mmsegment模型训练和推理(四)
目录
1、常用设定
2、模型训练
2.1、单GPU训练
2.2、使用多个GPU进行训练
3、模型推理
1、常用设定
1)默认使用4个GPU的分布式训练。
2)ImageNet上所有pytorch样式的预训练主干都是由open-lab团队自己训练的,参考文章https://arxiv.org/pdf/1812.01187.pdf。其中ResNet样式主干基于ResNetV1c变体,其中输入主干中的7x7转换被三个3x3转换取代。

3)为了确保不同硬件之间的一致性,将GPU内存报告torch.cuda.max_memory_allocated()为所有4个GPU的最大值torch.backends.cudnn.benchmark=False。请注意,该值通常小于nvidia-smi显示的值。
4)将推理时间报告为网络转发和后处理的总时间,不包括数据加载时间。使用脚本获得结果,该脚本使用tools/benchmark.py来计算200张图像的平均时间torch.backends.cudnn.benchmark=False。
5)此框架中有两种推理模式。
slide模式:test_cfg类似:
dict(mode='slide', crop_size=(769, 769), stride=(513, 513))在这种模式下,将从输入图像中裁剪多个patches,然后分别传递到网络中。patches之间的size和stride由crop_size和指定stride。重叠区域将平均合并。
whole模式:test_cfg类似:
dict(mode='whole')在这种模式下,整个图像将直接传递到网络中。
默认情况下,我们slide对769x769训练后的模型使用推断,whole其余部分使用推断。
6)对于8x + 1的输入大小(例如769),align_corner=True采用传统做法。否则,对于8x的输入大小(例如512、1024),将align_corner=False被采用。
2、模型训练
MMSegmentation实现使用MMDistributedDataParallel和MMDataParallel实现分布式训练和非分布式训练。
所有输出(日志文件和检查点)将保存到工作目录,该目录在config文件中的work_dir指定。
默认情况下,会在一些迭代后在验证集上评估模型,你可以通过在训练配置中添加interval参数来更改评估间隔。
evaluation = dict(interval=4000) # This evaluate the model per 4000 iterations.重要:配置文件中的默认学习率是4个GPU和2 img / gpu(批量大小= 4x2 = 8)。同样,还可以使用8个GPU和1个imgs / gpu,因为所有型号均使用跨GPU SyncBN。
为了与GPU内存交换速度,您可以传入--options model.backbone.with_cp=True以在主干中启用检查点。
2.1、单GPU训练
python tools/train.py ${CONFIG_FILE} [optional arguments]若要在命令中指定工作目录,则可以添加参数。--work-dir ${YOUR_WORK_DIR}。
因为我们一般都会使用自己的数据集,公开数据集只作为测试验证。这里以voc2012数据集+单机单开训练为例。
数据集百度云下载地址:
链接:https://pan.baidu.com/s/12Fk0yi05MYqTiiGJC-aCsA
提取码:atvb实例测试,选择configs/fcn下的fcn_r50-d8_512x512_20k_voc12aug.py作为配置文件,进行以下修改:
step1:修改配置文件。拷贝fcn_r50-d8_512x512_20k_voc12aug.py改名为fcn_r50-d8_512x512_20k_voc12.py。修改'../_base_/datasets/pascal_voc12_aug.py'为'../_base_/datasets/pascal_voc12.py',使用标准的voc2012数据集。
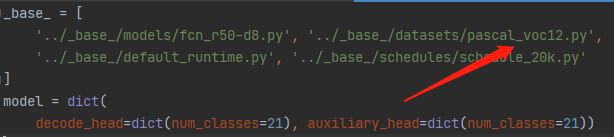
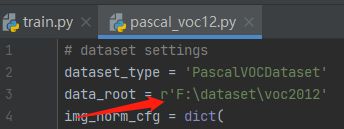
step2:修改数据集路径。
打开configs/_base_/datasets/pascal_voc12.py,将data_root路径设置为voc2012数据集的绝对路径,以方便调试。
step3:修改模型文件。单卡不使用分布式训练,修改SyncBN为BN,打开configs/_base_/models/fcn_r50-d8.py,将norm_cfg中type由SyncBN改为BN。这里顺便把model中pretrained参数改为None,不下载默认的预训练模型。
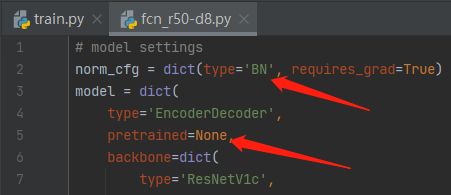
未修改BN,会报错误:
AssertionError: Default process group is not initialized
step4:训练
python tools/train.py configs/fcn/fcn_r50-d8_512x512_20k_voc12.py --work-dir="work_dir"出现如下打印信息,开始训练:
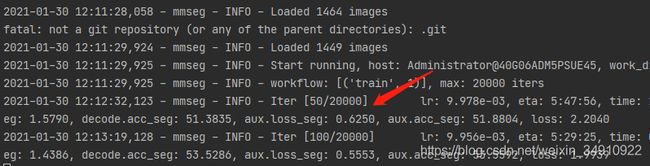
迭代后,会在工作目录保存模型、log及配置文件。更多参数参考2.2使用多GPU训练。
2.2、使用多个GPU进行训练
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]可选参数为:
--no-validate(不建议):默认情况下,代码库将在训练过程中每k次迭代执行评估。若要禁用此行为,请使用--no-validate。
--work-dir ${WORK_DIR}:覆盖配置文件中指定的工作目录。
--resume-from ${CHECKPOINT_FILE}:从先前的检查点文件继续(继续训练过程)。
--load-from ${CHECKPOINT_FILE}:从检查点文件中加载权重(以开始微调其他任务)。
resume-from和之间的区别load-from:
resume-from 加载模型权重和优化器状态,包括迭代次数。
load-from 仅加载模型权重,从迭代0开始训练。
3、模型推理
单GPU测试:
1)测试集图像,逐帧显示
python tools/test.py configs/fcn/fcn_r50-d8_512x512_20k_voc12.py work_dir/latest.pth --show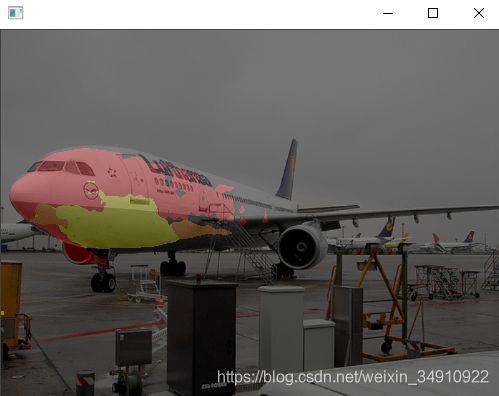
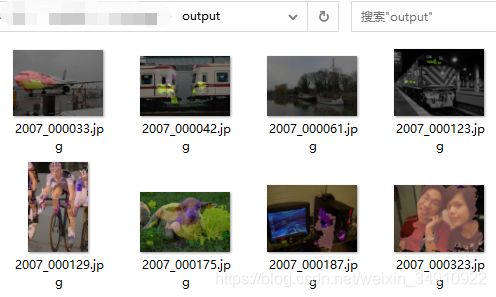
2)测试集图像,输出可视化结果至目录文件夹
python tools/test.py configs/fcn/fcn_r50-d8_512x512_20k_voc12.py work_dir/latest.pth --show-dir="output"输出结果如下:
3)评估map
python tools/test.py configs/fcn/fcn_r50-d8_512x512_20k_voc12.py work_dir/latest.pth --eval mAP4)测试结果保存至.pkl文件
python tools/test.py configs/fcn/fcn_r50-d8_512x512_20k_voc12.py work_dir/latest.pth --out results.pkl