聚类评价CH指标sklearn.metrics.calinski_harabasz_score
目录
- Calinski-Harbasz Score (CH指标)
- Calinski-Harbasz Score的缺点
- 案例1
- 案例2
在做海量数据聚类分析(MiniBatch Kmeans)的时候,常常因为数据量太大画不出 dendrogram,没办法用 Elbow Method 确定 K 值。这时需要其他 metrics 辅助确定 K 值。在做聚类之前,一定要先做去重啊!
Calinski-Harbasz Score (CH指标)
Caliński, Tadeusz, and Jerzy Harabasz. “A dendrite method for cluster analysis.” Communications in Statistics-theory and Methods 3.1 (1974): 1-27.
-
Calinski-Harbasz Score 是通过评估 类之间方差 和 类内方差 来计算得分,值越大效果越好。
s = S S B k − 1 / S S W N − k = t r ( B k ) t r ( W k ) × N − k k − 1 s=\frac{SS_B}{k-1}/\frac{SS_W}{N-k}=\frac{tr(B_k)}{tr(W_k)}\times \frac{N-k}{k-1} s=k−1SSB/N−kSSW=tr(Wk)tr(Bk)×k−1N−k -
其中,
- k k k 代表聚类类别数, N N N 代表全部数据数目。
- S S B SS_B SSB 是类间方差,
- S S W SS_W SSW 是类内方差。
- B k B_k Bk 为 between-clusters dispersion mean(类间距离),
- W k W_k Wk 为 within-cluster dispersion(类内部的距离)
-
1) 计算 S S B SS_B SSB
:
S S B = t r ( B k ) SS_B=tr(B_k) SSB=tr(Bk)
其中, B k B_k Bk 的计算方式为
B k = ∑ q = 1 k n q ( c q − c E ) ( c q − c E ) T B_k=\sum^k_{q=1}n_q(c_q-c_E)(c_q-c_E)^T Bk=q=1∑knq(cq−cE)(cq−cE)T
trace 只考虑了矩阵对角上的元素,即 q q q 中所有数据点到类的欧几里得距离。- n q n_q nq 是类 q q q 数据点的总数
- c q c_q cq 是类 q q q 的质点
- c E c_E cE 是所有数据的中心点
-
2)计算 S S W SS_W SSW
:
S S W = t r ( W k ) SS_W=tr(W_k) SSW=tr(Wk)
其中, W k W_k Wk的计算方式为
W k = ∑ q = 1 k ∑ x ∈ C q ( x − c q ) ( x − c q ) T W_k=\sum^k_{q=1}\sum_{x\in C_q}(x-c_q)(x-c_q)^T Wk=q=1∑kx∈Cq∑(x−cq)(x−cq)T
其中,- C q C_q Cq 是类 q q q 中所有数据的集合
- c q c_q cq 是类 q q q 的质点
Calinski-Harbasz Score的缺点
在实际使用的过程中,发现类别越少,Calinski-Harbasz Score的分数越高,当 k=2 时,分数达到最高。但是30w数据分成2类也太敷衍了吧(抓狂)!于是开始研究这个 metrics 到底在评估什么东西。结论,当上述情况发生的时候,需要一个个 K 值去测试,找到一个local maxium(局部最高)的分数,这个分数对应的K值就是当前最佳的分类。根据:Calinski-Harabasz Index and Boostrap Evaluation with Clustering Methods
Calinski-Harbasz Score 衡量分类情况和理想分类情况(类之间方差最大,类内方差最小)之间的区别,归一化因子 ( N − k ) / ( k − 1 ) (N-k)/(k-1) (N−k)/(k−1)随着类别数 k k k 的增加而减少,使得该方法更偏向于选择类别少的分类结果。
这导致了在实验中 K=2,往往得到很高的分数,但是这不是我们想要的结果。
这时,我们需要去找另一个局部最优的 K K K。即使找到的 K K K 不是真正的分数最高,但是只要它们对应的得分显著高,我们都可以接受这样的值,如同梯度一样,我们有的时候并不能找到全局最优,但是局部最优的结果仍可以接受。
for i in range(2, 20):
y_pred = SpectralClustering(n_clusters=i, affinity='precomputed').fit_predict(data)
print(f"n_clusters={i},Calinski-Harabasz Score: {metrics.calinski_harabasz_score(df_10min, y_pred)}")
结果如下图所示:(个人感觉,选取方法可以参考肘部法)

案例1
import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn.cluster import KMeans
dataframe = pd.DataFrame(data=np.random.randint(0, 50, size=(200, 10)))
# 以kmeans聚类方法为例
kmeans_model = KMeans(n_clusters=3, random_state=1).fit(dataframe)
labels = kmeans_model.labels_
score = metrics.calinski_harabasz_score(dataframe, labels)
print(score)
sklearn.metrics.calinski_harabasz_score(X, labels)

案例2
这里我们用一个例子讲述下SpectralClustering的聚类。我们选择最常用的高斯核来建立相似矩阵,用K-Means来做最后的聚类。
完整代码参见github地址:
首先我们生成 500 个 6 维的数据集,分为 5 个簇。由于是 6 维,这里就不可视化了,代码如下:
import numpy as np
from sklearn import datasets
X, y = datasets.make_blobs(n_samples=500, n_features=6, centers=5, cluster_std=[0.4, 0.3, 0.4, 0.3, 0.4], random_state=11)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()

接着我们看看默认的谱聚类的效果:
from sklearn.cluster import SpectralClustering
y_pred = SpectralClustering().fit_predict(X)
from sklearn import metrics
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, y_pred))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, marker='.')
plt.show()

输出的Calinski-Harabasz分数为:
Calinski-Harabasz Score 14908.9325026
由于我们使用的是高斯核,那么我们一般需要对n_clusters和gamma进行调参。选择合适的参数值。代码如下:
for index, gamma in enumerate((0.01,0.1,1,10)):
for index2, k in enumerate((3,4,5,6)):
y_pred = SpectralClustering(n_clusters=k, gamma=gamma).fit_predict(X)
print("Calinski-Harabasz Score with gamma=", gamma, "n_clusters=", k,"score:", metrics.calinski_harabasz_score(X, y_pred))
输出如下:
Calinski-Harabasz Score with gamma= 0.01 n_clusters= 3 score: 1979.77096092
Calinski-Harabasz Score with gamma= 0.01 n_clusters= 4 score: 3154.01841219
Calinski-Harabasz Score with gamma= 0.01 n_clusters= 5 score: 23410.63895
Calinski-Harabasz Score with gamma= 0.01 n_clusters= 6 score: 19303.7340877
Calinski-Harabasz Score with gamma= 0.1 n_clusters= 3 score: 1979.77096092
Calinski-Harabasz Score with gamma= 0.1 n_clusters= 4 score: 3154.01841219
Calinski-Harabasz Score with gamma= 0.1 n_clusters= 5 score: 23410.63895
Calinski-Harabasz Score with gamma= 0.1 n_clusters= 6 score: 19427.9618944
Calinski-Harabasz Score with gamma= 1 n_clusters= 3 score: 687.787319232
Calinski-Harabasz Score with gamma= 1 n_clusters= 4 score: 196.926294549
Calinski-Harabasz Score with gamma= 1 n_clusters= 5 score: 23410.63895
Calinski-Harabasz Score with gamma= 1 n_clusters= 6 score: 19384.9657724
Calinski-Harabasz Score with gamma= 10 n_clusters= 3 score: 43.8197355672
Calinski-Harabasz Score with gamma= 10 n_clusters= 4 score: 35.2149370067
Calinski-Harabasz Score with gamma= 10 n_clusters= 5 score: 29.1784898767
Calinski-Harabasz Score with gamma= 10 n_clusters= 6 score: 47.3799111856
可见最好的 n_clusters 是 5,而最好的高斯核参数是 1 或者 0.1.
我们可以看看不输入可选的 n_clusters 的时候,仅仅用最优的 gamma 为 0.1 时候的聚类效果,代码如下:
y_pred = SpectralClustering(n_clusters=5, gamma=0.1).fit_predict(X)
print("Calinski-Harabasz Score", metrics.calinski_harabasz_score(X, y_pred))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, marker='.')
plt.show()
输出为:
Calinski-Harabasz Score 14950.4939717
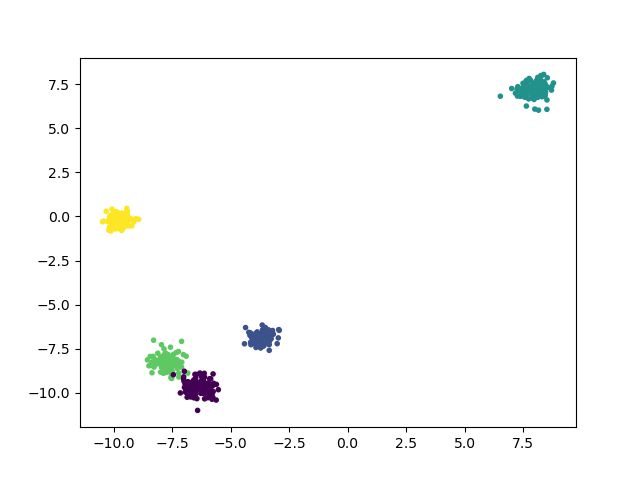
可见 n_clusters 一般还是调参选择比较好。
参考资料
[1] https://blog.csdn.net/chloe_ou/article/details/105277431
[2] https://blog.csdn.net/weixin_35757704/article/details/117549099