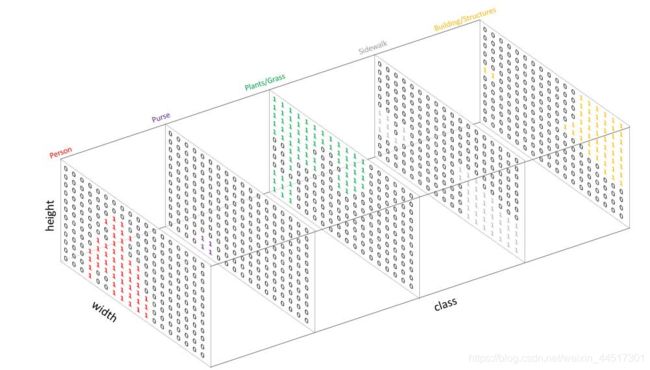
如上图所示,预测的结果可以通过对每个像素在深度上求argmax的方式被整合到一张分割图中。进而,我们可以轻松地通过重叠的方式观察到每个目标。
argmax的方式也很好理解。如上图所示,每个通道只有0或1,以Person的通道为例,红色的1表示为Person的像素,其他像素均为0。其他通道也是如此,并且不存在同一个像素点在两个以上的通道均为1的情况。因此,通过argmax就找到每个像素点的最大索引通道值。最终得到结果为:

当只有一层通道被重叠至原始图像时,我们称之为mask,即只指示某一特定类别所存在的区域。
高分辨率的结果如下图所示,不同的颜色代表不同的类别:

三、数据集
常见的语义分割算法属于有监督学习,因此标注好的数据集必不可少。
公开的语义分割数据集有很多,目前学术界主要有三个benchmark(数据集)用于模型训练和测试。
第一个常用的数据集是Pascal VOC系列。这个系列中目前较流行的是VOC2012,Pascal Context等类似的数据集也有用到。
第二个常用的数据集是Microsoft COCO。COCO一共有80个类别,虽然有很详细的像素级别的标注,但是官方没有专门对语义分割的评测。这个数据集主要用于实例级别的分割以及图片描述。所以COCO数据集往往被当成是额外的训练数据集用于模型的训练。
第三个数据集是辅助驾驶(自动驾驶)环境的Cityscapes,使用比较常见的19个类别用于评测。
可以用于语义分割训练的数据集有很多:
Pascal Voc 2012:比较常见的物体分类,共21个类别;
MS COCO:由微软赞助,几乎成为了图像语义理解算法性能评价的“标准”数据集,共80个类别;
Cityscapes:包含50个欧洲城市不同场景、不同背景、不同季节的街景的33类标注物体;
Pascal-Context:对于PASCAL-VOC 2010识别竞赛的扩展,共59个类别;
KITTI:用于移动机器人及自动驾驶研究的最受欢迎的数据集之一,共11个类别;
NYUDv2:2.5维数据集,它包含1449张由微软Kinect设备捕获的室内的RGB-D图像;
SUN-RGBD:由四个RGB-D传感器得来,包含10000张RGB-D图像,尺寸与PASCAL VOC一致;
ADE20K_MIT:一个场景理解的新的数据集,这个数据集是可以免费下载的,共151个类别。
数据集有很多,本系列教程不局限于具体数据集,可能也会用到Kaggle比赛之类的数据集,具体每个数据集怎么处理,数据集的格式是什么样的,后续文章用到什么数据集会具体讲解。
四、GPU机器
对于语义分割任务,有个带有高端GPU显卡的机器还是非常有必要的,如果没有,训练收敛会很慢。
最佳的开发环境为Linux,因为在公司的日常工作,基本都是使用Linux云服务器进行模型开发的工作,提前适应Linux操作系统还是有好处的。
对于学生党,如果实验室是做深度学习方向研究的,并且资源完备,那么GPU服务器应该还是能有的,对于GPU服务器的问题不用愁。
但可能由于条件限制,实验室没有配备GPU服务器,还想学习深度学习相关的知识,有三种方法:
1、免费云服务器Google Colab
勉强可以一用的是Google Colab,它是一个Google提供的免费GPU服务器,提供的GPU算力还算可以,但是它的主要问题在于需要和存储空间小,Google Colab的存储空间是通过挂载Google Drive得到的,Google Drive只提供15G的免费存储空间,想要扩展空间,还是需要花钱的。
想使用免费云服务器Google Colab的,可以自行百度教程。
2、阿里云付费GPU云服务器
阿里云提供GPU云服务器资源,有两种付费模式:包月和按流量付费。有P4服务器,甚至吊炸天的V100服务器。性能强劲,价格也很感人,两个字形容就是很贵,个人使用者并不推荐购买。除了阿里云提供GPU云服务,腾讯、百度、华为都有相应的服务,但是都很贵。
3、配置一台电脑主机
可以自己配置一台台式主机,也算是对自己的一种投资。配置一台不错的,可以用于深度学习训练的主机需要6000元左右。
深度学习的训练很依赖显卡的性能,因此需要配置一个较好的N卡,也就是NVIDIA的显卡,选显卡的技巧就是看下显卡天梯图:
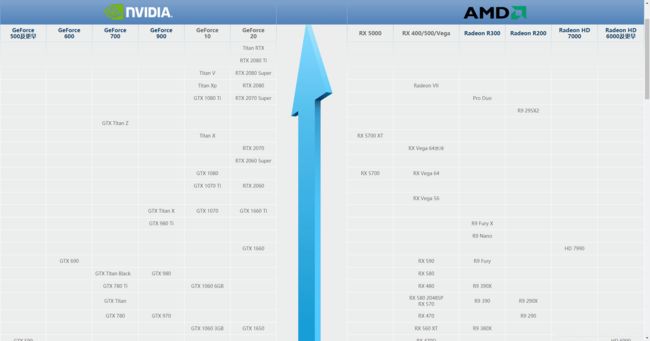
这个显卡天梯图主要包括的是市面常用的显卡排名,不包括类似V100这样的价格上10万的显卡。
天梯图,越靠上,显卡的性能越高,不要选择右侧的AMD显卡,虽然性能好,但A卡是不支持CUDA的。
根据自己的预算,选择显卡,显卡的显存尽量选择8G以上的,深度学习模型训练很吃显存资源。
本人买了微星的RTX 2060 Super,买时的价格是3399元,显卡很不保值,价格会随时间越来越低。
配置电脑其实能写很多,比如CPU、电脑主板、电源、内存、散热器的选择等,这里就不扩展了。没有精力自己组装台式机的,可以直接买配备相应显卡的台式机,但价格相对自己组装的台式机,价格会贵一些。
五、开发环境搭建
有条件的,推荐使用Ubuntu系统配置开发环境,Ubuntu是Linux的一个发行版之一,适合新手,界面友好,操作简单。
由于本人购买的电脑主板,不支持Linux架构的系统安装,因此后续会以Windows作为开发环境,但这并不影响算法原理与代码的讲解。
本人的台式机配置情况:
CPU:Intel i7 9700k
显卡:RTX 2060 Super
系统:Windows 10
安装好Windows系统和必要的驱动后,需要安装的工具有:CUDA、Anaconda3、cuDNN、Pytorch-gpu、Fluent Terminal(可选)。
1、CUDA
CUDA,是显卡厂商NVIDIA推出的运算平台。我们需要根据自己显卡的型号选择支持的CUDA版本,例如RTX 2060 Super支持CUDA 10,下载地址:点击查看
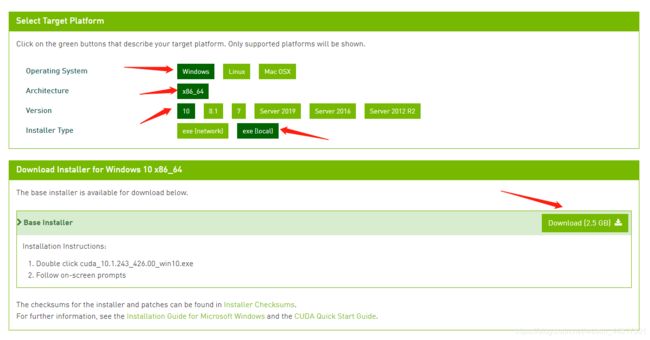
傻瓜式安装,很简单。
安装好后,需要再配置下系统的环境变量,电脑->鼠标右键->属性->高级系统设置->环境变量->Path:
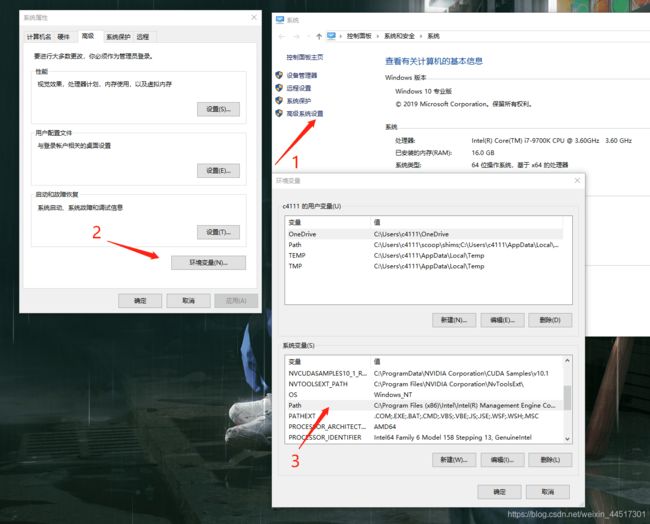
添加自己的NVSMI路径到环境变量中,我采用的是默认安装地址:

配置好后,就可以在cmd中使用nvidia-smi指令查看显卡了。
2、Anaconda3
Anaconda是Python的包管理器和环境管理器,可以方便我们安装Python的第三方库。
下载地址:点击查看
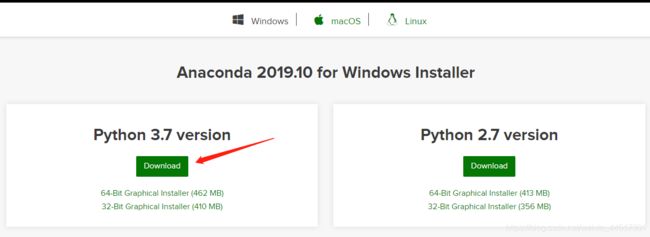
选择Python 3.7的版本,安装也很简单,傻瓜式下一步即可。
安装好后,需要添加系统环境变量,方法与安装CUDA时一样:
D:\Anaconda
D:\Anaconda\Scripts
路径改为自己安装的Anaconda路径即可。
配置好后,在cmd中运行conda -V没有报错,有版本信息输出,说明配置成功。
3、cuDNN和Pytorch安装
cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。
安装好Anaconda之后,可以使用conda安装cuDNN和Pytorch。
打开Anaconda Prompt,这是Anaconda自带的命令行工具,先一定要用这个工具创建环境,直接用系统自带的cmd,可能遇到一些奇怪的问题,例如CondaHTTPError的错误。在Anaconda Prompt中输入:
conda create -n your_name jupyter notebook
这句话的意思是创建一个名字为your_name的虚拟环境,并且这个虚拟环境额外安装jupyter notebook第三方库。可以将your_name改为你自己喜欢的名字,这个名字是你的虚拟环境的名字,自己随便取,比如jack。
随后,输入y进行安装:
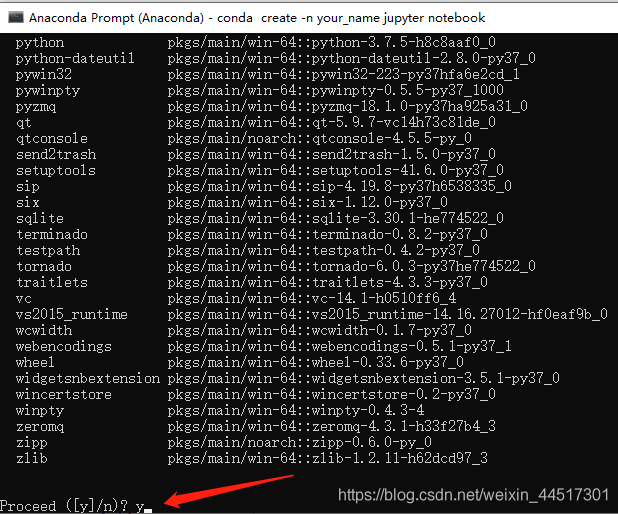
安装好后,可以通过指令conda info -e查看已有环境情况。
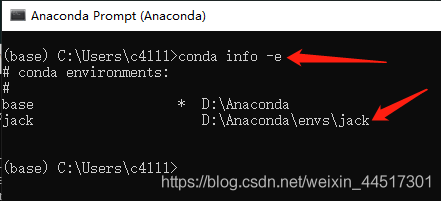
从上图可以看到,有两个环境,一个是base,自带的基础环境,另一个是我们新创建的名为jack的环境。新建环境的原因是,我们可以分开管理我们配置的环境。
安装好环境后,我们就可以激活jack环境,并安装cuDNN和GPU版的Pytorch了。激活名为jack的环境:
activate jack
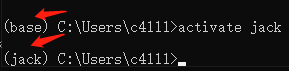
可以看到,我们的环境由base变成了jack。在jack环境中安装cuDNN:
conda install cudnn
安装cuDNN好后,安装Pytorch,打开Pytorch官网:点击查看
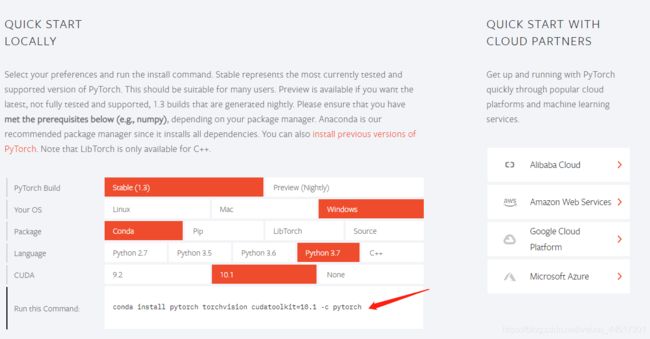
根据自己的环境选择,选择好后,网页会自动给出需要运行的指令。这里可能需要区分下Python的版本和CUDA的版本。
Python版本查看方法:直接在命令行中输入python,会看到Python的版本。

CUDA版本查看方法,在命令行中输入nvidia-smi:
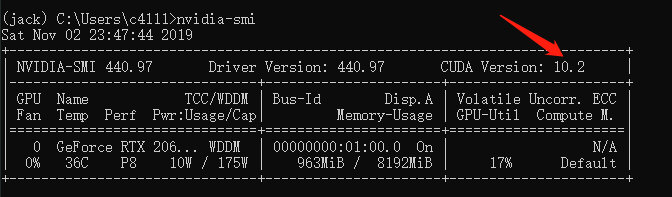
确定好版本后,就可以通过Pytorch官网提供的指令安装GPU版本的Pytorch了。
至此,基础的环境搭建已经完成,恭喜。
4、Fluent Terminal
基础环境配好了,正常使用已经够了。
但是追求颜值的人,可能会觉得,Windows自带的命令行工具和Anaconda提供的命令行工具都太丑了。
有没有好看,又好用的Terminal?答案是有的,不过需要自己配置,并且还有一些坑需要慢慢踩。
例如Fluent Terminal,它是现代的、也是我比较推荐的终端工具。它是专属于 Windows 平台,并利用UWP技术打造的颜值超高的终端模拟器。先看下颜值: