python数据预处理总结
文章目录
-
-
- 前言
- 1. 查看某个特征在列名中的位置(索引)
- 2. 去掉某个特征
- 3. 将object类型转换为数值型
- 4. 合并数据框
- 5. 重新加载py文件
- 6. data1['apply_id']=data2['apply_id']只有一个值?
- 7. 对数据集进行描述
- 8. append
-
前言
数据预处理或者说数据处理过程当中,往往会遇到很多比较基础又容易忘记、混淆的命令,因此这里做一个总结,免得每次又去翻石沉大海的笔记。
本文的背景以风控大数据为例
1. 查看某个特征在列名中的位置(索引)
ls.index(指定元素):只能返回首次出现的索引
#查看列名
data.columns
#转换成列表
data.columns.to_list()
#查找索引 ls.index()
a=['hello','world','nice','to','meet']
a.index('hello')
:返回索引值 0
2. 去掉某个特征
背景:在我们的data中,有一个特征是不需要纳入指标筛选范畴的,比如说创建时间create_date,客户唯一标识符apply_id,标签y等等,现在我要对这些变量进行删除,生成feature_list0
remove删除单个元素,且根据值进行删除pop根据索引值进行删除,并且返回删除的对象del也是根据索引值进行删除,只是表达方式不一样del data[1]data.drop([列1,列2],axis=1,inplace=True):用于数据框的删除行或者列,可以多个进行删除,此时只需将删除的列名或者索引放在列表中作为输入参数即可。
a.remove('hello')
a
-> ['world', 'nice', 'to', 'meet']
a.pop(0) 会得到删掉的值'world'
a
-> ['nice', 'to', 'meet']
del a[0]
a
-> ['to', 'meet']
对于数据框来说,删掉某一行或者某一列采用drop函数
用法如下: Remove rows or columns by specifying label names and corresponding
axis, or by specifying directly index or column names.
import numpy as np
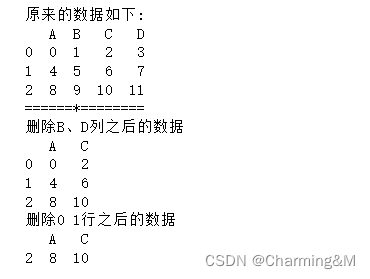
df = pd.DataFrame(np.arange(12).reshape(3, 4),columns=['A', 'B', 'C', 'D'])
print('原来的数据如下:')
print(df)
#删除BD列
df.drop(['B','D'],axis=1,inplace=True)
print('======*========')
print('删除B、D列之后的数据')
print(df)
#删除0,1行
df.drop([0,1],axis=0,inplace=True)
print('删除0 1行之后的数据')
print(df)
结果表示如下:
3. 将object类型转换为数值型
背景:现在我解析出来的三方数据是类别型的object,但是其中又包含类似信用分这样的数值型的特征。
经过查找,发现数值分数中混入了俩字符串ABDCHSI这种,导致没有办法将字符串类型转换成整数型,因此现在想要把字符串变成空值
经过多方尝试,暂时想到的方法还是循环呜呜呜
主要用到的知识点:
lambda x:x.isdigit()对每一个字符进行是否为数值的判断
fm_score=meituan['score']
h=list(fm_score.map(lambda x:x.isdigit())) #检测每一个字符是否为数值型
k=[] #主要是想存储非数值的那些值的索引是多少
for i in range(len(h)):
if h[i]==False:
k.append(i)
k #查看一下k
for j in k:
print(list(fm_score)[j])
#输出那些非数值型的值
#发现输出的都是一样的值,因此选择replace进行替换
meituan['score']=meituan['score'].map(lambda x:int(x))
#主要是如果存在字母的字符串的话,没有办法进行int
4. 合并数据框
背景:对sql立面读出来的多个数据进行合并
- 添加新的列/行
pd.concat([df1,df2],axis=1),
1 concat相当于全连接,待合并的序列放在列表中作为一个输入参数,
2 按行合并axis=0,按列合并axis=1
3 join:{‘inner’,‘outer’}表达连接方式
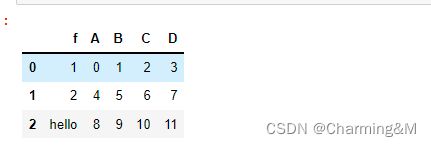
df = pd.DataFrame(np.arange(12).reshape(3, 4),columns=['A', 'B', 'C', 'D'])
df2=pd.DataFrame({
'f':['1','2','hello']
})
pd.concat([df2,df],axis=1)
结果展示如下:
- 按关联列合并:
pd.merge()
用法:pd.merge(A,B,on=‘相同列’)
how={‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’} 表示连接方式,默认是inner join
pd.concat和pd.merge的区别
- 当DataFrame的合并个数>2时,pd.concat()函数能同时合并,pd.merge()函数只能依次
两两合并; - pd.concat()函数是
轴向合并,pd.merge()函数是关联列合并; - 注意调用方法,书写格式不同;
- 各参数的使用不同。
5. 重新加载py文件
背景:在写代码的过程,有时会需要修改已加载的包(比如自己写的模块),此时为了不重新启动现有整个py文件,只需重新加载修改的模块
(1) 首先写入一个py文件,比如说print(‘hello world’)
(2) 然后修改py文件,print(‘modify’)
现在重新加载py文件
使用importlib模块里面的reload函数
import try1
-> hello world
import importlib
importlib.reload(try1)
-> modify
<module 'try1' from 'C:\\Users\\FM\\六月\\try1.py'>
6. data1[‘apply_id’]=data2[‘apply_id’]只有一个值?
背景:向data1里面添加data2的apply_id列
原因尚不明确???
解决方法
.values是将序列转化为数组的形式,然后再将数组转化为列表list()的形式,然后就可以将得到列表赋值给新的列
meituan['apply_id']=list(xindai['apply_id'].values)
7. 对数据集进行描述
用字典来存储每个数据集的描述,然后再用转换成数据框
我认为还是使用一下pd.DataFrame.from_dict()将字典转换成数据框,
其中,from_dict中的orient参数表示以...进行定位,
主要是指字典的键作为数据框的横坐标或者是纵坐标,取值为index,column
然后再进行转置
def data_set_statistic(data_dict:dict,y_col) ->pd.DataFrame:
'''
return:返回每一个数据集的总样本数,好样本数,坏样本数,坏样本占比
'''
res={}
for key in data_dict:
assert set(data_dict[key][y_col].unique())=={0,1} #是的话则跳过,否则报错
res[key]={
'Size':data_dict[key].shape[0],
'Good_Cnt':(data_dict[key][y_col]==0).sum(),
'Bad_Cnt':data_dict[key][y_col].sum(),
'Bad_Rate':data_dict[key][y_col].mean()
}
return pd.DataFrame(res).T
8. append
数据框的append和列表的append的用处均为添加元素
列表的append方法会直接在原始列表上添加元素,并且没有返回值,此时如果进行赋值则复制的变量为空,没有输出值
数据框的append方法会返回操作后的新的数据框,不会在原数据框上进行操作,因此需要进行赋值
正是由于这些差别,list在操作大量数据的时候会更快一些,而数据框每次操作之后会生成新数据框,大大增加操作时间
s=[1,2,3]
s1=s.append(5)
s1
print('列表append之后赋值得到的变量没有输出值')
data=pd.DataFrame({
'name':['he','qian'],
'age':[12,13]
})
print('原来的数据框为:')
print(data)
data1=pd.DataFrame({
'name':['zhang','yu'],
'age':[1,2]
})
data2=data.append(data1)
print('赋值之后的数据框为:')
print(data2)
输出结果为:
