决策树的value是什么意思_从零开始的机器学习实用指南(六):决策树

类似SVM,决策树也是非常多功能的机器学习算法,可以分类,回归,甚至可以完成多输出的任务,能够拟合复杂的数据集(比如第二章的房价预测例子,虽然是过拟合了=。=)
决策树也是很多集成学习的组件,比如随机森林和梯度提升树等等
决策树的训练和可视化
还是以熟悉的iris数据集为例:
首先训练一个决策树模型,然后做一些可视化,使用export_graphviz()方法,通过生成一个叫做iris_tree.dot。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=image_path("iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)可以利用graphviz package(http://www.graphviz.org/) 中的dot命令行,将.dot文件转换成 PDF 或 PNG 等多种数据格式。
$ dot -Tpng iris_tree.dot -o iris_tree.png
我们将从这个图开始,简单分析决策树是怎么样工作的
从根节点出发,首先要判断花瓣长度是否小于 2.45 厘米,如果小于移动到左子节点,会判断这个花是Iris-Setosa。如果大于2.45cm,会移动到右子节点,判断宽度是否小于等于1.75cm
,如果是的,会到它的左子节点,判断为versicolor,否则到右子节点,判断为,virginica。
过程是非常清晰简单的
决策树的众多特性之一就是, 它不需要太多的数据预处理, 尤其是不需要进行特征的缩放或者归一化。
图中还有一些属性
samples属性统计出它应用于多少个训练样本实例。如,开始有150组例子value属性告诉你这个节点对于每一个类别的样例有多少个。如:右下角的节点中包含 0 个 Iris-Setosa,1 个 Iris-Versicolor 和 45 个 Iris-Virginica。Gini属性用于测量它的纯度:如果一个节点包含的所有训练样例全都是同一类别的,我们就说这个节点是纯的(Gini=0)。基尼不纯度的公式在下面,具体的用处我们稍后再说。

Sklearn 用的是 CART 算法, CART 算法仅产生二叉树(是或否)。然而,像 ID3 这样的算法可以产生超过两个子节点的决策树模型。
下面的图展示了决策边界,第一次的边界是在length=2.45,左面是纯的,不用再分了。右面是不纯的,再在width=1.75做了分割,如果树高可以为3的话,会继续分割下去(如虚线)
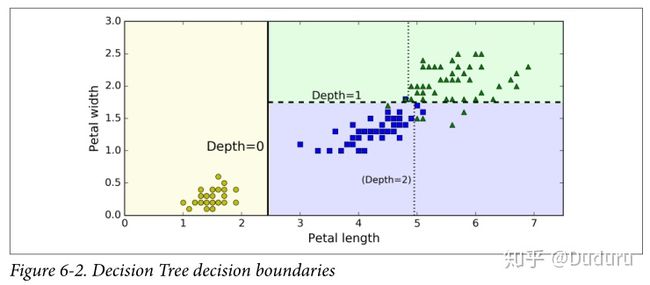
从图中可以看出,决策树是典型的白盒模型,可以提供清楚的分类依据。分类具有很强的可解释性
另外,决策树可以很容易的给出分类的概率
比如你发现了一个花瓣长 5 厘米,宽 1.5 厘米的花朵,对应上图6-1的绿色那一块
Iris-Setosa 为 0%(0/54),Iris-Versicolor 为 90.7%(49/54),Iris-Virginica 为 9.3%(5/54)
测试结果完全符合预期
>>> tree_clf.predict_proba([[5, 1.5]])
array([[ 0. , 0.90740741, 0.09259259]])
>>> tree_clf.predict([[5, 1.5]])
array([1])CART树算法
SkLearn 用分裂回归树(Classification And Regression Tree, CART)算法训练决策树
原理非常简单
每次分裂都要找到特征k和阈值tk(比如特征=宽度,阈值=2.45),CART会寻找一个分裂方法,让分裂后两边的基尼不纯度按照节点数量加权尽可能的小,损失函数为

然后递归的,对于子集,子集的子集,按照同样的方法进行分裂
可以看出,每次分割是贪心算法,不能保证这是全局上最好的解。这是因为找到最优树是一个 NP 完全问题,需要超出多项式的复杂度,我们需要找一个合理的(而不是最佳的)方案
CART停止的条件是达到预定的最大深度之后将会停止分裂(由max_depth超参数决定)
,或者是它找不到可以继续降低不纯度的分裂方法的时候(所有节点都是同一个类了)。几个其他超参数(之后介绍)控制了其他的停止生长条件。
复杂度计算
建立好决策树后,预测的速度是非常快的。决策树是一个近似平衡的树,大概只需要O(logm)的复杂度(m样本数),因此是非常快的。
但是训练上因为要比较多种的分裂可能,有了O(nmlogm)的复杂度。过程是比较慢的。对于小型的数据集(少于几千),可以用预排序来加速(presort = True)但是大数据反而会降低速度。
基尼不纯度/信息熵
通常,算法使用 Gini 不纯度来进行检测, 但是你也可以设置为"entropy"来使用熵不纯度进行检测。
熵的概念是源于热力学中分子混乱程度的概念,当分子井然有序的时候,熵值接近于 0。后来推广到信息论中,当所有信息相同的时候熵被定义为零。
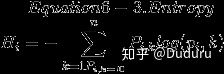
在机器学习中,熵经常被用作不纯度的衡量方式,当一个集合内只包含一类实例时, 我们称为数据集的熵为 0。 熵的减少通常称为信息增益。
通常来说Gini不纯度和信息熵的结果是类似的,基尼指数计算稍微快一点,所以这是一个很好的默认值。但是,也有的时候它们会产生不同的树,基尼指数会趋于在树的分支中将最多的类隔离出来,而熵指数趋向于产生略微平衡一些的决策树模型。
正则化
决策树不对数据做任何的假设,如果任由决策树无限制的拟合数据,必然会造成严重的过拟合。
这样的模型称为非参数模型,没有参数数量的限制,可以自由的去拟合数据。线性回归等这类有参数的模型,自由度受到一定的限制,本身就有一些抵御过拟合的能力(也增加了欠拟合的风险)
除了限制树的高度可以显著的限制模型过拟合,SKlearn还有一些其他的正则化相关的超参数:
min_samples_split(节点在被分裂之前必须具有的最小样本数)min_samples_leaf(叶节点必须具有的最小样本数)min_weight_fraction_leaf(和min_samples_leaf相同,但表示为加权总数的一小部分实例)max_leaf_nodes(叶节点的最大数量)max_features(在每个节点被评估是否分裂的时候,具有的最大特征数量)
增加min_开头的超参数或者减小max开头的超参数会让模型更正则化
还有一些其他的决策树算法采用后剪枝形式,先生成足够大的树,再删去一些不必要的节点
下图展示了正则化对决策边界的影响,左面显然是过拟合了。

回归
决策树也可以处理回归的问题
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)得到了一棵这样的树

可以看出,和分类相比,区别在于,不再最小化不纯度了,而是最小化MSE

直观的看,每一个子集的红线代表了value值,即这个子集的平均

同样,正则化可以带来帮助

不稳定性
决策树是一类非常强大的模型,但是也有一些局限性
首先,决策树的决策边界和坐标轴是垂直的,这样的性质导致对数据的旋转很敏感,如图,左右两个虽然都可以分割开,但是右面的泛化显然不如左边好(可以用PCA来解决这样的问题,见第八章)

其次,决策树对一些数据的微小变化可能非常敏感,一点点的区别可能导致决策边界截然不同的,而且,SKlearn中许多方法都有偶然性,除非设置了随机种子,这也会带来许多不稳定性。下一章中将会看到,随机森林可以通过多棵树的平均预测值限制这种不稳定性