Python实现m3u8下载mp4视频原理及源码
Python实现m3u8下载mp4视频原理及源码
- python下载 m3u8 视频
-
- m3u8 视频文件原理
- python下载 m3u8 视频原理
- python 实现源码
python下载 m3u8 视频
使用python实现对m3u8视频文件的下载(MP4),下面是我根据个人理解所整理的m3u8文件的原理,以及下载原理和下载的源码,若有错误望大家评论指出
m3u8 视频文件原理
现在一个视频的大小在几百M到几个G,在网上播放视频我们不可能等待一个视频下载完成后再去观看。而是采用一边“缓冲”一边观看的方式,而实现这一方式常用的就是m3u8视频格式
- 将mp4视频文件切片为多个ts视频文件
- 网页从视频加载开始,依次下载ts文件,实现一边下载ts片段视频文件一边播放已经下载好的ts片段视频
- 每一个ts视频文件,相当于就是原mp4视频文件的一部分
- m3u8文件其实是一个列表文件,里面存放了一个mp4文件所切片下来的所有ts文件路径
- 网页加载视频就是根据m3u8里面对应的ts列表地址,去依次下载ts片段视频文件来实现一边“缓冲”一边播放已经“缓冲”好的视频(即下载好的ts片段视频)

python下载 m3u8 视频原理
经过上面的学习,我们已经知道了mp4文件其实就是被切片为了多个ts文件,然后ts文件的下载路径被整理为列表保存在了我们的m3u8文件当中
现在我们就应该明白,m3u8文件其实只是存放了我们所需要的ts文件的下载路径,而并非是一个视频文件
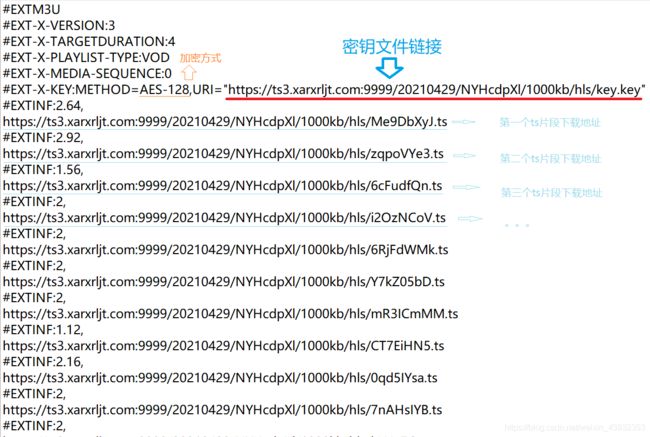
所以,我们只需要根据m3u8文件中的ts链接列表,依次下载ts文件。然后,我们将所有下载好的ts视频片段文件拼接起来,就是我们完整的mp4视频文件
大家可能注意到了上面图片中的加密方式,其实有一些m3u8的ts视频片段是存在加密的,而有些没有。对于使用了加密的视频一般都是采用的aes加密,我们只需要根据m3u8列表中给出的 key文件链接 去下载得到aes加密的key,然后根据key就可以对其进行解密啦
aes加密/解密在这就不做赘述了,可自行了解
注意:有一些m3u8文件里面的ts链接地址是不完整的需要拼接为完整链接
python 实现源码
- 自行安装模块
requests 请求模块,pip install requests
AES 解密模块,pip install pycryptodome (不要装错模块哦~) - 按需自行更改
线程池最大线程数按需自行调整 max_workers = 20
补发请求次数按需自行调整 max_request = 5 - 若 ts 链接不完整,需要自行更改 ts 的链接请求头 ts_url_title = ''
(由于一般的m3u8文件不存在这种情况,所以偷懒未作处理,缺失的链接头一般为m3u8链接的头部)
# m3u8视频下载
import os
import re
import time
import shutil
import requests
from concurrent.futures import ThreadPoolExecutor, wait
from Crypto.Cipher import AES
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML like Gecko) BrowserNG/7.1.18124'
}
def download_mp4(mp4_file_path, ts_url_list, ts_url_title):
'''下载ts文件并写入mp4文件
:param mp4_file_path: mp4文件名
:param ts_url_list: ts请求链接列表
:return:
'''
# 判断文件是否存在,存在则先清空
if os.path.exists(mp4_file_path):
with open(mp4_file_path, 'w') as fp:
fp.write('')
# 创建存放ts的文件夹
if not os.path.exists('ts'):
os.mkdir('ts')
print('开始下载{}...'.format(mp4_file_path))
excutor = ThreadPoolExecutor(max_workers=20) # 线程池
len_list = len(ts_url_list) # ts链接总数
all_tasks = [excutor.submit(lambda args: download_ts(*args), (ts_url_id, len_list, ts_url_list, ts_url_title))
for ts_url_id in range(len_list)] # 创建任务
wait(all_tasks) # 等待所有任务执行完成
# 检测ts数目是否正确
if len(os.listdir('ts')) == len_list:
pass
else:
print('ts文件部分缺失...')
# 删除存放ts的临时文件
shutil.rmtree('ts')
return ''
# ts合并为mp4文件
print('ts文件下载完成,正在合并ts文件...')
for ts_url_id in range(len_list):
ts_file_name = 'ts/{}.ts'.format(ts_url_id)
with open(ts_file_name, 'rb') as fp:
ts_content = fp.read() # 读取ts数据
with open(mp4_file_path, 'ab') as fp:
fp.write(ts_content) # 将ts数据追加写入文件
print('ts文件合并成功!')
# 删除存放ts的临时文件
shutil.rmtree('ts')
return 1
def download_ts(ts_url_id, len_list, ts_url_list, ts_url_title):
''' 请求下载ts文件
:param ts_url_id: 分区ts的id
:param len_list: ts个数
:param ts_url_list: 存放ts的列表
:param ts_url_title: ts链接拼接的头部
:return:
'''
print('{}/{}开始下载'.format(ts_url_id, len_list - 1))
# 请求不成功补发请求,最大补发次数为
max_request = 5 # 最大补发请求次数
for i in range(max_request):
try:
response = requests.get(url=ts_url_title + ts_url_list[ts_url_id],
headers=headers, timeout=(5, 20)) # 请求获取ts数据
if response.status_code == 200:
ts_content = response.content
break
except:
if i == max_request - 1:
print('{}/{}下载失败'.format(ts_url_id, len_list - 1))
return ''
else:
print('{}/{}下载失败,正在补发请求...'.format(ts_url_id, len_list - 1))
ts_file_name = 'ts/{}.ts'.format(ts_url_id)
with open(ts_file_name, 'wb') as fp:
fp.write(ts_content) # 将ts数据写入文件
print('{}/{}下载完成'.format(ts_url_id, len_list - 1))
def deciphering(key, fileName):
'''对aes加密视频进行解密
:param key: aes解密密钥
:param fileName: 需要解密的文件
:return:
'''
# 读取原文件
with open(fileName, 'rb') as fp:
part = fp.read()
# aes解密需要的偏移量
iv = b'0000000000000000'
# 解密数据
plain_data = AES.new(key, AES.MODE_CBC, iv).decrypt(part)
# 将解密数据写入文件
with open(fileName, 'wb') as fp:
fp.write(plain_data)
print('视频解密完成!')
def timer(start_time, end_time, mp4_file_name):
'''计时器
:param start_time: 开始时间
:param end_time: 结束时间
:return:
'''
spend_second = end_time - start_time
hour = str(int(spend_second / (60 * 60)))
minute = str(int(spend_second / 60))
second = str(int(spend_second % 60))
spend_time = '{}h{}m{}s'.format(hour, minute, second)
print('{}下载完成!用时:{}'.format(mp4_file_name, spend_time))
def start(m3u8_url, mp4_file_name, ts_url_title):
'''开始
:param m3u8_url: m3u8链接
:param mp4_file_path: 下载后的视频名称
:return:
'''
# 开始计时
start_time = time.time()
# 创建目录文件
if not os.path.exists('mv'):
os.mkdir('mv')
# 视频保存路径
mp4_file_path = 'mv/' + mp4_file_name + '.mp4'
# 获取m3u8内容
m3u8_file = requests.get(url=m3u8_url, headers=headers).text
# 整理ts列表
ts_url_list = re.findall(',\n(.*?)\n#', m3u8_file)
# 下载ts,并拼接为mp4文件
mp4 = download_mp4(mp4_file_path, ts_url_list, ts_url_title)
# 判断是否存在加密
if mp4 and re.search('#EXT-X-KEY', m3u8_file):
print('{}视频存在加密,正在对其进行解密,请稍后...'.format(mp4_file_path))
# 获取key
key_url = re.search('#EXT-X-KEY:(.*URI="(.*)")\n', m3u8_file)[2] # 获取key的url
key = requests.get(url=key_url, headers=headers).content # 请求获取key
# 解密视频
deciphering(key, mp4_file_path)
# 计时结束
end_time = time.time()
# 耗时统计
timer(start_time, end_time, mp4_file_name)
if __name__ == '__main__':
# m3u8 链接
m3u8_url = input('请输入m3u8链接:')
# ts链接头
ts_url_title = ''
# mp4 名称
mp4_file_name = input('请输入视频名称:')
# 执行下载
start(m3u8_url, mp4_file_name, ts_url_title)
希望对你有所帮助~