python爬取下来的数据保存csv文件怎么加title_我的实战经验分享:深入浅出Python数据库操作...
本篇适合刚入门Python、已经学习了一些基础,想要关联学习数据库相关操作的朋友们~
先前听到一些朋友的反馈说,Python语言本身是很轻松地入门了,
但在做数据储存的时候,
比如做爬虫爬取到的数据,想要把暂时保存在内存中的数据永久保存起来,
究竟往哪存,怎么存,就有些困惑了。
“with open()”存到本地文件是相对简单的处理,
爬取到的数据大多是结构化的,直接存取文件可能不是效率最高的方法,
但面对数据库,了解到使用数据库的优点之后,
总会感觉与数据库之间似乎还隔了一层神秘面纱,有些难入门。
其实细说下来,也不过如此,本篇会循序递进跟大伙儿聊聊实战经验,
练习实际操作,然后发出“so easy!”的感叹~
看过我图文的朋友大概会了解,是比较倾向于“授之以渔”的,
本篇也一样,除了说说关键点外,
会给很多资料传送门,明确方向方便大伙儿深入了解。
咱话不多说,直接进入主题吧!

在实操之前,我们稍微先提一下环境配置什么的。
这里建议大伙儿测试的时候搭配使用Anaconda 3
(之前发的图文《 安装环境配置,以及如何编译exe可执行程序(上篇) - Python高手成长路(系列)(第1阶段) 》可以参考),
使用里面自带的一款非常方便学习测试的IDE,叫 Jupyter Notebook(以下简称Notebook)。

图:Jupyter Notebook 的Logo
我能想到的用Jupyter Notebook练习的好处:
· 可以交互式操作,输入一段运行立即能得到运行结果,也能一直保留运行时的内存数据
· 同个笔记文件中,每段代码的运行结果都可以随时保存起来,下次再打开时也可以查看结果内容
· 对比官方原版搭配的IDLE,它界面流畅,而且操作上方便太多,而且还有能写Markdown、显示图表图像等等的加分功能
· 除了默认支持的Python外,还支持R、Julia、Scala等40多款程序语言(支持列表传送门:https://github.com/jupyter/jupyter/wiki/Jupyter-kernels )
但Jupyter Notebook它也是有缺点的:
· 运行起来可能不是特别快速,虽然做机器学习研究等等一些情景下用它会很方便,但由于软件是前后端分离的形式,后端回传结果到前端网页的过程有一定的性能损失
· 不太适合用做生产用途,对比另一款IDE,PyCharm,项目开发更适合使用后者这款
这里我们尽可能地减少安装环境配置等等的影响,
不同系统上具体操作的差别不会太大。
这里假定使用的是Win10,官网下载安装完成后,
在开始菜单找到Notebook并点开它。
默认配置下,点开后会出现一个黑底白字的控制台窗口,
然后自动调出系统默认浏览器弹出Notebook的主界面窗口。

图:Jupyter Notebook的网页界面和控制台界面
Notebook黑底白字的控制台窗口,在用的过程中千万不能关闭它,
最小化它即可,不必太多理会。
网络上有非常多的Notebook基本操作的指引
(网络资料传送门:https://zhuanlan.zhihu.com/p/33105153 )
这里不再赘述啦。
上图是我新建了一个文件夹,在里面新建了一个ipynb文件(统一称为Notebook文件)。
OK!实验环境准备就绪,可以继续下一步啦。
01
情景1:爬虫爬取了一些数据,已经整理成清单,怎样存进数据库里面呢?这里演示时用了一些新闻数据。
根据我的演示内容,目前只抓取一个页面上的部分数据,
然后整理出了“分类,标题,点击数,链接”共4个字段。
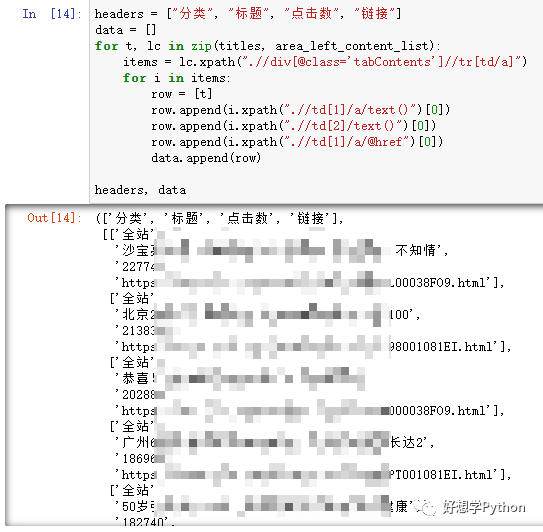
图:演示用的部分代码和数据(完整代码数据见GitHub)
数据量确实也不太多的样子,如果用自带的 csv 模块写入到文件也不会太差。
写入标准格式的csv文件,代码不过五六行而已。
(csv模块官方文档传送门:https://docs.python.org/3/library/csv.html )
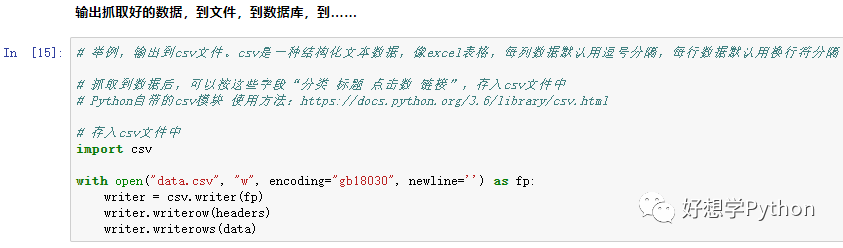
图:演示写入到csv文件
那么,
换成使用数据库会增加存取数据的操作成本吗?
会影响程序的运行效率,或者影响本机的性能吗?
答案或许是否定的。
Python自带了一个简单但非常有用的模块叫 sqlite3,
根据官方文档介绍(传送门:https://docs.python.org/3/library/sqlite3.html ),
它适合用于在本机上储存一些数据量不太大的内部数据,
而且对于Python来说,还有一点非常重要的优势是,
『容易迁移』,也就是说,后面改成用MySQL或者PostgreSQL都会很方便,
我们后面的情景会演示『容易迁移』这一点的。
在这种情景下,改成使用sqlite来存取数据有什么优势呢?
· 数据形式基本一致,都是二维的表格
· 存入csv文件的代码,可以很方便地改写成存入sqlite数据表的代码
· 对比csv文件,数据表的每一列可以指定数据类型,便于管理和使用
· 对比csv文件,利用SQL可以处理复杂数据,不需要一次性载入内存再做处理
· 对比csv文件,多了SQL语法语句的操作,支持模糊查询、索引加速等等
那怎么使用 sqlite3呢?
不同数据库还是有不少差别的,数据类型,SQL语法,等等。
因此首先需要查看相关资料了解一下sqlite本身的基本操作
(网络资料传送门:https://www.runoob.com/sqlite/sqlite-create-table.html )。
sqlite大概是最简单的关系型数据库了,
我们入手的时候尽量往简单里写,以后再深入了解把代码写得更强大。
了解完sqlite本身后,再了解一下在Python中的使用方式。
使用模式基本上离不开这3步:
· 连接数据库
· 操作数据
· 断开数据库
我们这里演示只演示把数据存入sqlite数据库文件的话,
也不外乎是这3步,只是其中多了一个叫“游标(Cursor)”的东东。
游标就像“指针”,增删改查都靠它!
先连接数据库,然后跟数据库申请一个游标对象,
再利用游标把数据依次写到数据库里面,so easy!
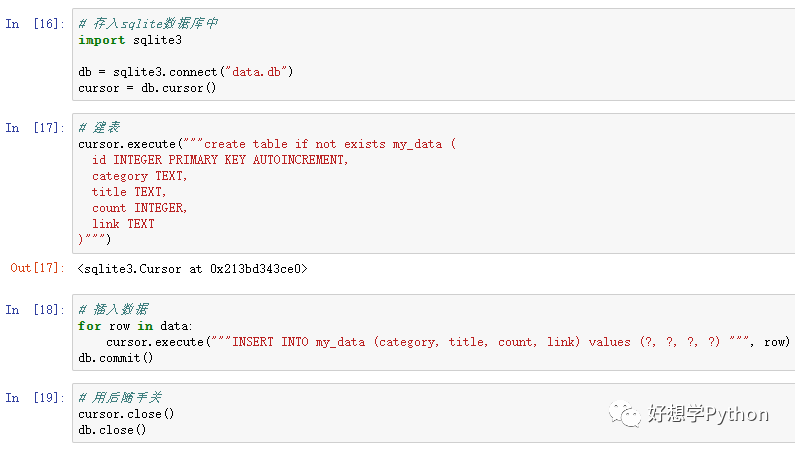
图:演示连接和写入到sqlite数据库
写进数据库后,怎样最直观地看到刚写入的数据内容呢?
除了可以再次利用刚才提到的游标,select查询一下数据内容,
也可以安装使用 SQLite Expert Personal 这款软件(个人免费使用),
图形界面操作,也可以在里面编写执行SQL对数据进行二次处理。
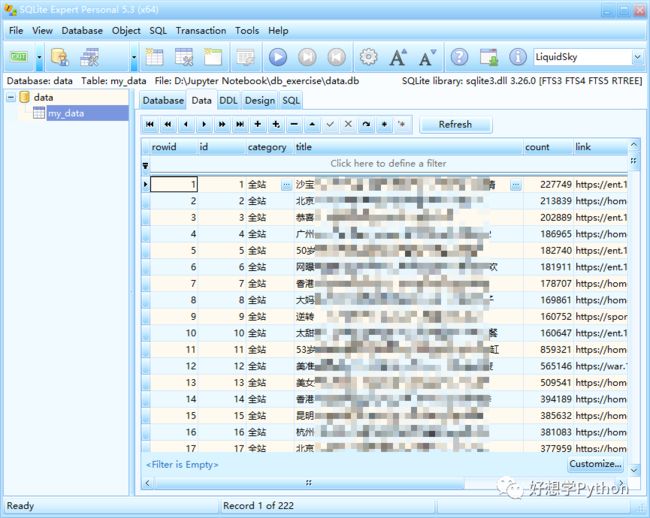
图:在 SQLite Expert Personal 中查看刚写入的数据
至此,sqlite已经基本入门了吧~
02
情景2:爬虫爬取的数据越来越多,sqlite数据库文件越滚越大,也满足不了一些更高级的使用需求了,可以快速地迁移到其他数据库上吗?“切换数据库”对IT运维人来说,有时确实是一个非常令人头大的问题,但对于我们个人使用来说,能否快速迁移,答案或许是肯定的,特别是数据规模还不太大的时候,而且!越早做迁移,痛苦越少~想象起来好像挺难的?其实并不难哦。我们先在目前主流的关系型数据库里面,挑选一款既简单又很强大的数据库软件来做试验,这里选的是跟MySQL同源的 MariaDB数据库,是开源的。(MariaDB官网: https://downloads.mariadb.org/mariadb/ )跟Anaconda 3类似,Win下有可以直接用的安装包, 安装MariaDB的过程中,别忘了设置好root用户的密码(root用户有最高权限),以及 别忘了给“用UTF-8作为服务器默认的字符集(Use UTF8 as default server's character set)”打上钩。 图:MariaDB 安装过程中需要注意的点安装完成后就可以直接在本机使用MariaDB数据库啦。我们还是尽量往简单里写,这里直接使用root用户操作 (不推荐直接使用root用户操作数据!这样不安全!) (不推荐直接使用root用户操作数据!这样不安全!) (不推荐直接使用root用户操作数据!这样不安全!) (重要的事情说三遍!)后面实际应用时,可以再深入了解一下数据库用户与权限这部分,给每个项目至少建立一个有限权限的用户,严格控制权限,以及项目之间除非必要,一般都要进行数据隔离。情景1里面提到 『容易迁移』,真的是这样的吗?确实可以!因为几乎所有的Python连接关系型数据库的模块,都是根据Python定的一个叫 “DB-API 2.0”的接口标准来写的,(官方文档传送门: https://www.python.org/dev/peps/pep-0249/ )最大的好处就是,非常方便地,我们不需要怎么改动代码就可以适用连接更多的数据库。
图:MariaDB 安装过程中需要注意的点安装完成后就可以直接在本机使用MariaDB数据库啦。我们还是尽量往简单里写,这里直接使用root用户操作 (不推荐直接使用root用户操作数据!这样不安全!) (不推荐直接使用root用户操作数据!这样不安全!) (不推荐直接使用root用户操作数据!这样不安全!) (重要的事情说三遍!)后面实际应用时,可以再深入了解一下数据库用户与权限这部分,给每个项目至少建立一个有限权限的用户,严格控制权限,以及项目之间除非必要,一般都要进行数据隔离。情景1里面提到 『容易迁移』,真的是这样的吗?确实可以!因为几乎所有的Python连接关系型数据库的模块,都是根据Python定的一个叫 “DB-API 2.0”的接口标准来写的,(官方文档传送门: https://www.python.org/dev/peps/pep-0249/ )最大的好处就是,非常方便地,我们不需要怎么改动代码就可以适用连接更多的数据库。 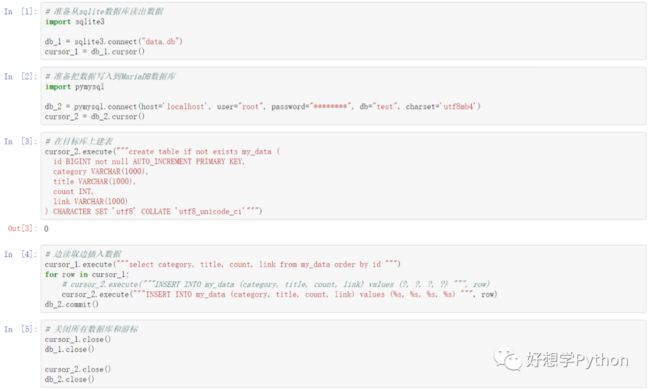 图:将先前存入sqlite数据库的数据,边读出边写入到MariaDB数据库中演示的代码可以看出,两种数据库调用的方法函数什么的基本都一样,可以 从sqlite的代码一比一复制过去,再根据 pymysql模块的文档(传送门: https://pymysql.readthedocs.io/en/latest/ )以及MariaDB的参考资料(网络资料传送门: https://www.w3cschool.cn/mariadb/ ) 稍微改一改代码,就可以用上了,还是so easy,是不?同样问题,写进数据库后,怎样最直观地看到刚写入的数据内容呢?依然是“游标”,select查询一下数据内容,或者使用非常经典的Navicat,进行图形界面操作,它也支持连接多款数据库软件,功能也相当强大的说 。
图:将先前存入sqlite数据库的数据,边读出边写入到MariaDB数据库中演示的代码可以看出,两种数据库调用的方法函数什么的基本都一样,可以 从sqlite的代码一比一复制过去,再根据 pymysql模块的文档(传送门: https://pymysql.readthedocs.io/en/latest/ )以及MariaDB的参考资料(网络资料传送门: https://www.w3cschool.cn/mariadb/ ) 稍微改一改代码,就可以用上了,还是so easy,是不?同样问题,写进数据库后,怎样最直观地看到刚写入的数据内容呢?依然是“游标”,select查询一下数据内容,或者使用非常经典的Navicat,进行图形界面操作,它也支持连接多款数据库软件,功能也相当强大的说 。  图:在 Navicat 中查看刚写入的数据至此,MariaDB数据库,以及怎样操作数据迁移,都已经基本入门了吧~最后提一下 拓展方向, 大伙儿可以在评论区留言说说哪些是感兴趣的,以后会专门写图文来讲哈: · 数据库ORM工具,如 SQLAlchemy:ORM是“把关系数据库的表结构映射到对象上”的意思,操作那些对象就等同于操作数据本身,它其实是在各种数据库连接驱动之上再做了一层封装,下层换数据库时上层代码基本不用做太大的改动,它都能自如应付,具体可以参考廖老师博客的文章(网络资料传送门: https://www.liaoxuefeng.com/wiki/897692888725344/955081460091040 ) · 非关系型数据库,如 MongoDB:储存数据的结构叫BSON,是一种类似JSON的结构,应用情景比如,经常爬取JSON结构的数据,用它来存取数据会方便很多,具体可以参考网络上的教程(网络资料传送门: https://www.runoob.com/mongodb/mongodb-tutorial.html ) · 复杂的SQL操作,是需要经验积累的,如果先前没怎么接触数据库,可以先从最简单的操作开始试验(网络资料传送门: https://www.runoob.com/sql/sql-tutorial.html ),然后找题库平台(比如力扣的,传送门: https://leetcode-cn.com/problemset/database/ )上数据库专题的题目多实操一下,很快就可以积累起来的 最后的最后,附上本篇实操练习的GitHub repo: https://github.com/djun/db_exercise
图:在 Navicat 中查看刚写入的数据至此,MariaDB数据库,以及怎样操作数据迁移,都已经基本入门了吧~最后提一下 拓展方向, 大伙儿可以在评论区留言说说哪些是感兴趣的,以后会专门写图文来讲哈: · 数据库ORM工具,如 SQLAlchemy:ORM是“把关系数据库的表结构映射到对象上”的意思,操作那些对象就等同于操作数据本身,它其实是在各种数据库连接驱动之上再做了一层封装,下层换数据库时上层代码基本不用做太大的改动,它都能自如应付,具体可以参考廖老师博客的文章(网络资料传送门: https://www.liaoxuefeng.com/wiki/897692888725344/955081460091040 ) · 非关系型数据库,如 MongoDB:储存数据的结构叫BSON,是一种类似JSON的结构,应用情景比如,经常爬取JSON结构的数据,用它来存取数据会方便很多,具体可以参考网络上的教程(网络资料传送门: https://www.runoob.com/mongodb/mongodb-tutorial.html ) · 复杂的SQL操作,是需要经验积累的,如果先前没怎么接触数据库,可以先从最简单的操作开始试验(网络资料传送门: https://www.runoob.com/sql/sql-tutorial.html ),然后找题库平台(比如力扣的,传送门: https://leetcode-cn.com/problemset/database/ )上数据库专题的题目多实操一下,很快就可以积累起来的 最后的最后,附上本篇实操练习的GitHub repo: https://github.com/djun/db_exercise

以上,希望对你有所帮助~


我是DJun(小丁),码龄19年,从事IT工作6年,踩过无数“语言”坑最后入坑Python,想通过公众号,把自己的成长经历与经验分享给朋友们。
同名酷安看看号“好想学Python”已开通,欢迎订阅。
相关推荐>>> 解谜了!Python 装饰器的魔法
>>> “鸭子类型”,因吹丝挺!- Python & Go
>>> 那么,办公室萌新可以跟Python碰撞出怎样的火花?
>>> Python从哪里开始学好呢?
>>> 网络爬虫与网页自动化操作:最小化版系统学习的大纲
