算法模型评测方式
以下内容来自:AI算法评测实践与探索-王超 MTSC2021
目录
模型评估在开发中的位置
模型评估方式
人工标注
模型效果评测
模型结果DIff
自动化评测流程
模型评估在开发中的位置
整个项目开发生命周期中,模型测试主要处于线下保障部分,贯穿研发和测试阶段。

模型评估方式
模型评估方式主要有3种:
- 人工标注 Manually Annotated
- 模型效果评估 Model Performance Evaluation
- 模型效果Diff Model Result Diff
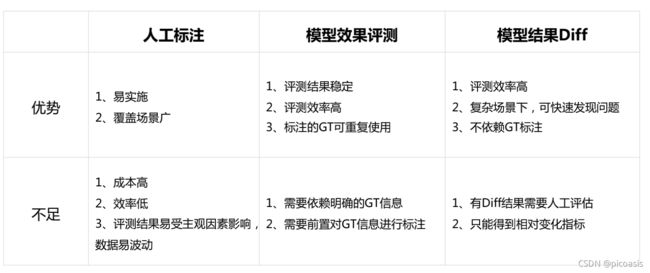
其中模型效果评测方法主要针对传统机器学习(需要人工进行特征提取,分类器选择步骤)
模型结果diff方法主要针对深度学习(不需要人工提取特征,而是依靠机器训练自动提取)。
下面是对三种方法的简单介绍。
人工标注
训练集和测试集都是标注过的数据。
数据标注简单来说就是对图像、文本、语音、视频等数据执行拉框、描点、转写等操作,以满足相关机器学习的需要。
数据标注主要类型如下:
分类标注:分类标注,就是我们常见的打标签。一般是从既定的标签中选择数据对应的标签,是封闭集合。如下图,一张图就可以有很多分类 / 标签:成人、女、黄种人、长发等。对于文字,可以标注主语、谓语、宾语,名词动词等。
适用:文本、图像、语音、视频
应用:脸龄识别,情绪识别,性别识别
2. 标框标注:机器视觉中的标框标注,很容易理解,就是框选要检测的对象。如人脸识别,首先要先把人脸的位置确定下来。行人识别。
适用:图像
应用:人脸识别,物品识别
3. 区域标注:相比于标框标注,区域标注要求更加精确。边缘可以是柔性的。如自动驾驶中的道路识别。
应用:自动驾驶
4. 描点标注:一些对于特征要求细致的应用中常常需要描点标注。人脸识别、骨骼识别等。
应用:人脸识别、骨骼识别
5. 其他标注:标注的类型除了上面几种常见,还有很多个性化的。根据不同的需求则需要不同的标注。如自动摘要,就需要标注文章的主要观点,这时候的标注严格上就不属于上面的任何一种了。(或则你把它归为分类也是可以的,只是标注主要观点就没有这么客观的标准,如果是标注苹果估计大多数人标注的结果都差不多。)
模型效果评测
通常,我们可以实现测试来对学习器的泛化误差进行评估并进而做出选择。
为此,需要使用一个“测试集”来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”作为泛化误差的近似。
通常我们假设测试样本也是从样本真实分布中独立同分布采样而得。
需要注意:测试集应该尽可能与训练集互斥,以防止过拟合现象。

主要流程是:首先基于业务场景进行数据集/测试集构建(重点1),接下来调用模型处理数据集。算法调用后,对模型执行结果进行评测,对于结果中出现的badcase进行聚类分析(重点2),对模型进行优化;无法通过模型解决的badcase,与产品经理沟通在badcase处做用户提示说明及操作引导。
模型结果DIff
diff方法直接对数据集操作,不依赖GT标注,但Diff结果需要人工评估。
Diff方法,是针对同一批数据,对比新旧版本模型的处理结果,通过分析两者结果的不同之处,来评估模型。
模型的新旧版本通常是指:正在使用的在线模型,以及新开发的离线模型。
根据调用模型的数据获取方式不同,模型结果diff有3种方法:
1. 基于数据闭环结果,进行数据Diff
2. 基于数据中心,通过数据埋点获取数据,进行数据diff
3. 基于流量调度策略,使用流量回放,进行数据Diff
下面是详细说明。
1. 基于数据闭环结果,进行数据Diff
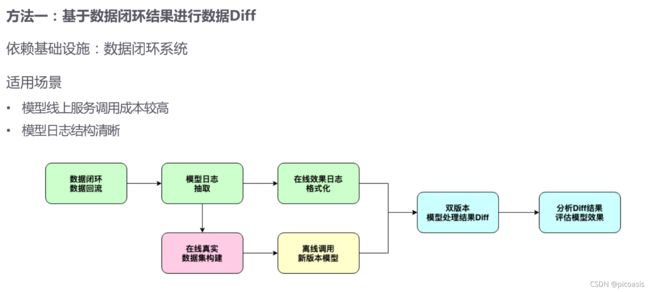
其中数据闭环系统是指:
在数据埋点时,使用模型日志上报消息队列,日志重点信息提取入库,不断积累数据。
2. 基于数据中心,通过数据埋点获取数据,进行数据diff
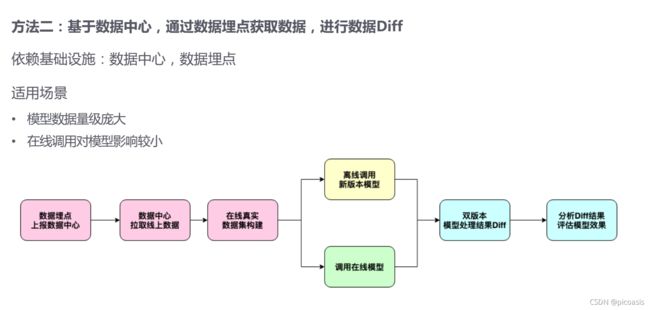
数据埋点我们可以分成:页面统计、行为统计、用户属性统计等。
页面统计可以帮我们知晓某个页面被多少人访问了多少次。
行为统计是指用户在界面上的操作行为,应用最为广泛的便是按钮的点击次数。
用户属性埋点,主要是记录用户相关的信息。
埋点是用户数据采集与分析的步骤,目的应该是分析行为和跟踪变化。
C端做埋点主要还是关注用户的行为路径,不断优化找出问题,提高留存,转化;B端的埋点关注功能使用情况,判断某个功能在某个时间段的使用场景,使用次数逐渐下降的就可以考虑考虑给他干掉了。
3. 基于流量调度策略,使用流量回放,进行数据Diff

流量录制:在不影响用户正常使用的前提下,获取线上用户的真实请求和服务响应结果,将其保存或者转发到目标应用。
因为涉及线上用户的真实数据,要注意数据脱敏、安全性等问题。
自动化评测流程
基于上述模型评测步骤,总结出了下面的自动化评测范式。
自动化主要体现在两个方面:
1 建立标注系统,提高标注效率。使用深度学习训练系统进行模型预标注,人工只需要在此基础上进行微调,而不用全部人工标注。
标注系统 是一种辅助型的产品;按照一定的标注标准,由人工完成标注对象的标注,为业务系统、模型系统、数据系统等提供支持服务。
除人工标注数据外,还可借助一些开源标注工具进行标注。


2. 建立数据闭环系统,感知badcase后自动定位位置,再转给人工分析,无需实时监控;并且通过埋点,模型日志等循环积累数据,有利于模型训练优化。
下图是自动评测的主要流程。

这里重点介绍STEP1数据预处理阶段的操作
此阶段主要进行,业务场景分析,数据收集、筛选及数据集构建,评测指标的选取,标注规则的确定,对数据集进行数据标注,最终输出符合不同模块格式要求的数据集及Ground Truth。
STEP1-1 首先基于业务场景进行分析。
主要工作是:
1. 分析用户行为分布,确定高频场景与边界场景
2. 基于业务场景设计测试用例脑图
STEP1-2: 接下来是测试集数据的收集。
从QA角度拉齐PM同学,补充用例场景维度,对用例 维度划分优先级P0, P1, P2:
• P0: 业务核心Case,用户高频出现Case
• P1: 非业务核心&用户中频出现边界Case
• P2: 可容忍的边界Case

STEP1-3: 选取评测指标。
下面分别是基于模型的指标选取,和基于业务场景的指标选取。

基于业务场景的指标选取,有利于与业务方沟通需求。
STEP1-4 标注。
之后标注团队制定标注标准对数据进行预标注,获得GroundTruth及Tag,即模型model期望的结果result。

STEP1-5 清洗数据集