【Knowledge Graph】C3KG: A Chinese Commonsense Conversation Knowledge Graph
C 3 ^3 3KG: A Chinese Commonsense Conversation Knowledge Graph
May 22-27, 2022 Association for Computational Linguistics
这篇文章所涉及到的领域不太熟悉,先记录下,以后方便看。
Abstract
现有的常识性知识库通常以一种孤立的方式来组织元组,这就缺乏常识性的会话模型来计划下一个步骤。为了填补这一空白,本文设计了一个大规模的多回合人写对话语料库,并创建了第一个包含社会常识知识和对话流信息的中国常识会话知识图。为了展示本文所提出的图的潜力,作者开发了一种图-对话匹配方法,并对两个基于图的会话任务进行了基准测试。
1. Introduction
常识描述了我们日常世界中的事实和相关判断,这在机器与人类互动时是必不可少的。这些年来,越来越多的文献将常识性知识融入到各种下游任务中。
最近,Sap等人设计一个大型的常识性知识库ATOMIC,涵盖了推理知识元组的以事件为中心的社会方面。例如,存在一些元组,如{PersonX adopts a cat, xEffect, feels happy}和{PersonX adopts a cat, xWant, company}。这里,xEffect和xWant是ATOMIC定义的9个关系中的两个,用来推断给定事件的心理状态。因此,在开发社交聊天机器人时,检测对话中提到的ATOMIC事件,并在对话中利用推断出的知识是很有希望的。
尽管该方法有潜力,但它仍面临两大困难。例如,当一个痛苦的朋友告诉我们他最近收养了一只猫时,我们人类很容易怀疑他可能对这只猫过敏。然而,这种推理对聊天机器人来说是很困难的。鉴于事件关系对{PersonX adopts a cat, xEffect, ___},ATOMIC包含多个tails,就像{finds out he has allergies},{becomes less lonely}。为此,第一个困难来自于多个tails的存在,这将在推断负面情绪背后的原因时,使聊天机器人感到困惑。
其次,ATOMIC中的知识元组是孤立的。因此,聊天机器人更难推断哪一个知识的tails应该使用,以此是的句子更加连贯。例如,如果从对话历史中检测到元组{PersonX adopts a cat, isAfter, finds a cat at the animal shelter},那么元组{PersonX adopts a cat, xNeed, go to an animal rescue center}进行未来的对话。我们认为,这些问题阻碍了ATOMIC对多回合对话建模的应用,其中会话代理不仅需要知道当前的状态,还需要规划未来的对话流。

为了解决这些问题,作者定义了4个新的对话流关系,,event flow, concept flow, emotion-cause flow, emotion-intent flow, 如图1。为了建立这些关系,作者在日常场景中收集了一个大规模的多回合对话,并使用情绪信息手动注释这些对话。基于这些注释,能够提取ATOMIC与对话相关的事件,并使用不同的对话流将它们连接起来。通过这种方式,作者用特定于对话的知识来增强ATOMIC,这有助于聊天机器人挑选出有用的常识知识,并减轻他们对与对话流不连贯的嘈杂知识的混淆。我们相信我们的图有利于常识性的对话建模。
Contribution
- 设计了一个新的中文语料库,包含关于日常生活主题的多回合人工对话和子话语层次的丰富高质量注释;
- 创建并将发布第一个大规模中国常识对话知识图C3KG,其中包含4种独特的对话流边,存储从多回合对话语料库中提取的对话知识;
- 设计了一种图会话匹配方法,并基于常识会话图对2个典型任务进行了基准实验。
2. Related Work
2.1 Commonsense Knowledge Bases
ConceptNet是一个流行的常识知识库(CKB),它有一个中文版本,知识集相对较小。另一个大规模的CKB是TransOMCS,它是通过将Web句子的句法解析转换为结构化知识而自动构建的。然而,现有CKB中的大多数关系都是分类学关系,如isA 和 Synonym,这不可避免地限制了它们的能力。不同的是,作者依赖于心理CBK ATOMIC,将ATOMIC转化为中文,并在其上面建立对话流关系,目的是促进中文会话系统。
为了构建这些ckb,ATOMIC和ConceceptNet依赖于众包,注释者根据自己的常识将tails知识添加到给定的实体或事件中。为了提高效率,Bosselut等人提出了COMET,这是一种预先训练的语言模型,能够在任何新事件下产生不同的tails知识。这使收集过程自动化,并导致常识性知识的缩放。然而,Zhang等人认为,COMET仍然存在过拟合问题,往往会产生高频繁和重复的知识。为了解决这个问题,他们开发了DISCOS,它能从现有的ckb中学习提取模式,并能从AESR知识图中自动提取常识性知识。
2.2 Connecting Knowledge and Conversation
这个工作其中一方面试图从对话中提取结构化的知识。这些工作从会话数据集中的每个话语中检测命名实体,并基于它们的顺序和点态相互信息(PMI)建立关系(。也有一些工作采用了自动提取工具,如OpenIE,构建某些领域的对话知识库。虽然这是合理的,但这些知识图是建立在单词或短语的粒度之上的,这使得它们很难匹配对话句子的整体语义。本文建立了一个基于多回合会话语料库和以事件为中心的知识库的汉语常识性会话知识图。同时,作者提出基于 Sentence-BERT在知识图中构建对话流边的方法。
人们对将常识知识融入对话建模越来越感兴趣。Zhou等人和Zhang等人将ConceptNet 的知识三联体引入开放域反应生成。最近,Li等人和Zhong等人利用ConceptNet增强响应生成的情感推理,其他研究者也设计图推理方法,在响应中计划主题转换。Ghosal等人利用ATOMIC进行情感对话建模以进行情绪识别。本文根据四种类型的对话流将ATOMIC中的头和尾连接起来。由于结果得到的图C 3 ^3 3KG既包含了ATOMIC知识,也包含了语料库的对话知识,因此更适合于移情对话建模。
3. A Scenario-based Multi-turn Conversation Corpus
作者的目标是从真实的对话中提取常见的对话流信息。这样,保证会话语料库的质量和提取方法的可靠性就至关重要了。下面首先介绍会话语料库CConv。
作者没有使用嘈杂的互联网数据,而是收集了一个基于众包的多回合人工书写的中文会话语料库。最初,雇佣了100名工作人员,他们在给定的场景下随机配对进行文本交谈。每个场景都是一个句子,描述了建议的对话背景,通常涉及到某些日常事件。此外,工作人员还必须遵守一些规则,如“每个话语应该超过6个汉字”,这对确保收集到的对话的质量至关重要。在众包开始时,检查每个收集到的对话,并对工作人员进行重新培训。为了保证质量,只保留了62名训练有素的工作人员,让他们完成我们的任务。请注意,工作人员每句工资1元(每句近0.2美元)。最后,作者获得了200次高质量的两方对话(共65万次),共15个日常主题。
为了便于未来的研究,又雇佣了另外3名训练有素的助手,用细粒度的情感标签手动标注对话,包括说话者的情绪类型、情绪原因和反应意图类型。继Rashkin等人之后,我们将情绪类型定义为5个一般类别{快乐、愤怒、悲伤、惊讶、其他}。情感原因跨度是一个连续的文本跨度,暗示了某种情绪的原因。反应意图类型对于构建移情聊天机器人至关重要,本文定义了6个常见的意图类别,如{ask, advise, describe, opinion, console, other}。图2中给出了一个会话示例的代码片段。

通过利用注释,作者提取对话知识,以增强会话图和基于图的会话建模。
4. Overview and Processing of ATOMIC
因为本文的会话语料库是中文的,所以作者想构建一个中文会话知识图。众所周知,从零开始构建一个知识图是非常费力和耗时的。相反,作者以 ATOMIC为基础,设计了一种管道方法,将其转化为中文,同时确保所得到的知识图是可靠的,适合于对话基础。
4.1 Brief Introduction of ATOMIC
ATOMIC以三联体的形式组织常识知识,其中头部经常描述日常事件。有两个独特的特性,使ATOMIC适合和有吸引力的构建移情聊天机器人。
- ATOMIC收集了关于人们对某一特定事件的反应的知识。这种知识与人们的心理状态有关,有助于理解内隐情绪。例如,给定一个头部事件,PersonX makes PersonY’s coffee,ATOMIC包含知识,PersonY会感激的关系oReact。
- 其次,ATOMIC使用几个推理关系来组织知识,并自然地支持if-then推理,这是至关重要的产生一致的反应。在ATOMIC中总共定义了9个关系。
在将ATOMIC翻译成中文方面,作者采用Regular Replacement和Joint Translation 的方法来提高翻译的质量,翻译后的ATOMIC表示为ATOMIC-zh。
5. Conversation Knowledge Graph Construction
5.1 Overview of C 3 ^3 3KG
为了为常识性推理提供对话流信息,本文创建了一个中国常识会话知识图C 3 ^3 3KG。然后,介绍了ATOMIC-zh和多回合会话语料库构造会话知识图的方法。一般来说,从每个对话中提取事件,并与ATOMIC-zh中的头部进行匹配。其核心是如何构建新的对话框流关系,如图2所示。
5.2 Event Extraction
ATOMIC-zh中的知识是基于事件的,其中大多数是声明性句子,其中省略了一些实体。然而,在端域对话数据集中的话语包含了许多结构更复杂的口语表达和子句。为了解决这个问题,本文开发了一个基于依赖关系解析的事件检测管道来提取每个话语中的显著事件。算法1描述了算法的概述。
Pre-processing. 我们首先用标点符号分割每一个话语,并在多余的水平上进行操作。为了减少噪声,我们然后用传递语义和哑语义过滤短的子话语,比如“好的”,“就是这样”。然后,使用ltp4进行依赖语句法解析和POS标记,并基于动词驱动和形容词驱动从句两种结构模式提取事件提及。
Verb-driven. 动词驱动的子句有一个动词连接到依赖项树中的根节点。在过滤了一些有噪声的单词后,得到了言语驱动的事件mention。例如,从话语“我和上司已经在催促提供物资的商家了”中提取了mention的“催促提供物资的商家”。在这个话语中,作者过滤了话语的主语“我和上司”,状语“已经”和模态粒子“了”。

Adjective-driven. 此外,形容词驱动从句往往有有意义的实体。同样,我们根据形容词驱动的从句提取形容词驱动的事件提及,通过保留关键形容词的修饰语,过滤掉其他词驱动的事件提及。例如,我们从话语“但学习节奏也太快了吧”中提取出mention的“学习节奏快”,过滤了话语结尾的初始连词“但是”,状词“也”和“太”,以及模态粒子“了”和“吧”。
Recursive Applying. 结果中的事件提及可能仍然包含多个动词和多个语义单元。在这种情况下,应用了一个二次分解。例如,把mention“以为进了大学就可以放松放松”)的活动分为两个活动:“进了大学”和“就可以放松放松”。为此计算了提到词中与词根词相连的动词的数量,以及由这些动词引导的子树的深度。基于这些结果,作者确定了该提到是否需要使用一个阈值进行二次分解。如果需要,会递归地在原始依赖树中搜索动词,并用我们找到的动词替换关键动词。
5.3 Event Linking as Matching

为了发现知识库之间的公共对话流,然后使用匹配技术将对话中提到的事件链接到ATOMIC。
通常采用Sentense-bert,一个强大的语义匹配模型,基于Siamese和 Triplet Network,对不同关系中的句子对进行预训练。它分别编码两个给定的句子,并计算它们的表示之间的相似性,从而在大规模的多对多匹配中有效地执行。
为了提高匹配性能,本文在语料库上对Sentence-BERT进行了微调。具体来说,随机选择8000个mention-head < m , h >
5.4 Edge Construction
现在有32k次多回合对话,并将他们的事件提到与ATOMIC头联系起来。剩下的部分是如何利用它们和建立常识性的会话知识图。在这项工作中,作者提出了三种边来反映不同类型的对话流。
5.4.1 Head-Head Edge Construction
Event Flow. 自然地,对话是分层的,因为它由两个对话者产生的一系列话语组成,其中每个话语由一个或几个子话语组成。如果在一个对话中同时检测到两个事件mention,则可以将共现视为一个对话流示例。按照流程,可以直观地连接提到链接的ATOMIC头,如图3所示。通过将话语内和话语间的提及联系起来,得到next-sub-utterance和next-utterance的事件流。
Concept Flow. 除了短语级事件之外,ATOMIC还具有实体级的head。为了利用它们,作者通过检测原始对话中属于{verb, noun, adjective}的POS标签的单词实体来执行实体链接,并将它们与实体级ATOMIC头进行匹配,以类似地构造概念流边。这些概念流有助于规划和转换主题感知对话中的内容。
因为我们一般对最常见的对话流很感兴趣,所以作者只保留这些高度频繁的连接,并在ATOMIC头实体和事件之间创建一个头对头的对话流。
5.4.2 Tail-Tail Edge Construction
此外,作者还考虑了另一种基本类型的对话流,即基于情感的同理心流。在本文中,作者利用语料库上的情感标签(在第3节中),在知识图中构造了两种基于情感的连接尾的边。直观地说,emotion-cause 的对话流反映了特定情绪的原因,这对细粒度的情绪理解很有用。emotion-intent 共情流表明当另一个人处于特定情绪时,反应意图适合使用,这对反应共情至关重要。
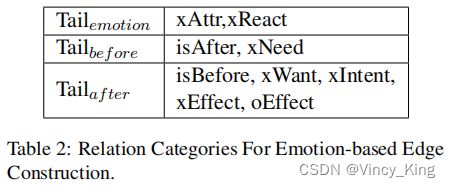
Pre-processing. 为了构建基于情感的边缘,作者根据它们的连接关系将尾巴分为3类,如表2所示。第一类尾巴通过关系xAttr或xReact联系起来,它反映了人们对某一事件(头部)的心理反应。例如,{PersonX runs out of steam, xAttr, tired}表示某人缺乏能量。把第一类表示为 T a i l e m o t i o n Tail_{emotion} Tailemotion。第二类 T a i l b e f o r e Tail_{before} Tailbefore,事件通常发生在头部之前,例如,{PersonX runs out of steam, isAfter, PersonX exercises in gym}。相反,最后一个类 T a i l a f t e r Tail_{after} Tailafter包含了头部事件之后的事件,如{PersonX runs out of steam, xWant, to get some energy}。
通过分析这些关系和尾部,作者发现了启发式方法来构建基于情感的对话流。通过在类别 T a i l e m o t i o n Tail_{emotion} Tailemotion上将头部和尾部连接起来,能够创建因果情绪推理,比如{PersonX exercises in gym, emotion-cause, tired}。通过类尾情感和尾巴的交叉连接能够发展推理边缘,如{tired, emotion-intent, to get some energy}。
Filtering. 基于启发式方法,作者应用SentiLARE将类 T a i l e m o t i o n Tail_{emotion} Tailemotion中的每个尾巴与数据集中定义的4个情绪标签中的一个进行匹配,即{joy, sad, angry, others}。对于标签“surprising”(这不包含在SentiLARE的标签中),使用Sentence-BERT,并设置阈值0.7,在根据SEntiLARE的标签是“others”的尾部标记“surprising”。与原始话语共享相同情感类别的尾部被保留,以构建基于情感的对话流。
Emotion Cause Flow. 然后对 T a i l b e f o r e Tail_{before} Tailbefore应用基于对话上下文的精确匹配。如果有一个关键字完全匹配一些关键字在前面的话语,创建一个emotion −cause 边从 T a i l b e f o r e Tail_{before} Tailbefore到过滤tail T a i l e m o t i o n Tail_{emotion} Tailemotion,表明 T a i l b e f o r e Tail_{before} Tailbefore的事件可能导致人感觉到 T a i l e m o t i o n Tail_{emotion} Tailemotion的情感。
图4描述了构建标记的emotion-cause边的过程。首先,将 T a i l e m o t i o n Tail_{emotion} Tailemotion中的愤怒与话语情感标签“angry”进行匹配。发现 T a i l b e f o r e Tail_{before} Tailbefore的tail insomnia出现在之前的话语中。所以建立了一个emotion_cause边缘从tail angry到tail insomnia。这种尾尾emotion_cause流支持聊天机器人通过推理其原因来更好地理解用户的情绪情绪。

Emotion Intent Flow. 对于类 T a i l a f t e r Tail_{after} Tailafter中的尾,创建了一个从尾情感到尾情感中经过过滤的尾的emotion_intent流。作者还为每个emotion_intent边分配了五个意图标签中的一个,即,{ask, advise, describe, opinion, console}(第3节)。
图5描述了构建标记的emotion-intent边的过程。首先将 T a i l e m o t i o n Tail_{emotion} Tailemotion中的尾巴Uncomfortable与话语情感标签“sad”相匹配。然后发现 T a i l a f t e r Tail_{after} Tailafter的尾巴Take medicine出现在下一个话语中。因此,作者从尾巴Uncomforable建立一个emotion_intent边到尾巴Take medicine,并在边缘添加第二个话语“ask”的意图标签。这种tail-tail emotion_intent流支持聊天机器人在一定情况下选择合适的响应策略。
Expertise Label. 考虑到每个话语中的情感和意图都是潜在的和微妙的,很难使自动提取的情绪流动结果在数量上表现良好。在这种情况下,作者还招募了2名具有丰富心理学经验的专业人员,并让他们在情绪表达的高频场景中标记情绪的原因和意图,比如失眠和学术压力。
为了方便专业知识,作者还构建了一个交互式注释工具,以便更容易地在C 3 ^3 3KG中进行注释和探索。该系统集成了修改和添加尾部等功能,这将是C3KG的一个很好的补充和清洁工具。
6. Evaluation
6.1 Matching Evaluation
Manual Assessment. 随机选择100个话语来评估事件提取(第5.2节)和匹配方法(第5.3节)。将本文提出的方法定义为P arsing。为了与此进行比较,作者使用另外两种方法来处理话语:P OS使用基于POS标记的模板来提取事件,以及Simple 在匹配前只根据标点符号对话语进行分割和过滤。以下报告了使用句子推理和句子推理微调的匹配结果。

在表3中,相似度表示平均匹配度,数字表示所选话语的匹配ATOMIC头的平均数,可以视为匹配回忆率的指标。虽然三种方法在没有微调的情况下平均相似度相似,但Parsing方法与简单和POS相比,微调后的相似性明显提高,也明显优于基于POS的方法。
Scenario Graph Visualization. 作者还基于匹配结果和场景描述建立了场景图。通过可视化每个场景主题的匹配结果,能够更好地理解匹配的质量。
具体来说,使用子句子来匹配ATOMIC-zh中的头,并使用在每个场景中匹配的前0.5%的头来构建基于场景的图。每一个都可以看作是ATOMIC-zh的采样子图,与其场景具有更高的主题一致性。注释后,基于3个注释器的匹配精度达到0.71,表明场景图的质量良好。为了描述,本文可视化了图6中的场景图“sickness”的一个片段。为清晰起见,在图6中只可视化了一小部分关系和尾部。事实上,每个场景图都包含了完整的C 3 ^3 3KG关系集。

6.2 Graph Evaluation
Node Evaluation. 因为C 3 ^3 3KG是建立在翻译后的ATOMIC-zh之上的。作者首先从翻译精度方面来评估图的质量。具体来说,从C 3 ^3 3KG中随机抽取200个三联体,并要求注释者用{0,1}分数的流畅性和逻辑正确性来标记每个中文三联体。为了验证本联合翻译方法,作者还与使用单独翻译的结果进行了比较。

如表4所示,流畅性和逻辑两方面的显著增加清楚地表明了联合平移方法的优越性。在逻辑一致性方面,我们发现许多样本案例由于头部的不完整而被标记为0的逻辑分数,这在某种程度上混淆了语义,阻碍了与尾部的逻辑连接。例如,{有人把他父亲,xAttr,告密者}({PersonX gets PersonX’s father, xAttr, a tattletale})看起来很荒谬。然而,如果在头部的结尾加上“叫来”,那么就可以想象这样一个场景,即一个孩子通过召唤父母来威胁另一个孩子。尽管如此,这些看似不合逻辑的知识可能仍然为使用模糊匹配技术的下游任务提供信息。因此,作者保留了这种不完整的头。
Edge Evaluation. C 3 ^3 3KG的核心是这项工作中开发的新颖的对话流关系。为了验证这些关系的质量和鲁棒性,作者使用了另一个开放域多回合中国对话数据集,MOD。具体来说,作者从MOD话语中提取事件mention,并使用第5.2节中所述的方法将它们与本文的图进行匹配。然后计算匹配结果的连通性和平均距离,w.r.t. next_utterance和next_sub_utterance之间的关系。其目的是评估本文知识图中相关内容的聚合程度。

表5显示了MOD的边缘评价结果。为了进行比较,作者添加了ATOMIC-zh的测试结果,并考虑到它们在大小上的相似性。比较结果表明,本文事件流的有效性,导致对话中的上下文匹配具有更高的连通性和更短的距离。
7. Proposed Tasks
为了展示其潜力,本文提出了两个基于图形的会话任务,即情绪分类和意图预测,并使用本文标记的语料库CConv训练基准模型。
Task 1: Emotion Classification 需要在对话中产生一个情绪标签的条件。按照通常的做法,作者选择BERT模型,并从匹配的头部中取样xAttr,xReact尾巴作为额外的输入。
Task 2: Intent Prediction 需要为对话预测一种适当类型的反应意图。我们选择BERT模型,并从我们匹配的头部中取样oEffect尾部。作为简单的基线,作者通过连接输入格式 U i − 2 U_{i−2} Ui−2 [SEP] U i − 1 U_{i−1} Ui−1 [SEP] U i U_{i} Ui [SEP] OReact [SEP]来引入历史和图形知识。
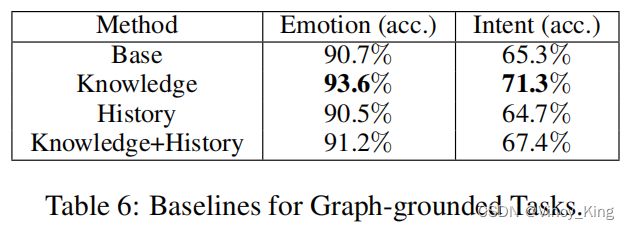
上述两个采样步骤都在处理过的子话语和匹配的头部之间使用0.7的阈值,以减少采样知识的噪声。基线方法的准确性见表6。Base表示只使用话语来进行预测。Knowledge和History表示是否在模型中添加作者采样的知识和对话历史。虽然添加知识可以提高模型的性能,但直接连接历史对话似乎存在问题,这可能会带来噪声。中等程度的分数也表明,对于基于图形的对话理解仍有改进的空间。
8. Discussions of Future Work
在这项工作中,作者提供了一个系统的方法,从事件提到检测,事件链接到对话图的构造,它由4种不同类型的对话流组成。对于每个步骤,都存在可能的改进。例如,作者计划包括其他基于事件的资源,以提高图-会话匹配的准确性以及图的知识的覆盖率。
作者还计划继续进行注释,以提供更多的对话流信息,特别是那些同情的信息,并评估其他数据集上更多的对话流关系。
Acknowledgements and Ethical Considerations
感谢匿名的审稿人提出的建设性意见。本工作经小井团队批准。本文的数据集中的所有个人身份信息都被删除了。
最后,作者讨论了这项工作的潜在伦理影响。(1) Transparency: 作者将发布新引入的语料库和构建的会话知识图,以及基准测试方法,以促进未来的研究。类似的数据集和知识库包括Empathetic-Dialogues和ATOMIC,这些对话通常是公开的,并已被广泛使用。 (2) Privacy: 该语料库是根据一套禁止工人披露的具体规定进行的敏感和个人身份信息。 (3) Politeness: 因为对话是由人写成的,并且与健康的日常生活场景有关,所以它们被期望是干净、合法和礼貌的。众包规则旨在尽可能避免情绪触发的词汇。