使用 COCO 数据集训练 YOLOv4-CSP 模型
文章目录
- 前言
- 1. 创建 YOLOv4-CSP 模型
- 2. 使用 tf.data.Dataset
- 3. 对 COCO 2017 数据集的处理
-
- 3.1 处理 COCO 2017 数据集的标注信息
- 3.2 对类别编号的处理
- 3.3 设置图片相关路径
- 模型架构、指标、损失函数之间的关系
- 4. 损失函数
-
- 4.1 原始的损失函数
- 4.2 改进后的损失函数
- 5. 使用 COCO 的 AP 指标
- 6. 关于学习率衰减
- 7. DIOU-NMS 操作
- 8. 下载地址
前言
如果完全按照 YOLO 的论文,并不能直接训练出一个好用的物体探测 object detection 模型。这是因为我们并不知道原作者使用的超参数是什么。所以需要自行编写损失函数,尝试各种超参,对模型进行训练。
下面是我用 COCO 2017 数据集中的少量图片,对 YOLOv4-CSP 模型进行训练的结果。 使用框架为 Keras/TensorFlow 2.9。
说明:YOLOv4-CSP 论文中提到,他们对整个 COCO 2017 数据集,训练了 300 多个 epochs。如果使用单张 RTX 3090 显卡,需要训练 10 个月以上。为了快速地展现模型的过拟合能力,我只用了 COCO 数据集的前 8 张图片进行训练。 如果是在企业 GPU 集群的情况下,有 100 张或更多的大算力显卡,则可以直接用整个 COCO 数据集对该模型进行训练,应该几天就可以将模型训练好。
从创建 YOLOv4-CSP 模型,到使用数据集对其进行训练,再到将预测结果可视化,这整个流程涉及到多个步骤。下面进行逐一讨论。
1. 创建 YOLOv4-CSP 模型
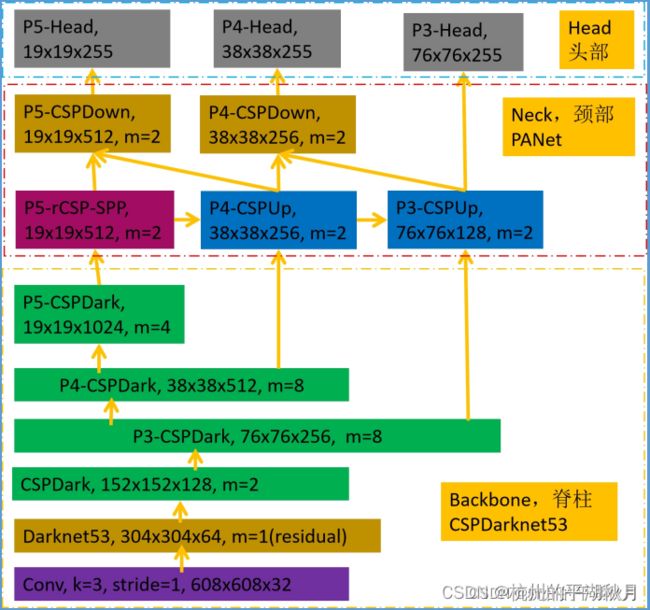
YOLOv4-CSP 的结构图如下。创建该模型的完整过程,可参见我的另一篇博客。→博客链接地址
2. 使用 tf.data.Dataset
COCO 2017 数据集有 12 万张图片,如果一次全部加载入内存,会使得内存占用量的峰值超过 128G(程序内部的数据在输出给外部变量时,瞬间占用内存会翻倍。所以虽然 12 万张图片本身不需要 128G,但是交换数据的瞬间会突破 128G)。
为了应对数据集图片极多的问题,可以使用 tf.data.Dataset。
使用 tf.data.Dataset 的好处,是它可以调用无穷大的数据集。它的原理是异步操作(并发编程 concurrency):即 tf.data.Dataset 先准备少量图片给模型训练。然后当模型在训练此批数据时, tf.data.Dataset 会同时开始准备下一批训练数据,从而使得各训练步骤等待的时间最小;也使得它可以借助少量内存,轻松调用上百万张图片乃至无穷多图片的数据集。
用 COCO 数据集创建 tf.data.Dataset 的过程如下图。

3. 对 COCO 2017 数据集的处理
3.1 处理 COCO 2017 数据集的标注信息
在读取 COCO 2017 数据集的标注信息时,训练集中有 2 张图片需要进行特别处理,因为它们的高度被标注为了 0。但是对物体探测来说,高度为 0 则意味着物体框不存在,也画不出来。所以需要把它们的高度手动修改为 1。这两张图片编号分别是 200365 和 550395。
下图是 200365,其中一个 hot dog 的高度被标注为了 0。

3.2 对类别编号的处理
COCO 数据集使用了1 到 90 之间的数字,来对 80 个类别进行编号,所以部分数字是空缺的,没有对应任何类别。
而 YOLOv4-CSP 模型的标签要使用 one-hot 编码,用 80 位代表 80 个类别,所以需要在模型的类别编号,和 COCO 的类别编号之间进行转换。
部分的类别编号转换关系如下图。

3.3 设置图片相关路径
我创建了文件 create_tf_dataset.py ,专门用于将 COCO 数据集转换为 tf.data.Dataset。
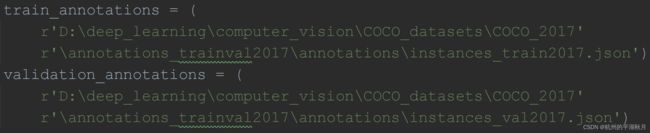
使用 create_tf_dataset.py 时,需要在其中设置好自己电脑本机中的 4 个文件路径。如下 2 图。

设置好 instances_train2017.json 和 instances_val2017.json 的路径。
模型架构、指标、损失函数之间的关系
模型架构决定了模型的能力上限。而训练方法则决定了能否把模型的能力上限发挥出来。训练方法包括了损失函数、训练数据等。
更具体来说,它们各自的作用是:
- 模型架构:决定了模型的能力上限。举例来说,YOLOv4 的架构,就会比 YOLOv1 要好。YOLOv4 能达到的 AP 值上限,要大于 YOLOv1。
- 指标:是衡量模型能力的工具。比如 COCO 的 AP 指标。
- 损失函数:损失函数的作用,是判断模型是否得到了训练。换句话说,如果看到损失值在不断下降,就说明模型在向着某一个方向,不断地得到训练。需要注意的是,损失值下降时,模型不一定是向着指标提高的方向训练,所以训练过程中,还需要不断查看指标的变化情况。
损失函数和指标都很重要,所以下面再看它们的细节部分。
4. 损失函数
4.1 原始的损失函数
论文中的原始损失函数,包括 3 部分:
- objectness 损失:对每个物体框,判断框内是否有物体,使用二元交叉熵损失。
- 分类损失 classification loss:判断物体框内的物体,属于哪个类别。使用二元交叉熵,或是多类别交叉熵损失函数。
- 物体框的损失:预测结果框和标签中物体框的位置差别,使用 CIOU 损失。
4.2 改进后的损失函数
-
增加超参数:如果直接使用 YOLOv4 论文中原始的损失函数,并不能得到一个好的探测模型。因为我们并不知道作者用的超参数是什么,所以需要自行增加超参数。
一个重要的超参数,是损失值之间的比例。并且实验证明,损失值之间的比例,是一个很关键的超参。
具体来说,是给 3 部分损失(objectness 损失,分类损失和物体框的损失),各自赋予一个权重值。求总的损失值时,各自乘以权重,然后再求和。
并且可以设置 objectness 损失的权重为 1,给另外 2 部分损失设定权重值,根据需要调节另外 2 部分损失的权重值即可。如下图。
-
另外一个重要的改进,是使用 BinaryFocalCrossentropy,即 focal loss 形式的二元交叉熵。
objectness 损失和类别损失,都需要用到二元交叉熵。而加上 focal loss ,则会有更好的效果。→ focal loss 论文地址在此
focal loss 的公式如下图,其中 (1-pt)**γ 是调节因子 modulating factor。

focal loss 的原理是:突出那些偏离标签很远的预测结果,通过调节因子对其加强惩罚,使它们的损失值更大。而那些和标签很接近的预测结果,它们的损失值则会变得很小。
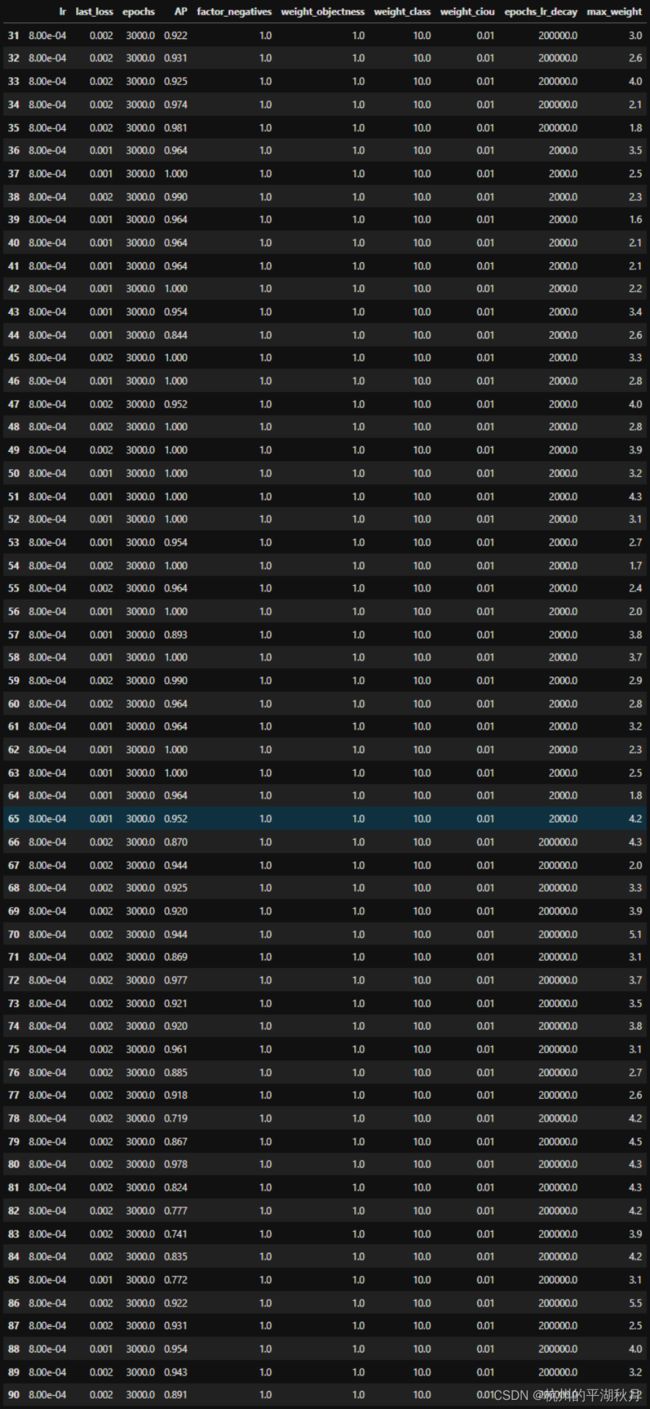
实验结果是,使用 BinaryFocalCrossentropy 时,AP 的均值在 0.975,标准差 0.035。而使用普通的二元交叉熵损失时,AP 的均值在 0.873 。(这里 AP 很高的原因,是因为使用了很少量的图片进行训练,所以是一个过拟合的结果)
下图是使用 BinaryFocalCrossentropy 时,30 次实验的 AP 结果记录。因为模型的权重是随机初始化的,所以每次的结果都会不同。而要看某一个模型的效果,或是某一组超参的效果,就需要使用统计的方式来进行对比。
在这些实验中,我使用了统计 30 次,计算 AP 均值和标准差的方法来进行比较。
5. 使用 COCO 的 AP 指标
训练模型时,我使用了 COCO 的 AP 指标。用 Keras 创建 AP 指标的方法,详见我的另一篇博客。→创建 AP 指标的博客链接
下图是使用 AP 指标训练模型的过程。设置为每过 5 个 epoch,使用回调函数 keras.callbacks.Callback,检查一次 AP。如果此时 AP 大于之前最高记录,则把当前模型保存下来。
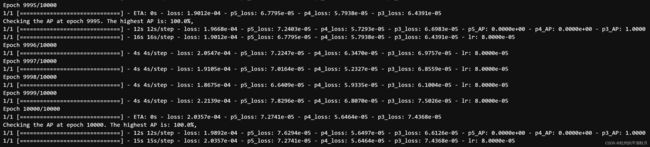
如果在编译模型时直接使用 AP 指标,需要对 AP 指标函数创建计算图,占用内存会超过 128G,个人电脑难以实现。所以一个变通的方法,是改为在回调函数 keras.callbacks.Callback 中计算 AP。
在这个 callback 内部,单独创建一个模型 self.evaluation_model,专门用于计算 AP 指标,并且是在 eager 模式下计算。这个做法是一举两得:既可以在训练过程中,实时查看 AP 指标的变化,又可以让 YOLOv4-CSP 模型始终运行在图模式下,实现快速训练。
计算 AP 的 callback 部分代码如下。

6. 关于学习率衰减
经过验证发现,不需要使用学习率余弦衰减 cosine decay,直接使用普通的学习率阶梯衰减 step decay 即可。阶梯衰减是指训练若干迭代之后,把学习率降低到另外一个值继续训练。
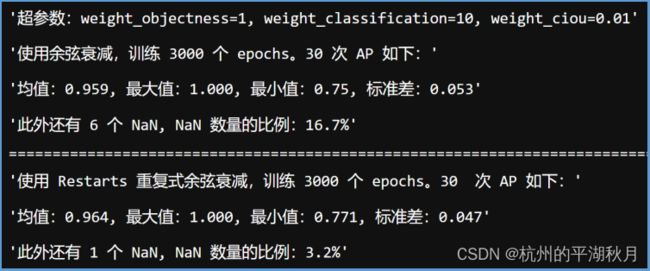
Keras 中有 2 种余弦衰减方式,分别是 keras.optimizers.schedules.CosineDecay 和 keras.optimizers.schedules.CosineDecayRestarts 。两者的差别是,第二种方式 CosineDecayRestarts 可以自动重复进行多次的余弦衰减。经过 30 次实验,记录的 AP 结果如下图(因为需要计算均值和标准差,所以用 Numpy 计算完之后,对计算结果进行了截图记录)。
而使用普通的学习率阶梯衰减时,30 次实验中,AP 的均值在 0.975,标准差 0.035,并且没有出现 NaN 值。所以使用普通的学习率阶梯衰减效果更好。
在深度学习中有一些是普遍适用的方法,这些方法在各种模型中,基本都是有用的。比如使用大量的训练数据,可以提高模型的泛化能力。使用数据增强,可以提高模型的能力。
而还有一些方法,或许只对某些模型比较有效。比如同一个学习率优化器,在不同的模型上效果可能会不一样。这本身也是训练模型过程的一部分,即找出最佳的模型、优化器、超参数的组合,以实现最好的指标。
顺带说一句:学习率“余弦衰减”,有时也被称为“余弦退火” cosine annealing。“退火” annealing 是一个金属热处理的专业名词,除了“退火”之外,还有“回火”、“正火”和“淬火”等等,它们都是关于在金属热处理过程中,“马氏体”、“奥氏体”和“珠光体”等金相组织的变化。绝大多数人都难以理解它们之间的区别。因此,为了便于理解,直接使用“余弦衰减”即可。
7. DIOU-NMS 操作
得到模型的输出结果之后,需要再进行 DIOU-NMS 操作,去掉重复的探测框。→ DIOU 论文链接
NMS 全称是 Non-Max Suppression,为了便于理解,可以翻译为 “保留最大框”。意思是“保留概率最大的探测框”。有时会把 NMS 翻译为 “非极大抑制”,但因为它是一个双重否定句式,略为拗口。
DIOU-NMS 的大致原理是如下 2 点:
- 传统的 IoU-NMS,是对 2 个交并比大于 0.5 的物体框,认为它们框住的是同一个物体。此时要保留概率更大的那个物体框,把概率小的物体框删除。
- 而 DIOU-NMS ,则是在传统 IoU 基础上,增加了两个物体框中心点距离 distance 的因素。也就是说如果两个物体框的中心点距离很大,那么它们框住同一个物体的可能性就会更低。用 DIOU-NMS 代替 IoU,能更好地判断 2 个物体框是否框住了同一个物体。
在 DIOU 的基础上,进一步把物体框的宽高比 aspect ratio 考虑进来,还能够得到 CIOU 损失(Complete IoU)。即如果两个物体框的宽高比差别很大,那么它们框住同一个物体的可能性也会很低。
DIOU 和 CIOU 可以合并到同一个函数中进行计算。部分代码如下图。

8. 下载地址
相关的 4 个文件,放在了 GitHub 上。→ GitHub 下载链接
- yolo_v4_csp.py: 模型的主体都在此文件中,包括模型,损失函数,指标等等。
- create_tf_dataset.py:用于将 COCO 数据集转换为 tf.data.Dataset。
- plot_utils.py:用于把训练过程的损失值画成折线图。
- yolo_v4_csp.ipynb:是用于训练的主要文件。它会调用上面这 3 个 Python 文件,比直接用 Pycharm 训练模型要方便。
——本文结束——