Learning from Very Few Samples:小样本学习综述(四)
FSL问题介绍
FSL两大模型(一)
FSL两大模型(二)
FSL
- 扩展主题
-
- Semi-supervised Few Sample Learning
- Unsupervised Few Sample Learning
- Cross-domain Few Sample Learning
- Generalized Few Sample Learning
- Multimodal Few Sample Learning
- 应用
-
- Computer Vision
- Natural Language Processing.
- Audio and Speech
- Reinforcement Learning and Robotic
- Data Analysis
- Cross-Field Applications.
- Other Applications
- Open Competitons
- 未来方向
-
- Robustness
- Universality
- Interpretability
- Theoretical System
- 总结
扩展主题
本节阐述了FSL的几个新兴扩展主题,包括半监督FSL(S-FSL),无监督FSL(U-FSL),跨域FSL(C-FSL),广义FSL(G-FSL)和多模态FSL(M-FSL)。
Semi-supervised Few Sample Learning
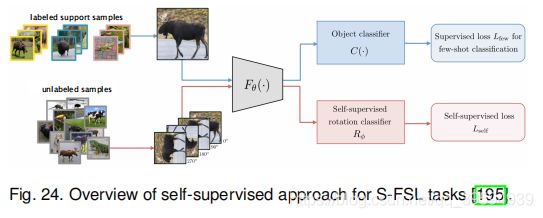
S-FSL假设,N-way K-shot任务的训练集Dtrn不仅包含NK标记的支持样本,而且包含一些属于或不属于C任务类的未标记样本。 研究人员可以使用半监督训练集来构建他们的FSL系统。利用自监督学习方式从未标记样本中摄取信息。特别地,如图24所示,在未标记的图像上构造了自我监督任务(即旋转预测和相对贴片位置),并将这种自我监督损失添加到主要的FSL任务损失中。
Unsupervised Few Sample Learning
与vanilla FSL相比,U-FSL鼓励更一般的设置,其中辅助集FSL是完全无监督的。目标是追求一个相对温和的条件来执行FSL,并且削弱构建FSL学习者的先决条件,因为收集属于非任务类的未标记辅助集比收集标记数据集更容易实现。基础学习者的顶层被预先训练为使用未标记样本的LDS,并鼓励它们为下游FSL任务捕获更通用的表示空间。CACTUs采用两个阶段策略:通过无监督表示学习方法(例如ACAI和BiGAN)在未标记集合上合成元训练任务,然后在这些合成任务上运行经典的MAML或Prototypical Nets。与此相比,UMTRA和AAL都通过增强未标记样本和处理原型来合成元训练任务,在此基础上进行增强,并将相应的增强数据作为同系物样本,然后是现成的MAML算法。 CACTUs、UMTRA和AAL之间的共性是,它们本质上专注于如何将伪标签分配给未标记的样本,以便现有的vanilla FSL模型可以在不进行修改的情况下工作。
Cross-domain Few Sample Learning
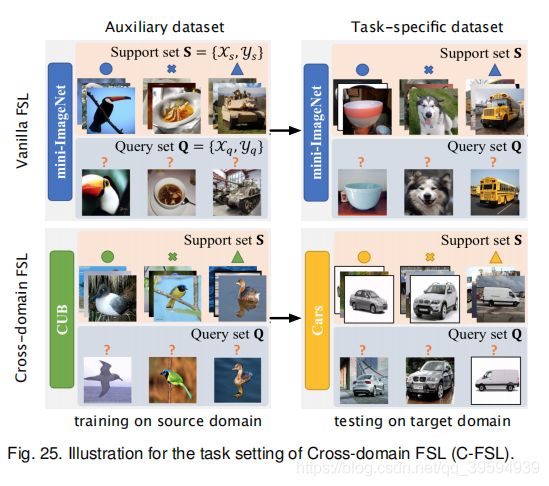
在 vanilla FSL 设置下,假设辅助数据集 D A D_{A} DA和T-特异性 数据集 D T D_T DT的样本都来自相同的数据域,如图25顶部部分所示。然而,当要处理的FSL任务来自一个没有相关辅助样本的新域时,就必须利用一些跨域样本作为辅助数据,如图25底部部分所示。辅助数据集和特定任务数据集之间域移对FSL方法提出了更高的挑战。
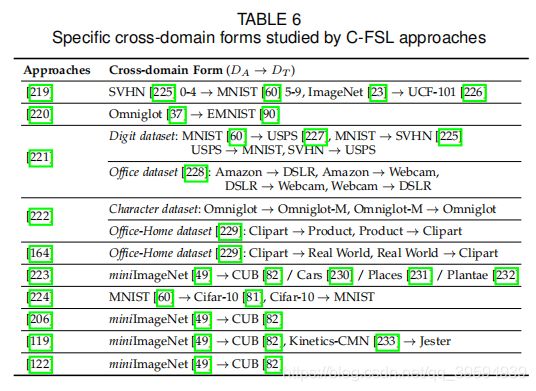
C-FSL与领域适应(DA)高度相关,这是机器学习领域的一个经典方向。虽然在利用少数样本寻址DS存在单独的工作,但其任务设置与C-FAL不同:DA中的标签空间在源域和目标域之间共享,而在C-FSL中,辅助数据集和任务特定数据集之间是不相交的。最近,人们提出了几种从各种角度来解决C-FSL问题的方法,例如对抗性训练,特征转换,域对齐,特定域微调,特征组成和集合方法等。为了便于后续的C-FSL相关研究,我们在表6中总结了它们使用的特定跨域形式。
Generalized Few Sample Learning
Vanilla FSL设置容易导致灾难性遗忘问题,即大多数FSL模型被训练为对一个新任务的预定义类进行推理,但不能连续地应用于辅助集中的前几个类。 然而,在许多应用程序中,类概念和样本以动态的方式到达,学习系统往往面临类间训练数据的极端不平衡,这意味着一些类得到了足够的训练样本,而有些类只有少数。在这种情况下,对于具有有限数据的新任务类具有增量学习能力是至关重要的,同时也不会忘记以前的非任务类。 因此,G-FSL的重点是使FSL模型能够联合处理DA和DT中的所有类。
Multimodal Few Sample Learning
与只包含任务模式的vanilla FSL 不同,M-FSL涉及来自附加模式的信息或数据。根据附加模态的作用,M-FSL设置可卡因进一步细分为两种情况,如图26所示。
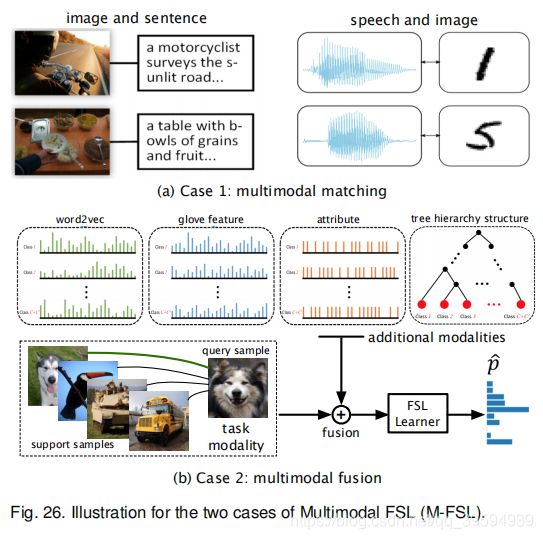
多模态匹配。Vanilla FSL寻求从任务模式到硬类标签空间的映射,而M-FSL的多模态匹配旨在学习从一种模式到另一种模式的映射。例如,给定几个图像-句子训练对,FSL学习者需要正确地确定描述查询图像、或给定一小批语音图像训练对的句子,FSL学习者需要找到一个正确的视觉图像,其中包含查询语音中所说的单词。 这些基于FSL的多模态匹配设置是有意义的,特别是对于机器人应用。
多模态融合。它允许FSL学习者使用额外的模式信息来帮助任务模式中的学习。
应用
由于机器学习系统对大规模训练样本的普遍需求和近年来FSL研究的蓬勃发展,FSL的方法和思想正在广泛应用于计算机视觉、自然语言处理、音频和语音、强化学习和机器人以及数据分析等各个研究领域。 表9概述了FSL应用程序的字段和子字段及其代表性出版物。
Computer Vision
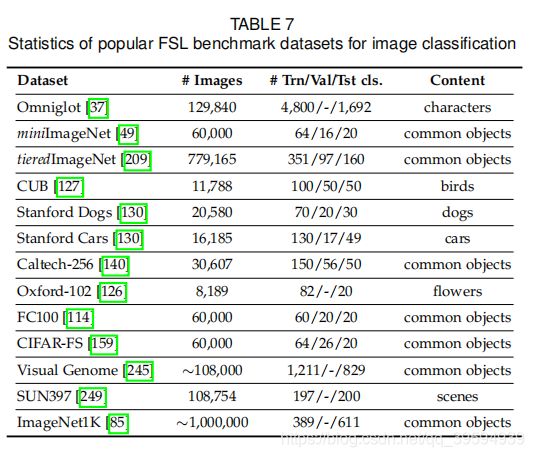
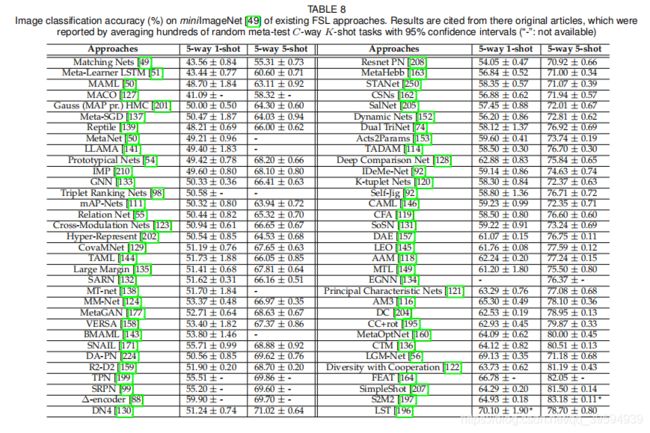
由于视觉数据的直观性和可懂度,计算机视觉一直是机器学习算法的主要测试平台,FSL也不例外。 从最早的Congealing模型[29]到今天的元学习方法,视觉任务一直是FSL方法的试金石,特别是少数基于样本(或少镜头)的图像分类任务。由于灰度字符图像的简单性和足够的元训练类,许多FSL方法已经在Omniglot上取得了良好的性能。因此,研究人员倾向于利用迷你图像网来评估FSL方法的性能。为了更好地参考后续研究,我们在表8中总结了在迷你图像网上报告其结果的所有FSL方法的性能。我们可以观察到,从2016年到2019年,仅在三年内,5路五分之一镜头精度提高了20%以上,这表明FSL研究得到了迅速的发展。
Natural Language Processing.
是FSL应用的第二大领域。 自然语言处理中一个常见的FSL应用是文本分类,它试图利用几个文档或单词来推断文档标签。 此外,FSL机制也被纳入自然语言处理的基础研究课题,如单词表示学习、关系学习和知识图。
Audio and Speech
声学数据是一种更复杂的数据形式,通常对其进行大规模的收集和注释比图像或文本更困难,这导致了对FSL方法的更迫切的需要。 目前,FSL已被用于解决从基本音频分类和关键字识别到具有挑战性的文本到语音和语音生成的许多声学任务。
Reinforcement Learning and Robotic
一个理想的机器人系统应该具有学习新任务的能力,有几个演示,没有较长的任务特定训练时间的任务,然而,新的情况可能使机器人容易陷入有限的观察样本的困境,这使得FSL成为未来先进机器人系统不可或缺的技能。 随着FSL方法的普及,许多研究人员重新考虑了FSL机制下强化学习和机器人[405]的应用,包括模仿学习[406]、视觉导航[407]和策略学习[408]等。
Data Analysis
众所周知,通过稀疏训练数据有效地分析数据和挖掘数据中的底层规则是数据科学研究人员不懈追求的目标。幸运的是,FSL正逐渐应用于一些经典的数据分析应用,如数据回归和异常检测。
Cross-Field Applications.
最近,FSL被集成到两个流行的跨场应用中,即图像字幕[383]和视觉问答。 在仅有少数图像文本训练对的情况下,前者试图为图像生成适当的文本描述,而后者则试图为关于图像的文本问题输出准确的自然语言答案。
Other Applications
除了上述几个常见的机器学习应用领域外,FSL还被引入到其他专业领域,如医学、化学计量学、农业、传感器和互联网安全等。
Open Competitons
随着对FSL的日益关注,一些相关的竞赛正在出现。第一次FSL竞赛是在ICCV2019研讨会上发表的Few-Shot verb Image Classification ,重点研究了大规模动词图像分类,提出了一种高质量少镜头动词图像数据集。最近,在CVPR2020的有限标签视觉学习研讨会上,提出了一个更具挑战性的竞争,即Cross-Domain Few-Shot Learning Challenge ,这项竞赛要求参与者在图像网上训练FSL模型,但对来自不同领域的其他四个数据集进行评估,如植物疾病图像、卫星图像、皮损皮肤镜图像和X射线图像。 这个比赛包括两个主要的轨道,使用或不使用未标记的图像从目标域进行训练。
未来方向
虽然近年来FSL在方法和应用上都取得了相当大的进展,但由于稀疏样本的内在困难,仍然存在挑战。 在本节中,我们建议FSL的四个未来方向。
Robustness
前大多数FSL研究都是基于理想的数据假设,但对于所有实际场景都很难成立。 在许多实际应用中,人们可能会面临不确定的干扰,破坏FSL的理想设置。 例如,少数训练数据可能由于仪器故障或噪声样本或标签错误数据而受到离群干扰或浅薄错误。它提出了一个问题,即现有的FSL模型是否能有效地减轻这些异常值的影响,并仍然保持一个可接受的泛化。提高FSL模型对各种潜在扰动因素的鲁棒性具有重要意义。
Universality
这里提到的普遍性是双重的。 首先是FSL方法的模型级通用性和可扩展性。 目前,大多数FSL方法都过于针对特定的基准任务和数据集设计,削弱了它们对其他更一般任务的适用性。 一个理想的FSL框架应该能够处理不同数据复杂度和不同数据形式的各种学习任务。 其次是FSL方法的应用级通用性和灵活性。 目前大多数FSL研究都集中在具有小规模任务类和大规模标记辅助数据的普通应用场景上。 然而,现实世界的问题可能会带来更复杂的应用场景,如大型任务类、数据分发的长尾现象、任务类的动态性、标记辅助数据的不可用性,甚至这些场景的混合。 它们对FSL方法的普遍性提出了更高的要求和挑战。
Interpretability
近年来FSL的激增和成功主要在于深度学习技术,这往往被批评为缺乏可解释性。 模型可解释性是深度学习的关键问题。 我们认为,人类令人印象深刻的少数样本学习能力受益于许多方面,包括合理使用经验知识和巧妙地探索任务数据背后的基本知识。 因此,如何利用外部先验知识和内部数据知识的融合来提高FSL模型的可解释性,可能是未来的研究方向。
Theoretical System
稀疏训练样本造成的根本困难是由于训练样本形成的有效函数正则化缺乏,学习函数f的搜索空间非常巨大。 如果我们从这个理论的角度重新审视当前的FSL方法,可以发现,从本质上讲,所有的FSL解决方案都是通过特定的技术来实现函数正则化。 例如,基于增强的FSL方法通过直接增加训练样本来达到这一目标,而元学习方法则建议引入其他无关的学习任务来规范跨任务的学习功能。 因此,从稀疏训练样本下学习函数空间正则化的角度构建FSL的系统理论体系可以给FSL研究人员带来新的启示。
总结
使学习系统能够从极少数样本中学习对于机器学习和人工智能的进一步发展至关重要。 本文对少数样本学习(FSL)进行了全面的调查)。 特别回顾了FSL的演变历史和目前的进展,所有FSL方法都是通过简洁易懂的分类法分组的。 深入分析了基于元学习的主流FSL方法之间的潜在发展关系。 此外,还系统地总结了FSL的几个新兴的扩展研究主题、现有的FSL在各个领域的应用、当前的基准数据集和性能,以及几个潜在的研究方向。 本次调查有望促进FSL相关知识的掌握和FSL研究领域的协同发展。