Kaggle系列(1)——Titanic
文章目录
-
- @[toc]
- 0x01、项目介绍
- 0x02、项目过程简述
- 0x03、数据探索与分析
-
- 3.1 数据的大致了解
- 3.2 查看各项数据的分布
-
- 3.2.1 数值统计
- 3.2.2 绘图观察
- 3.3 分析过程
- 3.4 缺失值与异常值观察
- 3.5 数据探索的总结
- 0x03、预处理
-
- 3.1 数据清洗
-
- 3.1.1 缺失值补全
- 3.1.2 字段转换
- 3.2 数据编码和归一化
- 3.3 取需要的字段
- 0x04、建立模型
-
- 4.1 逻辑回归模型
- 4.2 交叉验证
- 0x05、总结与展望
- 附录:从泰坦尼克号相关资料中提取出的一些可能有用的信息
- 参考资料
文章目录
-
- @[toc]
- 0x01、项目介绍
- 0x02、项目过程简述
- 0x03、数据探索与分析
-
- 3.1 数据的大致了解
- 3.2 查看各项数据的分布
-
- 3.2.1 数值统计
- 3.2.2 绘图观察
- 3.3 分析过程
- 3.4 缺失值与异常值观察
- 3.5 数据探索的总结
- 0x03、预处理
-
- 3.1 数据清洗
-
- 3.1.1 缺失值补全
- 3.1.2 字段转换
- 3.2 数据编码和归一化
- 3.3 取需要的字段
- 0x04、建立模型
-
- 4.1 逻辑回归模型
- 4.2 交叉验证
- 0x05、总结与展望
- 附录:从泰坦尼克号相关资料中提取出的一些可能有用的信息
- 参考资料
0x01、项目介绍
学习了各种机器学习算法之后,可以找一个简单项目来练练手,感受一下完整的ML过程。本文主要记录我做这个项目的整个过程和思路。Titanic是Kaggle的入门项目,网上可以找到很多资料,所以选择它作为第一个练手的项目。(记录一下哈哈哈,截止到2020年10月3日,已经有17548支队伍参赛~)
简单介绍一下Titanic这个项目。泰坦尼克号海难是历史上最著名的海难事故之一:1912年4月15日,被誉为“永不沉没”的泰坦尼克号游轮在她的首航中撞上冰山而沉没,而船上并没有足够的救生艇,导致船上包括乘客和船员在内的2224人中有1502人在此次海难中丧生。但似乎有某些因素使得有一部分人更容易获救。这个项目是使用机器学习方法建立一个模型,用来预测泰坦尼克号海难中乘客是否生还。训练集(train.csv)包括了891位乘客的一些个人信息及其生还与否的信息。测试集(test.csv)含有418位乘客的信息,但不含生还信息。以下列出了部分字段及其含义:
| 字段名称 | 含义 | 描述 |
|---|---|---|
| survival | 是否生还 | 0:否; 1:是 |
| pclass | 船票等级 | 可代表经济水平: 1为上等,2为中等,3为底层 |
| sex | 性别 | |
| Age | 年龄(单位是年) | 如果小于1,则年龄是小数。如果估计了年龄,则采用xx.5的形式 |
| sibsp | 同在船上的兄弟姐妹/配偶数量 | 表示家庭关系:Sibling-(继)兄弟姐妹;Spouse-丈夫,妻子(情妇和未婚夫被忽略) |
| parch | 同在船上的父母/子女数量 | 表示家庭关系:Parent-父母亲;Child-(继)子女。一些孩子只带一个保姆旅行,因此他们的parch=0。 |
| ticket | 船票号 | |
| fare | 船票价格 | |
| cabin | 船舱号 | |
| embarked | 登船港口 | C:Cherbourg(瑟堡,法国西北部港口城市), Q:Queenstown(皇后镇,爱尔兰), S:Southampton(南安普顿,英国南部港口城市) |
0x02、项目过程简述
-
了解项目
- 了解项目的背景,问题产生的原因等;
- 可查找一些项目相关的资料,了解有关知识等,有助于分析和特征工程;
-
数据探索与分析
- 了解训练集和测试集的字段结构,数据量,数据集的基本信息,有缺失值/异常值等;
- 通过前面了解的知识,和数据分析寻找影响最终预测的因素。这个阶段需要综合利用各种统计与分析方法,可用各种图表使数据分展现得更加直观;
- 生成挖掘思路,包括需要进行的预处理,规划使用的模型等;
-
预处理
- 根据之前对数据集的了解,进行数据清洗、字段处理等,将训练集和测试集处理成为建模需要的格式;
- 数据探索、分析与预处理的过程可能会占掉整个项目的80%以上的时间;
-
建模与优化
- 根据前面的分析选择合适的模型算法,拟合数据;
- 根据结果调整模型参数,优化特征工程,进行模型融合等。
0x03、数据探索与分析
3.1 数据的大致了解
首先读取训练集和测试集的数据,看一下含有的字段及取值范围,是否有缺失值或NaN等。
#coding=utf-8
import pandas as pd
d_train = pd.read_csv('train.csv')
d_test = pd.read_csv('test.csv')
print('---------- d_train.info() ----------')
print(d_train.info())
print('\n---------- d_train.describe() ----------')
print(d_train.describe())
print('\n---------- d_test.info() ----------')
print(d_test.info())
print('\n---------- d_test.describe() ----------')
print(d_test.describe())
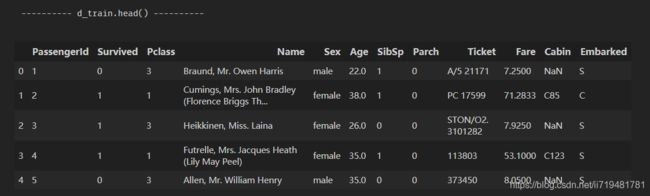
print('---------- d_train.head() ----------')
print(d_train.head())
print('---------- d_test.head() ----------')
print(d_test.head())
以下是结果:
---------- d_train.info() ----------
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
---------- d_train.describe() ----------
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
---------- d_test.info() ----------
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
None
---------- d_test.describe() ----------
PassengerId Pclass Age SibSp Parch Fare
count 418.000000 418.000000 332.000000 418.000000 418.000000 417.000000
mean 1100.500000 2.265550 30.272590 0.447368 0.392344 35.627188
std 120.810458 0.841838 14.181209 0.896760 0.981429 55.907576
min 892.000000 1.000000 0.170000 0.000000 0.000000 0.000000
25% 996.250000 1.000000 21.000000 0.000000 0.000000 7.895800
50% 1100.500000 3.000000 27.000000 0.000000 0.000000 14.454200
75% 1204.750000 3.000000 39.000000 1.000000 0.000000 31.500000
max 1309.000000 3.000000 76.000000 8.000000 9.000000 512.329200

观察数据并结合相关资料,把获得的信息梳理一下:
-
训练集train.csv共891条数据,其中Age缺了177条(占19.9%),Cabin缺了687条(占77.1%),Embarked缺了2条。
-
测试集test.csv共418条数据,其中Age缺了86条(占20.6%);Cabin缺了327条(占78.2%);Fare缺了1条。
-
训练集train.csv中,大约38.4%的乘客得救;平均年龄29.7岁,最大的80岁,最小的不到半岁;大多数乘客是一个人坐船,少数乘客与家人同乘;多数乘客是3等舱且票价很便宜,同等级的舱位票价也有不同。
-
测试集test.csv中,平均年龄30.3岁,最大的76岁,最小的也是不到半岁;同乘和舱位分布似乎与训练集差不多的样子。
-
据一些资料,船上的乘客数量是1316,而这里训练集和测试集相加后乘客数量是1309,那么几乎已经包含了所有的乘客。(所以这里没有把船员信息包含进来?)那么训练集占68%,测试集占32%。
-
训练集中比较重要的信息有是否获救、舱位等级、性别、年龄、父母子女数量、兄弟姐妹数量、登船港口这七个字段;而姓名、船票号、票价、舱位这四个字段初看并没有什么有用的信息,可能需要结合一些资料来挖掘。
-
乘客名字(Name)信息中,女性有区分Mrs.和Miss.,这似乎能代表是否已婚,不知道这与是否获救有没有关系?可以统计看看都有哪些称呼,找寻称呼中的“隐藏信息”。
-
查找了一些泰坦尼克号的资料,该船共有10层甲板,从上到下分别是:救生艇甲板(Top Deck),A~G共8层载客的甲板,H甲板和底层是锅炉和仓库。那么舱位(Cabin)信息是C85,是不是表示它位于C甲板?可以试着统计一下,验证一下猜想。
-
票价和船舱等级的关系。一些资料显示,一等舱票价30英镑起步(如果是套房就更贵了,最贵票价870英镑),乘客主要是富豪贵族和社会名流;二等舱票价13英镑,乘客主要是中产阶级如律师医生等精英职业;三等舱票价7~9英镑,儿童票价是3英镑,乘客主要是来自英国、爱尔兰、北欧、意大利、俄国和土耳其等地的贫穷移民。结合这些资料,可猜测本项目中的票价(Fare)单位是英镑。但是有一些记录似乎有点不对劲,例如有的三等舱票价21英镑?可能是因为是与亲属一起买的套票。例如船上有8位中国人,买的是56英镑的三等舱套票,这样的话会使其舱位等级和票价不符,不知道会不会影响算法结果。
-
舱位(Cabin)信息其实可以表示距离救生艇的远近,离救生艇较近的获救概率应该更大。但缺失值太多了,可能用处不大。
-
船票号目前没什么头绪。可能与船舱等级、舱位、登船口岸等有关。
3.2 查看各项数据的分布
3.2.1 数值统计
统计是否获救、性别、船舱等级、父母子女数量、兄弟姐妹数量、登船港口的分布。代码如下:
# 数值统计
print('---------- 1、获救人数 ----------')
print(d_train.groupby(['Survived'])['PassengerId'].count())
print('\n---------- 2、性别分布 ----------')
print(d_train.groupby(['Sex'])['PassengerId'].count())
print('\n---------- 3、船舱等级分布 ----------')
print(d_train.groupby(['Pclass'])['PassengerId'].count())
print('\n---------- 4、父母/子女数量分布 ----------')
print(d_train.groupby(['Parch'])['PassengerId'].count())
print('\n---------- 5、兄弟姐妹数量分布 ----------')
print(d_train.groupby(['SibSp'])['PassengerId'].count())
print('\n---------- 6、登船港口分布 ----------')
print(d_train.groupby(['Embarked'])['PassengerId'].count())
print('\n---------- 7、称呼的分布 ----------')
d_train['Title'] = d_train['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
print(pd.crosstab(d_train['Title'], d_train['Sex']))
print('\n---------- 8、名字长度分布 ----------')
d_train['NameLength'] = d_train['Name'].apply(len)
print(d_train.groupby(['NameLength'])['PassengerId'].count())
print('\n---------- 9、舱位甲板分布 ----------')
d_train['Deck'] = d_train['Cabin'].str[0]
print(d_train.groupby(['Deck'])['PassengerId'].count())
得到结果如下:
---------- 1、获救人数 ----------
Survived
0 549
1 342
Name: PassengerId, dtype: int64
---------- 2、性别分布 ----------
Sex
female 314
male 577
Name: PassengerId, dtype: int64
---------- 3、船舱等级分布 ----------
Pclass
1 216
2 184
3 491
Name: PassengerId, dtype: int64
---------- 4、父母/子女数量分布 ----------
Parch
0 678
1 118
2 80
3 5
4 4
5 5
6 1
Name: PassengerId, dtype: int64
---------- 5、兄弟姐妹数量分布 ----------
SibSp
0 608
1 209
2 28
3 16
4 18
5 5
8 7
Name: PassengerId, dtype: int64
---------- 6、登船港口分布 ----------
Embarked
C 168
Q 77
S 644
Name: PassengerId, dtype: int64
---------- 7、称呼的分布 ----------
Sex female male
Title
Capt 0 1
Col 0 2
Countess 1 0
Don 0 1
Dr 1 6
Jonkheer 0 1
Lady 1 0
Major 0 2
Master 0 40
Miss 182 0
Mlle 2 0
Mme 1 0
Mr 0 517
Mrs 125 0
Ms 1 0
Rev 0 6
Sir 0 1
---------- 8、名字长度分布 ----------
NameLength
12 2
13 2
14 3
15 15
16 26
17 42
18 50
19 64
20 39
21 40
22 38
23 39
24 43
25 55
26 49
27 50
28 43
29 32
30 37
31 30
32 23
33 22
34 7
35 6
36 9
37 10
38 9
39 9
40 7
41 8
42 5
43 5
44 8
45 9
46 7
47 11
48 3
49 5
50 4
51 7
52 4
53 2
54 1
55 2
56 3
57 2
61 1
65 1
67 1
82 1
Name: PassengerId, dtype: int64
---------- 9、舱位甲板分布 ----------
Deck
A 15
B 47
C 59
D 33
E 32
F 13
G 4
T 1
Name: PassengerId, dtype: int64
有很多种称呼(Title),整理了一下:
| 序号 | 称谓 | 含义 | 女性人数 | 男性人数 |
|---|---|---|---|---|
| 1 | Capt | 船长 | 0 | 1 |
| 2 | Col | 上校(简写) | 0 | 2 |
| 3 | Countess | 女伯爵/伯爵夫人 | 1 | 0 |
| 4 | Don | 大学教师 | 0 | 1 |
| 5 | Dr | 博士/医生 | 1 | 6 |
| 6 | Jonkheer | 可能是某个家族 | 0 | 1 |
| 7 | Lady | 女士(可能有一定地位) | 1 | 0 |
| 8 | Major | 少校 | 0 | 2 |
| 9 | Master | 硕士/专家 | 0 | 40 |
| 10 | Miss | (未婚)女士 | 182 | 0 |
| 11 | Mlle | 小姐(法语) | 2 | 0 |
| 12 | Mme | 夫人(法语) | 1 | 0 |
| 13 | Mr | 先生 | 0 | 517 |
| 14 | Mrs | (已婚)女士 | 125 | 0 |
| 15 | Ms | 女士(不指名婚否) | 1 | 0 |
| 16 | Rev | – | 0 | 6 |
| 17 | Sir | 男爵 | 0 | 1 |
-
另外测试集中还有一条Title是 Dona 的39岁头等舱女性,应该也是有一定社会地位的。
-
不知道 Master 指的是什么,因为Master有专家的意思,一开始我以为是随同登船的设计师团队,后来看了一下乘客的详细情况,发现年龄最大的是12岁,所以这里Master应该指的是小于等于12岁的男孩。顺便又看了一下,女孩都计算在Miss这个称呼里面,小于等于12岁的有32个。
-
Rev 这个缩写真的不知道是什么,都是二等舱,年龄范围也挺大的,但是数量不多。
-
Jonkheer 这个也比较奇怪,票价是0。我看了一下训练集中一共有15位票价是0的。三个舱位等级都有分布。大多数是Mr的称呼。有几张票号还是相同的,可能是套票?
-
Major其实也不太能确定是少校的意思,只是Major有这个意思,而且看了一下年龄比较符合。
-
基于以上分析可以对这些称呼对应的身份做一个大致分类:
| 分类名 | 称谓 |
|---|---|
| 专业人士(船长或军官) | Capt, Col, Major |
| 有社会地位的 | Countess, Don, Dona, Dr, Lady, Sir |
| 普通已婚女性 | Mme, Mrs, Ms |
| 普通未婚女性 | Miss, Mlle |
| 普通男性 | Master, Mr |
| 不明身份 | Jonkheer, Rev |
3.2.2 绘图观察
将上面的统计数值转化为直观的条形图来观察,再加上年龄的密度分布等。代码如下:
#coding=utf-8
import warnings
warnings.filterwarnings('ignore') #不输出warning信息
#绘图,简单了解一下训练集中各项数据的分布
import matplotlib.pyplot as plt
fig1 = plt.figure(facecolor='gray',figsize=(22,10))
# 获救人数分布
plt.subplot(2,4,1)
d_train.Survived.value_counts().plot(kind='bar')
plt.xlabel(u'是否获救', fontproperties="Microsoft YaHei") #设置标签字体为雅黑,否则会乱码
plt.xticks(rotation=360) #横轴标签旋转为正的
plt.ylabel(u"人数", fontproperties="Microsoft YaHei")
plt.title(u"获救分布", fontproperties="Microsoft YaHei")
#性别分布
plt.subplot(2,4,2)
d_train.Sex.value_counts().plot(kind='bar', rot=360) #设置标签正向显示
plt.xlabel(u'性别', fontproperties="Microsoft YaHei")
plt.ylabel(u'人数', fontproperties='Microsoft YaHei')
plt.title(u'性别分布', fontproperties='Microsoft YaHei')
#舱位分布
plt.subplot(2,4,3)
# 使用下面这种统计方式是为了让X轴按顺序排列
d_train.groupby(['Pclass'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.xlabel(u'舱位', fontproperties="Microsoft YaHei")
plt.ylabel(u'人数', fontproperties='Microsoft YaHei')
plt.title(u'舱位分布', fontproperties='Microsoft YaHei')
#兄弟姐妹/配偶数量分布(旁系亲属)
plt.subplot(2,4,4)
d_train.groupby(['SibSp'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.xlabel('兄弟姐妹/配偶数量', fontproperties='Microsoft YaHei')
plt.ylabel('人数', fontproperties='Microsoft YaHei')
plt.title('兄弟姐妹/配偶数量分布', fontproperties='Microsoft YaHei')
#父母/子女数量分布(直系亲属)
plt.subplot(2,4,5)
d_train.groupby(['Parch'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.xlabel('父母/子女数量', fontproperties='Microsoft YaHei')
plt.ylabel('人数', fontproperties='Microsoft YaHei')
plt.title('父母/子女数量分布', fontproperties='Microsoft YaHei')
#登船口岸分布
plt.subplot(2,4,6)
d_train.groupby(['Embarked'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.xlabel('登船地点', fontproperties='Microsoft YaHei')
plt.ylabel('人数', fontproperties='Microsoft YaHei')
plt.title('登船地点分布', fontproperties='Microsoft YaHei')
#各等级舱位中的年龄密度
plt.subplot2grid((2,4),(1,2),colspan=2)
d_train.Age[d_train['Pclass'] == 1].value_counts().plot(kind='kde')
d_train.Age[d_train['Pclass'] == 2].value_counts().plot(kind='kde')
d_train.Age[d_train['Pclass'] == 3].value_counts().plot(kind='kde')
plt.legend(('Pclass 1','Pclass 2','Pclass 3'))
plt.xlabel('年龄', fontproperties='Microsoft YaHei')
plt.ylabel('密度', fontproperties='Micorsoft YaHei')
plt.title('各等级舱位中的年龄密度', fontproperties='Microsoft YaHei')
plt.show()
得到7幅子图如下:

3.3 分析过程
绘图并观察获救与年龄、性别、船舱等的关系。
(1)性别与是否获救的关系
fig1 = plt.figure(facecolor='gray')
d_train.groupby(['Sex','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()
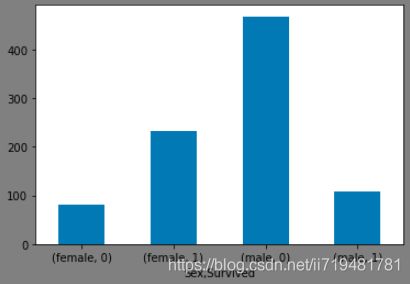
可以看出,女性获救的概率更大。
(2)船舱等级与是否获救的关系
fig2 = plt.figure(facecolor='gray')
d_train.groupby(['Pclass','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()
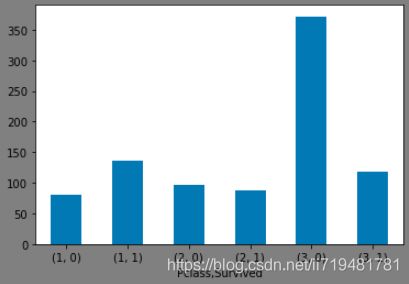
获救的概率:一等舱>二等舱>三等舱。
(3)登船地点与是否获救的关系
fig3 = plt.figure(facecolor='gray')
d_train.groupby(['Embarked','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()
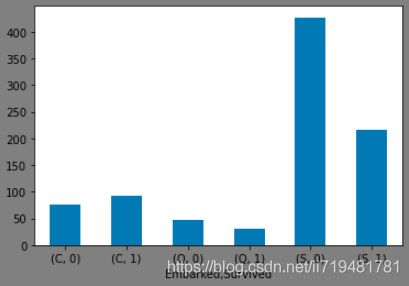
获救概率:C > Q > S。不知道是否与各个港口乘客的船舱等级有关。
(4)登船地点与船舱等级的关系
fig4 = plt.figure(facecolor='gray')
d_train.groupby(['Embarked','Pclass'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()

一等舱的乘客绝大部分是在C和S登船的,S比C多;二等舱的乘客有小部分在C、大部分在S登船;三等舱的乘客小部分在C和Q,大部分在S登船,C和Q登船的人数差不多。整理成表格如下(缺失了两条港口数据):
| 港口 | 一等舱乘客数 | 二等舱乘客数 | 三等舱乘客数 | 总计 |
|---|---|---|---|---|
| S | 127 | 164 | 353 | 644 |
| C | 85 | 17 | 66 | 168 |
| Q | 2 | 3 | 72 | 77 |
(5)年龄与获救的关系
fig5 = plt.figure(facecolor='gray')
d_train.Age[d_train['Survived'] == 1].value_counts().plot(kind='kde')
d_train.Age[d_train['Survived'] == 0].value_counts().plot(kind='kde')
plt.legend(['Survived=1','Survived=0'])
plt.show()
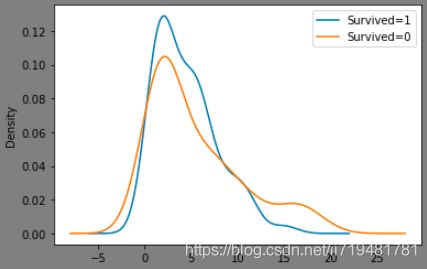
青年获救的概率更大。
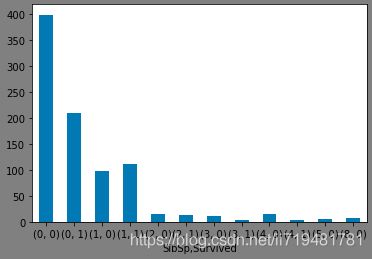
(6)兄弟姐妹数量与获救的关系
fig6 = plt.figure(facecolor='gray')
d_train.groupby(['SibSp','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()
(7)父母子女数量与获救的关系
fig7 = plt.figure(facecolor='gray')
d_train.groupby(['Parch','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()

(8)有无船舱信息与获救的关系
fig8 = plt.figure(facecolor='gray',figsize=(10,8))
plt.subplot(2,1,1)
d_train['HaveCabin'] = 1
d_train['HaveCabin'][d_train['Cabin'].isnull() == True] = 0
d_train.groupby(['HaveCabin','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.subplot(2,1,2)
d_train.groupby(['Deck','Survived'])['PassengerId'].count().plot(kind='bar',rot=360)
plt.show()

有舱位信息的获救概率更高。
(9)姓名与获救的关系(包括称呼、姓名长度等)
# 称呼与获救的关系
fig9 = plt.figure(facecolor='gray', figsize=(12,10))
plt.subplot(2,1,1)
d_train.groupby(['Title','Survived'])['PassengerId'].count().plot(kind='bar',rot=320)
plt.text(x=3,y=350,s='称呼与获救的关系:(称呼,是否获救)',fontproperties='Microsoft YaHei',size=13)
plt.xlabel('')
plt.subplot(2,1,2)
d_train.NameLength[d_train['Survived'] == 1].value_counts().plot(kind='kde')
d_train.NameLength[d_train['Survived'] == 0].value_counts().plot(kind='kde')
plt.legend({'Survived=1','Survived=0'})
plt.text(x=13,y=0.06,s='名字长度与获救的关系:(名字长度,是否获救)',fontproperties='Microsoft YaHei',size=13)
plt.show()
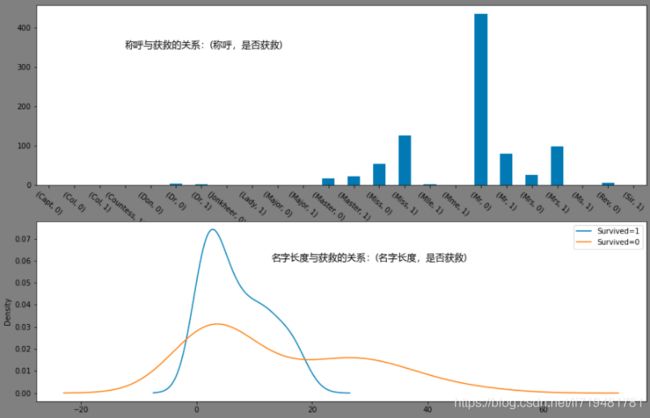
几个人数比较多的称呼中,Mrs和Miss获救概率较高,而Mr获救概率较低。而名字长度太长和太短的好像获救概率都不高。
(10)票价与获救的关系, 票价与船舱等级的关系
ffig10 = plt.figure(facecolor='gray',figsize=(12,7))
# 票价与获救的关系
plt.subplot(2,1,1)
plt.boxplot([d_train['Fare'][d_train['Survived']==1],d_train['Fare'][d_train['Survived']==0]],
vert=False, showmeans=True)
plt.yticks([1,2],['Survived=1','Survived=0'])
# 票价与船舱等级的关系
plt.subplot(2,1,2)
plt.boxplot([d_train['Fare'][d_train['Pclass']==1],d_train['Fare'][d_train['Pclass']==2],d_train['Fare'][d_train['Pclass']==3]],
vert=False, showmeans=True)
plt.yticks([1,2,3],['Pclass=1','Pclass=2','Pclass=3'])
plt.show()

没有特别明显的界限,但似乎票价稍高一点的获救概率较大。
3.4 缺失值与异常值观察
现在观察缺失值情况,看如何去补全它们。数据的缺失情况如下表,Cabin 字段缺失的太多了,放弃填充。其他的Age、Embarked、Fare似乎都有机会补全。
| 字段名称 | 训练集缺失条数及占比 | 测试集缺失条数及占比 |
|---|---|---|
| Age | 177 (19.9%) | 86 (20.6%) |
| Cabin | 687 (77.1%) | 327 (78.2%) |
| Emarked | 2 (0.2%) | 0 |
| Fare | 0 | 1 (0.2%) |
(1)Embarked字段
print('----------训练集 Embarked 缺失值---------')
d_train[(d_train['Embarked'].isnull() == 1)]

这两位乘客是一等舱的同一间房间,票号、票价还都一样,但好像并不是亲属关系。因为从C港口上船的乘客大多数 Ticket(票号)都是“PC”开头的,所以更有可能是从S港口上船的。于是把这两个置为“S"。
(2)Fare字段
print('----------测试集 Fare 缺失---------')
d_test[(d_test['Fare'].isnull() == 1)]

这位是三等舱的乘客,60.5岁,从S港口上船,无舱位信息,无亲属;且找不到另一个相同的Ticket票号。因为只有这一个缺失值,所以取具有如下特征的乘客的票价均值:“从S港口上船,三等舱,无亲属,年龄50~70岁”。但测试集中没有符合条件的记录,训练集中有8条,所以使用训练集的数据填充。这种方法得到的值是7.75365,
(3)Age字段
print('----------训练集 Age 缺失---------')
d_train[d_train.Age.isnull() == 1].head(10)

Age的缺失了20%的值,而且男性女性,三个港口,以及三个舱位等级都有分布,很难逐一去填补缺失值。因此有两种方法:一是直接把Age为空作为一个“NaN”的新类型,放到模型中计算;二是使用某种方法对Age进行拟合,填补这些缺失值。这里使用第二种方法。
3.5 数据探索的总结
(1)数据的情况总结
女性获救概率比男性大;一等舱获救概率较大;青壮年获救概率较大;有舱位信息的获救概率高;名字太长或太短的获救概率不高;票价则无特别明显的界限,但似乎票价稍高一点的获救概率会较高。
(2)数据预处理方法
-
数据清洗部分
-
训练集和测试集中,Age 都缺失20%左右,Cabin 都缺失78%左右。对Age缺失值,因为缺失的比例比较小,而且Age是一个比较重要的的因素,因此使用模型拟合填补它;
-
Cabin 缺失的比例实在太大,而且不知道船上舱位布局是怎样,无法判断距离救生艇的远近,所以这里直接丢弃原 Cabin 字段。也可以将其处理成为“有无Cabin”的形式,因为前面的分析可以看到,有舱位信息的乘客获救的概率较高。另外,前面还由Cabin 衍生出了“Deck”(甲板)信息,但由于缺失值太多,也直接丢弃。
-
缺失只有一两条的 Embarked 和 Fare 字段,可以直接用众数或者平均数来填充。另外因为Ticket没有缺失值,可以看看它和 Embarked 有没有什么关系,或许可以确定 Emarked 的值。
-
直接丢弃的字段:Name、Ticket、Cabin。其中 Name 直接丢弃,但保留它衍生的两个特征 Title(处理成TitleType) 和 NameLength;Cabin则处理成 HaveCabin。
-
-
数据转换部分
-
在数据探索阶段,生成了几个新的特征,Title(称呼),NameLength(名字长度),HaveCabin(有无舱位信息),需要进行相应处理,Title可以进行One-hot处理。
-
其他需要进行 one-hot 编码的字段:Embarked,Sex,Pclass, Title, HaveCabin。
-
从之前的分析中发现有亲属一起出行的通常买的是套票,需要把套票的价格平均分配到每个人头上。
-
(3)建模方法规划
逻辑回归,随机森林,XGBT模型似乎都可以,现在对于选用模型方面经验不多,先把觉得能用的都试试,可以比较一下效果。
0x03、预处理
预处理大致分为两个操作:一是对数据进行清洗,如缺失值的补全或丢弃,异常值处理等;二是将数据处理转换成为建模需要的格式,如特征工程、归一化、one-hot编码等。
3.1 数据清洗
3.1.1 缺失值补全
(1)Embarked字段
根据分析直接填充为“S”:
d_train.Embarked[d_train.Embarked.isnull() == 1] = 'S'
(2)Fare字段
使用均值填充:
d_test.Fare[d_test.Fare.isnull() == 1] = d_train.Fare[(d_train.Pclass==3) & (d_train.Embarked=='S') & (d_train.SibSp + d_train.Parch == 0) & (d_train.Age >= 50) & (d_train.Age <= 70)].mean()
(3)Age字段
这里基于参考资料1的方法,并增加了性别和舱位等级这两个因素,使用随机森林来填补Age缺失值。
from sklearn.ensemble import RandomForestRegressor
def set_missing_age(d_df):
df_age = d_df[['Age','Pclass','SibSp','Parch','Fare','Sex','Embarked']]
# 对 Sex, Embarked 进行one-hot编码
dummies_Sex = pd.get_dummies(df_age.Sex, prefix='Sex')
dummies_Embarked = pd.get_dummies(df_age.Embarked, prefix='Embarked')
df_age = pd.concat([df_age, dummies_Sex, dummies_Embarked], axis=1)
df_age.drop(['Sex','Embarked'], axis=1, inplace=True)
print(df_age.columns)
# 将df_age 按Age是否为空分成两份
known_age = df_age[df_age.Age.notnull() == 1].as_matrix()
unknown_age = df_age[df_age.Age.isnull() == 1].as_matrix()
#分割成训练集
age_train_X = known_age[:, 1:]
age_train_y = known_age[:, 0]
# 建立随机森林模型
rfr = RandomForestRegressor(random_state=0, n_estimators=2000)
rfr.fit(age_train_X, age_train_y)
# 预测年龄
predict_age = rfr.predict(unknown_age[:, 1:])
# 用预测得到的值填补缺失值
d_df.loc[(d_df.Age.isnull()), 'Age'] = predict_age
return d_df
d_train = set_missing_age(d_train)
d_test = set_missing_age(d_test)
3.1.2 字段转换
(1)从Name中提取 Title,再将Title分类得到TitleType
# 提取title
d_train['Title'] = d_train['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
d_test['Title'] = d_test['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
title_Dict = {}
title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major'], 'Officer'))
title_Dict.update(dict.fromkeys(['Don', 'Sir', 'Countess', 'Dona', 'Lady','Dr'], 'Nobility'))
title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
title_Dict.update(dict.fromkeys(['Mr','Master'], 'Mr'))
title_Dict.update(dict.fromkeys(['Rev','Jonkheer'], 'Rev'))
d_train['TitleType'] = d_train['Title'].map(title_Dict)
d_test['TitleType'] = d_test['Title'].map(title_Dict)
(2)计算 Name 的长度 NameLength
d_train['NameLength'] = d_train['Name'].apply(len)
d_test['NameLength'] = d_test['Name'].apply(len)
(3)Cabin 字段转换为 HaveCabin
def set_cabin_type(df):
df['HaveCabin'] = 'No'
df.HaveCabin[df.Cabin.notnull() == 1] = 'Yes'
return df
d_train = set_cabin_type(d_train)
d_test = set_cabin_type(d_test)
3.2 数据编码和归一化
(1)对Pclass, Sex, Embarked, Title, HaveCabin 进行one-hot编码
def one_hot_encode(df):
dummies_Pclass = pd.get_dummies(df.Pclass, prefix='Pclass')
dummies_Sex = pd.get_dummies(df.Sex, prefix='Sex')
dummies_Embarked = pd.get_dummies(df.Embarked, prefix='Embarked')
dummies_TitleType = pd.get_dummies(df.TitleType, prefix='TitleType')
dummies_HaveCabin = pd.get_dummies(df.HaveCabin, prefix='HaveCabin')
df = pd.concat([df, dummies_Pclass, dummies_Sex, dummies_Embarked, dummies_TitleType, dummies_HaveCabin], axis=1)
return df
d_train = one_hot_encode(d_train)
d_test = one_hot_encode(d_test)
(2)对 Age,Fare,Parch,SibSp,NameLength 进行归一化
import numpy as np
import sklearn.preprocessing as preprocessing
def df_scaling(df):
df['Age_scaled'] = preprocessing.scale(np.asarray(df.Age).reshape(-1,1))
df['Fare_scaled'] = preprocessing.scale(np.asarray(df.Fare).reshape(-1,1))
df['Prach_scaled'] = preprocessing.scale(np.asarray(df.Parch).reshape(-1,1))
df['SibSp_scaled'] = preprocessing.scale(np.asarray(df.SibSp).reshape(-1,1))
df['NameLength_scaled'] = preprocessing.scale(np.asarray(df.NameLength).reshape(-1,1))
return df
d_train = df_scaling(d_train)
d_test = df_scaling(d_test)
3.3 取需要的字段
取处理过的字段:
d_train = d_train[['Survived', 'Pclass_1', 'Pclass_2', 'Pclass_3','Sex_female', 'Sex_male',
'Embarked_C', 'Embarked_Q', 'Embarked_S', 'TitleType_Miss', 'TitleType_Mr',
'TitleType_Mrs', 'TitleType_Nobility', 'TitleType_Officer', 'TitleType_Rev',
'HaveCabin_No', 'HaveCabin_Yes', 'Age_scaled', 'Fare_scaled', 'Prach_scaled',
'SibSp_scaled', 'NameLength_scaled']]
d_test = d_train[['Pclass_1', 'Pclass_2', 'Pclass_3','Sex_female', 'Sex_male',
'Embarked_C', 'Embarked_Q', 'Embarked_S', 'TitleType_Miss', 'TitleType_Mr',
'TitleType_Mrs', 'TitleType_Nobility', 'TitleType_Officer', 'TitleType_Rev',
'HaveCabin_No', 'HaveCabin_Yes', 'Age_scaled', 'Fare_scaled', 'Prach_scaled',
'SibSp_scaled', 'NameLength_scaled']]
这样预处理工作就完成了。接下来就是建模和模型优化的工作了。
0x04、建立模型
4.1 逻辑回归模型
我在使用哪个模型方面真的没有什么经验。所以先用逻辑回归试试吧。
from sklearn.linear_model import LogisticRegression
# 建立
lrc = LogisticRegression(C=1.0, penalty='l2', tol=1e-6)
lrc.fit(train_X, train_y)
# 预测
lrc_predict = lrc.predict(test_X)
# 输出为需要的格式
lrc_result = pd.DataFrame({'PassengerId':d_test['PassengerId'].as_matrix(), 'Survived':lrc_predict.astype(np.int32)})
lrc_result.to_csv("lrc_submission.csv", index=False)
这样就可以在Kaggle上提交了。一开始怎么都提交不上,后来搜了一下发现提交和注册时一样,需要_梯子_,最后自己找了一把,终于提交成功了T_T。第一次提交并不是很高分,正常,正常~
下面来想想怎样优化。至少有三个可以优化的方向:一是特征工程,尝试使用别的划分方法,例如把年龄更加细粒度地划分;二是把数据放到其他模型里试试;三是在当前模型里调整参数,使模型能更好地拟合数据。当然实际操作时这三个方法是要结合起来的。现在先把数据放到其他模型里试试,并使用“交叉验证”的方法,在训练集里面拿出一部分数据验证一下模型效果。
4.2 交叉验证
(1)先看看之前的逻辑回归模型的分数:
from sklearn.model_selection import cross_validate
print('---- LogisticRegression cross_validate ----')
cross_validate(lrc, train_X, train_y, cv=5)

(2)使用随机森林
这里使用默认参数。
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(train_X, train_y)
# 交叉验证
print('---- RandomForestClassifier cross_validate ----')
cross_validate(rfc, train_X, train_y, cv=5)

(3)GBDT
这里同样使用默认参数。
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier()
gbc.fit(train_X, train_y)
# 交叉验证
print('---- GBDT cross_validate ----')
cross_validate(gbc, train_X, train_y, cv=5)
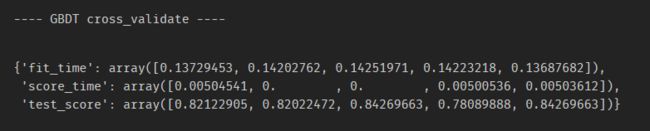
(4)xgboost
from xgboost import XGBClassifier
xgbc = XGBClassifier()
xgbc.fit(train_X, train_y)
# 交叉验证
print('---- xgboost cross_validate ----')
cross_validate(xgbc, train_X, train_y, cv=5)
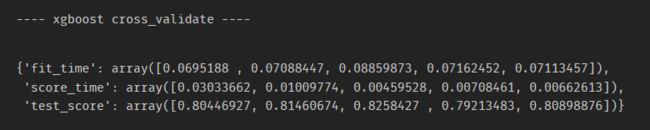
可以看到,使用默认参数的GBDT分数要高于随机森林。
0x05、总结与展望
-
总结
-
由于时间有限,不再继续深入挖掘了。这是第一次尝试,花了很多时间,也收获很多。对我来说这是第一次在实际项目中使用pandas,虽然之前学习过它的用法,但是在实际的应用中还是有很多不足,需要一边查找用法一边写代码,花费了不少时间。
-
对数据的认知真的很重要。我们拿到一份数据时,那就是盲人摸象,横看成岭侧成峰。要充分探索数据,从宏观、微观等方面找到数据间的联系。在此基础上才能更好地进行特征工程。
-
模型融合方法有bagging,boosting和stacking,本次由于时间有限就没有尝试stacking了,希望在下个项目里尝试一下。
-
-
改进方法
-
在数据探索步骤中有发现一些点,在这些地方进行改进可能会进一步提高模型准确度。
-
票价。因为有一些亲友同行的情况,这些人买的是套票,所以会出现三等舱票价21英镑的情况。可以把这些高票价平均分到这些人头上。会使票价的参考性更强。
-
人群细分。我这里把Master(小男孩)划分到男性群体中了,但孩童的存活概率明显高于成人,所以可以把Miss中的小于14岁的孩子也取出来单独分为一类。
-
附录:从泰坦尼克号相关资料中提取出的一些可能有用的信息
(基本来源于维基百科相关页面)
-
泰坦尼克号的航线:南安普敦(英国)-> 瑟堡(法国)-> 皇后镇(爱尔兰)-> 纽约(美国)。1912年4月10日从南安普敦港出发,4月14日星期天23时40分与一座冰山擦撞,右舷侧面部分船体出现缝隙,16个水密隔舱中的5个进水,而该船的设计仅能承受4个水密舱进水。2小时40分后,船只沉没。
-
1912年4月10日12时,泰坦尼克号离开英国南安普敦港,载着920名乘客展开首航(其中31人是购买短程票,在瑟堡和皇后镇下船)。首段航程先穿过英吉利海峡,18时30分到第一个停靠港法国瑟堡搭载274名乘客,20时10分离港;4月11日11时30分到达爱尔兰的皇后镇(现在的科芙),这里是第二个停靠港,搭载123名乘客和更多货物后,于当天13时30分离港,正式航向美国纽约。当泰坦尼克号横渡北大西洋时,她载着1332名乘客和892名船员。
-
泰坦尼克号可容纳833名头等舱乘客、二等舱614人、三等舱1006人,总客运量为2453人。还可以容纳超过900名船员,因此全部载客量为3547人。这次航行中有乘客1316名,客运量只达到一半。
-
船舱分布。共10层甲板:小艇甲板(Top Deck,主要是舰桥和海官起居舱,并存放了20搜救生艇)、A~G层甲板(乘客起居舱),H层甲板(货舱)与双层底舱顶板(锅炉、发动机等)。简单总结:头等舱(ABCD层),二等舱(DEF层),三等舱(EFG层)。
| 序号 | 甲板名称 | 船舱分布及作用说明 |
|---|---|---|
| 1 | 小艇甲板(顶层甲板,Top Deck) | 两侧排列着20艘救生艇;海官起居舱:舰桥,操舵室、电报室等;头等吸烟室,二等舱入口 |
| 2 | A层(散步甲板) | 34间头等舱客房,两间特等舱,头等读写室,头等休息室等 |
| 3 | B层(荍艛甲板,Bridge Deck) | 97个头等舱客房(含6间套房),头等餐厅和咖啡厅;二等门厅和吸烟室;艉艛甲板是三等舱乘客的散步场所 |
| 4 | C层(主甲板/遮蔽甲板,Shelter Deck) | 148间头等舱客房,头等理发店、仆人起居舱、船员起居舱、医生办公室等;二等图书室 |
| 5 | D层(交谊甲板,Saloon Deck) | 50间普通的更便宜的头等舱客房;头等接待室、餐厅,头等和二等面包店、肉店、医院;前端是船员起居舱。 |
| 6 | E层(上甲板,Upper Deck) | 二等客舱;三等客舱、船员起居舱、二等理发店、洗衣店、三等公共浴室、纠察长起居室等设施;厨师、海员、服务员和机房工人的舱间。 |
| 7 | F层(中甲板,Middle Deck) | 二等舱、三等舱、船员舱。三等餐厅、三等厨房、三等面包店及肉店;头等舱乘客付费使用的温水游泳池及土耳其浴室。最后一个完整的甲板,由防水舱壁分隔成12个部分。 |
| 8 | G层(下甲板,Lower Deck) | 三等客舱;头等乘客专用的壁球室;邮局、食品储藏室、食品冷冻柜、头等舱行李室、货舱、部分船员起居舱也都在这里。 |
| 9 | H层 | 主要用途是储存,前段是头等行李舱、二等行李舱和邮件室,后段则是冷藏货舱、煤仓、酒窖、食品储藏室和各种车间。 |
| 10 | 底层 | 锅炉、发动机、供水加热器、船舶制冷设备、泵送装置、各种管道、阀门和其他辅助设备 |
-
救生艇:20艘(可容纳1178人,位于最上层的小艇甲板),编号AD,116,大部分救生艇未坐满。分布位置和使用情况如下:
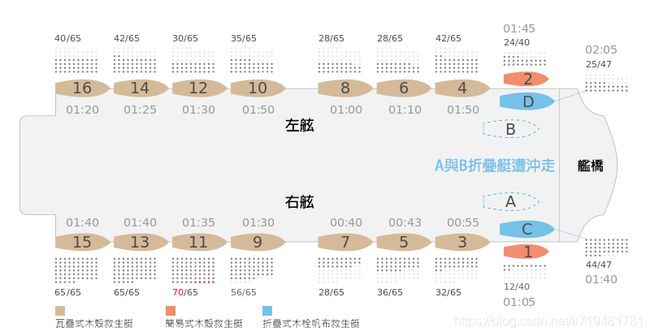
-
乘载人员数量:(按这里的统计,乘客1316人,船员908人)
| 舱位 | 孩童人数 | 女性人数 | 男性人数 | 总计 |
|---|---|---|---|---|
| 一等舱 | 6 | 144 | 175 | 325 |
| 二等舱 | 24 | 93 | 168 | 285 |
| 三等舱 | 79 | 165 | 462 | 706 |
| 船员 | 0 | 23 | 885 | 908 |
| 总计 | 109 | 425 | 1690 | 2224 |
-
维基百科上的统计数据:
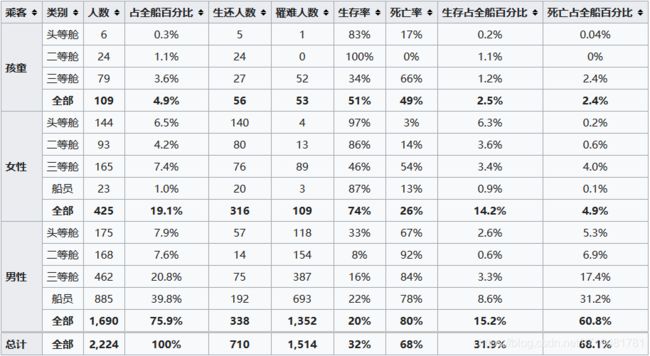
-
最便宜的头等舱票价是23英镑(不含餐饮费),套房价格是400~870英镑。头等舱几乎占据了全部B甲板和C甲板,并占据了A、D、E甲板上很大的部分;还有几间头等舱室在船的主甲板上,位于前面的主楼梯和船长宿舍之间。E甲板部分房间和船舱可在头等舱和二等舱之间互换,这意味着在超订或需求过高的情况下,可以将部分舱室优先分配给其中一个。E1至E42号房间就是头等舱/二等舱备用舱室。
-
来自南安普敦、瑟堡或皇后镇的三等舱单人票价为7英镑5先令,这包括前往港口的铁路专车和所有船上食宿的费用;儿童票价是3英镑。大部分三等舱乘客都是移民,此行希望在美国和加拿大开始新的生活。当时的三等舱是个多元化族群——除了大量的英国、爱尔兰和斯堪地纳维亚移民外,还有许多奥斯曼帝国(主要是现今的黎巴嫩和叙利亚)移民,以及来自英属香港的中国人。这些中国人是凭郎方(Lang Fang)购买的8人套票登船,价格是56英镑9先令11便士,他们计划一起前往纽约;最终有6人在灾难中幸存下来,但由于《排华法案》,他们遭美国当局拒绝入境,于4月19日遣送至古巴。另外,有部分乘客使用了假名购票。
-
三等舱乘客必须经过漫长且曲折的路线才能到达顶层甲板;位于C层至G层甲板上的三等舱客房,那里是泰坦尼克号的最末端,离救生艇最远。相比之下,头等舱套房位于上甲板右舷,离救生艇最近。因此,与救生艇的距离远近成为生还几率的关键因素。还有一个条件增加了逃生难度,许多三等舱乘客看不懂或不会说英语,因此会英语的爱尔兰移民在三等舱乘客之中,具有特别高的幸存比例,这也许并非巧合。(是否可以从乘客名字中看出其语言?)
参考资料
- 机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾. 寒小阳. CSDN
- Kaggle_Titanic生存预测 – 详细流程吐血梳理. 大树先生. CSDN
- matplotlib显示中文
- 泰坦尼克号-百度百科
- 泰坦尼克号-维基百科
- 泰坦尼克号头等舱设施-维基百科
- 泰坦尼克号二等舱三等舱设施-维基百科
- 泰坦尼克号沉没事故-维基百科