MySQL大杂烩
用户手册
mysql8.0:https://dev.mysql.com/doc/refman/8.0/en/preface.html
mysql5.7:https://dev.mysql.com/doc/refman/5.7/en/
mysql层级架构介绍
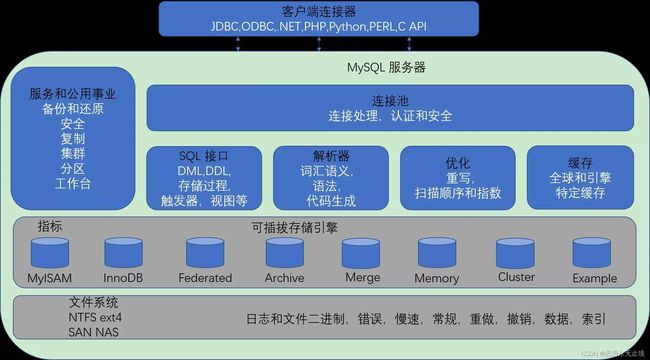
1.连接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2.服务层
第二层架构主要完成大多少的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是 select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3.引擎层
存储引擎层,存储引擎真正的负责了 MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。
4.存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
mysql存储引擎
查看数据库有哪些引擎
show engines;
查看当前默认的引擎
show variables like '%storage_engine%';
InnoDB
支持事务,支持行锁,支持外键,性能一般。
支持行锁,操作一行数据只会锁定单行,不会锁定整个表,适合高并发操作。
不仅缓存索引,也缓存真实数据,对内存要求较高,内存大小对性能有决定性影响。
一文了解InnoDB存储引擎:https://zhuanlan.zhihu.com/p/47581960/
MyISAM
不支持事务,不支持行锁,不支持外键,性能极佳。
支持表锁,操作一行数据会锁定整个表,不适合高并发操作。
只缓存索引,不缓存数据。
其他引擎
MERGE、MEMORY(HEAP)、BDB(BerkeleyDB)、EXAMPLE、FEDERATED、ARCHIVE、CSV、BLACKHOLE。
不用关系,一般都用不上。
安装
centos7安装mysql8
卸载mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64#改成上面命令的结果,有多个就卸载多个

安装方法1
下载
https://dev.mysql.com/downloads/mysql/

找到列表里的:RPM Bundle(mysql-8.0.30-1.el7.x86_64.rpm-bundle.tar),点击Download
然后点击下面的No thanks, just start my download.
上传
将下载后的tar压缩包上传到centos的当前工作目录或者随便新建一个目录。
解压
tar -xvf mysql-8.0.30-1.el7.x86_64.rpm-bundle.tar
安装
rpm -ivh mysql-community-common-8.0.30-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-libs-8.0.30-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-client-8.0.30-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-server-8.0.30-1.el7.x86_64.rpm --nodeps --force
查看是否安装成功
rpm -qa | grep mysql
初始化mysql
mysqld --initialize
启动mysqld服务,后续步骤请看下面方法2的启动mysqld服务。
安装方法2:
http://repo.mysql.com/
在浏览器搜索el7,el7对应的是小红帽的linux7(Red Hat Enterprise Linux7),centos7基于小红帽的linux7。
要下载mysql8的就下载mysql80开头的,要下载mysql5的就下载mysql57开头的。
找到后,右键复制链接。
下载:
把刚刚复制的链接在linux上用wget下载。
wget http://repo.mysql.com/mysql80-community-release-el7.rpm
安装1:
rpm -ivh mysql80-community-release-el7.rpm
查看下:
ls -1 /etc/yum.repos.d/mysql-community*
安装2:
yum install mysql-server
出现错误
获取 GPG 密钥失败:[Errno 14] curl#37 - "Couldn't open file /etc/pki/rpm-gpg/RPM-GPG-KEY-mysql-2022"
别慌,是mysql的yum源开启了GPG校验,关掉就好,vi /etc/yum.repos.d/mysql-community.repo
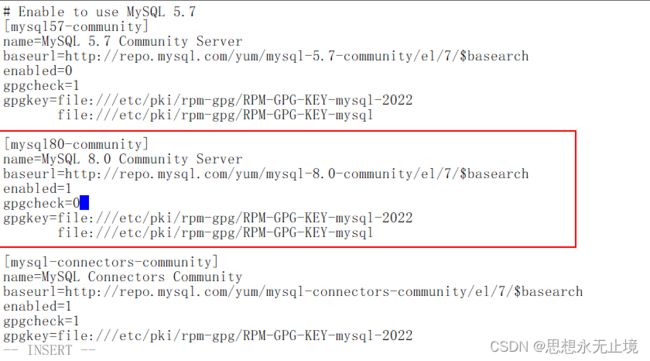
basearch下的将gpgcheck改成0然后保存。
安装3,继续安装
yum install mysql-server
启动mysqld服务
systemctl start mysqld
不是mysql服务是mysqld
登录mysql
mysql -u root -p
哈哈,是不是发现要密码?
登录方式一、获取root临时密码后登录
grep 'temporary password' /var/log/mysqld.log
登录方式二、免密登录,此方法被证明不好使,虽然能登录进去,但是不能修改密码
先停下服务
systemctl stop mysqld
修改my.cnf
vi /etc/my.cnf
找到[mysqld],在下面新增一行:skip_grant_tables=1,然后保存。
启动服务
systemctl start mysqld
再次登录mysql
mysql #不用输-u,直接进
修改root密码
ALTER user 'root'@'localhost' IDENTIFIED BY 'ABcd123456@';//密码太简单会报错Your password does not satisfy the current policy requirements
flush privileges;
卸载mysql
查看有哪些mysql软件包:
rpm -qa | grep mysql
卸载(具体卸载哪些,看你前面的rpm -qa | grep mysql的输出结果):
rpm -e --nodeps mysql-community-common-8.0.30-1.el7.x86_64
rpm -e --nodeps mysql-community-libs-8.0.30-1.el7.x86_64
rpm -e --nodeps mysql-community-server-8.0.30-1.el7.x86_64
rpm -e --nodeps mysql-community-client-8.0.30-1.el7.x86_64
rpm -e --nodeps mysql-community-client-plugins-8.0.30-1.el7.x86_64
rpm -e --nodeps mysql80-community-release-el7-6.noarch
rpm -e --nodeps mysql-community-icu-data-files-8.0.30-1.el7.x86_64
查看有哪些残留文件:
find / -name mysql
删除(具体删除哪些,看你前面的find / -name mysql的输出结果):
rm -rf /etc/selinux/targeted/active/modules/100/mysql
rm -rf /etc/selinux/targeted/tmp/modules/100/mysql
rm -rf /var/lib/mysql
rm -rf /var/lib/mysql/mysql
rm -rf /usr/lib64/mysql
rm -rf /usr/local/mysql
可以将上述命令用windows改好,存为卸载mysql.sh,然后上传到centos,运行sh 卸载mysql.sh。
多主多从配置
我也不会啊。
分享两个网上看到的:
mysql多主多从配置:https://blog.csdn.net/wn_96/article/details/124275272
shardingsphere多主多从配置https://www.cnblogs.com/java5wanping/p/16194529.html
docker 安装mysql
https://blog.csdn.net/u012643122/article/details/125899829
mysql5安装
和mysql8的区别:
mysql5启动mysql服务,mysql8启动mysqld服务。
mysql设置密码方式为:/usr/bin/mysqladmin -u root password 123456
linux下mysql相关目录介绍
| 路径 | 解释 | 备注 |
|---|---|---|
| /var/lib/mysql/ | mysql数据库文件的存放路径 | /var/lib/mysql/atguigu.cloud.pid |
| /usr/share/mysql | 配置文件目录 | mysql server命令及配置文件 |
| /usr/bin | 相关命令目录 | mysqladmin mysqldump等命令 |
| /etc/init.d/mysql | 启停相关脚本 |
在linux下查看安装目录ps -ef | grep mysql
mysql默认配置文件
5.5默认在/usr/share/mysql/my-huge.cnf(但并不生效,mysql并不加载这个位置的配置文件) ,需要拷贝至/etc/my.cnf。
5.6默认在/usr/share/mysql/my-default.cnf(但并不生效,mysql并不加载这个位置的配置文件) ,需要拷贝至/etc/my.cnf。
文件介绍
5.x版本
目录:/var/lib/mysql/data/数据库名称
frm文件:存放表结构
myd文件:存放表数据
myi文件:存放表索引
8.x版本
目录:/var/lib/mysql/数据库名称
ibd文件:存放表结构,存放表数据,存放表索引
开启远程访问
linux防火墙
首先先检测linux防火墙是不是开启的,如果是开启的,看见有没有将3306端口拦截,看看有没有将远程ip拦截。
#查看已经开放的端口号
firewall-cmd--list-all
# 将3306端口公开
# --permanent 永久生效,没有此参数重启后失效
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd-reload
或者根据需要关闭防火墙也可以的。
systemctl stop firewalld
mysql配置
看下my.cnf里有没有bind_address和skip_networking,有的话将这两个直接注释万事大吉。
bind_address释义:mysql绑定至该ip,只能由这个ip地址的客户端登录。
skip_networking释义:mysql只接受unix socket而不能提供tcp socket服务。
用户权限问题
mysql每个用户账号在创建时必须绑定一个ip,包括root,默认是localhost。
我们可是使用以下语句进行查询用户的ip:
select user,host,authentication_string from mysql.user where user='root';
如果将其设置为%,表示不绑定任何IP,该用户可以在任意ip的客户端进行登录。
为了保持用户可以远程登录,需要修改用户的host:
update mysql.user set host='%' where user='root';
flush privileges;
mysql基础配置
开启错误日志
记录严重的警告和错误信息,每次启动和关闭的详细信息等,默认关闭。
#格式
#log-error=文件绝对路径
#示例
log-error=D://mysql/log/error-log
开启数据日志
可用于主从同步、数据恢复。
#格式
#log-bin=文件绝对路径
#示例
log-bin=D://mysql/log/bin-log
开启查询日志
记录查询的sql语句,默认关闭,如果开启会降低mysql的整体性能,因为记录日志也是需要消耗系统资源的。
general_log=ON #或者general_log=1。1、ON表示开启,0、OFF表示关闭。
general_log_file=D://mysql/log/general_log.log
开启主从复制
主从复制基本原理
MySQL复制过程分成三步:
1 master将改变记录到二进制日志( binary log)。这些记录过程叫做二进制日志事件, binary log events;
2 slave将 master的 binary log events拷贝到它的中继日志( relay log);
3 slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的
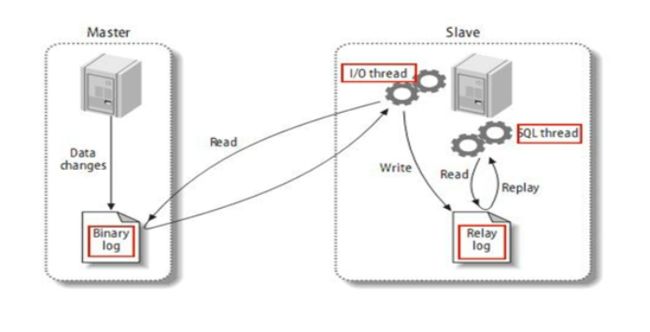
主从复制基本规则
每个 slave只有一个 master
每个 slave只能有一个唯一的服务器ID
每个 master可以有多个 salve
主从复制基本环境
主从数据库版本一致。
主从数据库的网络可互通。
master上创建一个专门用于主从复制的账号。
/*创建slave用户,不绑定IP(@'%'),密码为123456*/
create user 'slave'@'%' identified by '123456';
/*将replication slave权限和replication client权限授予slave用户,不限IP(@'%'),不限库(on *.*),不限表(on *.*)*/
grant replication slave,replication client on *.* to 'slave'@'%';
#或者 grant replication slave,replication client on *.* to 'slave'@'从数据库slave的主机地址';
主从复制基本流程
master:
1(必须).在master的配置文件的[mysqld]下新增一行:server_id=1。
server_id,服务ID,在数据库集群中需要唯一,建议master设置为1,其他slave用,2,3之类往后排。
2(必须).启用master的log-bin,log-bin=D: /install/mysql/data/mysqlbin。
log-bin,二进制日志记录,数据库所有的增删改和表结构变动都会被记录到这里。
3(可选).启用master的log-err,log-err=D: /install/mysql/data/mysqlerr。
log-err,如果主从复制发生错误,将记录错误
4(可选).设置master的basedir,basedir=D: /install/mysql/。
basedir,指定了安装 MySQL 的安装路径,填写全路径可以解决相对路径所造成的问题。
5(可选).设置master的tmpdir,basedir=D: /install/mysql/data/tempdata/。
tmpdir,临时目录用于存储临时文件或临时表。若临时目录不存在或权限不正确不仅会引起MySQL启动失败还会导致其他可能使用到临时目录的MySQL实用程序运行异常。
6(可选).设置master的datadir,datadir=D: /install/mysql/data/。
datadir,指定表库文件的存放目录。
7(可选).设置master的read-only=0,让主库可读可写。
read-only,设置数据库是否只读,0非只读,1是只读。
8(可选).设置master的binlog- ignore-db,binlog- ignore-db=mysql。
binlog- ignore-db,二进制日志(log-bin)开启后需要忽略的数据库,设置后该库将不产生二进制日志(log-bin)。
9(可选).设置master的binlog-do-db,binlog- do-db=xxxx。
binlog-do-db,二进制日志(log-bin)开启后需要记录的数据库,设置后该库将只有该库产生二进制日志(log-bin)。
10(必须).重启mysql服务
11(必须).查看master数据库的bin-log相关信息,show master status,备用。
12(可选).不要再操作master数据库,防止Position和File字段发生变化,如果发生变化,slave那边又得重新change master。
slave:
1(必须).在slave的配置文件的[mysqld]下新增一行:server_id=2。
2(必须).启用slave的log-bin,log-bin=/mysql/data/mysqlbin。
3(可选).启用slave的log-err,log-err=/mysql/data/mysqlerr。
4(可选).设置slave的slave_skip_errors,slave_skip_errors=1062。
slave_skip_errors,跳过主从复制中遇到的所有错误或者指定类型的错误,避免slave端的复制中断。如1062错误是指一些主键重复,1032错误是指主从数据库的数据不一致。
5(可选).设置slave的relay_log,relay_log=/mysql/data/relaylog。
relay_log,配置中继日志
6(可选).设置slave的og_slave_updates,log_slave_updates=1。
log_slave_updates,将复制事件写入自己的二进制日志
7(可选).设置slave的read-only=1,让从库只读。
8(可选).设置slave的binlog- ignore-db,binlog- ignore-db=mysql。
9(必须).重启mysql服务
10(必须).让slave主动认master,change master。
change master to master_host='172.17.0.2',master_user='slave',master_password='123456',master_port=3306,master_log_file='mall-mysql-bin.000001',master_log_pos=157,master_connect_retry=30;
字段解释:
master_host=master主机地址
master_port=master的服务端口号
master_user=master中用于主从同步的账号
master_password=master中用于主从同步的账号密码
master_log_file=master中show master status的File字段。
master_log_pos=master中show master status的Position字段。
master_connect_retry=从数据库连接主数据库失败时,重新尝试连接的间隔时间,单位秒
11(必须).开始同步,start slave;
12(可选).查看同步是否成功,show slave status \G;,\G只是用键值对格式输出结果,方便查看数据。
SQL语句
unin
将两个select结果集合并成一个结果集,并自动去除重复。
如果列数和列类型不匹配则报错。
unin all
同unin,但不会去重。
not like
反向like,如果,like '张%'是查询所有姓张的人,那not like '张%'就是查询所有不姓张的人。
基本操作1
MySQL创建用户和授权
https://blog.csdn.net/u012643122/article/details/52643715
MySQL建库建表和修改表结构
https://blog.csdn.net/u012643122/article/details/49052381
MySQL查看表结构
https://blog.csdn.net/u012643122/article/details/44039155
MySQL索引相关
https://blog.csdn.net/u012643122/article/details/52890772
数据库事务
https://blog.csdn.net/u012643122/article/details/92836000
数据库锁
https://blog.csdn.net/u012643122/article/details/126459617
基本操作2
MySQL导入和导出
https://blog.csdn.net/u012643122/article/details/125882337
MySQL数据类型
https://blog.csdn.net/u012643122/article/details/47368237
MySQL编码设置
https://blog.csdn.net/u012643122/article/details/46799943
MySQL大小写问题
https://blog.csdn.net/u012643122/article/details/46819825
拓展操作1
MySQL函数和存储过程
MySQL函数和存储过程:https://blog.csdn.net/u012643122/article/details/52813495
MySQL常用内置函数:https://blog.csdn.net/u012643122/article/details/104838695
MySQL获取汉字的拼音首字母
https://blog.csdn.net/u012643122/article/details/49308109
百万级别的数据如何做分页查询
mysql在数据量大的情况下分页查询,页数越大,查询越慢。
大分页慢的原因是没有使用到索引,而是全表扫描(即使添加了索引也没用):
MySQL数据库的查询优化器是采用了基于代价的,而查询代价的估算是基于CPU代价和IO代价。
如果MySQL在查询代价估算中,认为全表扫描方式比走索引扫描的方式效率更高的话,就会放弃索引,直接全表扫描。
这就是为什么在大分页的SQL查询中,明明给该字段加了索引,但是MySQL却走了全表扫描的原因。
解决方法:
使用连表查询进行优化:
结构:
select 查询的列写这里 from 表名 as t1
inner join (
select id from 表名 as t3 where 查询条件写这里 order by 排序写这里 limit 分页写这里
) as t2 on t1.id=t2.id;
示例:
select a.* from test_user a
inner join (
select id from test_user where text like 'text%' order by text limit 1000000, 10
) b on a.id=b.id;
MySQL问题排查,SQL优化
问题排查
出现性能下降SQL慢、执行时间长、等待时间长时,需要排查分析是哪里出现的问题。
1.先看看是不是索引失效(大部分都是这个情况)
使用explain+SQL查询语句即可查看是否使用了索引。
2.索引为什么失效
2.1 索引的设置和查询语句的字段是否匹配
2.2 查询语句是否正确的使用了索引,比如like%xxx就会导致索引失效
2.3 索引列都对上了,索引失效肯定是被mysql内部优化器给优化了(大部分都是这个情况), 为什么索引会被优化器弃用,能否优化SQL语句让mysql使用索引?
3.如果索引没失效,为什么查询还是这么慢,是不是索引设置的不对或者数据的问题?比如有大量的null字段、索引加在了存在大量重复值的字段。
4.索引没问题,那是不是join的表太多?
5.join表不多,那是不是数据量太大导致数据库的硬件资源不够用了?
CPU:CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候。
IO:磁盘I/O瓶颈发生在装入数据远大于内存容量的时候。
服务器硬件的性能瓶颈:top,free, iostat和 vmstat来查看系统的性能状态。
6.硬件资源够用,那是不是mysql的参数设置的太小了?
定位问题的步骤:
1 慢查询的开启并捕获
2 explain+慢SQL分析
3 show profile查询SQL在 Mysql服务器里面的执行细节和生命周期情况
4 SQL数据库服务器的参数调优。
Explain
https://dev.mysql.com/doc/refman/8.0/en/execution-plan-information.html
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道 MySQL是
如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
explain可以查看以下信息
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
下面是explain执行返回结果的字段解释:
id
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序。
一共分三种情况:
id相同
id相同,执行顺序由上至下。
id不同
id不同,id值越大优先级越高,越先被执行。
示例:
explain SELECT t2.* FROM t2 WHERE id=
(
SELECT id FROM t1 WHERE id=
(
SELECT t3.id FROM t3 WHERE t3.name =''
)
);
执行结果:

id有的相同有的不同
id不同时,id值越大,优先级越高,越先执行,id相同时,按顺序从上到下执行。
explain select t2.* from
(
select t3.id from t3 where t3.name =''
) s1, t2
where s1.id = t2.id;

derived:衍生表的意思,上图第一行的table列里的2对应的是id列里的2。
select_type
查询的类型。
常见值:
SIMPLE
简单的 select查询,查询中不包含子查询或者 UNION
PRIMARY
查询中若包含任何复杂的子部分,最外层查询则被标记为
SUBQUERY
在 SELECT或 WHERE列表中包含了子查询
在FROM列表中包含的子查询被标记为 DERIVED(衍生)
DERIVED
MySQL会递归执行这些子查询,把结果放在临时表里。
若第二个 SELECT出现在 UNION.之后,则被标记为 UNION
UNION
若 UNION包含在FROM子句的子查询中,外层 SELECT将被标记为: DERIVED
UNION RESULT
多个表UNION之后的结果集。
table
所查询的表
type
显示查询使用了何种检索类型(访问类型)。
常见值:
system>const>eq_ref>ref>range>index>all
从最好到最差依次是:
全部值:system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>all
常见值:system>const>eq_ref>ref>range>index>all
一般来说,得保证查询至少达到 range级别,最好能达到ref。同时也不要惧怕全表扫描,有时候多表联查时会有一个全表扫描是无法避免的,当然如果严重影响查询还是将全表扫描优化成index最好。
system
表只有一行记录(等于系统表),这是 const类型的特列,平时不会出现,这个也可以忽略不计。
const
表示通过索引一次就找到了, const/用于比较 primary key.或者 unique索引。因为只匹配一行数据,所以很快。
如将主键置于 where列表中, MySQL就能将该查询转换为一个常量。
表里有多行记录,但是通过where unique字段='xxx',直接检索出一条记录,通过主键查询出单行就是const。
eq_ref
使用到了索引,并且匹配出了一行数据。
主表在与从表连接查询时,主表是多,从表是一,主对从是多对一的关系,那么从表的查询类型就是eq_ref。
explain select * from channel_ref_news t2 left join `channel` t1 on t1.id=t2.channel_id;

ref
使用到了索引,并且匹配出了多行数据。
主表在与从表连接查询时,主表是一,从表是多,主对从是一对多的关系,那么从表的查询类型就是ref。
explain select * from `channel` t1 left join channel_ref_news t2 on t1.id=t2.channel_id;

range
只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。
一般就是在你的 wherei语句中出现了 between、<、>、in等的查询。
这种范围扫描比索引扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
index
Full Index Scan, index与ALL区别为 index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。
(也就是说虽然它和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
all
Full Table Scan,将遍历全表以找到匹配的行。
possible_keys
可选的索引、可用的索引、可能使用的索引。
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定使用。
key
真实使用的索引,如果为null,则没有使用索引。
查询中若使用了覆盖索引(覆盖索引是指select的数据列只用从索引中就能够取得,不必读取真实数据行),则该索引可能(注意是可能,不是必然,有时候明明是覆盖索引却可以出现在possible_keys,原因不明)仅出现在key列表中。
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
key_len的值越大,索引的精确匹配度越高,所占用的存储资源越多,索引的值越小,执行效率越高,所占用的存储资源越少。
where col1='ab' and col2='cd'的key_len肯定比where col1='ab'要长,条件越精确,所需要的key_len越长。
ref
主表在与从表连接查询时,显示从表索引引用了主表的哪个列,也可能是一个常数(where 索引列=‘我是常量’)。哪些列或常量被用于查找索引列上的值。
格式是:数据库名.表名.字段名,或者const
示例:
explain select * from channel_ref_news t2 left join `channel` t1 on t1.id=t2.channel_id;
explain select * from `channel` t1 left join channel_ref_news t2 on t1.id=t2.channel_id;
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
每张表有多少行被优化器查询。
rows越少越好,表明这个索引的检索更快更精确。
extra
using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照索引顺序进行读取。
MySQL中无法利用索引完成的排序操作称为"文件排序”。
文件排序和oder by的字段、字段顺序、排序方式都有关系,一旦oder by的字段、字段顺序、排序方式任意一项与索引定义的不一致,都会导致文件排序。
文件排序是开发中尽量要避免的。
using temporary
使了用临时表保存中间结果, MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询 group by。
临时表和oder by、group by的字段、字段顺序、排序方式都有关系,一旦oder by、group by的字段、字段顺序、排序方式任意一项与索引定义的不一致,都有可能会导致临时表的产生。
临时表是开发中绝对要避免的。
using index
表示相应的select操作中使用了覆盖索引,避免访问了表的真实数据行。
如果同时出现 using where,表明索引被用来执行索引键值的查找;
如果没有同时出现 using where,表明索引用来读取数据而非执行查找动作。
using where
使用了where条件查找。
using join buffer
使用了连接缓存,可在配置文件中增加innodb_buffer_pool_size大小。
impossible where
where子句的值总是 false,不能用来获取任何元组
select tables optimized away
在没有group by子句的情况下,基于索引优化min/max操作或者对于MyISAM存储引擎优化count(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
distinct
优化 distinct操作,在找到第一匹配的元组后即停止找同样值的动作
永远使用小表驱动大表
优化原则:小表驱动大表,即小的数据集驱动大的数据集。
exists和in
select from A where id in (select id from B)
等价于:
for select id from B
for select from A where A.id B.id
当B表的数据集必须小于A表的数据集时,用in优于 exists。
select from A where exists (select 1 from B where B.id =A.id)
等价于
for select from A
for select from B where B.id A.id
当A表的数据集系小于B表的数据集时,用 exists优于in。
注意:A表与B表的id字段应建立索引。
exists语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE或 FALSE)来决定主查询的数据结果是否得以保留。其循环顺序和in相反。
1 EXISTS( subquery)只返回TRUE或 FALSE,因此子查询中的 SELECT *也可以是 SELECT 1或者SELECT ‘x’,官方说法是实际执行时会忽略 SELECT清单,因此没有区别。
2 EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比,如果担忧效率问题,可进行实际检验以确定是否有效率问题。
3 EXISTS子查询往往也可以用条件表达式、其他子查询或者JOIN来替代,何种最优需要具体问题具体分析。
join
左连接是使用小表做左表。
order by
order by与单路排序
从磁盘读取查询需要的所有列,按照 order by列在 buffer对它们进行排序,然后扫描排序后的列表进行输出.
使用buffer可以使它的效率更快一些,避免了第二次读取数据。并且把随机变成了顺序,但是它会使用更多的内存空间,因为它把每一行都保存在内存中了。
在 sort buffert中,方法B比方法A要多占用很多空间,因为方法B是把所有字段都取出,所以有可能取出的数据的总大小超出了sort buffer的容量,导致每次只能取 sort buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取,取sort_ buffer容量大小,再排……从而多次l/O。
本来想省一次IO操作,反而导致了大量的IO操作,反而得不偿失。
提高order by速度
1.Order by时select *是一个大忌,只Query需要的字段,这点非常重要。在这里的影响是:
1.1当 Query的字段大小总和小于 max length_for_ sort_data而且排序字段不是TEXTIBLOB类型时,会用改进后的算法——单路排序,否则用老算法一一多路排序。
1.2两种算法的数据都有可能超出sort buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高 sort_buffer_size。
2.尝试提高sort_ buffer_size
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。
3.尝试提高max_ length_for_sort_data
提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出 sort buffer_size的概率就增大,明显症状是高
的磁盘/0活动和低的处理器使用率.
慢查询
MySQL的慢查询日志是 MySQL提供的一种日志记录,它用来记录在 MySQL中响应时间超过阀值的语句,具体指运行时间超过long_ query.time值的SQL,则会被记录到慢查询日志中。
具体指运行时间超过long_ query.time值的SQL,则会被记录到慢查询日志中。long_ query.time的默认值为10,意思是运行10秒以上的语句。
由他来查看哪些SQL超出了我们的最大忍耐时间值,比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合之前 explain进行全面分析。
默认情况下, MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。
当然,如果不是调优需要的话,一般不建议启动该参数,因为慢查询日志支持将日志记录写入文件,或多或少带来一定的性能影响,在调优完成之后要把它关闭。
临时修改:
SHOW global VARIABLES LIKE '%slow_query_log%';#查询当前是否开启
set global long_query_time=3#修改为阙值到3秒钟的就是慢sql
show global variables like '%long_query_time%';
set global slow_query_log=1;#开
set global slow_query_log=0;#关
永久修改(不建议修改配置文件,因为我们调完优是需要关闭它的):
修改配置文件my.cnf
[mysqld]下增加或修改参数slow_ query_log和slow_ query_log_file后,然后重启 MySQL服务器。也即将如下两行配置进my.cnf文件
slow_query_log =1
slow_query_log_file=/var/lib/mysql/atguigu-slow.log
关于慢查询的参数slow_ query._log_file,它指定慢查询日志文件的存放路径,系统默认会给一个缺省的文件host_name-slow.log(如果没有指定参数sow_ query_log_file的话)
mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活, MySQL提供了日志分析工具
mysqldumpslow。
参数说明:
s:是表示按照何种方式排序;
c:访问次数
|:锁定时间
r:返回记录
t:查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间
t:即为返回前面多少条的数据;
g:后边搭配一个正则匹配模式,大小写不敏感的;
示例:
#得到返回记录集最多的10个SQL
mysqldumpslow -s r-t 10/var/lib/mysql/my-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow-s c-t 10 /var/lib/mysql/my-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t-t 10 -g "left join" /var/lib/mysql/my-slow.log
#另外建议在使用这些命令时结合|和more使用,否则有可能出现爆屏情况
mysqldumpslow -s r-t 10 /var/lib/mysql/my-slow. log | more
查询语句
sql查询语句结构
SELECT
< distinct > < select columns >
FROM
< left table > < join type >
JOIN
< right table > ON < join condition >
WHERE
< where condition >
GROUP BY
< group by list >
HAVING
< having condition >
ORDER BY
< order by condition >
LIMIT
< limit number >
翻译:
SELECT
<是否去重,如果要去重加上distinct,否则不加> < 要查询的列 >
FROM
< 左表 > < 连接类型,有inner、left、right等 >
JOIN
< 右表 > ON < 两个表的连接条件,如左表.id=右表.id >
WHERE
< 查询条件 >
GROUP BY
< 要分组的列,可以为多列>
HAVING
< 分组的查询条件 >
ORDER BY
< 要排序的列+升序还是降序,升序asc,降序desc,示例,order by create_time desc,id asc >
LIMIT
< 分页值,格式:起始行号,截取的行数,如limit 0,10表示取结果集的前10条,10,10表示取结果集的10~20这10条 >
sql查询语句读取顺序
- FROM < left table >
- ON < join condition >
- < join type > JOIN < right table >
- WHERE < where condition >
- GROUP BY < group by list >
- HAVING < having condition >
- SELECT
- < distinct > < select columns >
- ORDER BY < order by condition >
- LIMIT < limit number >
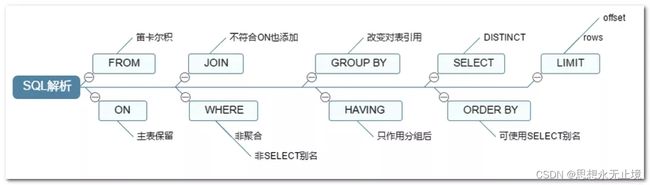
7种join

其实只有5种,因为左右表可以对换,left join和right join其实是一样的,left outer join和right outer join其实也是一样的。
而以上5种是Oracle支持的语法,mysql中不支持full join,所以mysql默认支持的只剩三种(不是inner、left、right,而是上图中左侧两个left out join加中间上部的inner join)。
1.内联
2.左联
3.左联但去除共有部分
select * from t1 left join t2 on t1.id=t2.id where t2.id is null
如果需要使用全连接,需要使用union查两次左右连接后再去重。
1.包含AB全集
select * from t1 left join t2 on t1.id=t2.id
union
select * from t2 left join t1 on t1.id=t2.id#等价于:select * from t1 right join t2 on t1.id=t2.id
2.包含AB全集,去除共有部分
select * from t1 left join t2 on t1.id=t2.id where t2.id is null
union
select * from t2 left join t1 on t1.id=t2.id where t1.id is null
使用where联接和inner join等同。
MySQL问题汇总
低版本引发的CURRENT_TIMESTAMP问题
https://blog.csdn.net/u012643122/article/details/103413895
低版本导致的问题
https://blog.csdn.net/u012643122/article/details/103681602
查询语句中不支持if/else
https://blog.csdn.net/u012643122/article/details/103603276
子查询Subquery returns more than 1 row问题
https://blog.csdn.net/u012643122/article/details/48295055
子查询on条件中无法访问父查询的表别名
https://blog.csdn.net/u012643122/article/details/103974293
update嵌套问题
https://blog.csdn.net/u012643122/article/details/52945370
datetime超出24小时问题
https://blog.csdn.net/u012643122/article/details/47432103