python数据分析与展示 嵩天_【学习笔记】PYTHON数据分析与展示(北理工 嵩天)
0 数据分析之前奏
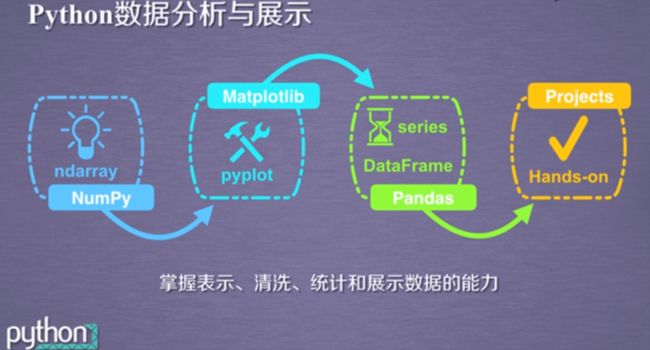
课程主要内容:
 常用IDE:
常用IDE:
 本课程主要使用:AnacondaAnaconda:一个集合,包括conda、某版本Python、一批第三方库等
本课程主要使用:AnacondaAnaconda:一个集合,包括conda、某版本Python、一批第三方库等
-支持近800个第三方库
-适合科学计算领域
-包含多个主流工具
-开源免费
-跨平台
本身不是个ide 是将多个工具集成在一起的
conda
-一个工具,用于包管理和环境管理
-包管理与pip类似,管理Python第三方库
-环境管理能够允许用户使用不同版本的Python,并能灵活切换
conda将工具、第三方库、Python版本、conda都当作包,同等对待
conda有命令行工具
C:\Users\king\Anaconda3\Scripts\conda.exe –version 可以查看conda版本
conda update conda 升级conda
刚开始的是命令行,现在也集成为GUI,anaconda默认生成root的环境空间
 编程工具:spyder
编程工具:spyder
 默认不舒服 改下
默认不舒服 改下
交互式编程环境:IPython
-是一个功能强大的交互式shell
-适合进行交互式数据可视化和GUI相关应用
IPython几个技巧
?:可以在变量或者函数前面加?获得通用信息
%run :可以执行.py程序 注意:%run在一个空的命名空间执行%
trouble shooting:
在ubuntu18中安装了anaconda3,启动spyder报错Segmentation fault (core dumped)
安装conda install pyopengl 然后再启动 卡住半天没了 出现killed报错 我日 然后升级了下anaconda3到最新才好了
1. 数据分析之表示
1.1 NumPy库入门
数据的维度
一维数据 列表、集合
二维数据 表格是经典的二维数据 用列表表示
多维数据 二维数据在更多维度上展开 比如时间维度 用列表表示
高维数据 仅使用最基本的二元关系展示复杂关系 key-value形式组织数据 用字典类型或者其他json、xmal、yaml等
NumPy的数组对象:ndarray
NumPy是一个开源的Python科学计算基础库
-一个强大的N维数组对象ndarray
-广播函数功能
-整合c/c++/fortran代码的工具
-线性代数、傅里叶变换、随机数生成等功能
NumPy是SciPy、Pandas等数据处理或科学计算库的基础
使用 import numpy as np
ndarray是一个多维数组,由两部分组成,要求数组元素类型相同,数组下标从0开始
-元数据(数据维度,数据类型等)
-实际数据
np.array() –ndarray别名是array
轴(axis):保存数据的维度
秩(rank):轴的数量
 例子:
例子:
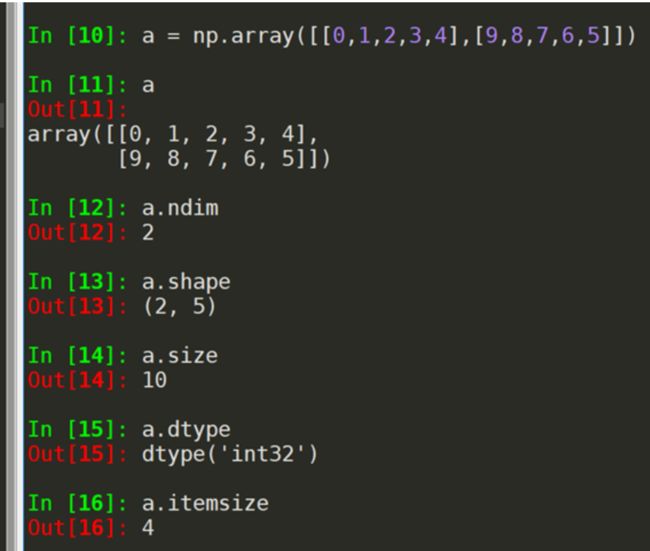 里面的int32不是Python基础类型,是NumPy定义的类型,更多类型如下:
里面的int32不是Python基础类型,是NumPy定义的类型,更多类型如下:
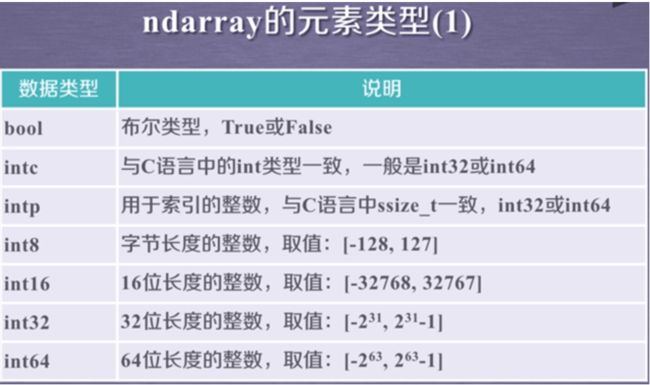


为啥要这么多数据类型?
-科学计算涉及大量数据,对性能和存储都有较高要求
-对元素类型精细定义,有助于numpy合理使用存储空间并优化性能,有助于程序员对程序规模由合理评估
ndarray数组也可以由非同质对象构成
非同质ndarray元素为对象类型
非同质ndarray数组无法发挥numpy优势,尽量避免使用
ndarray数组的创建和变换

1) 从python列表元组等类型创建数组
x = np.array(list/tuple)
x = np.array(list/tuple,dtype=np.float32) 不指定类型的时候numpy自动关联一个合适的



 除了arange函数,其他都是浮点数
除了arange函数,其他都是浮点数
 ndarray数组的变换:维度变换、元素类型变换
ndarray数组的变换:维度变换、元素类型变换

ndarray数组向列表变换
ls = a.tolist()
ndarray数组的操作
索引和切片
ndarray一维数组的索引和列表一样

ndarray数组的运算
数组与标量的运算等于每个元素都和这个标量算一下


maximum等经过运算存在数据类型隐式转换
1.2 NumPy数据存取与函数
数据的csv文件存取
csv只能存储读取一维和二维数据,这是它的局限
多维数据的存取
对于ndarray数组 有个方法 a.tofile(frame,sep=’’,format=’%s’)
-frame 文件、字符串 sep:数据分隔符,如果是空串,写入文件为二进制 format:写入数据的格式

可以保存为二进制,小些,但是无法人类读懂,如果知道是这样写的,可以还原,作为一种保存数据的方法
如何还原呢,np.fromfile(frame,dtype=float,count=-1,sep=’’)
-dtype:读取的数据类型 count:读入元素的个数-1表示全部
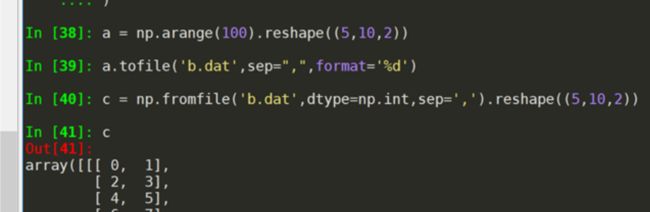
使用这个方法需要知道存入文件时候的数组维度和元素类型,就是元数据,所以fromfile和tofile需要配合使用,可以将元数据另外存储解决
NumPy的便捷文件存取
np.save(fname,array)或者np.savez(fname,array)
-fname:文件名以.npy或者.npz
np.load(fname)
NumPy的随机数函数
NumPy的random子库 np.random.*
 NumPy的统计函数
NumPy的统计函数
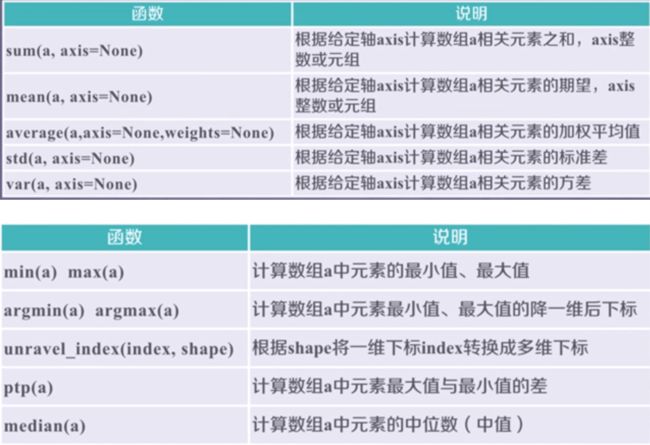
 NumPy的梯度函数
NumPy的梯度函数

1.3 实例1:图像的手绘效果
图像的数组表示
RGB色彩表示
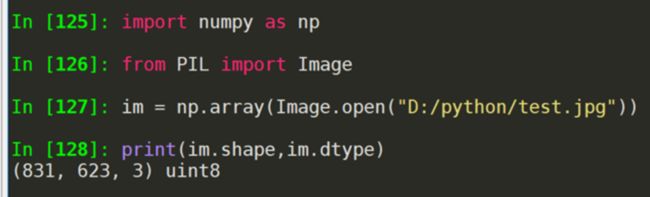
PIL库 处理图像的第三方库 pip install pillow from PIL import Image
Image是PIL库中代表图像的类(对象)
图像是一个由像素组成的二维矩阵,每个元素是一个RGB值
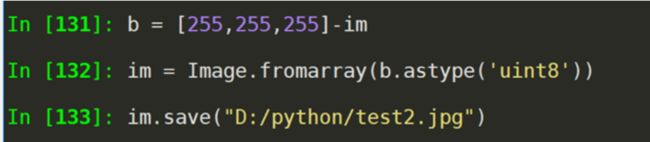
 图像的变换
图像的变换

图像的手绘实例
手绘特征:黑白灰色、边界线条较重、相同或者相近色彩趋于白色、略有光源效果

from PIL import Image
import numpy as np
a = np.asarray(Image.open('./beijing.jpg').convert('L')).astype('float')
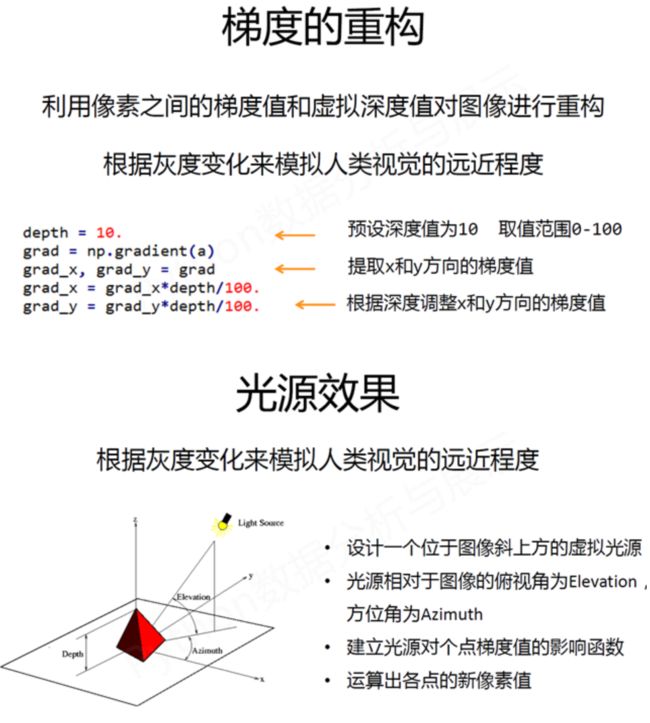
depth = 10. # (0-100)
grad = np.gradient(a) #取图像灰度的梯度值
grad_x, grad_y = grad #分别取横纵图像梯度值
grad_x = grad_x*depth/100.
grad_y = grad_y*depth/100.
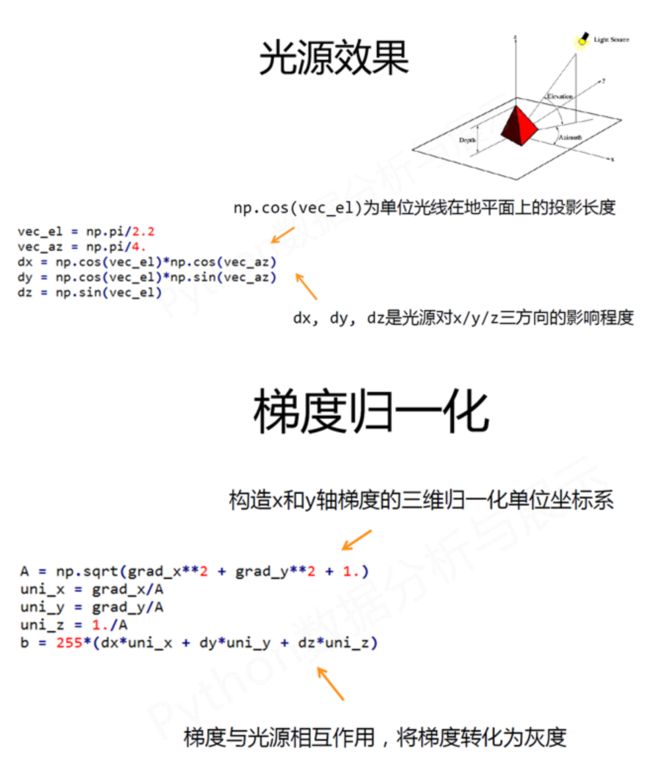
A = np.sqrt(grad_x**2 + grad_y**2 + 1.)
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
vec_el = np.pi/2.2 # 光源的俯视角度,弧度值
vec_az = np.pi/4. # 光源的方位角度,弧度值
dx = np.cos(vec_el)*np.cos(vec_az) #光源对x 轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对y 轴的影响
dz = np.sin(vec_el) #光源对z 轴的影响
b = 255*(dx*uni_x + dy*uni_y + dz*uni_z) #光源归一化
b = b.clip(0,255)
im = Image.fromarray(b.astype('uint8')) #重构图像
im.save('./beijingHD.jpg')

2. 数据分析与展示
2.1 Matplotlib库入门
由各种数据可视化类组成,内部结构复杂,是受matlab启发
matplotlib.pyplot是绘制各类可视化图形的命令子库,相当于快捷方式
import matplotlib.pyplot as plt
plt.savefig(‘test’,dpi=600) #保存为png文件
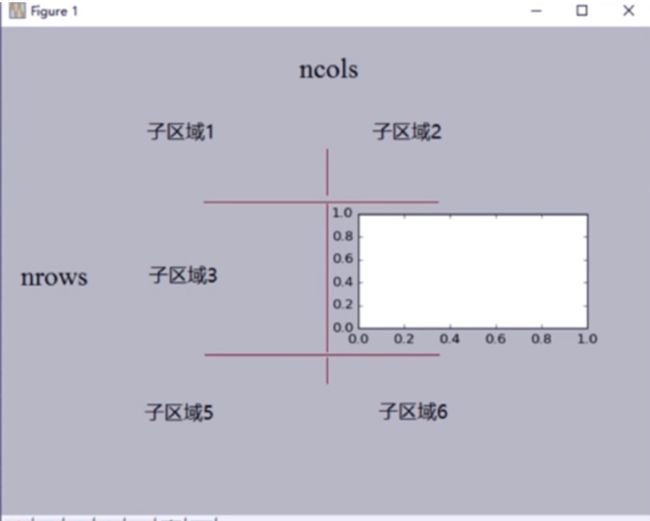
绘制多个图形,分区域plt.subplot(3,2,4)
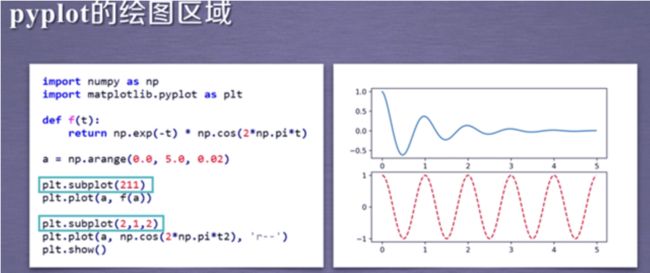
pylot的plot函数
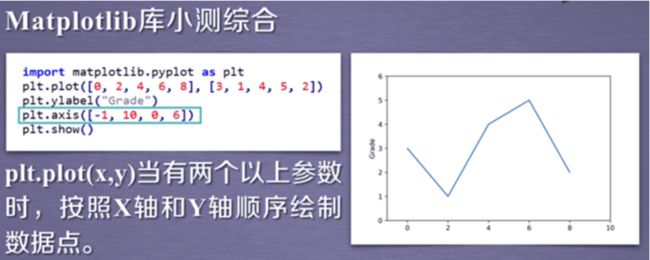
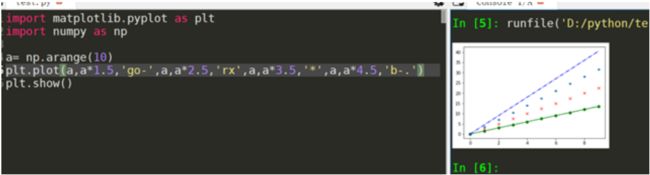
plt.plot(x,y,format_string,**kwargs)
-format_string 表示曲线的格式字符串 **kwargs表示第二组或更多(x,y,format_string) 当绘制多条曲线x不能省略,当绘制一条时候可以省略x用索引值
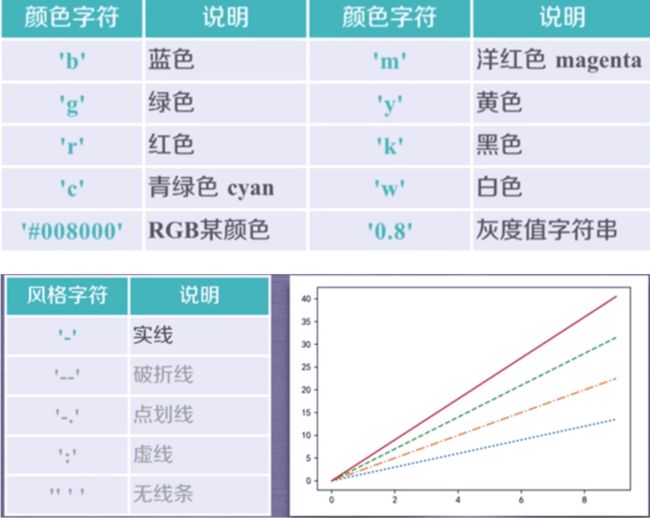
 format_string由颜色字符、风格字符、标记字符组成
format_string由颜色字符、风格字符、标记字符组成
pyplot的中文显示
方法1:修改绘制区域的全部字体
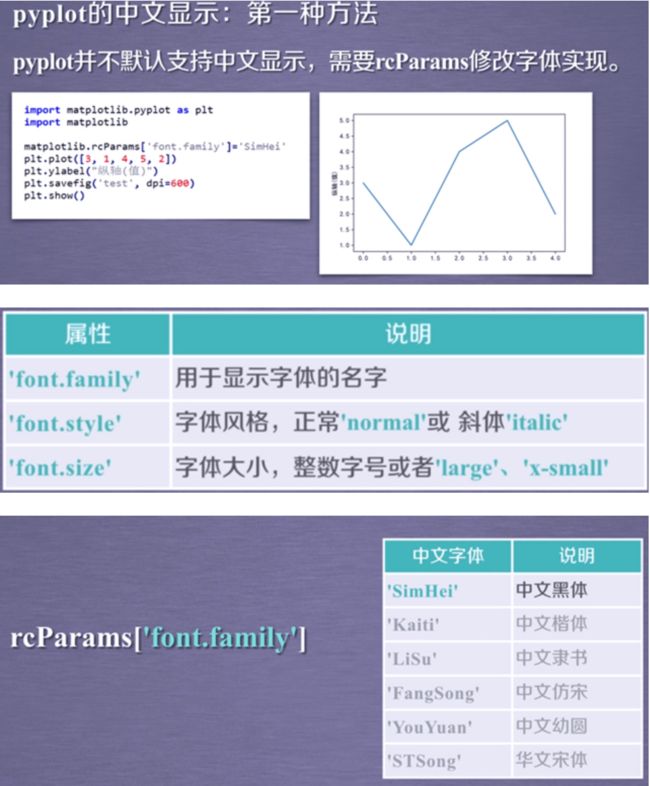 方法2:
方法2:
 pylot的文本显示
pylot的文本显示
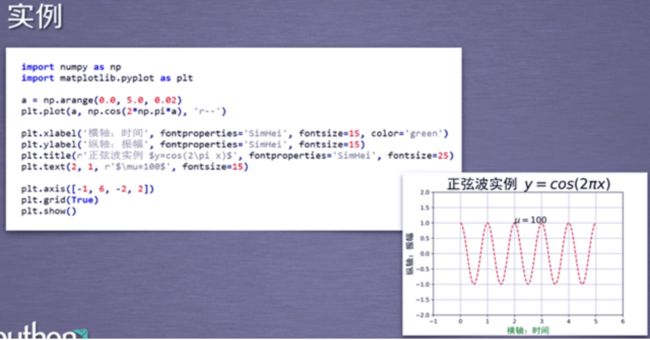 首先字符串前边的r代表是原始字符串,也就是里边的内容不需要转移,这个一般在正则表达式的时候也这么用,而这里是laText的用法,在python中使用laText,需要在文本的前后加上$符号,也就是你所用的那样,然后就是laText的文本了,当你输入了以上内容,matplotlib会自动为你解析的,\pi代表的就是π
首先字符串前边的r代表是原始字符串,也就是里边的内容不需要转移,这个一般在正则表达式的时候也这么用,而这里是laText的用法,在python中使用laText,需要在文本的前后加上$符号,也就是你所用的那样,然后就是laText的文本了,当你输入了以上内容,matplotlib会自动为你解析的,\pi代表的就是π
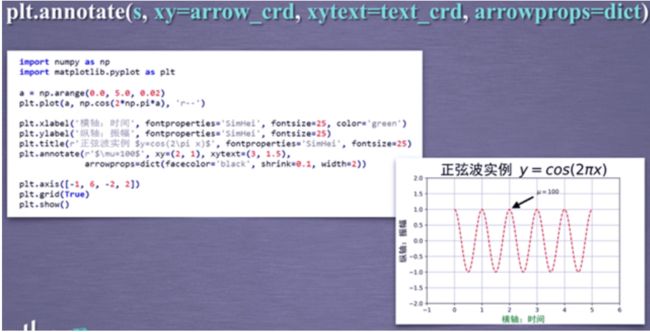 pylot子绘图区域
pylot子绘图区域
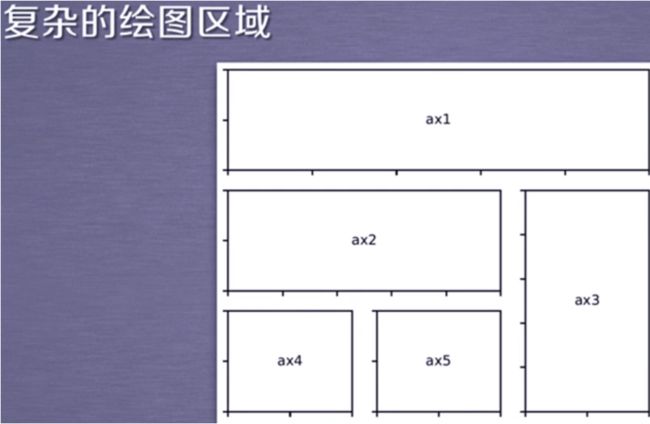

 这种方法每次都要写(3,3),用另外一种方法GridSpec类
这种方法每次都要写(3,3),用另外一种方法GridSpec类


2.2 Matplotlib基础绘图函数示例(5个实例)
 pylot饼图绘制
pylot饼图绘制
 pylot直方图绘制
pylot直方图绘制
 pylot极坐标绘制
pylot极坐标绘制
 pyplot散点图绘制
pyplot散点图绘制
 面向对象的绘制方法是matplotlib库的推荐方法,pillow库的函数变为对象的方法
面向对象的绘制方法是matplotlib库的推荐方法,pillow库的函数变为对象的方法
2.3 实例2:引力波的绘制
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
rate_h, hstrain= wavfile.read(r"H1_Strain.wav","rb")
rate_l, lstrain= wavfile.read(r"L1_Strain.wav","rb")
#reftime, ref_H1 = np.genfromtxt('GW150914_4_NR_waveform_template.txt').transpose()
reftime, ref_H1 = np.genfromtxt('wf_template.txt').transpose() #使用python123.io下载文件
htime_interval = 1/rate_h
ltime_interval = 1/rate_l
fig = plt.figure(figsize=(12, 6))
# 丢失信号起始点
htime_len = hstrain.shape[0]/rate_h
htime = np.arange(-htime_len/2, htime_len/2 , htime_interval)
plth = fig.add_subplot(221)
plth.plot(htime, hstrain, 'y')
plth.set_xlabel('Time (seconds)')
plth.set_ylabel('H1 Strain')
plth.set_title('H1 Strain')
ltime_len = lstrain.shape[0]/rate_l
ltime = np.arange(-ltime_len/2, ltime_len/2 , ltime_interval)
pltl = fig.add_subplot(222)
pltl.plot(ltime, lstrain, 'g')
pltl.set_xlabel('Time (seconds)')
pltl.set_ylabel('L1 Strain')
pltl.set_title('L1 Strain')
pltref = fig.add_subplot(212)
pltref.plot(reftime, ref_H1)
pltref.set_xlabel('Time (seconds)')
pltref.set_ylabel('Template Strain')
pltref.set_title('Template')
fig.tight_layout()
plt.savefig("Gravitational_Waves_Original.png")
plt.show()
plt.close(fig)
结果
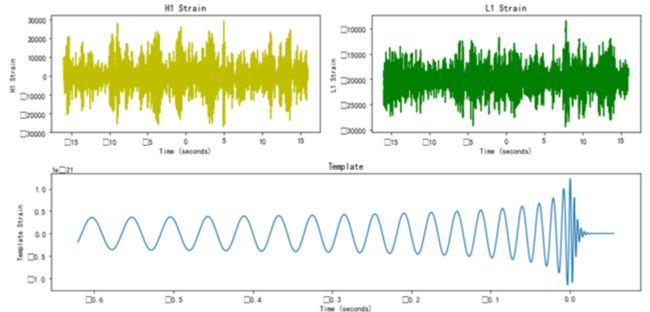
3. 数据分析之概要
3.1 Pandas库入门
Pandas提供高性能易用数据类型和分析工具
import pandas as pd
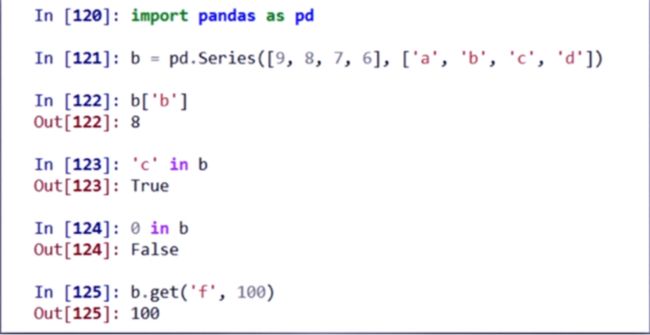
 Pandas库的Series类型 –一维
Pandas库的Series类型 –一维
 也支持自定义索引
也支持自定义索引


b.index b.values 获得索引和数据 类似ndarray和字典
两套索引并存 但是不能混用
 Series类型也与字典类型类似 可以in, get()
Series类型也与字典类型类似 可以in, get()


Pandas库的DataFrame类型 –二维
由共用相同索引的一组列组成,实际上就是一个表格
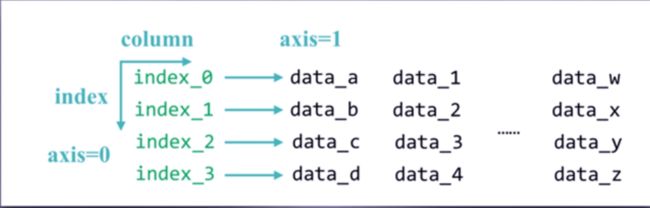
是一个表格型的数据类型,每列值类型可以不同
既有行索引也有列索引
常用于表达二维数据,单可以表达多维数据



DataFrame基本操作类似Series,根据行列索引
Pandas库的数据数据类型操作
如何改变结构呢 增加 或重排:重新索引 删除:drop

 索引是不可修改类型 索引的操作就是对数据的操作 numpy不存在索引 必须通过维度来操作
索引是不可修改类型 索引的操作就是对数据的操作 numpy不存在索引 必须通过维度来操作


Series只有0轴 DataFrame由0轴 1轴,drop默认操作0轴
Pandas库的数据类型运算
算术类型运算


 比较运算
比较运算
数据和索引建立关联关系 达到操作索引就是操作数据

3.2 Pandas数据特征分析
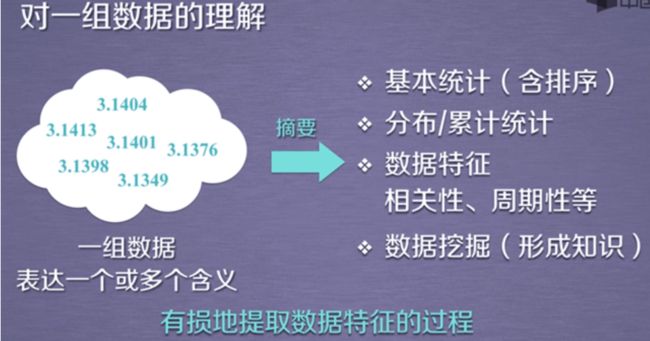
数据的排序
可以对索引排序
也可以对数据排序
 基本的统计分析函数
基本的统计分析函数


 累计统计分析
累计统计分析
滚动计算(窗口计算)
 数据的相关分析
数据的相关分析

