PyTorch - 22 - 使用PyTorch进行CNN图像预测 - 解释正向传播
PyTorch - 22 - 使用PyTorch进行CNN图像预测 - 解释正向传播
- What Is Forward Propagation?
- Predicting With The Network: Forward Pass
- Passing A Single Image To The Network
- Network Weights Are Randomly Generated
- Using The Data Loader To Pass A Batch Is Next
What Is Forward Propagation?
正向传播是将输入张量转换为输出张量的过程。神经网络的核心是将输入张量映射到输出张量的功能,而正向传播只是将输入传递到网络并从网络接收输出的过程的特殊名称。

如我们所见,神经网络以张量形式对数据进行操作。前向传播的概念用于指示输入张量数据是通过网络在前向方向上传输的。
对于我们的网络,这意味着简单地将输入张量传递到网络并接收输出张量。为此,我们将样本数据传递给网络的forward()方法。
这就是为什么forward()方法具有正向名称的原因,forward()的执行是正向传播的过程。
如果您正在关注该系列文章,那么现在我们知道,我们不会直接调用forward()方法,而是会调用网络实例。有关更多详细信息,请参见此剧集。
前进这个词很直截了当。 ;)
但是,“传播”一词是指通过某种媒介移动或传播。在神经网络的情况下,数据通过网络的各个层传播。
也有反向传播(backpropagation)的概念,这使得术语正向传播适合作为第一步。在训练过程中,反向传播发生在正向传播之后。
在我们的案例中,从实际角度出发,正向传播是将输入图像张量传递给我们在上一集中实现的forward()方法的过程。此输出是网络的预测。
在关于数据集和数据加载器的情节中,我们了解了如何从训练集中访问单个样本图像张量,更重要的是,如何从数据加载器访问一批图像张量。现在我们已经定义了我们的网络并实现了forward()方法,将图像传递到我们的网络以获得预测。
Predicting With The Network: Forward Pass
在此之前,我们将关闭PyTorch的渐变计算功能。当我们的张量流过网络时,这将阻止PyTorch自动构建计算图。

计算图通过跟踪每次发生的计算来跟踪网络的映射。该图在训练过程中用于计算损失函数相对于网络权重的导数(梯度)。
由于我们尚未训练网络,因此我们不打算更新权重,因此不需要进行梯度计算。培训开始时,我们将重新打开此功能。
随着计算的发生,跟踪计算的过程实时发生。记得在本系列开始时,我们曾说过PyTorch使用动态计算图。现在,我们将其关闭。
严格来说,将其关闭不是必需的,但是由于该图形未存储在内存中,因此关闭该功能确实会减少内存消耗。此代码将关闭该功能。
> torch.set_grad_enabled(False)
<torch.autograd.grad_mode.set_grad_enabled at 0x17c4867dcc0>
Passing A Single Image To The Network
让我们继续创建Network类的实例:
> network = Network()
接下来,我们将从训练集中获取一个样本,解压图像和标签,并验证图像的形状:
> sample = next(iter(train_set))
> image, label = sample
> image.shape
torch.Size([1, 28, 28])
图像张量的形状表示我们有一个单通道图像,其高度为28,宽度为28。很酷,这就是我们的期望。
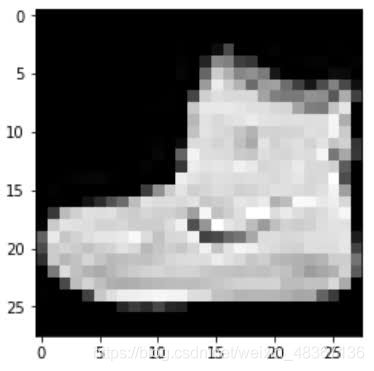
现在,我们必须执行第二步,然后才将张量传递到我们的网络。当我们将张量传递给我们的网络时,网络正在等待一批,因此即使我们要传递单个图像,我们仍然需要一批。
没问题我们可以创建一个包含单个图像的批处理。所有这些都将打包成一个单一的四维张量,以反映以下尺寸。
(batch_size,in_channels,高度,宽度)
对网络的这种要求来自以下事实:nn.Conv2d卷积层类中的forward()方法期望它们的进程具有4维。这是相当标准的,因为大多数神经网络实现都处理成批的输入样本,而不是单个样本。
要将单个样本图像张量放入大小为1的批处理中,我们只需要松开()张量即可添加一个额外的尺寸。我们在前几集中看到了如何执行此操作。
# Inserts an additional dimension that represents a batch of size 1
image.unsqueeze(0).shape
torch.Size([1, 1, 28, 28])
使用此工具,我们现在可以将未压缩的图像传递到我们的网络并获得网络的预测。
> pred = network(image.unsqueeze(0)) # image shape needs to be (batch_size × in_channels × H × W)
> pred
tensor([[0.0991, 0.0916, 0.0907, 0.0949, 0.1013, 0.0922, 0.0990, 0.1130, 0.1107, 0.1074]])
> pred.shape
torch.Size([1, 10])
> label
9
> pred.argmax(dim=1)
tensor([7])
而我们做到了!我们使用了前向方法从网络中获取预测。网络已返回一个预测张量,其中包含针对十种服装的每一种的预测值。
预测张量的形状为1 x10。这告诉我们第一轴的长度为1,而第二轴的长度为10。对此的解释是,我们批次中有一张图像,并且有十个预测类。
(批次大小,预测类别数)
对于批次中的每个输入,以及每个预测类别,我们都有一个预测值。如果我们希望这些值是概率,则可以使用nn.functional软件包中的softmax()函数。
> F.softmax(pred, dim=1)
tensor([[0.1096, 0.1018, 0.0867, 0.0936, 0.1102, 0.0929, 0.1083, 0.0998, 0.0943, 0.1030]])
> F.softmax(pred, dim=1).sum()
tensor(1.)
训练集中第一张图像的标签为9,使用argmax()函数,我们可以看到预测张量中的最大值出现在由索引7表示的类上。
- 预测:运动鞋(7)
- 当前:脚踝靴(9)
请记住,每个预测类都由一个对应的索引表示。
| 索引 | 标签 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 头衫 |
| 3 | 礼服 |
| 4 | 外套 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 包 |
| 9 | 踝靴 |
这种情况下的预测是不正确的,这是我们期望的,因为网络中的权重是随机生成的。
Network Weights Are Randomly Generated
关于这些结果,我们需要指出一些重要的事情。 大多数概率接近10%,这是有道理的,因为我们的网络正在猜测,并且我们有十个来自平衡数据集的预测类。
随机生成的权重的另一个含义是,每次我们创建网络的新实例时,网络内的权重都会不同。 这意味着,如果我们创建不同的网络,我们得到的预测将有所不同。 请记住这一点。 您的预测将与我们在此处看到的有所不同。
> net1 = Network()
> net2 = Network()
> net1(image.unsqueeze(0))
tensor([[ 0.0855, 0.1123, -0.0290, -0.1411, -0.1293, -0.0688, 0.0149, 0.1410, -0.0936, -0.1157]])
> net2(image.unsqueeze(0))
tensor([[-0.0408, -0.0696, -0.1022, -0.0316, -0.0986, -0.0123, 0.0463, 0.0248, 0.0157, -0.1251]])
Using The Data Loader To Pass A Batch Is Next
现在,我们准备将一批数据传递到我们的网络并解释结果。
现在,我们应该对什么是正向传播以及如何将单个图像张量传递给PyTorch中的卷积神经网络有一个很好的了解。 在下一篇文章中,我们将看到如何使用数据加载器将批处理传递给我们的网络。 我会在那里见你!