独家丨DeepMind科学家、AlphaTensor一作解读背后的故事与实现细节
一直以来,DeepMind的Alpha系列工作,AlphaGo、AlphaStar等致力于棋类和游戏应用中战胜人类,而两个月前发布的AlphaTensor则把目标指向了科学计算领域,意在为矩阵乘法等基本计算任务自动设计更高效的经典算法,这一工作一经推出,效果显著,让人眼前一亮,甚至被知名AI主播Lex Fridman评价为值得「诺贝尔奖和菲尔兹奖」的工作。
AlphaTensor是如何做到的?其工作背后的灵感来源是什么?智源社区邀请到该工作第一作者Alhussein Fawzi博士,为我们独家讲授了如何将强化学习方法应用到矩阵乘法等基础科学问题,同时Fawzi博士也分享了项目背后的细节,以及给交叉学科研究者的建议。

Fawzi博士是DeepMind的研究科学家。他于2016年从洛桑联邦理工学院(EPFL)信号处理实验室获得了博士学位。2012年他获得了EPFL电气工程学士学位。他在2013-2014和2015-2016学年获得了IBM博士奖学金(IBM PhD Fellowship awards)。目前Fawzi博士从事的是科学人工智能方面的工作,尤其是使用机器学习来解锁数学领域的新成果。同时,他对机器学习系统的可靠性也很感兴趣,尤其是计算机视觉方面。
“
Q&A
1、AlphaTensor的灵感从何而来?
A:我的灵感本质上就是我们如何使用机器学习来自动化算法发现的过程。发现新的算法是一个艰难的过程,所以我们可以尝试使用机器学习自动化其中的一部分,我们想专注于一个特定的问题,例如,矩阵乘法这种影响重大的问题。我们的工作表明对于矩阵乘法这个概念是可行的,希望在未来,对于其他算法也是可行的。另一个灵感就是要尝试使用现有的算法,像AlphaZero 本来就是专门用来玩复杂游戏,我们看看这是否可以被超越。
2、这个项目是如何一步一步开始的?团队是如何组织的?
A:好的,这个项目本质上是从监督学习开始的,我们一开始并不喜欢应用强化学习,所以尝试只使用这种综合演示。然后,我们做了一个为期两周的冲刺,有点像黑客松,想尝试使用强化学习解决这个问题,结果证明是非常有前途的。我们团队中有数学、强化学习和transformer等各个方面的专家。我认为,还有一件有趣的事情是,团队做了一个leaderboard(排行榜),结果开始真正变得越来越好。leaderboard列出每个人的运行实验所有结果,互相之间进行竞争以获得本质上最好的结果。
3、在整个过程之间里程碑是什么?
A:首先尝试实现现有算法,比如第一个就是重新发现Strassen算法,然后尝试重新发现其他算法,然后就超越现有的算法,就是非常自然的里程碑。
4、有哪些经验可以向跨学科领域的同行(包括AI和基础数学等)分享?
A:AlphaTensor中谈到的这些方法实际上适用于许多领域,特别是数学领域。例如,关于证明一个特定的定理,但这对定理的多样化描述很重要,我们本质上尝试以等效的方式表达定理,并生成训练数据。这就是我认为一件非常重要的事情。第二,我要分享的是不要直接去做强化学习,因为强化学习很难从“零”开始直接运行。所以,恰当的步骤非常重要,比如首先进行监督学习,如果你发现监督学习有效,那么你尝试在它之上做一些搜索,然后如果监督学习、交叉搜索都有效之后再尝试嵌入到强化学习的流程。
“
研究背景
矩阵乘法,是矩阵变换的基础运算之一,也是线性代数的基础工具,不仅在数学中有大量应用,在物理学、工程学等领域也有广泛使用。作为构成数学算法的基础运算之一,矩阵乘法的应用史长达数千年。
矩阵乘法在现代计算机中更是无处不在,被广泛地应用于处理图像、语音、图形甚至仿真模拟、数据压缩等,在当代数字世界有着巨大的影响力。世界各地的公司花费了大量的时间和金钱来开发计算软硬件,以有效地进行矩阵乘法。因此,即使是对矩阵乘法效率的微小改进也会产生广泛的影响。几个世纪以来,人们一直认为标准的矩阵乘法算法在效率方面已经达到最佳状态。
但在1969年,德国数学家Volken Strassen表明确实存在更好的算法,震惊了数学界。矩阵乘法的标准算法与Strassen的算法相比,后者在计算两个2x2矩阵相乘时少用了一个标量乘法(共用7次而不是8次)。矩阵乘法需要执行多次标量的数值乘法或加法运算,考虑计算机架构的乘指令开销远大于加法,在保证结果正确的前提下,尽量减少矩阵乘中的数值乘法次数。经过几十年的研究,这个问题仍然没有更好的解决办法。

使用机器学习来发现新的可证明正确的高效算法来解决有影响力的问题!Fawzi博士开宗明义讲出他做这项研究的目标,并强调了其中的关键字:可证明正确。算法不针对于特定的测试分布,而对所有实例或所有输入都是正确的。高效,算法运行速度快或者具有良好的渐近复杂度。
意义重大的问题或者称之为根节点问题,是指如果解锁这些问题,其他位于根节点路径上的问题也将被解决,因而将产生很大的影响。如果能够使用机器学习自动化来寻找这些算法,可能会产生变革性的影响和巨大的价值。如下图中的矩阵乘法就是重要的根节点问题之一。

但是,使用机器学习自动化发现算法面临着许多挑战。首先,为了找到一个可证明正确的算法,用来表示算法的空间是什么?如何在这个空间中描述问题,比如两个矩阵之间的乘法?即使能够找到这个空间,在规模巨大的空间中搜索也相当困难。
那么,如何能够高效的找到需要的解?有效地应用最先进的机器学习方法非常重要。
“
矩阵乘法及其算法的描述

如上图所示,两个大小为2x2矩阵做乘法,在标准定义下总共需要 8 次标量乘法。Strassen算法首先把矩阵的一些切片组合在一起构成中间变量,然后这些中间结果被分配到目标的结果当中。这个算法确实需要一定的独创性才能想出,但检查它是否正确却很容易,只要判断两种算法得到的结果是否完全一样即可。两个2X2矩阵乘法中Strassen算法与标准算法相比只减少了1次乘法,但是依然非常重要,因为超过2X2矩阵大小可以递归地应用该算法。例如对于N X N矩阵,把矩阵分块,递归地应用Strassen算法,分治处理矩阵乘子块,可以将矩阵乘法的复杂度由原来的O(N3)降低为O(N2.81)。
参考文献[6]中较早地解释了如何用张量空间描述双线性操作,需要确定两个对应关系:(1)将矩阵乘法对应为表征张量(2)将表征张量的一种低秩分解 (将表征张量拆分为R个秩1的张量的和) 对应为一种包含R次数值乘法的矩阵乘法算法。
矩阵乘法描述张量
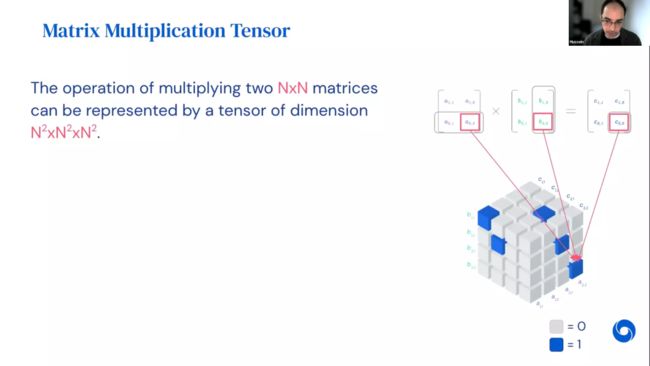
就像线性运算可以表示为矩阵,双线性运算可以表示为张量,矩阵乘法张量代表矩阵乘法这种双线性运算。从本质上相当于引入了一种新语言,这种语言对于自动化发现算法非常重要,因为这个张量记录了矩阵乘法的操作。需要指出的是这个张量表达的是在操作层次而不是在实例层次的内容,所以这个张量与想要相乘的具体矩阵无关。表示n x m与m x p矩阵相乘,需要张量大小为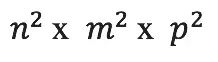 。如上图,以两个2x2矩阵为例,对应的矩阵乘法张量大小为4x4x4。
。如上图,以两个2x2矩阵为例,对应的矩阵乘法张量大小为4x4x4。
张量中的元素要么是 0 要么是 1,并用1指示具体的乘法。a、b维度表示读,c维度表示写。若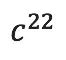 要用
要用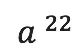 乘以
乘以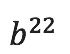 ,因此在<
,因此在<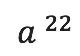 ,
, ,
,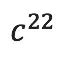 >处为 1。同理,<
>处为 1。同理,<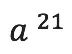 ,
,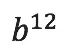 ,
,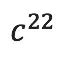 >位置的值也为1。因此这个描述标准算法的张量中共有8个1,其余为0。
>位置的值也为1。因此这个描述标准算法的张量中共有8个1,其余为0。
矩阵乘法算法的张量分解描述
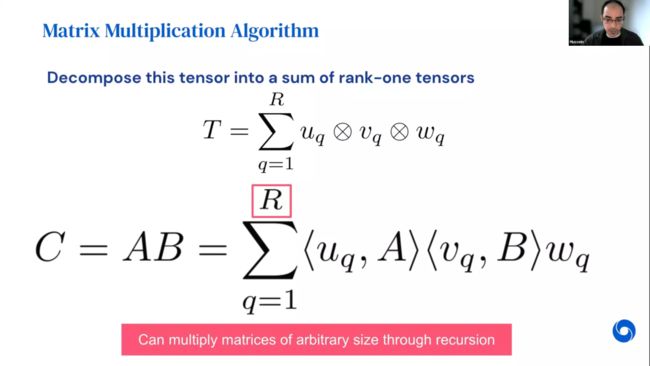
如何通过张量如何描述矩阵乘法的算法?其实可以将具体算法看作是这个特定张量的一种低阶分解。与矩阵分解需要两个模式向量的外积进行求和类似,张量分解可以看作是三个模式向量的外积求和。如图,原始张量分解为R个秩(Rank)为1的张量的和,其中每个秩为1的张量是3个向量uq, vq,wq的外积。所以有了张量的分解就可以得到任何矩阵A和B相乘的一种算法。这个算法正是由上图的公式给出。需要指出的是这个分解的秩R是一个非常重要的属性,因为它控制着渐近复杂性。一旦通过张量分解得到算法就可以使用递归地将其应用于任意大小矩阵之间的乘法。
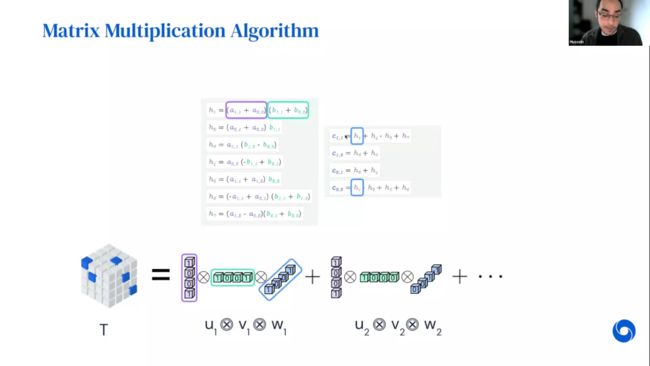
如上图,使用这种张量分解“语言”同样可以描述Strassen算法。这里张量的大小为4x4x4,Strassen算法实际上对应于7个秩为1的分解。算法和张量分解之间对应关系如上图所示。从这个简单的例子可以看出,u向量表示的A矩阵中元素的线性组合,v向量表示B矩阵中元素的线性组合,u和v的外积表示相应线性组合值的一次标量乘法运算,并记为一个中间结果,w向量表示哪些最终结果包括该中间结果作为部分和。
现在面临的问题是,如果想找到矩阵乘法的快速算法,就需要找到矩阵乘法张量的低秩分解,即一个R较小的张量分解。与矩阵能够用多项式时间算法计算其秩非常不同,即使很尺寸很小的张量的秩的计算也非常困难,这正是可以使用机器学习的地方。
“
机器学习解决数学问题
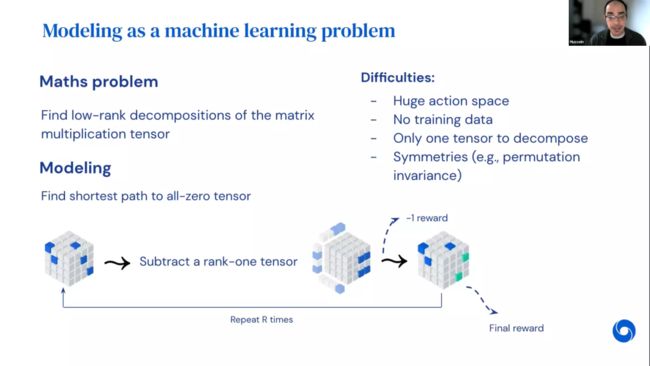
应用机器学习解决数学问题的主要困难
计算张量秩是非常非常困难的问题。通过前文的方法定义好了搜索空间后,考虑 N 阶方阵乘法的定义直接确定了张量 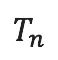 的每个元素的0/1取值,可以不断尝试对
的每个元素的0/1取值,可以不断尝试对 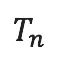 进行低秩分解就可以实现 N 阶方阵乘法算法的自动搜索。搜索目标很简单,也就是用尽可能少的秩1张量凑出
进行低秩分解就可以实现 N 阶方阵乘法算法的自动搜索。搜索目标很简单,也就是用尽可能少的秩1张量凑出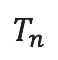 。
。
为了解决这个问题,可以把尝试低秩分解的过程看作游戏,将张量作为三维棋盘,玩家可以做的是在每一步中从剩余张量中减去一个秩为1的张量并更新状态,如果到达零张量,则玩家获胜。由前面的描述可知,到达零张量所需的步数实际上就是对应张量的秩,为了使Agent 尽可能早地凑出零张量,每一步得到一个常数 -1的奖励;若指定的最长的步后没凑出零张量,会得到额外的的奖励,其数值与最后剩下的张量的秩有关,秩越大惩罚就越多。
然而,完成这样的游戏面临非常多的困难:1)动作空间非常大。秩为1的张量数量实际上是无限的。即使把它离散化也会得到一个非常非常大的动作空间。2)没有训练数据。像围棋这样的游戏可以在线找到很多专家游戏,但是并没有张量分解相应的训练数据。3)游戏中只有一个张量,并考虑如何去分解这个张量,问题本质上没有足够的机器学习所需要的多样性。4)对称性。
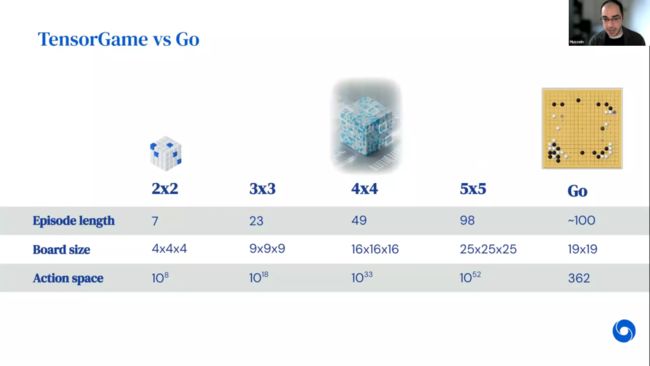
下图比较了不同游戏中Agent的动作空间的大小。在张量游戏中即使将所有元素离散化为-2、-1、0、1、2, 动作空间仍然非常大,不可能枚举所有这些情况。例如,两个2x2矩阵相乘的游戏中Agent具有108 的动作空间,如果是两个 5x5 矩阵相乘,那么对应的阶数为1052,与围棋相比动作空间大很多。找到一个很好的低阶分解无异于「大海捞针」,这也是许多数学问题中存在的巨大的挑战。
基于AlphaZero构建张量分解游戏

AlphaZero是一种强化学习算法,其包含 2 个组件即Actor和Learner。AlphaZero在训练的开始时候选择的动作很差,每个秩为1的张量相当于随机选择。Actor收集所有这些游戏,并将它们发送到Learner。Learner将尝试理解或者说模仿这些数据,通过对状态进行采样作为神经网络的输入。
网络的输出包括两个部分:第一个输出是策略即采取的下一步行动,第二个输出是价值(即对当前状态的估计),这里指当前情况下张量秩的估计。网络将尝试模仿游戏进行有效地训练,然后将训练后的网络发送回Actor,需要同时使用策略和价值来指导树搜索,因此也使得比仅仅进行随机搜索效果要好一点。蒙特卡洛树搜索(MCTS)尝试改进神经网络给出的策略和价值,并将这些改进的游戏发送给Learner。然后,神经网络再模拟该数据,再发送回Actor。这是一个自我强化的循环 ,也是取得突破的基础,最终显示出令人难以置信的能力。
使用机器学习解决数学问题的「秘笈」
为了让AlphaZero适应Tensor游戏,Fawzi 博士给出了 4 个特别的「秘笈」。

第一,合成数据。在数学问题中,可用数据不多所以需要依赖合成数据。很多数学问题表现得像“单边函数”,有一个方向很难但是其他方向很容易。例如张量分解很难,但是如果有一个分解,从它得到张量很容易。所以可以生成一些随机分解,然后从这个分解中创建张量,并通过这种方式生成很多随机张量和分解。这种方法的好处是很容易地将它合并到训练数据中,因此训练数据是混合训练数据。混合数据的真正挑战是,合成数据的分布可能与目标数据的分布相去甚远。但这种方法仍然非常有用,特别是在训练开始时这些合成数据能够帮助提供有关张量分解问题的更多信息。
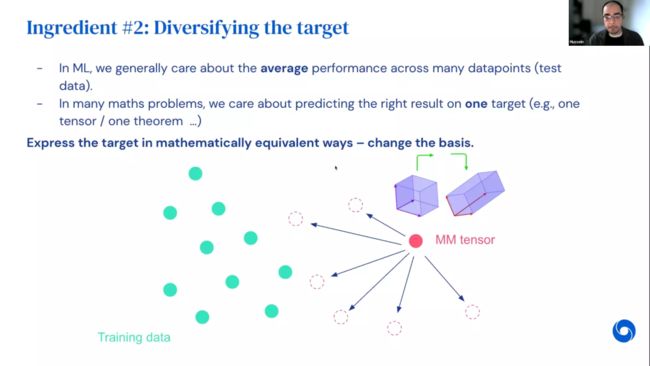
第二,目标多样化。正如之前所述,这个问题没有足够的多样性。从某种意义上说,游戏开始只考虑一个张量。但机器学习通常更关心测试分布,如果只关注这个张量,一遍又一遍地生成同一个游戏,基本上不会有足够的多样性。解决的方法是通过数学上等效的方式表达张量。原始张量以规范基表示,可以通过更改基得到新的张量。因为这些是非常不同的张量,神经网络会变得丰富,并使对称乘法张量更接近于训练数据分布。因为这些张量的数学等价性,如果找到其中任何一个的分解,都可以将它映射回规范基,所以求解其中一个等价于解决所有这些问题。

第三,训练一个多面手智能体,而不是几个专家智能体t。分别为不同尺寸张量训练一个智能体比训练分解所有这些张量的智能体更糟糕,智能体能够在不同规模之间转移技术,因此全能的智能体具有更好性能。对所有这些目标训练一个智能体,而不是为每个目标训练一个智能体,效率也要高得多。
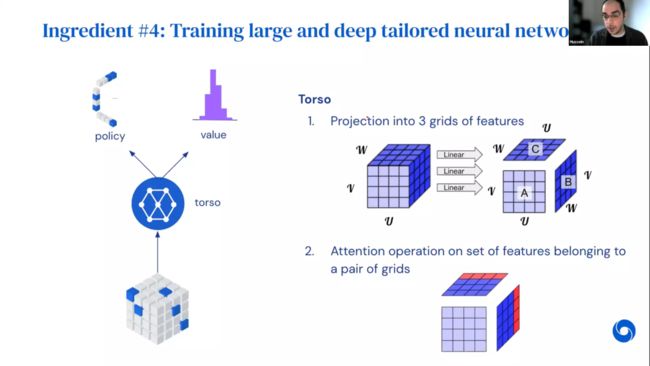
第四,专用深度网络。神经网络架构对于嵌入先验知识非常重要。因为使用三维张量计算量很大,这里的主干网络将三维张量投影到 3 组特征中以降低维度。可以认为3个特征网格是张量的不同视图,每个代表 3 种模式中的 2 种。同时,这里的自注意力机制之间只存在于有限的组或者切片当中,因为属于同一切片的元素比不同切片的元素更相关,而且如果重排切片,张量的秩保持不变。通过对彼此更相关的元素进行受限的注意力操作,就将关于张量分解问题的直觉与先验纳入架构中。
“
成果
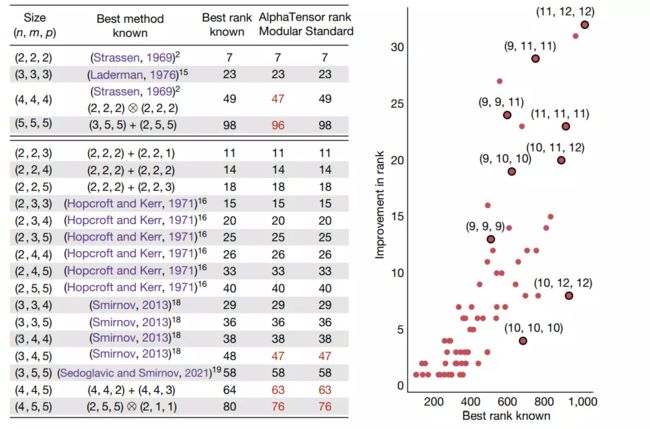
同一个Agent在所有不同的张量大小以及在不同的数域(离散域F2和实数域R)训练得到的结果如上图所示。AlphaTensor重新发现像Strassen算法等重要算法,在较大矩阵乘法上超越人类已知的结果,可以说越大的矩阵AlphaTensor 甩开人类的差距越大。传统算法用100次乘法对实现4x5乘以5x5的矩阵乘法,而人类的当下最好的算法将其减少到80次,AlphaTensor找到了只用76次乘法就能完成同样操作的算法。除此之外,AlphaTensor首次在有限域中改进了Strassen的两级算法。此外,AlphaTensor还发现了先进复杂度的多样化算法即每种大小的矩阵乘法算法多达数千种,表明矩阵乘法算法的空间比以前想象的要丰富。
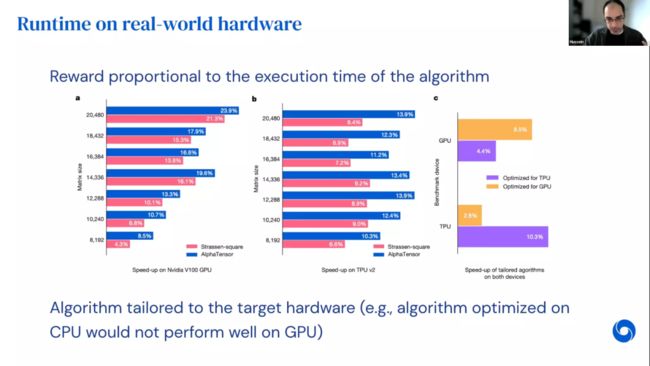
AlphaTensor也可以用来寻找在特定硬件上加速算法,如英伟达V100 GPU和谷歌TPU v2。这里采用与之前完全相同的工作流程,仅仅增加了与该算法在特定硬件上的运行时间成正比的额外奖励。特别强调的是,强化学习的奖励不一定是可微的,而可以是任何可计算的函数。从下图可以看出这些算法在相同的硬件上比常用的算法快10-20%,这展示了AlphaTensor在优化任意目标上的灵活性。需要指出的是,在特定硬件上优化的加速算法在其他不同硬件上并不一定能够起到加速的效果。
“
结论
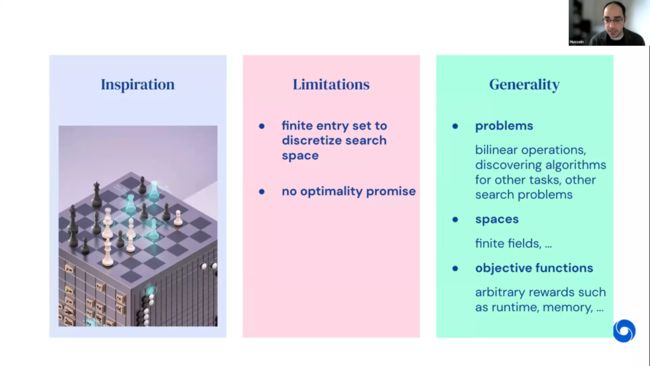
Fawzi博士最后总结到,像 AlphaZero等深度强化学习方法可以用于解决算法发现和组合问题中非常复杂的问题,该方法在这些领域有巨大的潜力。虽然存在无法保证最优解以及需要离散化空间等局限性,这种方法仍可普遍地适用于不同的双线性运算和其他搜索问题。无论在任何类型的域或任何空间,采用任何可计算的奖励函数,只要存在乘法加法表,就可以用这种方法。
参考链接
1. GitHub:https://github.com/deepmind/alphatensor
2. Paper:https://www.nature.com/articles/s41586-022-05172-4
3.paper-appendix:https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-022-05172-4/MediaObjects/41586_2022_5172_MOESM1_ESM.pdf
4. 中文视频:http://www.deeprlhub.com/d/942-alphatensorslide
5. DeepMind blog: https://www.deepmind.com/blog/discovering-novel-algorithms-with-alphatensor
6. Smirnov, A. V. (2013). The bilinear complexity and practical algorithms for matrix multiplication. Computational Mathematics and Mathematical Physics, 53(12), 1781-1795.