自然语言处理实战——Pytorch实现基于LSTM的情感分析(LMDB)——详细
目录
1 一、实验过程
1.1 实验目的
1.2 实验简介
1.3 数据集的介绍
1.4 网络模型
1.5 实验步骤
1.5.1 导入实验所需要的库
1.5.2 数据预处理
1.5.3 构建网络
1.5.4 创建 Word2vec 模型
1.5.5 加载词向量
1.5.6 模型实例化
1.5.7 构建训练函数
1.5.8 结果可视化
代码实现
导入python工具库
数据预处理
文本过滤
读取数据
文本分词
统计单词和映射
文本映射编码
映射编码填充或裁剪
数据张量化
转为DataLoader
训练 Word2vec 模型
加载词向量
搭建网络
LSTM神经网络
GRU神经网络
构建训练函数
实例化模型
开始训练
数据集下载链接
上集回顾:
自然语言处理入门实战——基于循环神经网络RNN、LSTM、GRU的文本分类(超级详细,学不会找我!!!)_~北木南的博客-CSDN博客
1 一、实验过程
1.1 实验目的
通过这个课程项目大,期望达到以下目的:
- 1.了解如何对 自然语言处理 的数据集进行预处理操作。
- 2.初识自然语言数据集处理操作的步骤流程。
- 3.进一步学习双向LSTM、GRU神经网络的模型思想、网络架构和代码实现。
- 4.学习在自然语言处理领域中情感分析的任务实训。
- 5.掌握了如何在真实业务数据中,对社交网络文本执行情感分析。
1.2 实验简介
这个项目名称为“实现基于LSTM的情感分析”,并对测试集进行情感类别的预测。这个项目提供的数据集是IMDB Dataset (IMDB 数据集):IMDB 数据集包含用于自然语言处理或文本分析的 5 万条影评。这是用于二进制情绪分类的数据集,包括用于训练的 25,000 条观点鲜明的影评和用于测试的 25,000 条影评。 Sentiment Analysis 数据之间存在单词数量的差异具有一定的挑战性。实验采用最适合自然语言处理的双向循环神经网络LSTM、GRU模型。
情感分析是文本分类的一个分支,是对带有情感色彩(褒义贬义/正向负向)的主观性文本进行分析,以确定该文本的背后的主管观点、喜好与情感倾向。情感分析领域是由几个主要因素驱动的。首先,它是由在线内容的快速增长驱动的,这些内容被互联网企业用来理解和回应人们的感受。其次,由于情感驱动人类决策,了解客户情感的企业在预测和刺激购买决策上,将占据主动的优势。最后,随着近年来自然语言处理技术显著的进步,使得情感分析的应用更加广泛。
情感分析是实际上可以被归类为 文本分类 (文本挖掘) 的一种。在机器学习情感分析中,情感分析模型通常使用 监督性数据集 进行训练。监督性数据集是一种用目标变量标记的数据集,通常用列表示文本中的情感值。也就是我们想从文本中预测到的那些本来看不到的价值。
1.3 数据集的介绍
IMDB 数据集包含用于自然语言处理或文本分析的 5 万条影评。这是用于二进制情绪分类的数据集,包括用于训练的 25,000 条观点鲜明的影评和用于测试的 25,000 条影评。 train、test文件夹下都包含了pos(正面评论),neg(负面评论),这两个文件夹下各有12500个txt文本文件,记录了评论的内容。
1.4 网络模型
本次项目使用了2个网络模型,都属于RNN循环神经网络的范畴,分别是Lstm、GRU,因为LSTM和GRU是RNN比较著名的变形,更适合自然语言处理领域。下面依次简单介绍原理。
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种,和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。我们在实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
双向循环神经网络(BRNN)
RNN和LSTM、GRU都只能依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。BRNN有两个RNN上下叠加在一起组成的,输出由这两个RNN的状态共同决定。
对于每个时刻t,输入会同时提供给两个方向相反的RNN,输出由这两个单向RNN共同决定。
所谓的Bi-LSTM、Bi-GRU以及Bi-RNN,可以看成是两层神经网络,第一层从左边作为系列的起始输入,在文本处理上可以理解成从句子的开头开始输入,而第二层则是从右边作为系列的起始输入,在文本处理上可以理解成从句子的最后一个词语作为输入,反向做与第一层一样的处理处理。最后对得到的两个结果进行处理。
实验中设计的模型也比较简单,只用到了一层LSTM、GRU作为主要的数据处理,一个embedding来初始化模型权重参数,一层全连接层做最终的输出。输入层节点是字符总数500,隐藏层节点设置了100,以及输出层结点2(也就是类别数量)
1.5 实验步骤
基本流程:
1.5.1 导入实验所需要的库
os、numpy、pandas、matplotlib.pyplot、glob、ramdon、time、torch等必须python工具库。
1.5.2 数据预处理
- 定义一个文本过滤函数,实现文本的过滤功能,包括移除停用词,将标点符号和一些特殊符 替换 为空格,将文本切分成列表,然后进行词干提取【'a','about','above','after','again','against','ain','all','am','an','and','any','are','aren'...】
词干提取 (Stemming) 是英文语料预处理的其中一个必要步骤(中文不存在这个问题),因为英语单词在句子中使用时会转化成各种形式。 例如,单词 product 可能会转化为 production,或者转化为复数形式的 products。 playing, played, plays --> play play play 所以,有必要将这些词转换为它们的基本形式,因为它们在任何情况下都具有相同的含义。词干提取就是帮助我们这样做的过程。

文本过滤的效果如下例子:
-
读取数据并进行文本过滤操作。
-
文本分词,遍历数据集文本,执行分词操作,将每个数据样本的单词且分开了,存储在列表。

-
统计训练集文本单词数量,不需要统计测试集文本单词,为词表vocab中的每个单词一个数字标签,为每个数字赋一个单词。
-
将每个文本的分词列表中的单词映射为 单词的数字 列表。

-
对映射后的特征数字列表进行填充补齐到最大长度或裁剪到最大长度。

-
将数据进行独热编码转为Tensor张量,将数据集的分词列表进行数字映射和截取填充操作,并张量化。
-
转为DataLoader
下面展示了几个步骤的流程简单实例:

1.5.3 构建网络
- 构建双向LSTM神经网络,并测试
- 构建双向GRU神经网络,并测试
1.5.4 创建 Word2vec 模型
Word2vec 是一种有效创建词嵌入的方法,它自 2013 年以来就一直存在。但除了作为词嵌入的方法之外,它的一些概念已经被证明可以有效地创建推荐引擎和理解时序数据。在商业的、非语言的任务中。像 Airbnb、阿里巴巴、Spotify 这样的公司都从 NLP 领域中提取灵感并用于产品中,从而为新型推荐引擎提供支持。

利用训练数据train_tokenized,调用 Word2Vec 创建模型。
使用 model.train() 方法训练模型,包括 documents、total_examples 和 epoch 等参数。这里,
- documents: 指定要训练的句子,
- total_examples: 表示句子的计数,
- epochs: 表示对给定数据的总迭代次数
最后,将训练好的单词向量存储到模型中。
1.5.5 加载词向量
利用已经学好的word embedding 预训练数据 glove.6B.100d 、glove.6B.50d、my_glove.100d 【其中,6B表示词向量是在60亿规模的tokens上训练得到的,100d表示词向量是100维的。】
'''Glove的解析方式和word2vec是不一样的,所以要转换成word2vec才能用。'''
加载转化后的词向量文件
- 调用 wv.get_vector查看某个词向量
- wvmodel.get_vector('rose')
- 调用 wv.most_similar 查看关联相似的单词
- wvmodel.most_similar('rose')
初始化模型参数,也就是加载预训练词向量
1.5.6 模型实例化
为每个神经网络搭建三个实例,分别传入三种不同的词向量模型参数。
1.5.7 构建训练函数
- 为模型定义一个用于模型参数初始化、传入数据训练得到输出、计算损失值和模型参数更新的函数
- 开始训练
1.5.8 结果可视化
- 记录每轮训练损失
- 记录每轮测试损失
- 记录每轮训练准确率
- 记录每轮测试准确率
对记录的数据进行可视化:
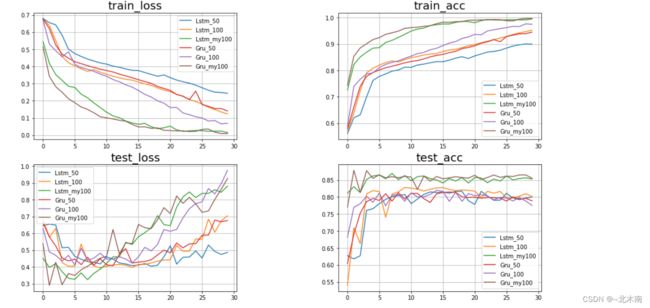
对于glove.6B.100d 、glove.6B.50d这两个词向量预训练模型,无论是LSTM,还是GRU最后的效果都差不多,而针对训练数据集进行搭建的my_glove.100d词向量预训练模型的效果会更好一些,所以说针对具体的任务场景设计具体符合现实的模型就显得非常有必要,所谓具体情况具体分析,需要针对具体任务来设计模型,提高模型性能。
代码实现
导入python工具库
# coding: utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data.dataloader as dataloader
import torch.optim as optim
import torch.autograd as autograd
import torchtext.vocab as torchvocab
from torch.autograd import Variable
import tqdm
import os
import time
import re
import pandas as pd
import string
import gensim
import time
import random
import snowballstemmer # 词干提取算法的最佳实践的选择 【 nltk库:Porter、Snowball、Lancaster 】
import collections
from collections import Counter
from nltk.corpus import stopwords
from itertools import chain
from sklearn.metrics import accuracy_score
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
# cpu or gpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))
print(gensim.__version__)数据预处理
文本过滤
'''
对文本内容进行过滤 *text:文本
'''
def clean_text(text):
## 将文本转为小写并拆分单词, 【列表】
text = text.lower().split()
# 停用词 【'a','about','above','after','again','against','ain','all','am','an','and','any','are','aren'...】
stops = set(stopwords.words("english"))
# 将停用词从文本列表终移除
text = [w for w in text if not w in stops and len(w) >= 3]
# 重新连成文本
text = " ".join(text)
# 文本特殊清洗,将标点符号和一些特殊符 替换 为空格
text = re.sub(r"[^A-Za-z0-9^,!.\/'+-=]", " ", text)
text = re.sub(r"what's", "what is ", text)
text = re.sub(r"\'s", " ", text)
text = re.sub(r"\'ve", " have ", text)
text = re.sub(r"n't", " not ", text)
text = re.sub(r"i'm", "i am ", text)
text = re.sub(r"\'re", " are ", text)
text = re.sub(r"\'d", " would ", text)
text = re.sub(r"\'ll", " will ", text)
text = re.sub(r",", " ", text)
text = re.sub(r"\.", " ", text)
text = re.sub(r"!", " ! ", text)
text = re.sub(r"\/", " ", text)
text = re.sub(r"\^", " ^ ", text)
text = re.sub(r"\+", " + ", text)
text = re.sub(r"\-", " - ", text)
text = re.sub(r"\=", " = ", text)
text = re.sub(r"'", " ", text)
text = re.sub(r"(\d+)(k)", r"\g<1>000", text)
text = re.sub(r":", " : ", text)
text = re.sub(r" e g ", " eg ", text)
text = re.sub(r" b g ", " bg ", text)
text = re.sub(r" u s ", " american ", text)
text = re.sub(r"\0s", "0", text)
text = re.sub(r" 9 11 ", "911", text)
text = re.sub(r"e - mail", "email", text)
text = re.sub(r"j k", "jk", text)
text = re.sub(r"\s{2,}", " ", text)
## 再次将文本切分成列表,然后进行词干提取
text = text.split()
'''2.7
词干提取 (Stemming) 是英文语料预处理的其中一个必要步骤(中文不存在这个问题),因为英语单词在句子中使用时会转化成各种形式。
例如,单词 product 可能会转化为 production,或者转化为复数形式的 products。
playing, played, plays --> play play play
所以,有必要将这些词转换为它们的基本形式,因为它们在任何情况下都具有相同的含义。词干提取就是帮助我们这样做的过程。
'''
stemmer = snowballstemmer.stemmer('english') # 定义词干提取为 snowball,语言为英文
stemmed_words = [stemmer.stemWord(word) for word in text] # 遍历每个单词执行词干提取操作
# 重新连成文本
text = " ".join(stemmed_words)
return text
# 函数测试
if __name__ == '__main__':
path ='/kaggle/input/lmdbsentimentclassification/aclImdb/aclImdb/train/pos/0_9.txt'
with open(path, 'r', encoding='utf8') as rf: # 读取文本
test_text = rf.read().replace('\n', '')
cleaned_test_text = clean_text(test_text) # 对文本进行过滤
print('\n原始的文本:', test_text, '\n')
print('过滤后文本:', cleaned_test_text)
读取数据
'''
读取文本数据并进行过滤
'''
def readIMDB(path, seg='train'):
pos_or_neg = ['pos', 'neg'] # 对应两个类文件夹
data = [] # 存放数据
for label in pos_or_neg: # 遍历两个类文件夹
files = os.listdir(os.path.join(path, seg, label)) # 返回每个类文件夹下的所有txt文件路径
for file in files: # 遍历所有txt文件,读取文本内容
with open(os.path.join(path, seg, label, file), 'r', encoding='utf8') as rf:
review = rf.read().replace('\n', '')
review = clean_text(review) # 对文本内容进行过滤操作
if label == 'pos':
data.append([review, 1]) # 每条数据包含文本内容和标签
elif label == 'neg':
data.append([review, 0])
return data
# 读取
root = '/kaggle/input/lmdbsentimentclassification/aclImdb/aclImdb'
train_data = readIMDB(root)
test_data = readIMDB(root, 'test')
# 训练、测试数据的长度
len(train_data), len(test_data)
#(25000, 25000)文本分词
'''传入文本,进行文本分词函数'''
def tokenizer(text):
return [tok.lower() for tok in text.split(' ')]
train_tokenized = [] # 存储训练数据的文本分词
test_tokenized = [] # # 存储测试数据的文本分词
# 遍历训练数据集文本,执行分词操作
for review, score in train_data:
train_tokenized.append(tokenizer(review))
# 遍历测试集文本,执行分词操作
for review, score in test_data:
test_tokenized.append(tokenizer(review))
print(len(tokenizer(cleaned_test_text)))
print("训练样本一分词结果:\n", tokenizer(cleaned_test_text))
# 验证是否存在数据丢失
len(train_tokenized), len(test_tokenized)
#(25000, 25000)统计单词和映射
# 统计训练集文本单词数量,不需要统计测试集文本单词
vocab = set(chain(*train_tokenized))
vocab_size = len(vocab)
print('词汇量: ',vocab_size)
# 词汇量: 54253
# 为词表vocab中的每个单词映射一个数字标签
word_to_idx = {word: i+1 for i, word in enumerate(vocab)}
word_to_idx[''] = 0
# 为每个数字映射一个单词
idx_to_word = {i+1: word for i, word in enumerate(vocab)}
idx_to_word[0] = ''
len(word_to_idx) # 因为多了一个 : 0
#54254 文本映射编码
'''
将每个文本的分词列表中的单词映射为 单词的数字 列表
*tokenized_samples: 文本分词列表
*vocab: 词汇表
'''
def encode_samples(tokenized_samples, vocab):
features = [] # 存储映射后的特征数字列表
for sample in tokenized_samples: # 遍历所有文本样本的分词列表
feature = []
for token in sample: # 遍历某个样本的分词列表
if token in word_to_idx: # 如果该单词在词汇表,匹配相对应的数字映射
feature.append(word_to_idx[token])
else:
feature.append(0) # 不存在则为0
features.append(feature)
return features
# 测试
test_text_features = encode_samples([tokenizer(cleaned_test_text)], vocab)
print(len(test_text_features[0]))
print('训练样本一映射编码结果:\n', test_text_features[0])
映射编码填充或裁剪
'''
对映射后的特征数字列表进行填充补齐到最大长度
*features:文本数据映射为特征数字的列表
*maxlen:填充到最大长度
*PAD:用于填充的值
'''
def pad_samples(features, maxlen=500, PAD=0):
padded_features = [] # 存储填充后的数据
for feature in features: # 遍历每个样本的特征数字列表,进行操作
if len(feature) >= maxlen: # 超出最大长度则截取最大长度前面的
padded_feature = feature[:maxlen]
else:
padded_feature = feature # 不足则填充到最大长度
while(len(padded_feature) < maxlen):
padded_feature.append(PAD)
padded_features.append(padded_feature)
return padded_features
# 测试
test_text_pad_samples = pad_samples(test_text_features, 500, 0)
print('训练样本一映射编码填充结果:\n', test_text_pad_samples, len(test_text_pad_samples[0]))
数据张量化
# 将数据集的分词列表进行数字映射和截取填充操作,并张量化
train_features = torch.tensor(pad_samples(encode_samples(train_tokenized, vocab)))
train_labels = torch.tensor([score for _, score in train_data])
test_features = torch.tensor(pad_samples(encode_samples(test_tokenized, vocab)))
test_labels = torch.tensor([score for _, score in test_data])
# 验证数据有无丢失
train_features.shape, train_labels.shape, test_features.shape, test_labels.shape
'''
(torch.Size([25000, 500]),
torch.Size([25000]),
torch.Size([25000, 500]),
torch.Size([25000]))
'''转为DataLoader
# 转为DataLoaders数据
batch_size = 64
# Dataset
train_set = torch.utils.data.TensorDataset(train_features, train_labels)
test_set = torch.utils.data.TensorDataset(test_features, test_labels)
# DataLoader
train_iter = torch.utils.data.DataLoader(train_set, batch_size=batch_size,shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set, batch_size=batch_size,shuffle=False)
# 验证数据有无丢失
len(train_set), len(test_set), device, len(train_iter), len(test_iter)训练 Word2vec 模型
from gensim.models import Word2Vec
# 参数说明
my_glove_100 = Word2Vec(train_tokenized, # 提供给类的语料库
size=100, # 每个标记的密集向量的长度
min_count=2, # 训练特定模型时可以考虑的最小单词数
workers=1) # 训练模型时所需的线程数
my_glove_100.train(train_tokenized, total_examples=len(train_tokenized), epochs=50)
path = r'/kaggle/working/glove_my.100d.txt'
my_glove_100.wv.save_word2vec_format(path)加载词向量
'''
利用已经学好的word embedding 预训练数据 glove.6B.100d 、glove.6B.50d.txt、glove_my.100d.txt
【其中,6B表示词向量是在60亿规模的tokens上训练得到的,100d表示词向量是100维的。】
'''
# 输入文件,也有一个词维度是50的glove.6B.100d.txt模型
glove_file_50 = datapath(r'/kaggle/input/lmdbsentimentclassification/glove.6B.50d.txt')
glove_file_100 = datapath(r'/kaggle/input/lmdbsentimentclassification/glove.6B.100d.txt')
my_glove_file_100 = datapath(r'/kaggle/working/glove_my.100d.txt')
# 输出文件
tmp_file_50 = get_tmpfile(r'/kaggle/working/wv.6B.50d.txt')
tmp_file_100 = get_tmpfile(r'/kaggle/working/wv.6B.100d.txt')
my_tmp_file_100 = get_tmpfile(r'/kaggle/working/wv_my.100d.txt')
# 开始转换
'''Glove的解析方式和word2vec是不一样的,所以要转换成word2vec才能用。'''
from gensim.scripts.glove2word2vec import glove2word2vec
# 加载转化后的词向量文件
glove2word2vec(glove_file_50, tmp_file_50)
wvmodel_50 = KeyedVectors.load_word2vec_format(tmp_file_50)
glove2word2vec(glove_file_100, tmp_file_100)
wvmodel_100 = KeyedVectors.load_word2vec_format(tmp_file_100)
glove2word2vec(my_glove_file_100, my_tmp_file_100)
my_wvmodel_100 = KeyedVectors.load_word2vec_format(my_glove_file_100)
def load_weight(wvmodel, embed_size):
# 初始化参数 (54254, 100)
weight = torch.zeros(vocab_size+1, embed_size)
# 加载将预训练的词向量wvmodel作为参数,就是将词向量复制到参数weight上作为模型初始权重参数
# 也可以调用pytorch方法:self.embedding.weight.data.copy_(torch.from_numpy(embeding_vector))
for i in range(len(wvmodel.index2word)):
try:
index = word_to_idx[wvmodel.index2word[i]]
except:
continue
weight[index, :] = torch.from_numpy(wvmodel.get_vector(
idx_to_word[word_to_idx[wvmodel.index2word[i]]]))
return weight
# 加载预训练词向量
weight_50 = load_weight(wvmodel_50, 50)
weight_100 = load_weight(wvmodel_100, 100)
my_weight_100 = load_weight(my_wvmodel_100, 100)
len(wvmodel_50.index2word), len(wvmodel_100.index2word), len(my_wvmodel_100.index2word)搭建网络
LSTM神经网络
'''
搭建双向LSTM网络,使用预训练词向量作为参数
*vocab_size: 数据集的词汇量
*embed_size: 词维度
*num_hiddens: 隐藏层张量的最后一个维度
*num_layers: LSTM网络的层数
*bidirectional: 是否使用双向LSTM
*weight: 词向量参数
*labels: 分类数
*use_gpu: 使用GPU
'''
class SentimentLSTM_Net(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
bidirectional, weight, labels, use_gpu, **kwargs):
super(SentimentLSTM_Net, self).__init__(**kwargs)
self.num_hiddens = num_hiddens # 隐藏层输出节点维度
self.num_layers = num_layers # LSTM的网络层数
self.use_gpu = use_gpu # 使用GPU
self.bidirectional = bidirectional # 是否双向LSTM
# 使用预训练的词向量作为参数
self.embedding = nn.Embedding.from_pretrained(weight)
# 在反向传播的时候, 不对这些词向量进行求导更新, 默认是为True的
self.embedding.weight.requires_grad = False
self.encoder = nn.LSTM(input_size=embed_size, hidden_size=self.num_hiddens,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=0)
# 是否使用双向的LSTM
if self.bidirectional:
self.decoder = nn.Linear(num_hiddens * 4, labels) # 全连接层
else:
self.decoder = nn.Linear(num_hiddens * 2, labels)
def forward(self, inputs):
embeddings = self.embedding(inputs)
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
encoding = torch.cat([states[0], states[-1]], dim=1)
outputs = self.decoder(encoding)
return outputs
if __name__ == '__main__':
feature = torch.randint(0, 54254, size=(5,500)) # 生成随机样本
weight = torch.randn(54254, 100) # 初始化参数
test_LSTM_net = SentimentLSTM_Net(vocab_size=54254, embed_size=100,
num_hiddens=100, num_layers=2,
bidirectional=True, weight=weight,
labels=2, use_gpu=True)
out = test_LSTM_net(feature)
print(out)GRU神经网络
'''
搭建双向GRU网络,使用预训练词向量作为参数
*vocab_size: 数据集的词汇量
*embed_size: 词维度
*num_hiddens: 隐藏层张量的最后一个维度
*num_layers: LSTM网络的层数
*bidirectional: 是否使用双向LSTM
*weight: 词向量参数
*labels: 分类数
*use_gpu: 使用GPU
'''
class SentimentGRU_Net(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
bidirectional, weight, labels, use_gpu, **kwargs):
super(SentimentGRU_Net, self).__init__(**kwargs)
self.num_hiddens = num_hiddens # 隐藏层输出节点维度
self.num_layers = num_layers # GRU的网络层数
self.use_gpu = use_gpu # 使用GPU
self.bidirectional = bidirectional # 是否双向GRU
# 使用预训练的词向量作为参数
self.embedding = nn.Embedding.from_pretrained(weight)
# 在反向传播的时候, 不对这些词向量进行求导更新, 默认是为True的
self.embedding.weight.requires_grad = False
self.encoder = nn.GRU(input_size=embed_size, hidden_size=self.num_hiddens,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=0)
# 是否使用双向的LSTM
if self.bidirectional:
self.decoder = nn.Linear(num_hiddens * 4, labels) # 全连接层
else:
self.decoder = nn.Linear(num_hiddens * 2, labels)
def forward(self, inputs):
embeddings = self.embedding(inputs)
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
encoding = torch.cat([states[0], states[-1]], dim=1)
outputs = self.decoder(encoding)
return outputs
# 网络测试
if __name__ == '__main__':
test_GRU_net = SentimentGRU_Net(vocab_size=54254, embed_size=100,
num_hiddens=100, num_layers=2,
bidirectional=True, weight=weight,
labels=2, use_gpu=True)
out = test_GRU_net(feature)
print(out)构建训练函数
def train(net, net_name):
print('\n===================={}开始训练==================='.format(net_name))
# 定义损失函数
loss_function = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(net.parameters(), lr=lr)
train_loss_list = [] # 记录每轮训练损失
test_loss_list = [] # 记录每轮测试损失
train_acc_list = [] # 记录每轮训练准确率
test_acc_list = [] # 记录每轮测试准确率
for epoch in tqdm(range(num_epochs)):
start = time.time() # 记录训练时间
train_loss, test_losses = 0, 0
train_acc, test_acc = 0, 0
n, m = 0, 0
print('train:', end='')
for feature, label in train_iter:
n += 1
if n%40==0:
print('.', end='')
net.zero_grad()
# variable默认是不需要被求导的,即requires_grad属性默认为False
# Variable是Torch里的一种数据类型,他与tensor没有什么很大的区别,但是他们属于不同的数据类型
feature = Variable(feature.to(device))
label = Variable(label.to(device))
score = net(feature) # 传入模型
loss = loss_function(score, label) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化
train_acc += accuracy_score(torch.argmax(score.cpu().data, dim=1), label.cpu())
train_loss += loss
train_loss_list.append(train_loss.item()/n)
train_acc_list.append(train_acc.item()/n)
print("--test:", end='')
with torch.no_grad():
for test_feature, test_label in test_iter:
m += 1
if m%40==0:
print('.', end='')
test_feature = test_feature.to(device)
test_label = test_label.to(device)
test_score = net(test_feature) # 传入模型
test_loss = loss_function(test_score, test_label) # 计算损失
test_acc += accuracy_score(torch.argmax(test_score.cpu().data, dim=1), test_label.cpu()) # 累加正确预测
test_losses += test_loss # 累加损失
test_loss_list.append(test_losses.item()/m)
test_acc_list.append(test_acc.item()/m)
end = time.time()
runtime = end - start
print('epoch: %d, train loss: %.4f, train acc: %.2f, test loss: %.4f, test acc: %.2f, time: %.2f' %
(epoch, train_loss.data / n, train_acc / n, test_losses.data / m, test_acc / m, runtime))
return train_loss_list, train_acc_list, test_loss_list, test_acc_list实例化模型
# 设置超参数
num_epochs = 30
embed_size = 100 # 词向量长度
num_hiddens = 100 # 隐藏层输出节点
num_layers = 2 # Lstm网络层数
bidirectional = True # 是否双向LSTM
labels = 2
lr = 0.8
use_gpu = True
# 实例化模型
# Lstm - weight_50
Lstm_50 = SentimentLSTM_Net(vocab_size=(vocab_size+1), embed_size=50, num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=weight_50,labels=labels, use_gpu=use_gpu)
# Lstm - weight_100
Lstm_100 = SentimentLSTM_Net(vocab_size=(vocab_size+1), embed_size=100, num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=weight_100,labels=labels, use_gpu=use_gpu)
# Lstm - my_weight_100
Lstm_my100 = SentimentLSTM_Net(vocab_size=(vocab_size+1), embed_size=100, num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=my_weight_100,labels=labels, use_gpu=use_gpu)
# Gru - weight_50
Gru_50 = SentimentGRU_Net(vocab_size=(vocab_size+1), embed_size=50, num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=weight_50,labels=labels, use_gpu=use_gpu)
# Gru - weight_100
Gru_100 = SentimentGRU_Net(vocab_size=(vocab_size+1), embed_size=100, num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=weight_100,labels=labels, use_gpu=use_gpu)
# Gru - my_weight_100
Gru_my100 = SentimentGRU_Net(vocab_size=(vocab_size+1), embed_size=100, num_hiddens=num_hiddens, num_layers=num_layers,
bidirectional=bidirectional, weight=my_weight_100,labels=labels, use_gpu=use_gpu)
Lstm_50.to(device)
Lstm_100.to(device)
Lstm_my100.to(device)
Gru_50.to(device)
Gru_100.to(device)
Gru_my100.to(device)
Lstm_50,Lstm_100,Lstm_my100, Gru_50,Gru_100,Gru_my100开始训练
# 记录
train_loss_list = [] # 记录每轮训练损失
test_loss_list = [] # 记录每轮测试损失
train_acc_list = [] # 记录每轮训练准确率
test_acc_list = [] # 记录每轮测试准确率
nets = [Lstm_50, Lstm_100, Lstm_my100, Gru_50, Gru_100, Gru_my100]
nets_name = ['Lstm_50','Lstm_100','Lstm_my100', 'Gru_50','Gru_100','Gru_my100']
for i in range(len(nets)):
train_loss, train_acc, test_loss, test_acc = train(nets[i], nets_name[i])
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
test_loss_list.append(test_loss)
test_acc_list.append(test_acc)result_data = [train_loss_list, train_acc_list, test_loss_list, test_acc_list]
result_data_name = ["train_loss", "train_acc", "test_loss", "test_acc"]
plt.figure(figsize=(16,9))
for i in range(4):
plt.subplot(2, 2, i+1)
for j in range(6):
plt.plot(range(num_epochs), result_data[i][j])
plt.title(result_data_name[i], fontsize=20)
plt.legend(nets_name)
plt.grid(True)
plt.subplots_adjust(wspace=0.5)

如果对你有帮助,点个三连+关注吧,谢谢老板!
数据集下载链接
https://www.kaggle.com/datasets/zybmnb/lmdbsentimentclassification