时间序列预测框架--Darts--快速开始(上)
时间序列框架-Darts
- 快速开始
-
- 安装Darts
- 构建和操作时间序列
-
- 读取数据并构建时间序列
- 一些时间序列操作
-
- splitting
- slicing
- arithmetic operations
- stacking
- mapping
- 同时在时间戳和值之间进行映射
- 添加一些datetime属性作为额外的维度(产生多元序列)
- 添加一些二进制节日组件:
- differencing(差分?)
- 填充缺失的值(使用' ' utils ' '函数)
- 构建训练序列和验证序列
- 训练预测模型并进行预测
-
- playing with toy models
-
- 检查季节性
- 一个稍微naive的模型
- 计算误差指标
- 快速尝试几个模型
-
- 用Theta方法搜索超参数
- 回测:模拟历史预测
- 机器学习和全局模型
-
- 两个序列的例子
- 使用深度学习:N-BEATS的例子
快速开始
安装Darts
pip 安装:
pip install darts
conda安装:
conda install -c conda-forge -c pytorch u8darts-all
首先引入一些包
%load_ext autoreload
%autoreload 2
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from darts import TimeSeries
from darts.datasets import AirPassengersDataset
构建和操作时间序列
TimeSeries是dart中的主要数据类。TimeSeries表示单变量或多变量时间序列,具有适当的时间索引。时间索引可以是pandas类型。DatetimeIndex(包含日期时间)或pandas类型。RangeIndex(包含整数;用于表示没有特定时间戳的顺序数据)。在某些情况下,TimeSeries甚至可以表示概率序列,例如,为了获得置信区间。dart中的所有模型都输入TimeSeries并输出TimeSeries。
读取数据并构建时间序列
使用一些factory方法可以轻松构建时间序列:
- 从一个完整的Pandas DataFrame,使用
TimeSeries.from_dataframe() - 从时间索引和相应值的数组中获取
TimeSeries.from_times_and_values() - 从NumPy值数组中,使用
TimeSeries.from_values() - 从Pandas系列中,使用
TimeSeries.from_series() - 从
xarray.DataArray,使用TimeSeries.from_xarray () - 从CSV文件,使用
TimeSeries.from_csv()
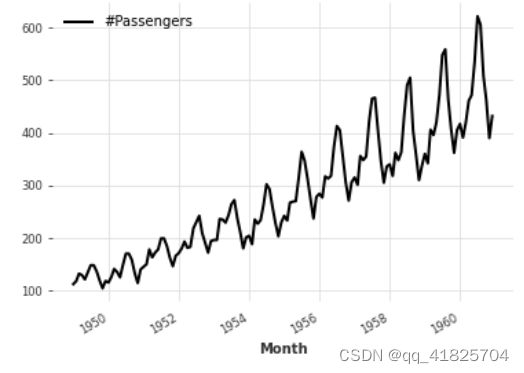
下面,我们通过直接从dart中提供的一个数据集加载航空乘客系列来获得TimeSeries
series = AirPassengersDataset().load()
series.plot()
一些时间序列操作
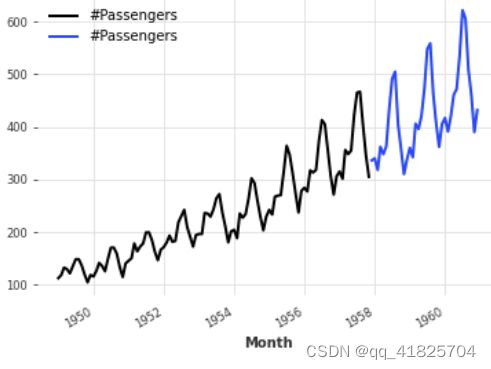
splitting
我们还可以以系列的一小部分、pands的时间戳或整数索引值进行分割
series1, series2 = series.split_before(0.75)
series1.plot()
series2.plot()
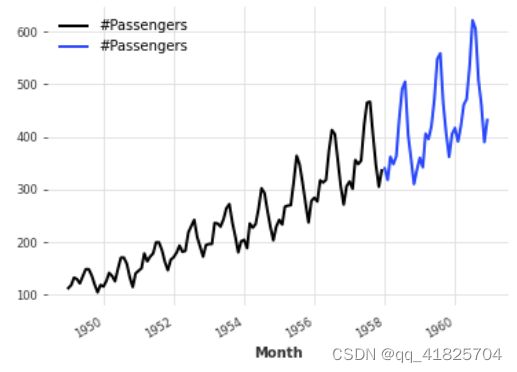
slicing
series1, series2 = series[:-36], series[-36:]
series1.plot()
series2.plot()
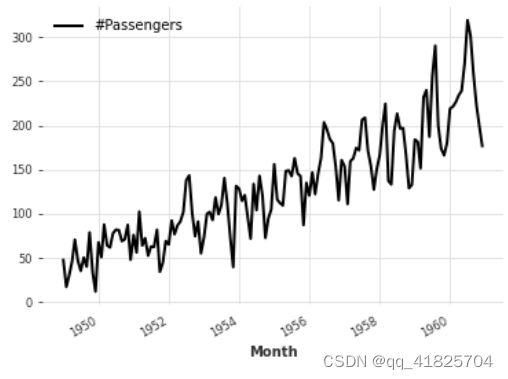
arithmetic operations
series_noise = TimeSeries.from_times_and_values(
series.time_index, np.random.randn(len(series))
)
(series / 2 + 20 * series_noise - 10).plot()
stacking
连接一个新的维度以产生一个新的单一的多元序列。
(series / 50).stack(series_noise).plot()
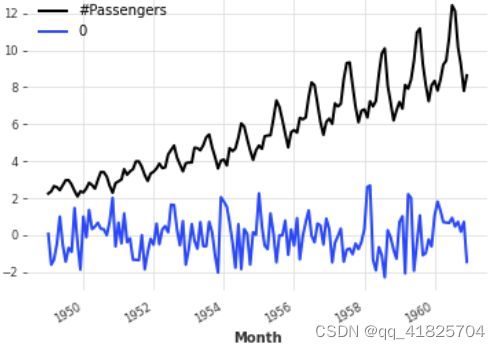
mapping
series.map(np.log).plot()
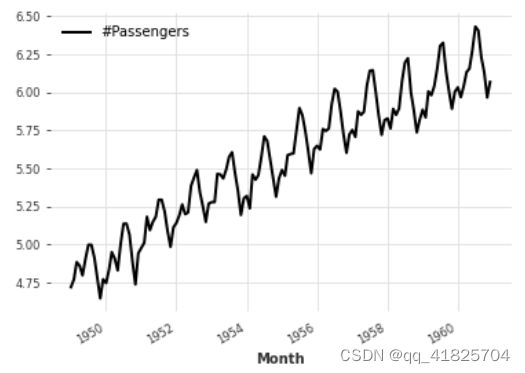
同时在时间戳和值之间进行映射
series.map(lambda ts, x: x / ts.days_in_month).plot()
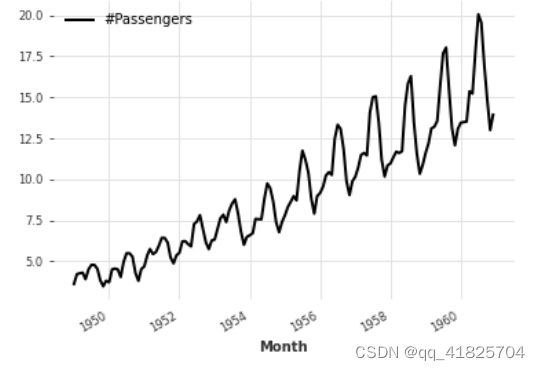
添加一些datetime属性作为额外的维度(产生多元序列)
(series / 20).add_datetime_attribute("month").plot()

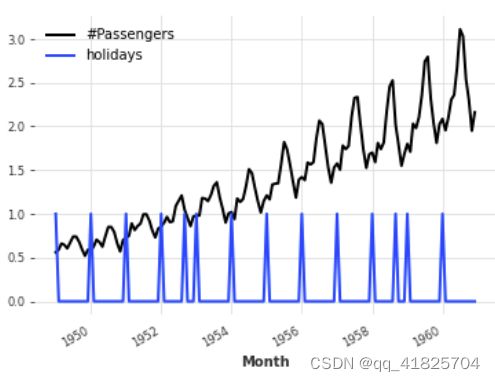
添加一些二进制节日组件:
(series / 200).add_holidays("US").plot()
differencing(差分?)
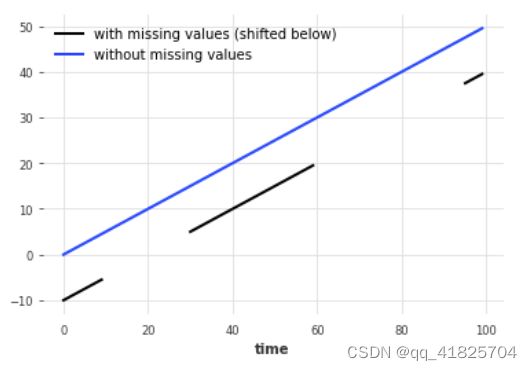
填充缺失的值(使用’ ’ utils ’ '函数)
缺失值用np.nan表示
from darts.utils.missing_values import fill_missing_values
values = np.arange(50, step=0.5)
values[10:30] = np.nan
values[60:95] = np.nan
series_ = TimeSeries.from_values(values)
(series_ - 10).plot(label="with missing values (shifted below)")
fill_missing_values(series_).plot(label="without missing values")
构建训练序列和验证序列
接下来,我们将把TimeSeries分成训练集和验证集。注意:通常,将测试集放在一边,直到过程结束时才接触它,这也是一个很好的实践。在这里,为了简单起见,我们只构建了一个训练集和验证集。
训练集将是一个TimeSeries,其中包含1958年1月之前的值(除外),验证集是一个TimeSeries,其中包含其他值
train, val = series.split_before(pd.Timestamp("19580101"))
train.plot(label="training")
val.plot(label="validation")

训练预测模型并进行预测
playing with toy models
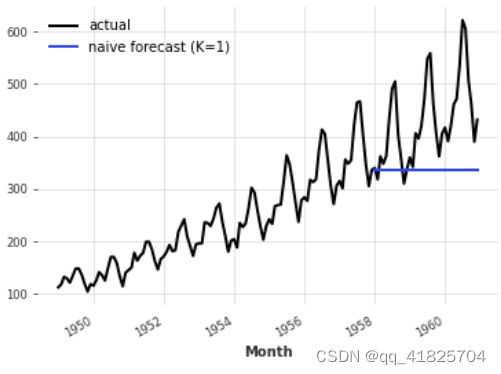
在dart中有一组“naive”的基线模型,这对于获得人们所期望的最低精度非常有用。例如,NaiveSeasonal(K)模型总是“重复”发生在K个时间步之前的值。
在最简单的情况下,当K=1时,这个模型只是简单地重复训练序列的最后一个值。
from darts.models import NaiveSeasonal
naive_model = NaiveSeasonal(K=1)
naive_model.fit(train)
naive_forecast = naive_model.predict(36)
series.plot(label="actual")
naive_forecast.plot(label="naive forecast (K=1)")
在TimeSeries上拟合模型和产生预测非常容易。所有模型都有一个fit()和一个predict()函数。这类似于Scikit-learn,只不过它是特定于时间序列的。fit()函数的参数是拟合模型的训练时间序列,predict()函数的参数是要预测的时间步数(在训练序列结束后)
检查季节性
我们上面的模型可能有点太naive了。我们已经可以通过利用数据中的季节性来改进。很明显,数据具有年度季节性,我们可以通过观察自相关函数(ACF)和突出滞后m=12来确认这一点。
from darts.utils.statistics import plot_acf, check_seasonality
plot_acf(train, m=12, alpha=0.05)
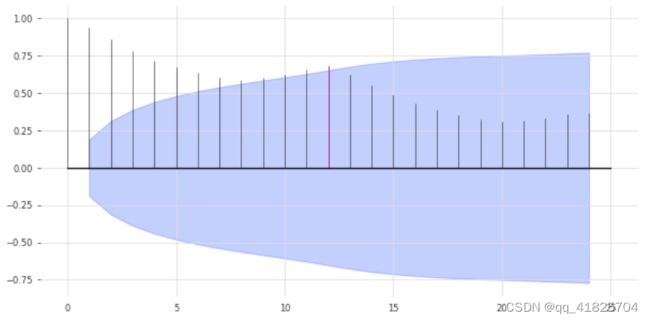
ACF在x = 12处呈现一个峰值,这表明了年度季节性趋势(用红色突出显示)。蓝色区域决定了置信水平的统计数据的显著性。我们还可以对每个候选时期m进行季节性的统计检查。
for m in range(2, 25):
is_seasonal, period = check_seasonality(train, m=m, alpha=0.05)
if is_seasonal:
print("There is seasonality of order {}.".format(period))
There is seasonality of order 12.
一个稍微naive的模型
让我们再次尝试NaiveSeasonal模型,将季节性设置为12
seasonal_model = NaiveSeasonal(K=12)
seasonal_model.fit(train)
seasonal_forecast = seasonal_model.predict(36)
series.plot(label="actual")
seasonal_forecast.plot(label="naive forecast (K=12)")
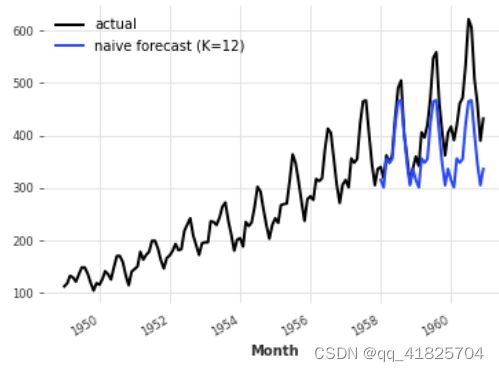
这是更好的,但我们仍然忽略了趋势。幸运的是,还有另一个naive基线模型捕捉了这一趋势,它被称为NaiveDrift。这个模型只是产生线性预测,其斜率由训练集的第一个和最后一个值决定。
from darts.models import NaiveDrift
drift_model = NaiveDrift()
drift_model.fit(train)
drift_forecast = drift_model.predict(36)
combined_forecast = drift_forecast + seasonal_forecast - train.last_value()
series.plot()
combined_forecast.plot(label="combined")
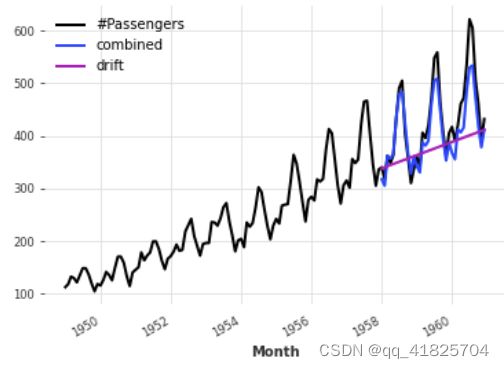
我们只是简单地拟合一个朴素的漂移模型,并将其预测添加到我们之前的季节预测中。我们还从结果中减去训练集的最后一个值,这样得到的组合预测从正确的偏移量开始。
计算误差指标
这看起来已经是一个相当不错的预测,而且我们还没有使用任何非幼稚模型。事实上,任何模型都应该能够克服这个问题。
那么我们需要克服什么误差呢?我们将使用平均绝对百分比误差(MAPE)(注意,在实践中,不使用MAPE通常有很好的理由—我们在这里使用它,因为它非常方便并且与规模无关)。在dart中,它是一个简单的函数调用:
from darts.metrics import mape
print(
"Mean absolute percentage error for the combined naive drift + seasonal: {:.2f}%.".format(
mape(series, combined_forecast)
)
)
Mean absolute percentage error for the combined naive drift + seasonal: 5.66%.
darts.metrics指标包含更多用于比较时间序列的指标。当两个级数没有对齐时,该度量将只比较级数的普通片段,并对大量的级数对进行并行计算—但我们不要过于超前。
快速尝试几个模型
dart的建立是为了便于以统一的方式训练和验证几个模型。让我们再训练一些代码,并在验证集中计算它们各自的MAPE。
from darts.models import ExponentialSmoothing, TBATS, AutoARIMA, Theta
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
eval_model(ExponentialSmoothing())
eval_model(TBATS())
eval_model(AutoARIMA())
eval_model(Theta())
model ExponentialSmoothing(trend=ModelMode.ADDITIVE, damped=False, seasonal=SeasonalityMode.ADDITIVE, seasonal_periods=12 obtains MAPE: 5.11%
model (T)BATS obtains MAPE: 5.87%
model Auto-ARIMA obtains MAPE: 11.65%
model Theta(2) obtains MAPE: 8.15%
在这里,我们只使用默认参数构建了这些模型。如果我们对问题进行微调,可能会做得更好。我们试试θ法。
用Theta方法搜索超参数
模型Theta包含Assimakopoulos和Nikolopoulos的Theta方法的实现。这种方法已经取得了一些成功,特别是在m3比赛中。
虽然在应用程序中Theta参数的值经常被设置为0,但我们的实现支持变量值,以进行参数调优。让我们试着为Theta找到一个好的值:
# Search for the best theta parameter, by trying 50 different values
thetas = 2 - np.linspace(-10, 10, 50)
best_mape = float("inf")
best_theta = 0
for theta in thetas:
model = Theta(theta)
model.fit(train)
pred_theta = model.predict(len(val))
res = mape(val, pred_theta)
if res < best_mape:
best_mape = res
best_theta = theta
best_theta_model = Theta(best_theta)
best_theta_model.fit(train)
pred_best_theta = best_theta_model.predict(len(val))
print(
"The MAPE is: {:.2f}, with theta = {}.".format(
mape(val, pred_best_theta), best_theta
)
)
The MAPE is: 4.40, with theta = -3.5102040816326543.
train.plot(label="train")
val.plot(label="true")
pred_best_theta.plot(label="prediction")
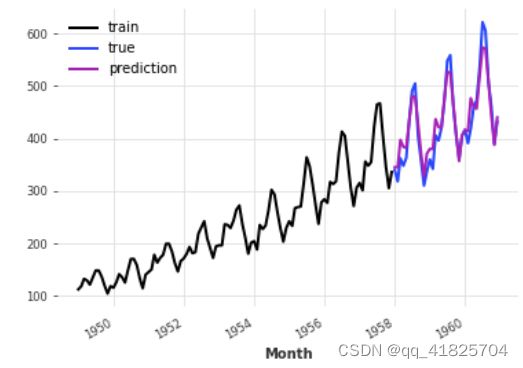
我们可以观察到,就MAPE而言,带best_theta的模型是目前为止最好的
回测:模拟历史预测
所以在这一点上,我们有了一个在验证集上表现良好的模型,这很好。但是,如果我们在历史上一直使用这个模型,我们如何知道我们会获得的性能呢?
回溯测试模拟的是在给定模型的历史上获得的预测。它可能需要一段时间来生成,因为(默认情况下)每当模拟预测时间向前推进时,都会对模型进行重新训练。
这种模拟预报总是根据forecast horizon来定义的,它是将预测时间与预报时间分开的时间步数。在下面的例子中,我们模拟了未来3个月的预测(与预测时间相比)。调用historical_forecasts()的结果(默认)是一个包含未来3个月预测的TimeSeries:
historical_fcast_theta = best_theta_model.historical_forecasts(
series, start=0.6, forecast_horizon=3, verbose=True
)
series.plot(label="data")
historical_fcast_theta.plot(label="backtest 3-months ahead forecast (Theta)")
print("MAPE = {:.2f}%".format(mape(historical_fcast_theta, series)))
MAPE = 7.70%
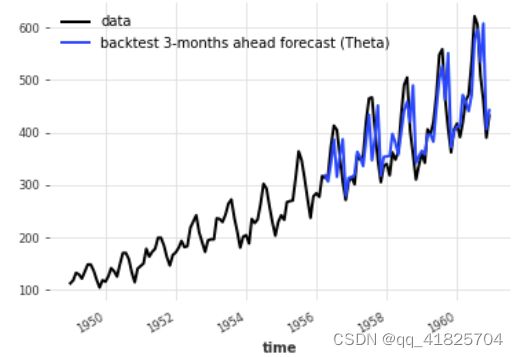
因此,当我们进行回测时,我们在验证集上最好的模型似乎不再那么好了(我听到过拟合了吗:D)
为了更仔细地查看错误,我们还可以使用backtest()方法来获得所有原始错误(例如,MAPE错误),这些错误将由我们的模型获得:
best_theta_model = Theta(best_theta)
raw_errors = best_theta_model.backtest(
series, start=0.6, forecast_horizon=3, metric=mape, reduction=None, verbose=True
)
from darts.utils.statistics import plot_hist
plot_hist(
raw_errors,
bins=np.arange(0, max(raw_errors), 1),
title="Individual backtest error scores (histogram)",
)

最后,使用backtest()我们还可以得到历史预测平均误差的一个更简单的视图:
average_error = best_theta_model.backtest(
series,
start=0.6,
forecast_horizon=3,
metric=mape,
reduction=np.mean, # this is actually the default
verbose=True,
)
print("Average error (MAPE) over all historical forecasts: %.2f" % average_error)
Average error (MAPE) over all historical forecasts: 6.36
例如,我们也可以指定参数reduction=np.mean。来得到中值MAPE。
我们来看看我们现在的Theta模型的拟合残差,即模型在之前所有点上拟合得到的每个时间点上的1步预测与实际观测值的差值。
from darts.utils.statistics import plot_residuals_analysis
plot_residuals_analysis(best_theta_model.residuals(series))
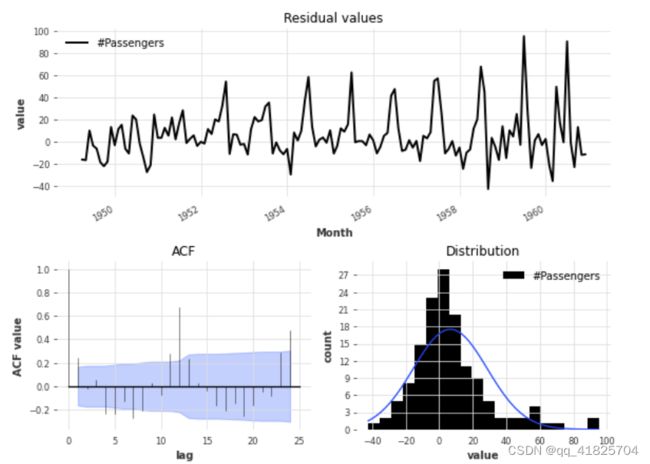
我们可以看到分布不是以0为中心,这意味着我们的Theta模型是有偏差的。我们还可以得出一个较大的滞后ACF值为12,这表明残差中包含了模型没有用到的信息。
我们能用简单的指数平滑模型做得更好吗?
model_es = ExponentialSmoothing()
historical_fcast_es = model_es.historical_forecasts(
series, start=0.6, forecast_horizon=3, verbose=True
)
series.plot(label="data")
historical_fcast_es.plot(label="backtest 3-months ahead forecast (Exp. Smoothing)")
print("MAPE = {:.2f}%".format(mape(historical_fcast_es, series)))
MAPE = 4.45%
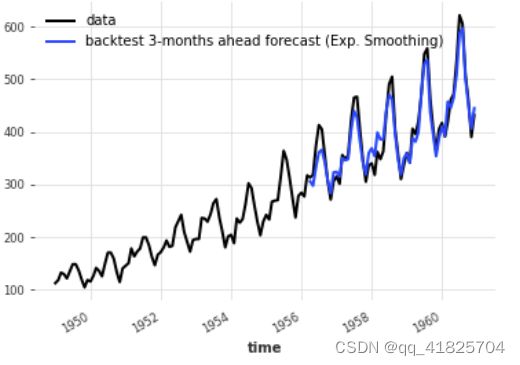
这个更好!在这种情况下,当使用3个月的预测水平进行回溯测试时,我们得到了大约4-5%的平均绝对百分比误差。
plot_residuals_analysis(model_es.residuals(series))
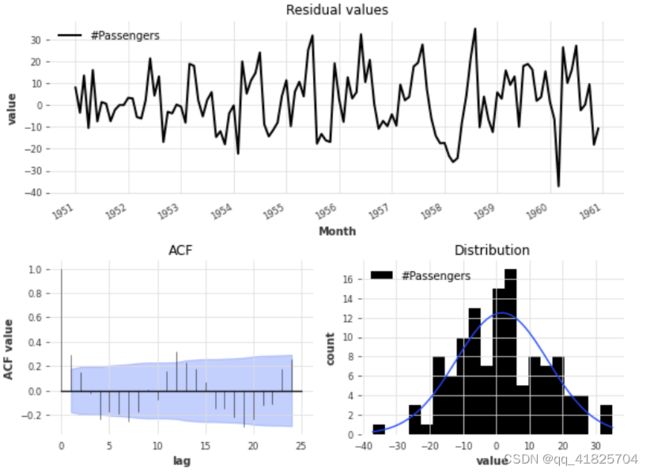
残差分析还反映了性能的改进,因为我们现在有一个残差分布集中在值0,而ACF值虽然不是无关紧要,但具有较低的幅度。
机器学习和全局模型
dart为机器学习和深度学习预测模型提供了丰富的支持;例如:
regression model可以围绕任何sklearn兼容的回归模型来产生预测(它在下面有自己的部分)。RNNModel是一个灵活的RNN实现,可以像DeepAR一样使用。NBEATSModel实现了N-BEATS模型。- TFTModel实现了Temporal Fusion Transformer model.
- TCNModel实现了时间卷积网络
除了支持与其他模型相同的基本fit()/predict()接口外,这些模型也是全局模型,因为它们支持对多个时间序列进行训练(有时称为元学习)。
这是使用基于ML的模型进行预测的关键点:通常,ML模型(尤其是深度学习模型)需要在大量数据上进行训练,这通常意味着大量独立但相关的时间序列。
在dart中,指定多个TimeSeries的基本方法是使用一个TimeSeries序列(例如,一个简单的TimeSeries列表)。
两个序列的例子
这些模型可以在数千个序列上训练。在这里,为了说明问题,我们将加载两个不同的序列——航空交通乘客数和另一个系列,包含每头奶牛每月生产的牛奶的磅数。我们也将我们的级数转换为np.Float32会稍微加快训练速度:
from darts.datasets import AirPassengersDataset, MonthlyMilkDataset
series_air = AirPassengersDataset().load().astype(np.float32)
series_milk = MonthlyMilkDataset().load().astype(np.float32)
# set aside last 36 months of each series as validation set:
train_air, val_air = series_air[:-36], series_air[-36:]
train_milk, val_milk = series_milk[:-36], series_milk[-36:]
train_air.plot()
val_air.plot()
train_milk.plot()
val_milk.plot()
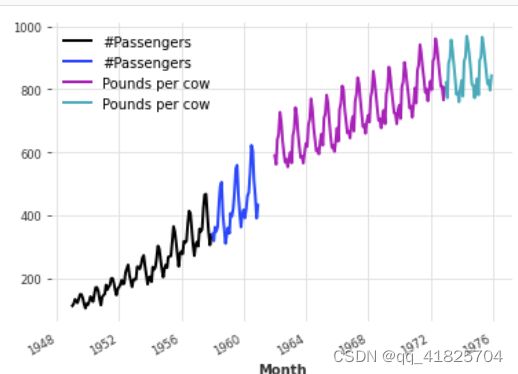
首先,让我们在0到1之间缩放这两个序列,因为这将使大多数ML模型受益。我们将使用一个标量:
from darts.dataprocessing.transformers import Scaler
scaler = Scaler()
train_air_scaled, train_milk_scaled = scaler.fit_transform([train_air, train_milk])
train_air_scaled.plot()
train_milk_scaled.plot()

请注意我们如何一次扩展多个系列。我们还可以通过指定n_jobs来在多个处理器上并行处理这类操作。
使用深度学习:N-BEATS的例子
接下来,我们将建立一个N-BEATS模型。这个模型可以通过许多超参数(如栈数、层数等)进行调优。这里,为了简单起见,我们将使用默认超参数。我们只需要提供两个超参数:
nput_chunk_length:这是模型的“回望窗口”——即,神经网络在前向传递中以多少时间步作为输入来产生输出。Output_chunk_length:这是模型的“前向窗口”,即神经网络在前向传递中输出未来值的时间步数。
random_state参数用于获得可重现的结果。
darts中的大多数神经网络都需要这两个参数。在这里,我们将使用季节性的倍数。现在,我们准备对两个系列的模型进行拟合(通过给出包含两个系列的列表to fit()):
from darts.models import NBEATSModel
model = NBEATSModel(input_chunk_length=24, output_chunk_length=12, random_state=42)
model.fit([train_air_scaled, train_milk_scaled], epochs=50, verbose=True);
[2022-06-21 16:04:42,259] INFO | darts.models.forecasting.torch_forecasting_model | Train dataset contains 194 samples.
[2022-06-21 16:04:42,259] INFO | darts.models.forecasting.torch_forecasting_model | Train dataset contains 194 samples.
2022-06-21 16:04:42 darts.models.forecasting.torch_forecasting_model INFO: Train dataset contains 194 samples.
[2022-06-21 16:04:42,341] INFO | darts.models.forecasting.torch_forecasting_model | Time series values are 32-bits; casting model to float32.
[2022-06-21 16:04:42,341] INFO | darts.models.forecasting.torch_forecasting_model | Time series values are 32-bits; casting model to float32.
2022-06-21 16:04:42 darts.models.forecasting.torch_forecasting_model INFO: Time series values are 32-bits; casting model to float32.
2022-06-21 16:04:42 pytorch_lightning.utilities.rank_zero INFO: GPU available: False, used: False
2022-06-21 16:04:42 pytorch_lightning.utilities.rank_zero INFO: TPU available: False, using: 0 TPU cores
2022-06-21 16:04:42 pytorch_lightning.utilities.rank_zero INFO: IPU available: False, using: 0 IPUs
2022-06-21 16:04:42 pytorch_lightning.utilities.rank_zero INFO: HPU available: False, using: 0 HPUs
2022-06-21 16:04:42 pytorch_lightning.callbacks.model_summary INFO:
| Name | Type | Params
---------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | stacks | ModuleList | 6.2 M
---------------------------------------------------
6.2 M Trainable params
1.4 K Non-trainable params
6.2 M Total params
24.787 Total estimated model params size (MB)
现在让我们对未来36个月的两个序列做一些预测。我们可以使用fit()函数的serise参数来告诉模型预测哪个级数。重要的是,output_chunk_length并没有直接限制可与predict()一起使用的预测水平n。在这里,我们用Output_chunk_length =12,并对未来n=36个月进行预测;这只是在幕后以一种自动回归的方式完成的(网络递归地消耗它以前的输出)。
pred_air = model.predict(series=train_air_scaled, n=36)
pred_milk = model.predict(series=train_milk_scaled, n=36)
# scale back:
pred_air, pred_milk = scaler.inverse_transform([pred_air, pred_milk])
plt.figure(figsize=(10, 6))
series_air.plot(label="actual (air)")
series_milk.plot(label="actual (milk)")
pred_air.plot(label="forecast (air)")
pred_milk.plot(label="forecast (milk)")
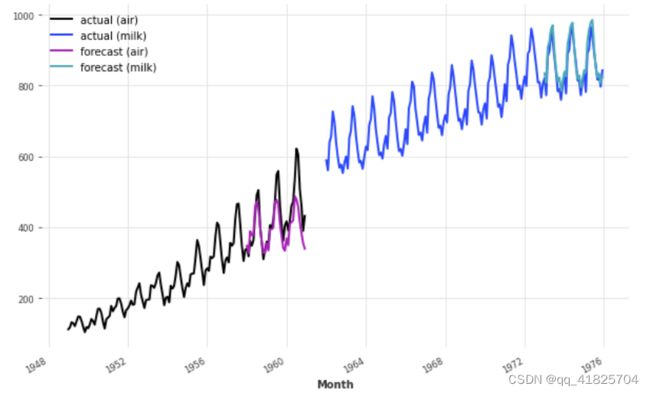
考虑到我们使用一个带有默认超参数的模型来捕捉航空乘客和牛奶产量,我们的预测实际上并不那么可怕!
这个模型似乎很好地捕捉了每年的季节,但错过了air series的趋势信息。在下一节中,我们将尝试使用外部数据(协变量)来解决这个问题。