从决策树到xgboost(一)
文章目录
- 1 决策树
-
- 1.1决策树定义
- 1.2信息增益
- 1.3 信息增益的算法
- 1.4 信息增益比
- 2 决策树ID3
-
- 2.1 ID3树的构建
- 2.2 决策树的剪枝
-
- 2.2.1 损失函数定义与计算
- 2.2.2 剪枝过程
- 2.3 CART树
-
- 2.3.1 CART回归树
- 2.3.2 CART分类树
- 2.3.3 CART树剪枝
1 决策树
1.1决策树定义
决策树的基本组成:决策节点、分支、叶子。

决策树表示给定特征条件下的概率分布。
条件概率分布定义在特征空间的一个划分上。将特征空间划分为互不相交的单元。并在每个单元上定义一个类的概率分布,就构成了一个条件概率分布。
决策树的一条路径对应于划分中的一个单元。
决策树的本质是在特征空间上的切割。
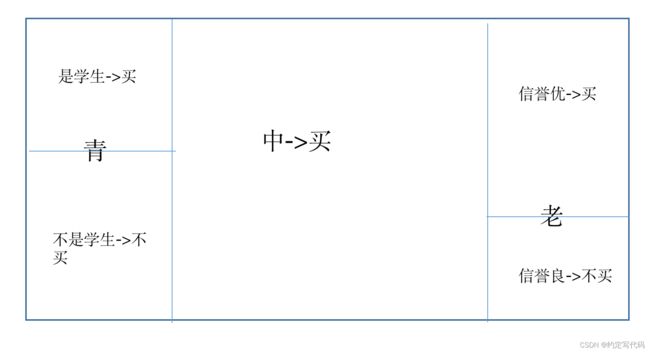
1.2信息增益
熵:设X是一个取有限个值的离散随机变量,其概率分布为: P ( X = x i ) = p i , i = 1 , 2 , 3... n P(X=x_i)=p_i,i=1,2,3...n P(X=xi)=pi,i=1,2,3...n
那么X的熵为: H ( X ) = − ∑ i = 1 n p i l o g p i H(X)=-\sum_{i=1}^np_ilogp_i H(X)=−∑i=1npilogpi
对数以2为底或者以e为底,这时熵的单位称为比特或者纳特。熵只依赖于X的分布,而与X的具体取值无关。
熵的理论解释:熵越大,随机变量的不确定性越大。 0 < = H ( X ) < = l o g n 0<=H(X)<=logn 0<=H(X)<=logn.
例如,一个骰子6个面全是1,那么 H ( X ) = − 1 ∗ l o g 1 = 0 H(X)=-1*log1=0 H(X)=−1∗log1=0。因为结果是确定的。
如果6个面分别为1,2,3,4,5,6,并且每个面的概率相同,都是 1 6 \dfrac{1}{6} 61。那么 H ( X ) = − ( 1 6 l o g ( 1 6 ) + 1 6 l o g ( 1 6 ) + 1 6 l o g ( 1 6 ) + 1 6 l o g ( 1 6 ) + 1 6 l o g ( 1 6 ) + 1 6 l o g ( 1 6 ) ) = − ( 0.17 ∗ ( − 2.58 ) ∗ 6 ) = 2.58 H(X)=-(\dfrac{1}{6}log(\dfrac{1}{6})+\dfrac{1}{6}log(\dfrac{1}{6})+\dfrac{1}{6}log(\dfrac{1}{6})+\dfrac{1}{6}log(\dfrac{1}{6})+\dfrac{1}{6}log(\dfrac{1}{6})+\dfrac{1}{6}log(\dfrac{1}{6}))=-(0.17*(-2.58)*6)=2.58 H(X)=−(61log(61)+61log(61)+61log(61)+61log(61)+61log(61)+61log(61))=−(0.17∗(−2.58)∗6)=2.58,这个时候的不确定性就比刚才要高。
设有随机变量(X,Y),其联合概率分布为 P ( X = x i , Y = y i ) = p i , j , i = 1 , 2 , 3... n ; j = 1 , 2 , 3... m P(X=x_i,Y=y_i)=p_{i,j},i=1,2,3...n; j=1,2,3...m P(X=xi,Y=yi)=pi,j,i=1,2,3...n;j=1,2,3...m
条件熵H(Y|X):表示在已知随机变量X的条件下,Y的不确定性。定义为X给定条件下Y的条件概率分布的熵对X的数学期望: H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) H(Y|X)=\sum_{i=1}^np_iH(Y|X=x_i) H(Y∣X)=∑i=1npiH(Y∣X=xi)
当熵和条件熵,由数据估计得到时,分别称为经验熵与经验条件熵。
信息增益:特征A对训练数据集D的信息增益g(D,A)定义为:集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差: g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
这表示了特征X的引入,使得分类Y的不确定性减少的程度。
互信息=信息熵H(Y)-条件熵H(Y|X)
1.3 信息增益的算法
设训练数据集为D
|D|表示其样本容量,即样本个数
设有K个类 C k C_k Ck,k=1,2,3…K
∣ C k ∣ |C_k| ∣Ck∣表示属于类 C k C_k Ck的样本数
特征A有n个不同的取值{ a 1 , a 2 , . . . a n a_1,a_2,...a_n a1,a2,...an}。根据特征A的取值,将D划分为n个子集 D 1 , D 2 . . . D n D_1,D_2...D_n D1,D2...Dn。
∣ D i ∣ |D_i| ∣Di∣为子集 D i D_i Di的样本个数
子集 D i D_i Di中属于类 C k C_k Ck的样本集合为 D i k D_{ik} Dik
∣ D i k ∣ |D_{ik}| ∣Dik∣为集合 D i k D_{ik} Dik的样本数
输入:数据集D,以及特征A
输出:特征A对数据集的信息增益g(D,A)
1 计算数据集D的经验熵H(D): H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ l o g 2 ∣ C k ∣ ∣ D ∣ H(D)=-\sum_{k=1}^K\dfrac{|C_k|}{|D|}log_2\dfrac{|C_k|}{|D|} H(D)=−∑k=1K∣D∣∣Ck∣log2∣D∣∣Ck∣
2 计算特征A对数据集D的经验条件熵H(D|A): H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ k = 1 K ∣ D i k ∣ ∣ D i ∣ l o g 2 ∣ D i k ∣ ∣ D i ∣ H(D|A)=\sum_{i=1}^n\dfrac{|D_i|}{|D|}H(D_i)=\sum_{i=1}^n\dfrac{|D_i|}{|D|}\sum_{k=1}^K\dfrac{|D_{ik}|}{|D_i|}log_2\dfrac{|D_{ik}|}{|D_i|} H(D∣A)=∑i=1n∣D∣∣Di∣H(Di)=∑i=1n∣D∣∣Di∣∑k=1K∣Di∣∣Dik∣log2∣Di∣∣Dik∣
3 计算信息增益g(D,A): g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
1.4 信息增益比
以信息增益来选择特征,会倾向于选择特征取值多的特征。可以使用信息增益比来解决这个问题。
特征A对数据集D的信息增益比定义为信息增益与训练数据集D关于特征A的值的熵的比: g R ( D , A ) = g ( D , A ) H A ( D ) g_R(D,A)=\dfrac{g(D,A)}{H_A(D)} gR(D,A)=HA(D)g(D,A)
H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ l o g 2 ∣ D i ∣ ∣ D ∣ H_A(D)=-\sum_{i=1}^n\dfrac{|D_i|}{|D|}log_2\dfrac{|D_i|}{|D|} HA(D)=−∑i=1n∣D∣∣Di∣log2∣D∣∣Di∣,n为特征A的取值个数
2 决策树ID3
2.1 ID3树的构建
按照信息增益选择特征,形成的决策树称为ID3树。
输入:训练数据集D、特征集合A、阈值 ϵ \epsilon ϵ
输出:决策树T
1 若D中所有实例属于同一类 C k C_k Ck,则T为单节点树,并将类 C k C_k Ck作为该节点的类标签,返回T;
2 若 A = ∅ A=\empty A=∅,则T为单节点树,并选择D中实例数最大的类 C k C_k Ck作为该节点的类标签,返回T;
3 按照信息增益的算法,计算特征集合A中每个特征对D的信息增益,选择信息增益最大的特征 A g A_g Ag;
4 如果 A g A_g Ag的信息增益小于阈值 ϵ \epsilon ϵ,则T为单节点树,并选择D中实例数最大的类 C k C_k Ck作为该节点的类标签,返回T;
5 否则,对 A g A_g Ag的每一个可能的值 a i a_i ai,依 A g = a i A_g=a_i Ag=ai将D分割为若干非空子集 D i D_i Di,将 D i D_i Di中实例数最大的类作为节点标记,构建子节点。由节点及其子节点构成树T,返回T;
6 对第i个子节点,以数据集 D i D_i Di作为训练集,以A-{ A g A_g Ag}为特征集,递归地调用步骤1-5,得到子树 T i T_i Ti,返回 T i T_i Ti。
2.2 决策树的剪枝
2.2.1 损失函数定义与计算
通过极小化 决策树整体的损失函数 来实现。
设树|T|的叶子节点个数为|T|,t是树T的叶子节点,该叶子节点有 N t N_t Nt个样本。其中k类的样本量为 N t k N_{tk} Ntk,k=1,2,3…K。
说明:一棵树T的叶子节点不一定只包含一类数据。例如在上述步骤2和5,就可能一个节点中实际存在多个类别的数据。只是因为再细分特征的信息增益太小了,不再划分。
H t ( T ) H_t(T) Ht(T)为叶子节点t上的经验熵, α > = 0 \alpha>=0 α>=0为参数,
损失函数: C α ( T ) = ∑ i = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ C_{\alpha}(T)=\sum_{i=1}^{|T|}N_tH_t(T)+\alpha|T| Cα(T)=∑i=1∣T∣NtHt(T)+α∣T∣
说明:树的损失函数对所有叶子节点的遍历。每一个叶子节点计算:当前叶子节点个数 N t N_t Nt,以及叶子节点的熵 H t ( T ) H_t(T) Ht(T)。它们的乘积表示当前叶子节点不确定的度量,也就是损失。对所有叶子节点不确定性的度量,就称为树的损失。
α ∣ T ∣ \alpha|T| α∣T∣是为了防止树过拟合。
∑ i = 1 ∣ T ∣ N t H t ( T ) \sum_{i=1}^{|T|}N_tH_t(T) ∑i=1∣T∣NtHt(T)熵越小,说明叶子节点越来越多,这一部分会使得模型越来越复杂。 α ∣ T ∣ \alpha|T| α∣T∣是为了对抗模型过渡复杂。
经验熵: H t ( T ) = − ∑ k N t k N t l o g N t k N t H_t(T)=-\sum_k\dfrac{N_{tk}}{N_t}log\dfrac{N_{tk}}{N_t} Ht(T)=−∑kNtNtklogNtNtk
C ( T ) = ∑ i = 1 ∣ T ∣ N t H t ( T ) = − ∑ i = 1 ∣ T ∣ ∑ k = 1 K N t k l o g N t k N t C(T)= \sum_{i=1}^{|T|}N_tH_t(T)=-\sum_{i=1}^{|T|}\sum_{k=1}^KN_{tk}log\dfrac{N_{tk}}{N_t} C(T)=∑i=1∣T∣NtHt(T)=−∑i=1∣T∣∑k=1KNtklogNtNtk
那么 C α ( T ) = C ( T ) + α ∣ T ∣ C_{\alpha}(T)=C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣
2.2.2 剪枝过程
输入:决策树T,参数 α \alpha α
输出:剪枝后的子树 T α T_{\alpha} Tα
1 计算每个节点的经验熵
2 递归地从树的叶子结点向上缩
设一组叶子节点回缩到其父节点之前与之后的损失函数分别为: C α ( T B ) C_{\alpha}(T_B) Cα(TB), C α ( T A ) C_{\alpha}(T_A) Cα(TA)
如果: C α ( T A ) C_{\alpha}(T_A) Cα(TA)<= C α ( T B ) C_{\alpha}(T_B) Cα(TB),则进行剪枝。
3 返回2,直至不能继续为止,得到损失最小的子树 T a T_a Ta。
以上过程将信息增益,换成信息增益比,那么得到的树就是C4.5。
2.3 CART树
CART是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法。
CART树是一棵二叉树。左分支的取值为是,右分支的取值为否。
这样的决策树等价于递归地二分每个特征,将输入空间划分为有限个单元,并在这些单元上确定预测的概率分布。
CART算法=决策树生成 + 决策树剪枝
2.3.1 CART回归树
- 树的定义
设Y是连续变量,给定训练数据集: D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . ( x n , y n ) } D=\{(x_1,y_1),(x_2,y_2),...(x_n,y_n)\} D={(x1,y1),(x2,y2),...(xn,yn)}, y i ∈ R y_i \in R yi∈R 。假设已经将输入空间划分为M个单元R1,R2…Rm,每个单元上 R m R_m Rm上有一个固定的输出 C m C_m Cm,则回归树表示为: f ( x ) = ∑ m = 1 M C m I ( x ∈ R m ) f(x)=\sum_{m=1}^MC_mI(x\in R_m) f(x)=∑m=1MCmI(x∈Rm)
备注:遍历所有分割的子空间,数据属于某个子空间,函数值就是该空间的输出值。
- 求解每个单元上的最优输出值
平方误差来表示预测误差,用平方误差最小准则求解每个单元上的最优输出值: ∑ x i ∈ R m ( y i − f ( x ) ) 2 \sum_{x_i \in R_m}(y_i-f(x))^2 ∑xi∈Rm(yi−f(x))2
那么 R m R_m Rm上的 C m C_m Cm的最优值怎么计算呢? c m ^ = a v e ( y i ∣ x i ∈ R m ) \hat{c_m} = ave(y_i|x_i \in R_m) cm^=ave(yi∣xi∈Rm) 使用落在 R m R_m Rm空间内所有点的y值求平均得到。
- 如何对输入空间进行划分
使用启发式选择的方法。
选择第j个变量 x ( j ) x^{(j)} x(j)和它的取值s,作为切分变量和切分点,定义两个区域,一个是比s小的,一个是比s大的: R 1 = { x ∣ x ( j ) < = s } R_1=\{x|x^{(j)}<=s\} R1={x∣x(j)<=s}, R 2 = { x ∣ x ( j ) > s } R_2=\{x|x^{(j)}>s\} R2={x∣x(j)>s}
寻找最优切分变量和切分点:
m i n j , s [ m i n e 1 ∑ x i ∈ R 1 ( y i − c 1 ) 2 + m i n e 2 ∑ x i ∈ R 2 ( y i − c 2 ) 2 ] min_{j,s}[min_{e_1}\sum_{x_i \in R_1}(y_i-c_1)^2+min_{e2}\sum_{x_i\in R_2}(y_i-c_2)^2] minj,s[mine1∑xi∈R1(yi−c1)2+mine2∑xi∈R2(yi−c2)2]
c 1 ^ = a v e ( y i ∣ x i ∈ R 1 ) \hat{c_1}=ave(y_i|x_i\in R_1) c1^=ave(yi∣xi∈R1)
c 2 ^ = a v e ( y i ∣ x i ∈ R 2 ) \hat{c_2}=ave(y_i|x_i\in R_2) c2^=ave(yi∣xi∈R2)
使得两部分误差和最小的变量j和切分点s
需要对所有变量和所有切分点遍历。(这是NP问题吧)
再对两个区域重复上述划分,直到满足停止条件。
总结成算法是这样的:最小二乘回归树生成算法。
输入:训练数据集D
输出:回归树f(x)
在训练数据集所在的输入空间中,递归地将每个区域划分为2个子区域,并决定每个子区域上的输出值,构建二叉决策树。
1 选择最优切分变量j和切分点s,求解
m i n j , s [ m i n e 1 ∑ x i ∈ R 1 ( y i − c 1 ) 2 + m i n e 2 ∑ x i ∈ R 2 ( y i − c 2 ) 2 ] min_{j,s}[min_{e_1}\sum_{x_i \in R_1}(y_i-c_1)^2+min_{e2}\sum_{x_i\in R_2}(y_i-c_2)^2] minj,s[mine1∑xi∈R1(yi−c1)2+mine2∑xi∈R2(yi−c2)2]
遍历变量j,对固定的切分变量j扫描切分点s,选择使得上式达到最小值的对(j,s)
2 用选定的对(j,s)划分区域,并决定相应的输出值:
R 1 = { x ∣ x ( j ) < = s } R_1=\{x|x^{(j)}<=s\} R1={x∣x(j)<=s}
R 2 = { x ∣ x ( j ) > s } R_2=\{x|x^{(j)}>s\} R2={x∣x(j)>s}
c m ^ = 1 N m ∑ x i ∈ R m ( j , s ) y i \hat{c_m}=\dfrac{1}{N_m}\sum_{x_i\in R_m(j,s)}y_i cm^=Nm1∑xi∈Rm(j,s)yi, x ∈ R m , m = 1 , 2 x\in R_m,m=1,2 x∈Rm,m=1,2
每个子空间数据的y的平均值作为空间的输出。
3 继续对2个子区域调用步骤1,2,直到满足停止条件
4 将输入空间划分为M个区域 R 1 , R 2 , . . . R M R_1,R_2,...R_M R1,R2,...RM,生成决策树: f ( x ) = ∑ m = 1 M C m I ( x ∈ R m ) f(x)=\sum_{m=1}^MC_mI(x\in R_m) f(x)=∑m=1MCmI(x∈Rm)
2.3.2 CART分类树
选择依据基尼指数
假设有K个分类,每个样本点属于分类k的概率是 P k P_k Pk。则概率分布的基尼指数: G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum_{k=1}^K p_k(1-p_k)=1-\sum_{k=1}^Kp_k^2 Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2
对于二分类 G i n i ( p ) = 2 p ( 1 − p ) Gini(p)=2p(1-p) Gini(p)=2p(1−p)
对于给定数据集的基尼指数: G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D)=1-\sum_{k=1}^K(\dfrac{|C_k|}{|D|})^2 Gini(D)=1−∑k=1K(∣D∣∣Ck∣)2
如果样本集合D根据特征A是否为a,划分为数据集D1,和数据集D2。
D 1 = { ( x , y ) ∈ D ∣ A ( x ) = a } D_1=\{(x,y)\in D|A(x)=a\} D1={(x,y)∈D∣A(x)=a}
D 2 = D − D 1 D_2=D-D_1 D2=D−D1
在特征A下,集合D的基尼指数为: G i n i ( D ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D)=\dfrac{|D_1|}{|D|}Gini(D_1)+\dfrac{|D_2|}{|D|}Gini(D_2) Gini(D)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
CART分类树生成算法
输入:训练数据集D,停止计算条件
输出:CART分类树
从根节点开始,递归对每个结点操作。
1、设结点数据集为D,对每个特征A,对其每个值a,根据样本点对A=a的测试为是或否,将D分为D1,D2,计算A=a的基尼指数
2、在所有的特征A以及所有可能的切分点a中,选择基尼指数最小的特征和切分点,将数据集分配到两个子结点中。
3、对两个子结点递归调用1,2步骤
算法停止的条件是:节点中的样本个数小于阈值,或者样本集的基尼指数小于阈值。
2.3.3 CART树剪枝
计算子树的损失函数: C α ( T ) = C ( T ) + α ∣ T ∣ C_{\alpha}(T)=C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣
当 α \alpha α很大的时候,这样得到的会是一棵偏小的决策树。也就是叶子节点少的决策树。
α \alpha α从0到一个较大的值的过程中可以生成很多颗树。选择最优的子树 T α T_{\alpha} Tα