数学建模十大算法04—图论算法(最短路径、最小生成树、最大流问题、二分图)
文章目录
-
-
- 一、最短路径问题
-
- 1.1 两个指定顶点之间的最短路径
-
- 1.1.1 Dijkstra算法
- 1.1.2 Matlab函数
- 1.2 每对顶点之间的最短路径
-
- 1.2.1 Dijkstra算法
- 1.2.2 Floyd算法
- 1.2.3 Matlab函数
- 二、最小生成树问题
-
- 2.1 Kruskal算法
- 2.2 Prim算法
- 三、网络最大流问题
-
- 3.1 网络流问题基础
- 3.2 Ford-Fulkerson算法
- 3.3 Edmonds-Karp算法
- 3.4 Dinic's算法
- 3.5 最小割问题(Min-Cut)
-
- 3.5.1 S-T Cut
- 3.5.2 ★最大流-最小割定理(Max-Flow Min-Cut Theorem)
- 3.5.3 **寻找最小割的方法**
- 四、二分图
-
一、最短路径问题
从图中的某个顶点出发,到达另一个顶点的所经过的边的权重之和最小的一条路径。
1.1 两个指定顶点之间的最短路径
问题如下:给出了一个连接若干个城镇的铁路网络,在这个网络的两个指定城镇间,求一条最短铁路线。

1.1.1 Dijkstra算法
迪杰斯特拉(Dijkstra)算法是由荷兰计算机科学家狄克斯特拉于1959年提出的。是寻找从一个顶点到其余各顶点的最短路径算法,可用来解决最短路径问题。详细的讲解可参考:数据结构–Dijkstra算法最清楚的讲解
更正:第2、3步中,B(23)应为B(13)。
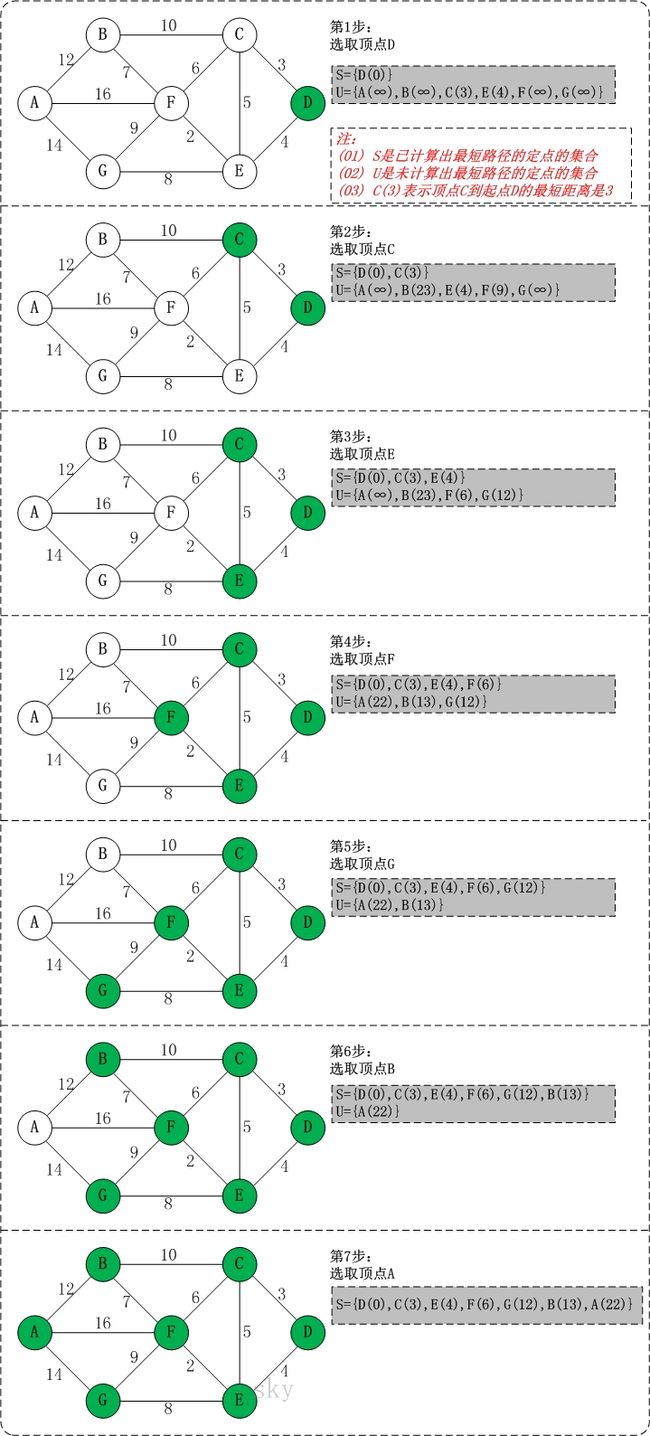
迪杰斯特拉算法采用贪心算法的策略,将所有顶点分为已标记点和未标记点两个集合,从起始点开始,不断在未标记点中寻找距离起始点路径最短的顶点,并将其标记,直到所有顶点都被标记为止。 需要注意的一点是该方法不能处理带有负权边的图,下面我们举出一个实例并通过迪杰斯特拉方法对其进行求解。
【例】 某公司在六个城市 c 1 , c 2 , c 3 , . . . , c 6 c_1,c_2,c_3,...,c_6 c1,c2,c3,...,c6 中有分公司,从 c i c_i ci 到 c j c_j cj 的直接航程票价记在下述矩阵的 ( i , j ) (i,j) (i,j) 位置上(∞表示无直接航路)。请帮助该公司设计一张城市 c 1 c_1 c1 到其他城市间的票价最便宜的路线图。

用矩阵 a n × n a_{n×n} an×n (n为顶点个数) 存放各边权的邻接矩阵,行向量 p d 、 i n d e x 1 、 i n d e x 2 、 d pd、index_1、index_2、d pd、index1、index2、d 分别用来存放 P P P 标号信息、标号顶点顺序、标号顶点索引、最短通路的值。其中分量

i n d e x 2 ( i ) index_2(i) index2(i) 存放始点到第 i i i 顶点最短通路中第 i i i 顶点的序号; d ( i ) d(i) d(i) 存放由始点到第 i i i 顶点最短通路的值。
求第一个城市到其他城市的最短路径的Matlab程序如下:
clc,clear
a=zeros(6); %邻接矩阵初始化
a(1,2)=50;a(1,4)=40;a(1,5)=25;a(1,6)=10;
a(2,3)=15;a(2,4)=20;a(2,6)=25;
a(3,4)=10;a(3,5)=20;
a(4,5)=10;a(4,6)=25;
a(5,6)=55;
a=a+a'; % 两点之间的距离是一样的→对称矩阵
a(a==0)=inf;
pb(1:length(a))=0;pb(1)=1;index1=1;index2=ones(1,length(a));
d(1:length(a))=inf;d(1)=0;
temp=1; %最新的P标号的顶点
while sum(pb)<length(a)
tb=find(pb==0);
d(tb)=min(d(tb),d(temp)+a(temp,tb));
tmpb=find(d(tb)==min(d(tb)));
temp=tb(tmpb(1)); %可能有多个点同时达到最小值,只取其中的一个
pb(temp)=1;
index1=[index1,temp];
temp2=find(d(index1)==d(temp)-a(temp,index1));
index2(temp)=index1(temp2(1));
end
d, index1, index2
运行结果为:

结果表示,最终求得的 c 1 c_1 c1 到 c 2 , . . . , c 6 c_2,...,c_6 c2,...,c6 的最便宜票价分别为35,45,35,25,10。
1.1.2 Matlab函数
【例】 在下图中,用点表示城市,现有 v 1 , v 2 , . . . , v 5 v_1,v_2,...,v_5 v1,v2,...,v5 共5个城市。点与点之间的连线表示城市间有道路相连。连线旁的数字表示道路的长度。现计划从城市 v 1 v_1 v1 到城市 v 3 v_3 v3 铺设一条天然气管道,请设计出最小长度管道铺设方案。
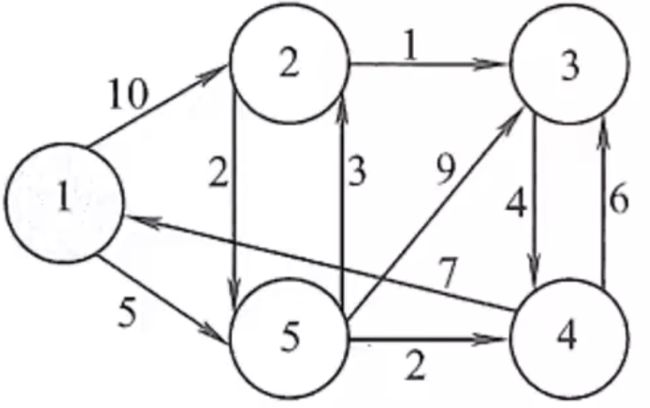
除了上面提到的迪杰斯特拉求两点之间最短路径外,我们还可以使用MATLAB自带的graphshortestpath函数。
W = [10,5,1,2,4,7,6,3,9,2];
% sparse生成稀疏矩阵,除了标注的元素外,其余都是0
DG = sparse([1,1,2,2,3,4,4,5,5,5],... % sparse第一个矩阵,三个.代表没写完,下一行接着
[2,5,3,5,4,1,3,2,3,4],W) % sparse第二个矩阵
% sparse里第一个和第二个矩阵相同位置的元素值就是非零元素的值,W是每条边的权值
% dist是最短路径的值,path是最短路径的节点顺序,pred是每一个节点的最短路径的终点前一个节点
[dist,path,pred] = graphshortestpath(DG,1,3) % 节点1到3的最短路径
point_name = ["city1","city2","city3","city4","city5"];
p = biograph(DG,point_name,'ShowWeights','on')
h = view(p) % biograph生成图对象,view显示该图
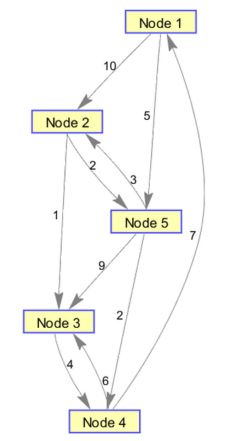
我们可以查看一下sparse生成的稀疏矩阵DG:

从矩阵的角度看:

用view显示此时生成的图对象:
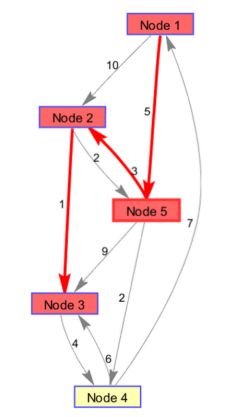
然后,我们将通过该函数计算得到的最短路径节点以红色显示:
% 将最短路径的结点以红色显示
set(h.Nodes(path),'Color',[1 0.4 0.4]);
% 将最短路径的弧以红色显示
edges = getedgesbynodeid(h,get(h.Nodes(path),'ID')); % getedgesbynodeid得到图h指定便的句柄,第一个参数是图,第二个是边的出点,第三个是边的入点
% get查询图的属性 set用来设置图形属性
set(edges,'LineColor',[1 0 0]); % RGB数值
set(edges,'LineWidth',2.0);
注意:这里的ID是Matlab自带的。

1.2 每对顶点之间的最短路径
1.2.1 Dijkstra算法
计算赋权图中各对顶点之间最短路径,显然可以调用Dijkstra算法。具体方法是:每
次以不同的顶点作为起点,用Dijkstra算法求出从该起点到其余顶点的最短路径, 反复执行n-1次这样的操作,就可得到从每一个顶点到其他顶点的最短路径。这种算法的时间复杂度 O ( n 3 ) O(n^3) O(n3) 为。
1.2.2 Floyd算法
第二种解决这一问题的方法是由R. W. Floyd提出的算法,称为Floyd算法。其时间复杂度也是 O ( n 3 ) O(n^3) O(n3) ,但形式上要简单些。
对于赋权图 G = ( V , E , A 0 ) G=(V,E,A_0) G=(V,E,A0) ,其中,顶点集 V V V = { v 1 , . . . , v n v_1,...,v_n v1,...,vn},邻接矩阵
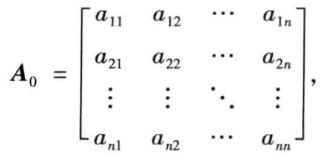
其中,
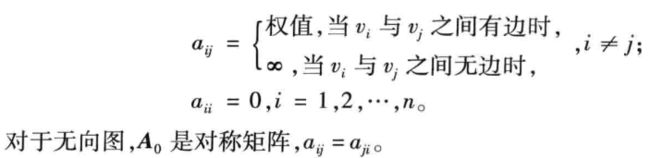
Floyd算法的基本思想是递推产生一个矩阵序列 A 1 , . . . A k , . . . A n A_1,...A_k,...A_n A1,...Ak,...An, 其中矩阵A的第 i i i 行第 j j j 列元素 A k ( i , j ) A_k(i,j) Ak(i,j) 表示从顶点 v i v_i vi 到顶点 v j v_j vj 的路径上所经过的顶点序号不大于 k k k 的最短路径长度。
计算时利用迭代公式:

举一个简单的例子帮助大家理解:
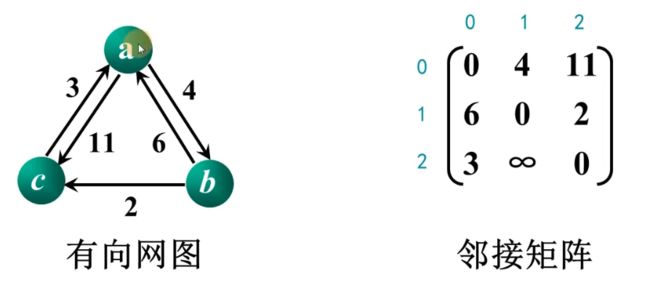
对上述信息初始化:
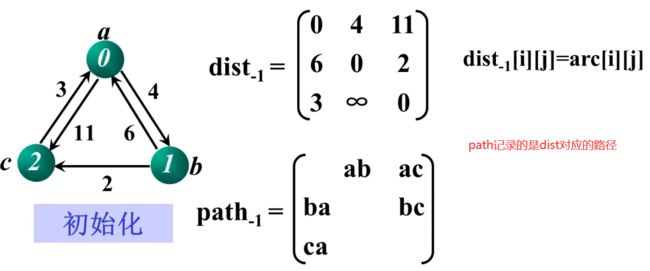
第一次迭代时,以 a 为起点判断矩阵是否需要更新:
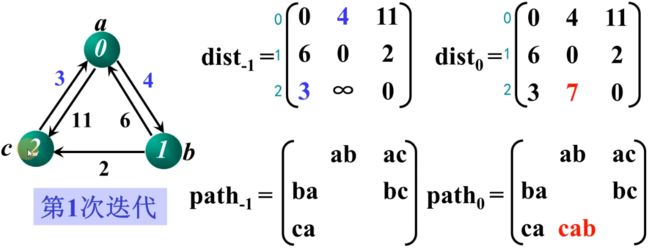
第二次迭代,加入顶点 b,即k=1时判断矩阵是否需要更新:
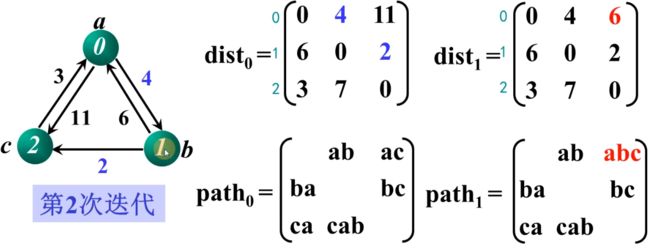
第三次迭代,加入顶点 c,即k=2时判断矩阵是否需要更新:
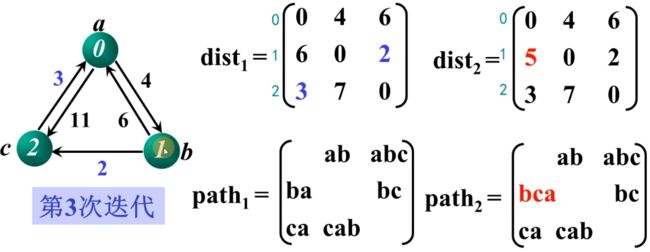
上述案例来自B站:数据结构
【例】用Floyd算法求解和之前同样的问题。
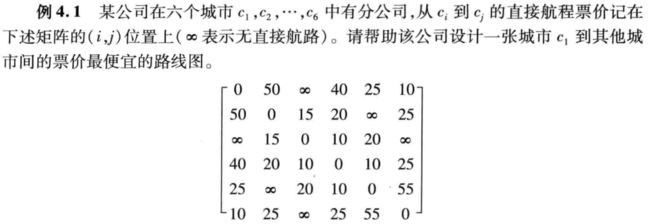
Matlab代码如下:
clear;clc;
n=6; a=zeros(n);
a(1,2)=50;a(1,4)=40;a(1,5)=25;a(1,6)=10;
a(2,3)=15;a(2,4)=20;a(2,6)=25; a(3,4)=10;a(3,5)=20;
a(4,5)=10;a(4,6)=25; a(5,6)=55;
a=a+a';
a(a==0)=inf; % 把所有零元素替换成无穷
a([1:n+1:n^2])=0; % 对角线元素替换成零,Matlab中数据是逐列存储的★
path=zeros(n);
for k=1:n
for i=1:n
for j=1:n
if a(i,j)>a(i,k)+a(k,j)
a(i,j)=a(i,k)+a(k,j);
path(i,j)=k;
end
end
end
end
a, path
求出来的结果为:

矩阵 a a a 的第一行求得 c 1 c_1 c1 到 c 2 , . . . , c 6 c_2,...,c_6 c2,...,c6 的最便宜票价分别为35,45,35,25,10。
1.2.3 Matlab函数
利用graphallshortestpaths函数,可以求出所有结点之间的最短路径。
Dists = graphallshortestpaths(DG) %求所有最短路径
以1.1.2中的为例,我们可以看到求得的矩阵中城市 v 1 v_1 v1 到城市 v 3 v_3 v3 的最小路径为9。

二、最小生成树问题
欲修筑连接 n 个城市的铁路,已知 i i i 城与 j j j 城之间的铁路造价为 c i j c_{ij} cij 设计一个线路图,使总造价最低。上述问题的数学模型是在连通赋权图上求权最小的生成树。赋权图的具有最小权的生成树叫做最小生成树。 下面介绍构造最小生成树的两种常用算法。
2.1 Kruskal算法
1、把图 G G G 中的所有边全部去掉,得到所有单独的顶点 V V V 构成图 T = ( V , T=(V, T=(V, { } ) ) ),其中 V V V 是顶点集合;
2、从 G G G 中取出当前权值最小的边,如果该边加入 T T T 的边的集合后 T T T 不形成回路,则加入 T T T ;否则舍弃;
3、重复第2步,直到 T T T 中有 n − 1 n-1 n−1 条边 ( n n n 是顶点数);
4、若第2步中遇到两条权值相同的最小权值边,任选一条即可,所以最小生成树可能不唯一,但权值之和相同。
Kruskal简单理解就是每次都选一条权值最小的边。适合边少点多的图。

用Kruskal算法求解上图的Matlab代码为:
clc;clear;
% 输入邻接矩阵
a(1,2)=50; a(1,3)=60; a(2,4)=65; a(2,5)=40;
a(3,4)=52;a(3,7)=45; a(4,5)=50; a(4,6)=30;
a(4,7)=42; a(5,6)=70;
[i,j,b]=find(a);
[i,j,b]=find(a)这一步的含义是求出有权值边的索引。

构建弧表表示矩阵data,及所有边的索引矩阵index:
data=[i';j';b']
index=data(1:2,:)


loop=max(size(a))-1;
result=[];
while length(result)<loop
temp=min(data(3,:)); % 30
flag=find(data(3,:)==temp); % 7-->在第七个位置上
flag=flag(1);
v1=data(1,flag); % 第7个位置上对应的第一行数据为4
v2=data(2,flag); % 第7个位置上对应的第二行数据为6
if index(1,flag)~=index(2,flag)
result=[result,data(:,flag)]; % 4 6 30
end
index(find(index==v2))=v1; % 把index里面的6全部改成4
data(:,flag)=[]; % 删除第七个位置的三个值 4 6 30
index(:,flag)=[]; % 删除第七个位置的索引
end
result
求得的结果为:

在图上标注出最小生成树如下:
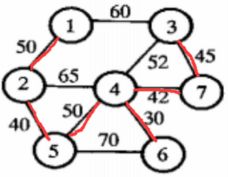
2.2 Prim算法
1、设置一个图 U U U ,将原图 G G G 中任意一顶点取出加入 U U U 中;
2、在所有 u ∈ U u∈U u∈U, v ∈ ( V − U ) v∈(V-U) v∈(V−U) 的边 ( u , v ) (u,v) (u,v) 中找到一条权值最小的边,并入图 U U U 中;
3、重复步骤2,直到 U U U 中包含了所有顶点;
4、若第2步中遇到两条权值相同的最小权值边,任选一条即可,所以最小生成树可能不唯一,但权值之和相同。
Prim算法简单理解就是选顶点。适合边多点少的图。
使用Prim算法求解的Matlab代码如下:
a=zeros(7);
a(1,2)=50;
a(1,3)=60;
a(2,4)=65;
a(2,5)=40;
a(3,4)=52;
a(3,7)=45;
a(4,5)=50;
a(4,6)=30;
a(4,7)=42;
a(5,6)=70;
a=a+a';
a(find(a==0))=inf;
初始化之后的矩阵 a a a 为:

result=[] % 存储最小生成树
p=1; % 选取顶点1
tb=2:length(a) % 剩余顶点
while length(result)~=length(a)-1 % 当边的个数=n-1时,退出循环
temp=a(p,tb); % tb中存储着其他未处理的顶点,temp存储着未处理的边的权重
temp=temp(:);
d=min(temp);
[jb,kb]=find(a(p,tb)==d); % 找到最小权的横纵坐标
j=p(jb(1)); % j存储找到的边的起始位置,可能有多最小权,但我们只取一个
k=tb(kb(1)); % k存储找到的边的末位置,可能有多最小权,但我们只取一个
result=[result,[j;k;d]]; % 存储找到的此条边的信息
p=[p,k]; % 包含新加入的顶点
tb(find(tb==k))=[]; % 在tb中删除与刚加入的边相连接的点
end
result
最终得到的结果为:

求得的最小生成树在图上标注为:
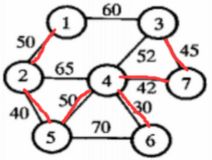
我们可以看到,当边的权值无重复值时,用Kruskal和Prim求得的最小生成树是一致的。
三、网络最大流问题
网络流优化问题一般是指在有向图中分配流量,使每条边的流量不会超过它的容量约束(Capacity),同时达到路径长度最小或者花费最小等目标函数的优化问题。因为在运筹学中,我们经常把有向图称为网络。所以这类基于有向图流量分配的优化问题也被称之为网络流优化问题。网络流优化属于组合优化问题的一种。
3.1 网络流问题基础
本小节内容参考B站(强推!!!):13-1: 网络流问题基础 Network Flow Problems
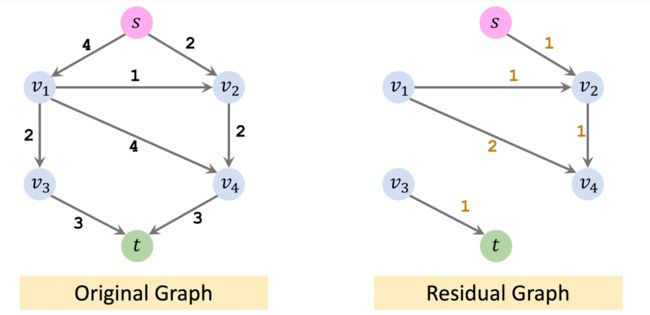
左图边的权重表示水管的容量,允许多少水流入。右图边的权重表示水管的空闲量,初始值是相同的,刚开始时没有水流入水管。算法在执行时,我们会用到右边的图。
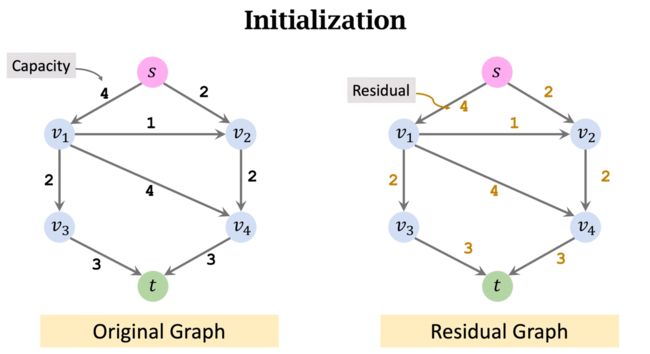
第一次迭代: 选取一条从起点 s s s 到 t t t 的简单路径(不能有回路)。假设找到了一条路径,用红色标注为:
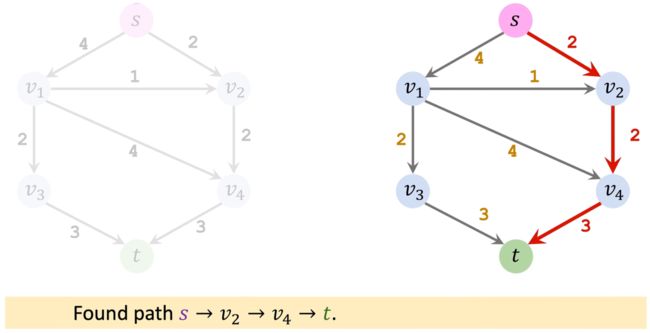
路径上的权重为3、3、2,由于短板效应,这条路径上只能通过流量为2的水。我们让容量为2的水通过该条路径,那么就要更新Residual的值。
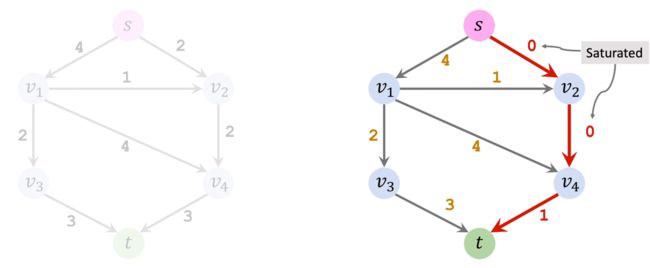
注意上面有两条管道Residual值为0,已经饱和,代表它们不能输送更多的水流了,在图中我们将这两条管道删除。
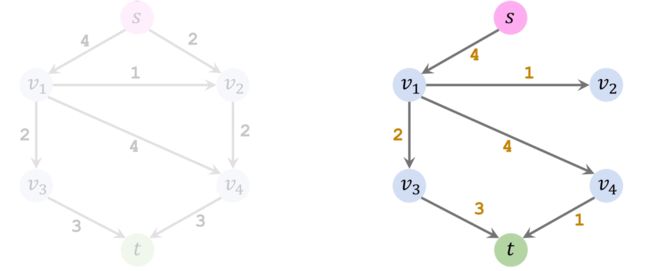
以上就是第一轮循环。
第二轮迭代: 仍然是找到一条从起点 s s s 到 t t t 的简单路径。
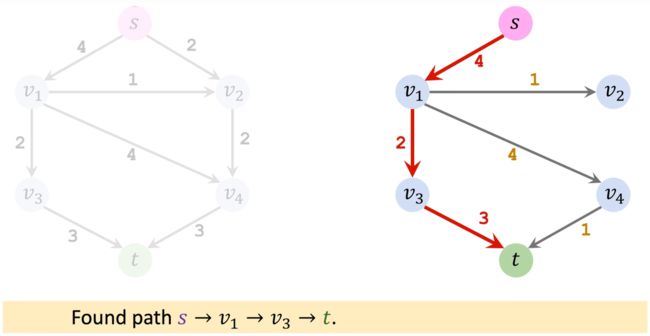
同样地,更新Residual的值。
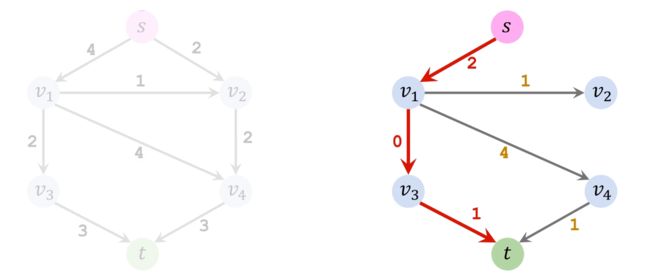
删除饱和的边:
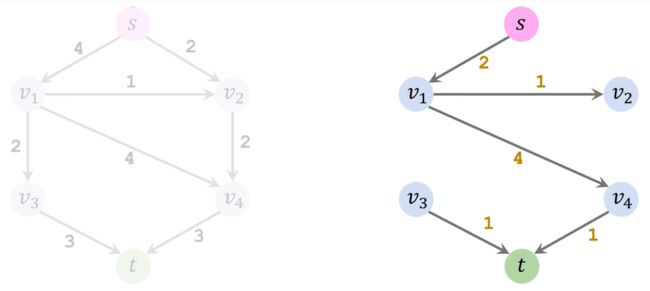
第三轮迭代: 找到一条从起点 s s s 到 t t t 的简单路径。
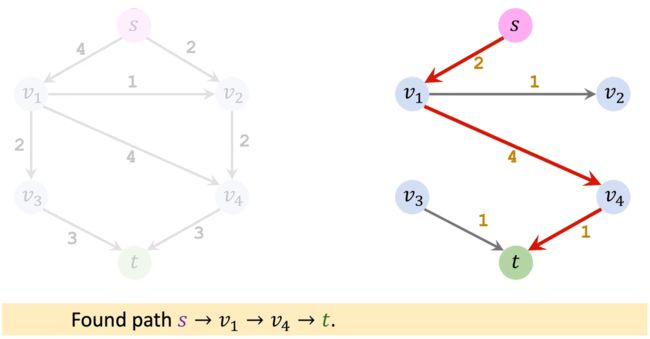
更新Residual的值。
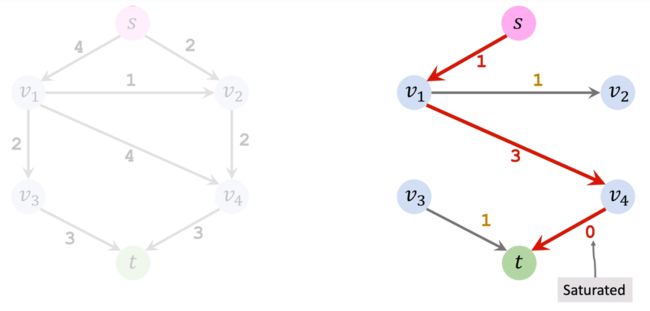
在图上删除已经饱和的边:
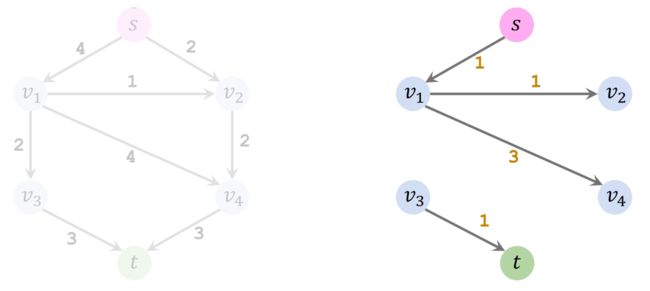
第四轮迭代: 仍然试图找到一条从起点 s s s 到 t t t 的简单路径。但是此时不存在这样的路径,算法终止。
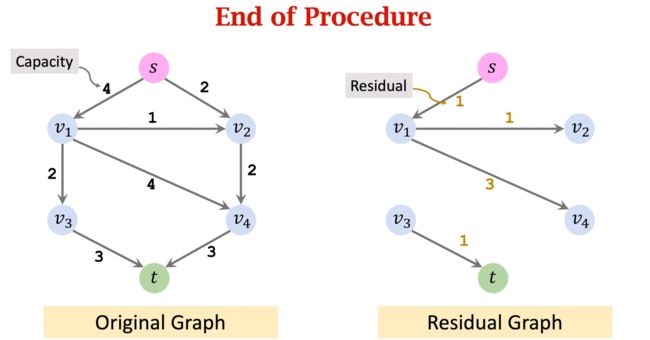
根据 F l o w = C a p a c i t y − R e s i d u a l Flow = Capacity - Residual Flow=Capacity−Residual 计算可得 f l o w flow flow(图中红色标注)。

那么,我们可以得到总流量为5。两个角度可以计算总流量:有两份水从起点流出,流量分别为3和2。此外,有两份水流入终点,流量分别为2和3。
以上是一种简单的找网络流的算法,但是该算法不能保证最优性(结果不一定是最大流),举一个简单的例子。
假设第一轮循环找的路径为: S − v 1 − v 4 − t S-v_1-v_4-t S−v1−v4−t,更新Residual的值。

第二轮找到的路径为: S − v 1 − v 3 − t S-v_1-v_3-t S−v1−v3−t,更新Residual的值。

第三轮循环,找不到一条能从起点到重点的路径,算法结束。但是此时 f l o w = 4 flow=4 flow=4 并不是网络的最大流。
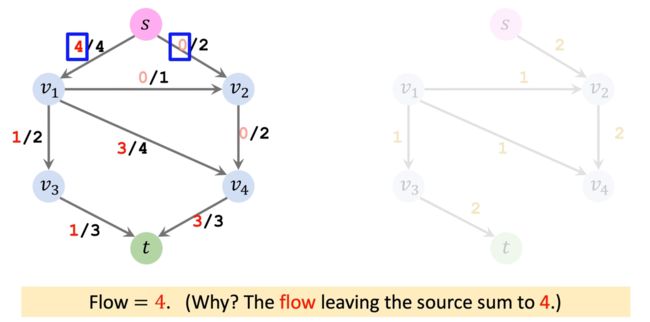
f l o w = 4 flow=4 flow=4 称为 B l o c k i n g Blocking Blocking F l o w Flow Flow,它虽然不是最大流,但是它将管道堵住了不能让更多的水流通过,所以称为阻塞流。显而易见,最大流也是一种阻塞流。
我们可以看到,寻找路径的先后顺序变了之后,就有可能找不到最大流。所以,之后我们需要学习一些优化算法。
3.2 Ford-Fulkerson算法
3.1小节中的简单算法有个缺陷:一旦找到一条不是最大流的路径,就不能更正。这节课所学的算法,可以反悔,将不好的路径撤销。该节内容依旧是参考:13-2: Ford-Fulkerson Algorithm 寻找网络最大流
该算法比之前讲的简单算法多了一步:增加反向路径。

仍然是之前那个例子。第一次循环 找到路径 S − v 1 − v 4 − t S-v_1-v_4-t S−v1−v4−t (允许让容量为3 的水通过),更新Residual的值。

然后,增加一个反向路径,允许让容量为3的水原路流回去,这样的话,选择的路径不是最好的,我们就可以选择撤销。
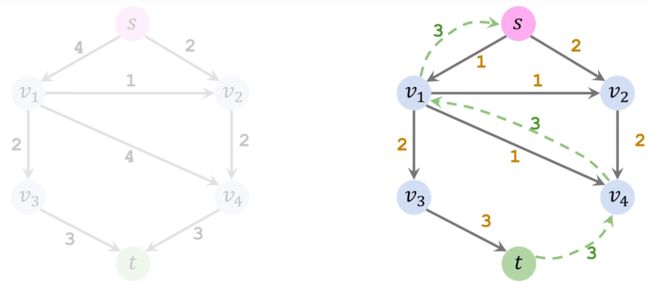
第二轮循环,找到路径 S − v 1 − v 3 − t S-v_1-v_3-t S−v1−v3−t ,并添加反向路径:

合并方向相同的路径:
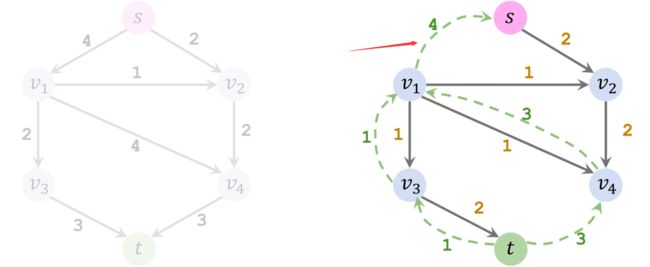
第三轮循环,假如没有反向路径的化,算法就会终止。但是添加了反向路径之后,有下面这样的结果:
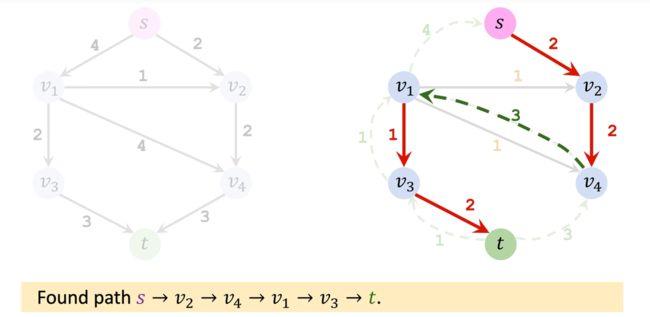
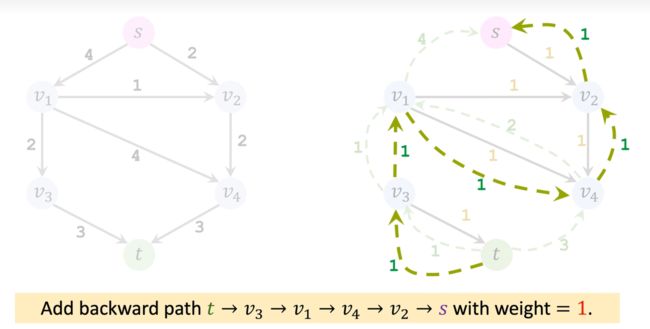
合并方向相同边的权重:
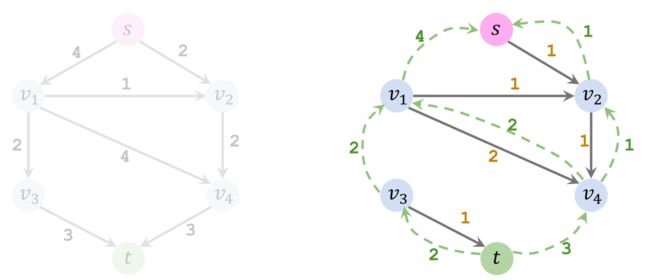
第四轮循环,没有任何水流能流入 v 3 v_3 v3 和 t t t。找不到路径,算法终止。
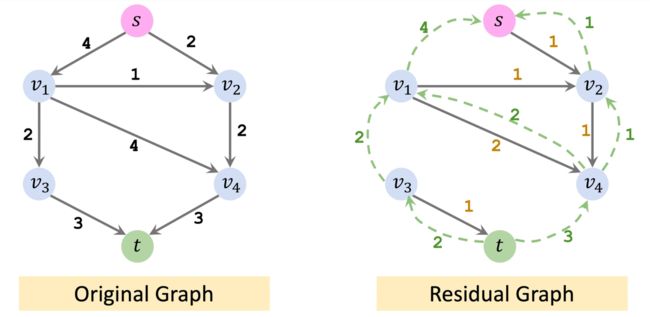
算法结束后,不再需要反向流,将其去除。
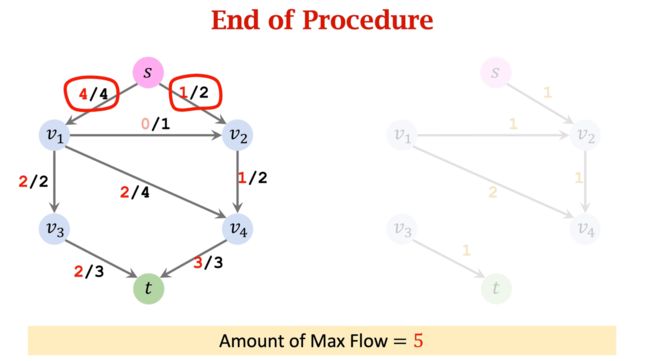
最坏情况下的时间复杂度:

如果每次找的都是100→1→100这样的路径,那么要200次才能找到最大流。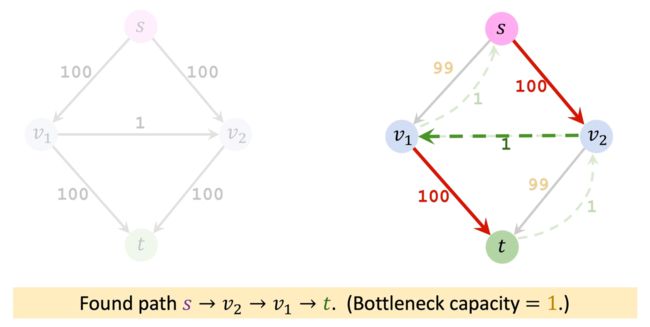


更多细节可参考:最大流问题与Ford-Fulkerson算法介绍
3.3 Edmonds-Karp算法
Edmonds-Karp算法与Ford-Fulkerson算法唯一的区别就在于,前者在寻找路径时使用最短路径算法(将Residual图所有边的权重都视为1,找到步长最短的那一条路径)。而后者允许使用任意方法寻找路径,因此可以将Edmonds-Karp算法看作是后者的一种特殊情况。

这个算法的贡献在于提升了时间复杂度,不依赖于网络流的大小,之和边和结点有关。
Edmonds-Karp算法时间复杂度分析:
- 记 m m m 为图中边的数量, n n n 为图中顶点的数量,每一轮循环都是要找到一条最短路径,所以每一轮循环的时间复杂度为 O ( m ) O(m) O(m)。
- 原图中有 m m m 条边,那么最多会有 m m m 条反向边,所以Residual graph最多含有 2 m 2m 2m 条边。
- 算法证明最多循环 m × n m×n m×n 轮。(证明过程略复杂,省略)
- 每一轮需要 O ( m ) O(m) O(m),最多循环 m × n m×n m×n 轮,所以最坏时间复杂度为 O ( m 2 ⋅ n ) O(m^2·n) O(m2⋅n)。
- 这个时间复杂度与最大流大小无关,实际应用中即使最大流很大,也不会有影响,因此该算法要优于Ford-Fulkerson算法。
3.4 Dinic’s算法
该算法引入了一个新的概念:Level Graph。下面简单演示一下如何构建Level Graph。
从起点 s s s 开始,将一步能到达的节点 v 1 v_1 v1 和 v 2 v_2 v2 记作第一层节点,并保留其权重边。
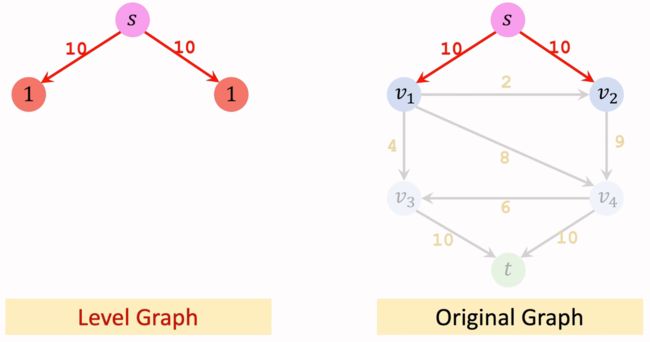
再从第一层的节点 v 1 v_1 v1 和 v 2 v_2 v2 出发,走一步能到达的节点有 v 3 v_3 v3 和 v 4 v_4 v4 ,将这两个节点加入到Level Graph中的第二层节点,并保留权值边。

再从第二层的节点 v 3 v_3 v3 和 v 4 v_4 v4 出发,走一步能到达终点 t t t。将终点 t t t 当作第三层节点。
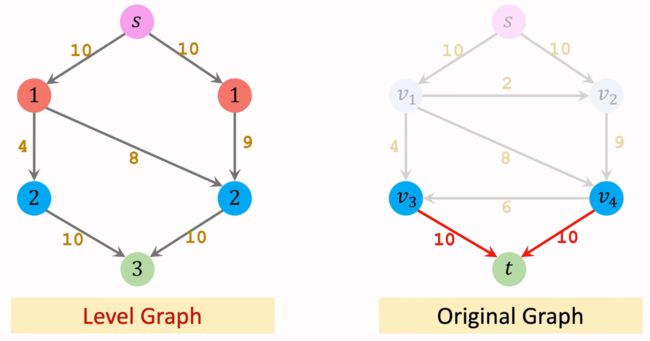
Level Graph中只允许从上一层节点到下一层节点边的存在,不允许其他边(同层之间或从下层到上层)的存在。
一个更复杂的例子,大家可以先自行画出Level Graph,看看是否与左边的结果一致:
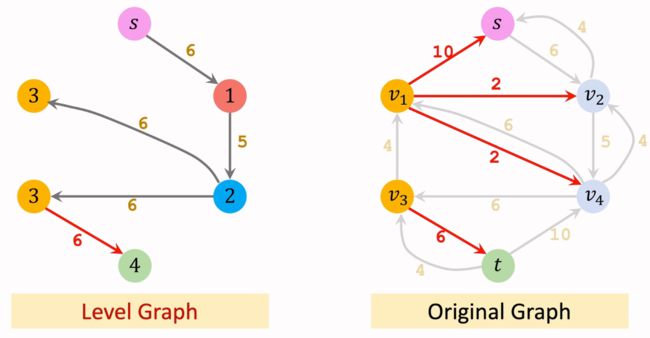
下面正式以一个简单的例子来讲解Dinic’s算法。
初始化:
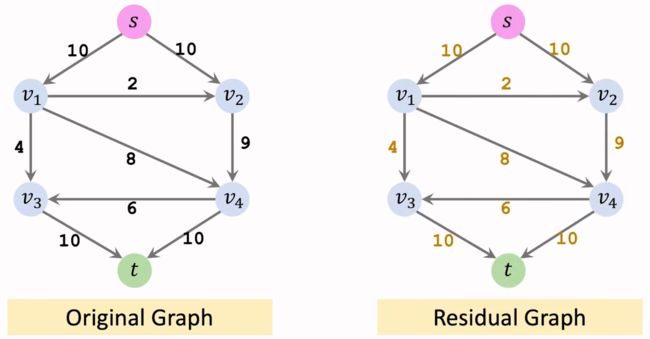
第一轮循环: 把Residual Graph作为输入,构建其Level Graph。
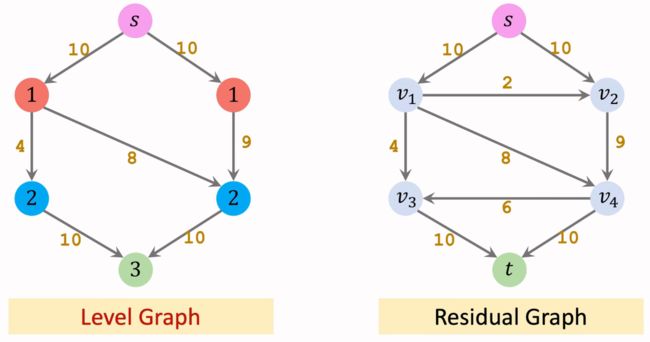
然后在左边构造好的Level Graph中寻找阻塞流(blocking flow)。 (注意:阻塞流未必是最大流),下图中用红色标识阻塞流。
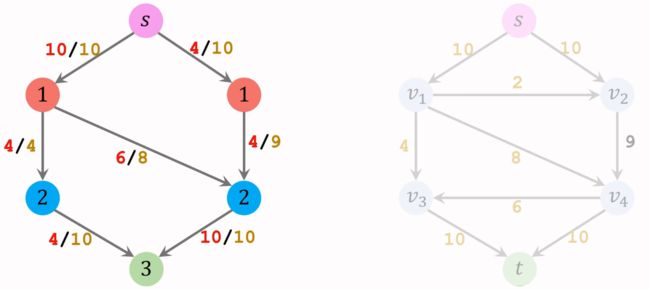
让阻塞流通过Residual Graph,那么就要相应更新Residual Graph的值。
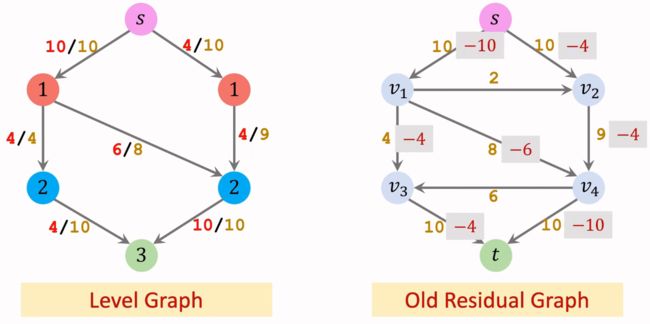
然后增加反向流。删除此轮构造的Level Graph。

第二轮循环: Residual Graph沿用第一轮更新后的样子。构造其Level Graph。
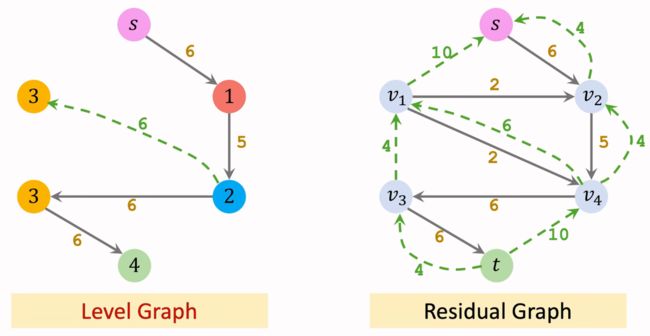
找到该Level Graph中的阻塞流,并更新Residual Graph。
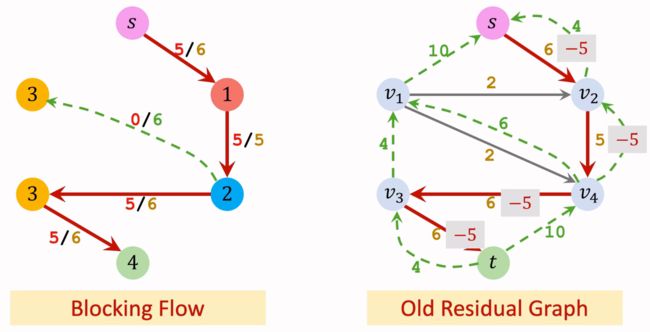
然后增加反向流(注意有相同方向的边需要合并权重值)。删除此轮构造的Level Graph。
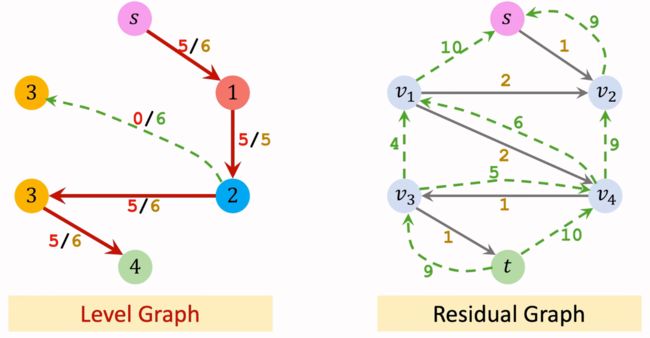
第三轮循环: Residual Graph沿用第二轮更新后的样子。构造其Level Graph。注意这里与之前不同的是,该轮中从起点走一步只能到达一个节点,并且后续无法到达其他节点,所以将其他节点设为∞。
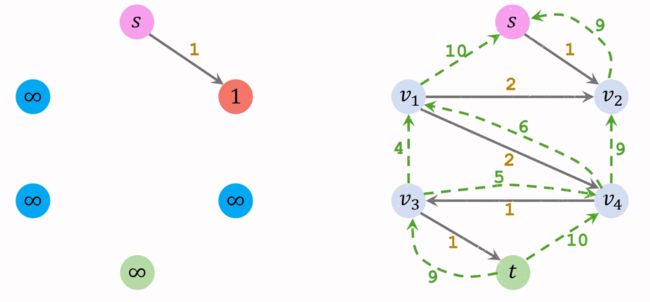
此时,我们就要终止程序,并将最后得到的Residual Graph中反向边删去。
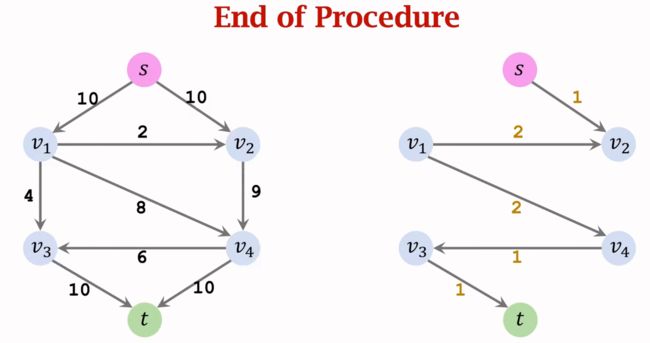
仍然用 F l o w = C a p a c i t y − R e s i d u a l Flow=Capacity-Residual Flow=Capacity−Residual 计算流量,最终算出最大流为19。
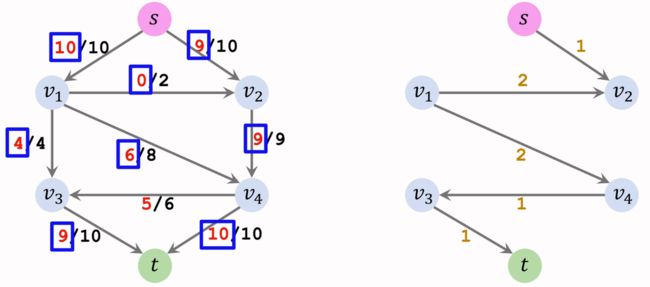
时间复杂度:

3.5 最小割问题(Min-Cut)
3.5.1 S-T Cut
将顶点集合 V V V 切割为两个集合 S S S 和 T T T 之后, S ∪ T = V S∪T=V S∪T=V 且 S ∩ T = Ø S∩T=Ø S∩T=Ø,其中起点 s ∈ S s∈S s∈S,终点 t ∈ T t∈T t∈T。那么 ( S , T ) (S,T) (S,T)称为 S-T Cut。
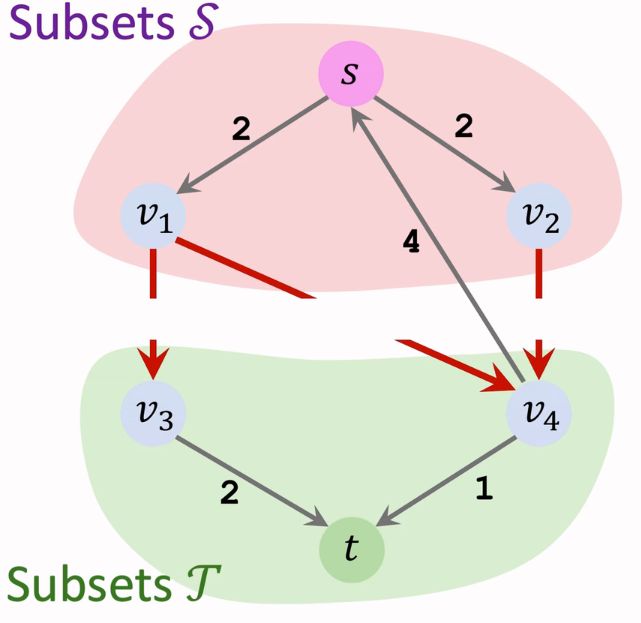
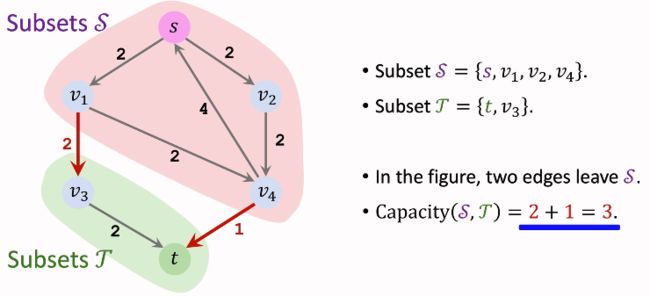
S-T Cut 容量(Capacity) 的定义为离开集合 S S S 的边的权重之和。上图中 C a p a c i t y ( S , T ) = 6 Capacity(S,T)=6 Capacity(S,T)=6。S-T Cut 并不唯一,下图中容量为3。
Min-cut简单来说,就是所有S-T Cut中容量最小的。意味着我们想要割断少数的细的管道就能阻断水流(花的代价小)。
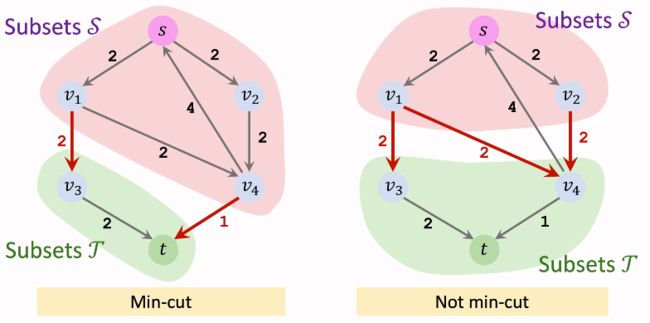
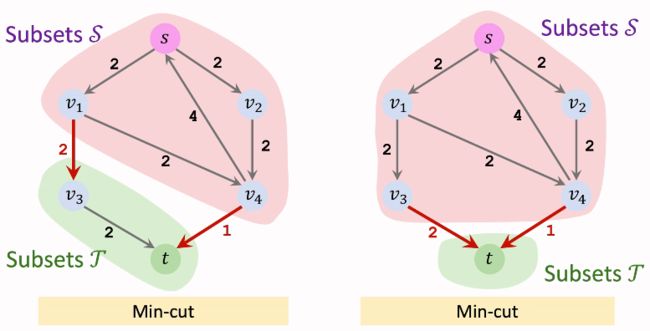
最小割可能并不唯一。
3.5.2 ★最大流-最小割定理(Max-Flow Min-Cut Theorem)
网络的最大流等于最小割容量。
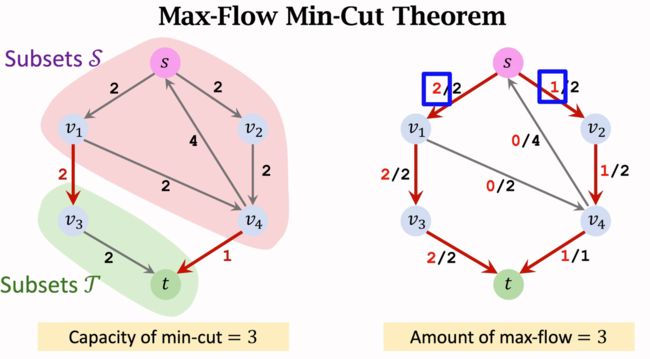
3.5.3 寻找最小割的方法
只要找到最小割就可以找到最大流。
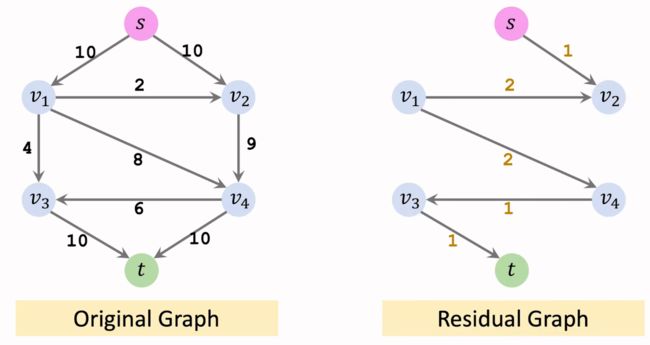
1、首先用任意的最大流算法得到最终的Residual graph,并忽略其中的反向边。
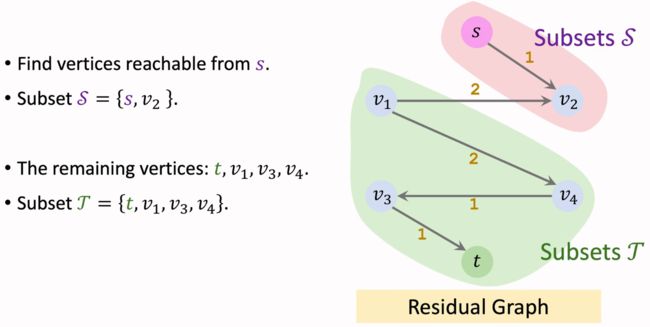
2、在Residual graph中,将从起点 s s s 一步能到达的节点归入集合 S S S。将无法到达的节点归入集合 T T T。这样,我们就得到了最小割 ( S , T ) (S,T) (S,T)。
举一个简单的例子,首先用最大流算法得到Residual graph。
然后从Residual graph中得到最小割。
上述内容来自B站:13-5: 最小割 Min-Cut
四、二分图
挖坑------------------------------未完待续-----------------------------------