python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心...

嵩天老师的课感觉很好呀,啦啦啦
0. 数据分析之前奏
课程主要内容:
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第1张图片](http://img.e-com-net.com/image/info8/ffcabd74296e4c679bcf685a806b893f.jpg)
常用IDE:
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第2张图片](http://img.e-com-net.com/image/info8/42ec8c792de1470eb6bb4879638da17d.jpg)
本课程主要使用:Anaconda
Anaconda:一个集合,包括conda、某版本Python、一批第三方库等
-支持近800个第三方库
-适合科学计算领域
-包含多个主流工具
-开源免费
-跨平台
本身不是个ide 是将多个工具集成在一起的
conda
-一个工具,用于包管理和环境管理
-包管理与pip类似,管理Python第三方库
-环境管理能够允许用户使用不同版本的Python,并能灵活切换
conda将工具、第三方库、Python版本、conda都当作包,同等对待
conda有命令行工具
C:\Users\king\Anaconda3\Scripts\conda.exe –version 可以查看conda版本
conda update conda 升级conda
刚开始的是命令行,现在也集成为GUI,anaconda默认生成root的环境空间
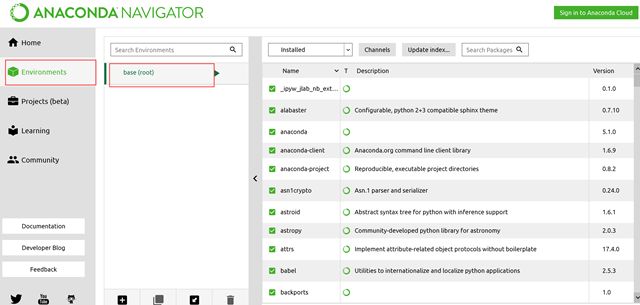
编程工具:spyder
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第3张图片](http://img.e-com-net.com/image/info8/c46e9f611868464fb8830fb3a30b15a5.jpg)
默认不舒服 改下
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第4张图片](http://img.e-com-net.com/image/info8/40c1e127542342748700b2072782f95c.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第5张图片](http://img.e-com-net.com/image/info8/c0da06f812c6453dbce640a15461e075.jpg)
交互式编程环境:IPython
-是一个功能强大的交互式shell
-适合进行交互式数据可视化和GUI相关应用
IPython几个技巧
?:可以在变量或者函数前面加?获得通用信息
%run :可以执行.py程序 注意:%run在一个空的命名空间执行%
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第6张图片](http://img.e-com-net.com/image/info8/a7f2d854ce4244f1beb34d479305e7ed.jpg)
trouble shooting:
在ubuntu18中安装了anaconda3,启动spyder报错Segmentation fault (core dumped)
安装conda install pyopengl 然后再启动 卡住半天没了 出现killed报错 我日 然后升级了下anaconda3到最新才好了
1. 数据分析之表示
1.1 NumPy库入门
数据的维度
一维数据 列表、集合
二维数据 表格是经典的二维数据 用列表表示
多维数据 二维数据在更多维度上展开 比如时间维度 用列表表示
高维数据 仅使用最基本的二元关系展示复杂关系 key-value形式组织数据 用字典类型或者其他json、xmal、yaml等
NumPy的数组对象:ndarray
NumPy是一个开源的Python科学计算基础库
-一个强大的N维数组对象ndarray
-广播函数功能
-整合c/c++/fortran代码的工具
-线性代数、傅里叶变换、随机数生成等功能
NumPy是SciPy、Pandas等数据处理或科学计算库的基础
使用 import numpy as np
ndarray是一个多维数组,由两部分组成,要求数组元素类型相同,数组下标从0开始
-元数据(数据维度,数据类型等)
-实际数据
np.array() --ndarray别名是array
轴(axis):保存数据的维度
秩(rank):轴的数量
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第7张图片](http://img.e-com-net.com/image/info8/895aa4b6f671430a86f08ad5f279878f.jpg)
例子:
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第8张图片](http://img.e-com-net.com/image/info8/bc434fd1c4d243dc8d58b33ecc37b6da.jpg)
里面的int32不是Python基础类型,是NumPy定义的类型,更多类型如下:
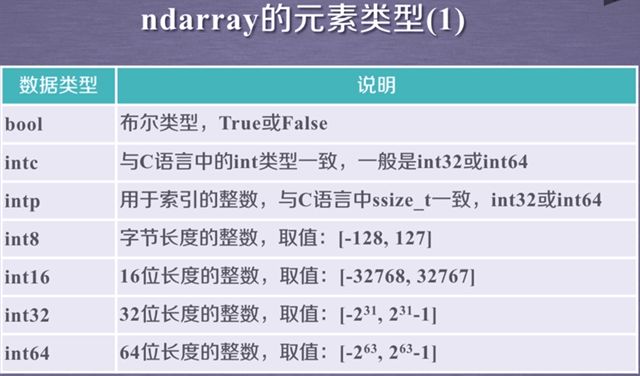
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第9张图片](http://img.e-com-net.com/image/info8/451c8940f2ee4811bdb92d02c7d01e22.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第10张图片](http://img.e-com-net.com/image/info8/5ea68bc95b654c258fc454556edb6f52.jpg)
为啥要这么多数据类型?
-科学计算涉及大量数据,对性能和存储都有较高要求
-对元素类型精细定义,有助于numpy合理使用存储空间并优化性能,有助于程序员对程序规模由合理评估
ndarray数组也可以由非同质对象构成
非同质ndarray元素为对象类型
非同质ndarray数组无法发挥numpy优势,尽量避免使用
ndarray数组的创建和变换
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第11张图片](http://img.e-com-net.com/image/info8/e641386a411a45cb8570336e8d388f56.jpg)
1) 从python列表元组等类型创建数组
x = np.array(list/tuple)
x = np.array(list/tuple,dtype=np.float32) 不指定类型的时候numpy自动关联一个合适的
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第12张图片](http://img.e-com-net.com/image/info8/54d4b720d58944549409022594d1e82c.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第13张图片](http://img.e-com-net.com/image/info8/1d28ea9130644e2b80e9592745cdbc66.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第14张图片](http://img.e-com-net.com/image/info8/9994c398124e4ad39d3946f535982362.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第15张图片](http://img.e-com-net.com/image/info8/f370ab0a13a248359f6a25f99fb9a00d.jpg)
除了arange函数,其他都是浮点数
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第16张图片](http://img.e-com-net.com/image/info8/02653f067582486080ea3046f643d484.jpg)
ndarray数组的变换:维度变换、元素类型变换
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第17张图片](http://img.e-com-net.com/image/info8/7c180d60b9b144c7a09d5ea9cc0c2eb4.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第18张图片](http://img.e-com-net.com/image/info8/a264e8d609ff457e8e48f5ac4c507d78.jpg)
ndarray数组向列表变换
ls = a.tolist()
ndarray数组的操作
索引和切片
ndarray一维数组的索引和列表一样
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第19张图片](http://img.e-com-net.com/image/info8/6181f3ff771a47f19cc73b53ab25e55c.jpg)
ndarray数组的运算
数组与标量的运算等于每个元素都和这个标量算一下
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第20张图片](http://img.e-com-net.com/image/info8/8a68f15175a34866bacb83d0dc65fcca.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第21张图片](http://img.e-com-net.com/image/info8/ede8066765694266855a51faba508a0b.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第22张图片](http://img.e-com-net.com/image/info8/37d55efd366c4b52a4df307b0e006823.jpg)
maximum等经过运算存在数据类型隐式转换
1.2 NumPy数据存取与函数
数据的csv文件存取
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第23张图片](http://img.e-com-net.com/image/info8/81a70174e31b4b2ebca5554b74c7523e.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第24张图片](http://img.e-com-net.com/image/info8/fa8745f0b7e2445f8e59609c8cb8c2bb.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第25张图片](http://img.e-com-net.com/image/info8/68c3c553eeea4c8295cbbb20362c111e.jpg)
csv只能存储读取一维和二维数据,这是它的局限
多维数据的存取
对于ndarray数组 有个方法 a.tofile(frame,sep=’’,format=’%s’)
-frame 文件、字符串 sep:数据分隔符,如果是空串,写入文件为二进制 format:写入数据的格式
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第26张图片](http://img.e-com-net.com/image/info8/14e9ec0e74094958b38e8593ea65d293.jpg)
可以保存为二进制,小些,但是无法人类读懂,如果知道是这样写的,可以还原,作为一种保存数据的方法
如何还原呢,np.fromfile(frame,dtype=float,count=-1,sep=’’)
-dtype:读取的数据类型 count:读入元素的个数-1表示全部
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第27张图片](http://img.e-com-net.com/image/info8/98042bd410cc44b095d9d50d5e15a76c.jpg)
使用这个方法需要知道存入文件时候的数组维度和元素类型,就是元数据,所以fromfile和tofile需要配合使用,可以将元数据另外存储解决
NumPy的便捷文件存取
np.save(fname,array)或者np.savez(fname,array)
-fname:文件名以.npy或者.npz
np.load(fname)
NumPy的随机数函数
NumPy的random子库 np.random.*
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第28张图片](http://img.e-com-net.com/image/info8/24685c7593734b85bef8ecb6786db242.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第29张图片](http://img.e-com-net.com/image/info8/a529f45843ba4aab9bd714e3d959f460.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第30张图片](http://img.e-com-net.com/image/info8/e1b05587bf824f0d8e6f4d6fecc6e5cb.jpg)
NumPy的统计函数
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第31张图片](http://img.e-com-net.com/image/info8/283c46040138436ba4e7188f5a4dae9d.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第32张图片](http://img.e-com-net.com/image/info8/166de5a2634841b5a9c92a2f18fec34f.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第33张图片](http://img.e-com-net.com/image/info8/4057d565711146b298e3907377f4e346.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第34张图片](http://img.e-com-net.com/image/info8/5eb7c5653ff34edd85b14d5ea56a1f55.jpg)
NumPy的梯度函数
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第35张图片](http://img.e-com-net.com/image/info8/cad75860a6734f50aa79ba7be9312b7a.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第36张图片](http://img.e-com-net.com/image/info8/ba9a17205bdc4ac3bfd9f19a828841e2.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第37张图片](http://img.e-com-net.com/image/info8/73b2cfb062da4e62b51c629863f1f2fc.jpg)
1.3 实例1:图像的手绘效果
图像的数组表示
RGB色彩表示
PIL库 处理图像的第三方库 pip install pillow from PIL import Image
Image是PIL库中代表图像的类(对象)
图像是一个由像素组成的二维矩阵,每个元素是一个RGB值
图像的变换
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第38张图片](http://img.e-com-net.com/image/info8/2afd2ed52d114aef8400e62f0bd07daf.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第39张图片](http://img.e-com-net.com/image/info8/514c3ffd6b2c4a97b1a705a6a397e1fe.jpg)

![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第40张图片](http://img.e-com-net.com/image/info8/76f137786c3944fcb1055b6f9997ba09.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第41张图片](http://img.e-com-net.com/image/info8/2ea25b60bbb146a09d99514b9fe17bad.jpg)
图像的手绘实例
手绘特征:黑白灰色、边界线条较重、相同或者相近色彩趋于白色、略有光源效果
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第42张图片](http://img.e-com-net.com/image/info8/52f3d83257674548a8d5131d4aca7b52.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第43张图片](http://img.e-com-net.com/image/info8/cbd1c97f92d6456c9262b814a9944764.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第44张图片](http://img.e-com-net.com/image/info8/e0f1c773141b4cff8b12d35244e1a66e.jpg)

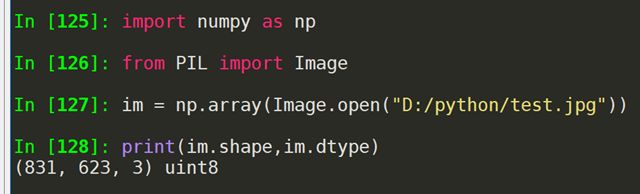
from PIL importImageimportnumpy as np
a= np.asarray(Image.open('./test.jpg').convert('L')).astype('float')
depth= 10. #(0-100)
grad = np.gradient(a) #取图像灰度的梯度值
grad_x, grad_y = grad #分别取横纵图像梯度值
grad_x = grad_x*depth/100.
grad_y= grad_y*depth/100.
A= np.sqrt(grad_x**2 + grad_y**2 + 1.)
uni_x= grad_x/A
uni_y= grad_y/A
uni_z= 1./A
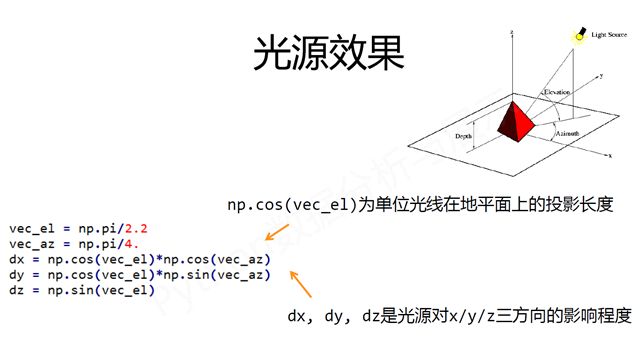
vec_el= np.pi/2.2 #光源的俯视角度,弧度值
vec_az = np.pi/4. #光源的方位角度,弧度值
dx = np.cos(vec_el)*np.cos(vec_az) #光源对x 轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对y 轴的影响
dz = np.sin(vec_el) #光源对z 轴的影响
b= 255*(dx*uni_x + dy*uni_y + dz*uni_z) #光源归一化
b = b.clip(0,255)
im= Image.fromarray(b.astype('uint8')) #重构图像
im.save('./test2.jpg')
结果
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第45张图片](http://img.e-com-net.com/image/info8/1e4d94fd4ea848fda5ce69a5f0b9639e.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第46张图片](http://img.e-com-net.com/image/info8/1c20f1a064e54690aea186362711fbac.jpg)
2. 数据分析与展示
2.1 Matplotlib库入门
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第47张图片](http://img.e-com-net.com/image/info8/92defdd294c64d458066e9ad72b2574d.jpg)
由各种数据可视化类组成,内部结构复杂,是受matlab启发
matplotlib.pyplot是绘制各类可视化图形的命令子库,相当于快捷方式
import matplotlib.pyplot as plt
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第48张图片](http://img.e-com-net.com/image/info8/f91d5aaa0dbd4ed1a78bafdc439a2bd4.jpg)
plt.savefig(‘test’,dpi=600) #保存为png文件
绘制多个图形,分区域plt.subplot(3,2,4)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第49张图片](http://img.e-com-net.com/image/info8/ef38313324234eff9e3f1c21e279644d.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第50张图片](http://img.e-com-net.com/image/info8/7e446d12e54f4336b402c6c97a9da903.jpg)
pylot的plot函数
plt.plot(x,y,format_string,**kwargs)
-format_string 表示曲线的格式字符串 **kwargs表示第二组或更多(x,y,format_string) 当绘制多条曲线x不能省略,当绘制一条时候可以省略x用索引值
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第51张图片](http://img.e-com-net.com/image/info8/bcb09feb458f44c9906c4483863a2918.jpg)
format_string由颜色字符、风格字符、标记字符组成
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第52张图片](http://img.e-com-net.com/image/info8/671d4e96f6e14e6f83bc5d22860c54f4.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第53张图片](http://img.e-com-net.com/image/info8/dc891f0117904b0295aa53513f08a02e.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第54张图片](http://img.e-com-net.com/image/info8/4cf10870a16646fb8d1f37763a23cb28.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第55张图片](http://img.e-com-net.com/image/info8/0c963aa5daf7464f8e34599d2c0b2e36.jpg)
pyplot的中文显示
方法1:修改绘制区域的全部字体
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第56张图片](http://img.e-com-net.com/image/info8/6d44e69760854be08f9f2f0e25e901f7.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第57张图片](http://img.e-com-net.com/image/info8/a7391d0b33614e49a8506d3dd0ed70df.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第58张图片](http://img.e-com-net.com/image/info8/aebfe7200c2e401cb9d8f58b4f500e0d.jpg)
方法2:
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第59张图片](http://img.e-com-net.com/image/info8/c5a6d57fc4a4404581518fc8f367be9a.jpg)
pylot的文本显示
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第60张图片](http://img.e-com-net.com/image/info8/e0c05a10a38c42649ea7b8f703ccc3ad.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第61张图片](http://img.e-com-net.com/image/info8/d338ab332af945e19d05fbacf5a8d6e7.jpg)
首先字符串前边的r代表是原始字符串,也就是里边的内容不需要转移,这个一般在正则表达式的时候也这么用,而这里是laText的用法,在python中使用laText,需要在文本的前后加上$符号,也就是你所用的那样,然后就是laText的文本了,当你输入了以上内容,matplotlib会自动为你解析的,\pi代表的就是π
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第62张图片](http://img.e-com-net.com/image/info8/a555e93bcae549aabfa07f6ba538f418.jpg)
pylot子绘图区域
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第63张图片](http://img.e-com-net.com/image/info8/f0bad84be7e3424aa6eab07991a03382.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第64张图片](http://img.e-com-net.com/image/info8/fbc67f0369574df286ae7f1cc6a0863d.jpg)
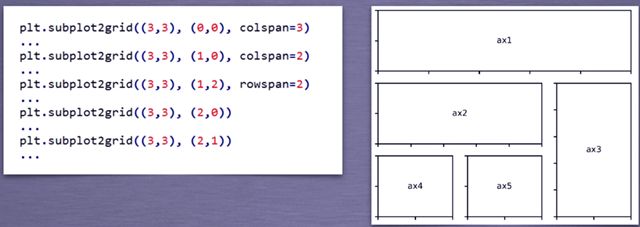
这种方法每次都要写(3,3),用另外一种方法GridSpec类
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第65张图片](http://img.e-com-net.com/image/info8/d06dedf65a654209add19abf18d5e864.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第66张图片](http://img.e-com-net.com/image/info8/c893ba204b8c4e94ba44333b6dedf201.jpg)
2.2 Matplotlib基础绘图函数示例(5个实例)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第67张图片](http://img.e-com-net.com/image/info8/ea4374ffc4b24aa3b3bfa5ed2f219fa7.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第68张图片](http://img.e-com-net.com/image/info8/51fee82ba8964ace9fe6416f3bf32cb7.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第69张图片](http://img.e-com-net.com/image/info8/5598ff134d8e4252a0b8f580cbe4f575.jpg)
pylot饼图绘制
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第70张图片](http://img.e-com-net.com/image/info8/d1c8da0261724a12ba3bcff9df41f5d6.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第71张图片](http://img.e-com-net.com/image/info8/99b9282c9bf34423a491f635f1be3d01.jpg)
pylot直方图绘制
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第72张图片](http://img.e-com-net.com/image/info8/d7441533959b45318891e28306bc9bcd.jpg)
pylot极坐标绘制
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第73张图片](http://img.e-com-net.com/image/info8/fa934acc1ae54d469bb9f61da2191202.jpg)
pyplot散点图绘制
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第74张图片](http://img.e-com-net.com/image/info8/94436a2e4f89459a9675743c614a3332.jpg)
面向对象的绘制方法是matplotlib库的推荐方法,pillow库的函数变为对象的方法
2.3 实例2:引力波的绘制
http://python123.io/dv/grawave.html 引力波数据源
importnumpy as npimportmatplotlib.pyplot as pltfrom scipy.io importwavfile
rate_h, hstrain= wavfile.read(r"H1_Strain.wav","rb")
rate_l, lstrain= wavfile.read(r"L1_Strain.wav","rb")#reftime, ref_H1 = np.genfromtxt('GW150914_4_NR_waveform_template.txt').transpose()
reftime, ref_H1 = np.genfromtxt('wf_template.txt').transpose() #使用python123.io下载文件
htime_interval= 1/rate_h
ltime_interval= 1/rate_l
fig= plt.figure(figsize=(12, 6))#丢失信号起始点
htime_len = hstrain.shape[0]/rate_h
htime= np.arange(-htime_len/2, htime_len/2, htime_interval)
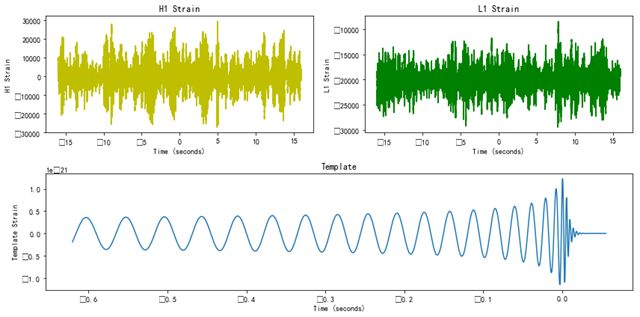
plth= fig.add_subplot(221)
plth.plot(htime, hstrain,'y')
plth.set_xlabel('Time (seconds)')
plth.set_ylabel('H1 Strain')
plth.set_title('H1 Strain')
ltime_len= lstrain.shape[0]/rate_l
ltime= np.arange(-ltime_len/2, ltime_len/2, ltime_interval)
pltl= fig.add_subplot(222)
pltl.plot(ltime, lstrain,'g')
pltl.set_xlabel('Time (seconds)')
pltl.set_ylabel('L1 Strain')
pltl.set_title('L1 Strain')
pltref= fig.add_subplot(212)
pltref.plot(reftime, ref_H1)
pltref.set_xlabel('Time (seconds)')
pltref.set_ylabel('Template Strain')
pltref.set_title('Template')
fig.tight_layout()
plt.savefig("Gravitational_Waves_Original.png")
plt.show()
plt.close(fig)
结果
3. 数据分析之概要
3.1 Pandas库入门
Pandas提供高性能易用数据类型和分析工具
import pandas as pd
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第75张图片](http://img.e-com-net.com/image/info8/a746a9b6127d4d5cb2da9a55bb2e977b.jpg)
Pandas库的Series类型 --一维
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第76张图片](http://img.e-com-net.com/image/info8/08ed43f5e8614676969049a4c9ea859a.jpg)
也支持自定义索引
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第77张图片](http://img.e-com-net.com/image/info8/b9c9a73a48c74c2e844c70e9ae112bf5.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第78张图片](http://img.e-com-net.com/image/info8/e7b2f886ac01430ea7febee60f790001.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第79张图片](http://img.e-com-net.com/image/info8/5fcfc60b6cd344e7adf7714b2663a511.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第80张图片](http://img.e-com-net.com/image/info8/e24da4fd4b9e47b08c77146384ac0cb6.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第81张图片](http://img.e-com-net.com/image/info8/769a69d5205f40bdacab83af82efd588.jpg)
b.index b.values 获得索引和数据 类似ndarray和字典
两套索引并存 但是不能混用
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第82张图片](http://img.e-com-net.com/image/info8/7215ecd25528420b8777ea3607315c07.jpg)
Series类型也与字典类型类似 可以in, get()
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第83张图片](http://img.e-com-net.com/image/info8/52d217378bf3480b981b5a0d5bd0bc14.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第84张图片](http://img.e-com-net.com/image/info8/8ca10e30cfa444ec955927c424ea7683.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第85张图片](http://img.e-com-net.com/image/info8/fab59c161f8544749ca148c42765093c.jpg)
Pandas库的DataFrame类型 --二维
由共用相同索引的一组列组成,实际上就是一个表格

是一个表格型的数据类型,每列值类型可以不同
既有行索引也有列索引
常用于表达二维数据,单可以表达多维数据
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第86张图片](http://img.e-com-net.com/image/info8/7e02d87215a14d8198c91917b060350d.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第87张图片](http://img.e-com-net.com/image/info8/40675d3c50814b2abdf36d47e4c306ba.jpg)

![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第88张图片](http://img.e-com-net.com/image/info8/fae8c9ffa2d24863837a841214bcd1fa.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第89张图片](http://img.e-com-net.com/image/info8/fed1361580da43129f9ff3074fa82384.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第90张图片](http://img.e-com-net.com/image/info8/d95ff188e19a48cf9e5b9bbe62d038a0.jpg)
DataFrame基本操作类似Series,根据行列索引
Pandas库的数据数据类型操作
如何改变结构呢 增加 或重排:重新索引 删除:drop
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第91张图片](http://img.e-com-net.com/image/info8/90648fb6b1114f8d9cbae693fe91f19b.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第92张图片](http://img.e-com-net.com/image/info8/08196b57614e42c1bc7441badf42f092.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第93张图片](http://img.e-com-net.com/image/info8/28b696e13c0d4c0db08f6122ba67fe34.jpg)
索引是不可修改类型 索引的操作就是对数据的操作 numpy不存在索引 必须通过维度来操作
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第94张图片](http://img.e-com-net.com/image/info8/4e58a1b4c9974304822aaef2a7ea6abb.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第95张图片](http://img.e-com-net.com/image/info8/50724058703f498dba8d97c947d143d5.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第96张图片](http://img.e-com-net.com/image/info8/c33ee998b3574ef5a9041df7143c9882.jpg)
Series只有0轴 DataFrame由0轴 1轴,drop默认操作0轴
Pandas库的数据类型运算
算术类型运算
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第97张图片](http://img.e-com-net.com/image/info8/be9094aac5a94fa993bb7410e3c80d16.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第98张图片](http://img.e-com-net.com/image/info8/2630c6379e0e406ebb3b9334a00c9cb5.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第99张图片](http://img.e-com-net.com/image/info8/d5e69163fd0c4b3882785dafef5d46e4.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第100张图片](http://img.e-com-net.com/image/info8/b7ab96b5d53a46628147a35c9bbff411.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第101张图片](http://img.e-com-net.com/image/info8/fc7758587d4d4e01ae6090c62326bbc2.jpg)
比较运算
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第102张图片](http://img.e-com-net.com/image/info8/a2ebb674d6fa48a1afced4caee53f15b.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第103张图片](http://img.e-com-net.com/image/info8/56d8f405dccd485ca652767b4289520d.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第104张图片](http://img.e-com-net.com/image/info8/388d73e21d724bffb4bcb2e37f8226f6.jpg)
数据和索引建立关联关系 达到操作索引就是操作数据
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第105张图片](http://img.e-com-net.com/image/info8/82e3ce811dfe447e90462dea9e3f8228.jpg)
3.2 Pandas数据特征分析
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第106张图片](http://img.e-com-net.com/image/info8/f7297ee3735148aaaf27b495b63d5f55.jpg)
数据的排序
可以对索引排序
也可以对数据排序
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第107张图片](http://img.e-com-net.com/image/info8/17bc1d49539247cd92d3e4d9f73b43b5.jpg)

![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第108张图片](http://img.e-com-net.com/image/info8/b6995086525442c69c39d1bc45078d95.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第109张图片](http://img.e-com-net.com/image/info8/af8cd947bdb3461896e197b2aff753e4.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第110张图片](http://img.e-com-net.com/image/info8/c01b023a06da469c9db6594ab0cdae0c.jpg)
基本的统计分析函数
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第111张图片](http://img.e-com-net.com/image/info8/7508f26220794a49b9a7222723aa0b28.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第112张图片](http://img.e-com-net.com/image/info8/8a352de12ba14be0999a88db8ab048ba.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第113张图片](http://img.e-com-net.com/image/info8/008acf69a30142499441caa4f67db831.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第114张图片](http://img.e-com-net.com/image/info8/14e167de05654b2488f4f0db0b7180d4.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第115张图片](http://img.e-com-net.com/image/info8/dcacd778ff5544c9b948358f7d6b3e5d.jpg)
累计统计分析
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第116张图片](http://img.e-com-net.com/image/info8/adee4914b03a4fb2957ded10f01dcb98.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第117张图片](http://img.e-com-net.com/image/info8/ade761528d87405dab8df4115f4b0440.jpg)
滚动计算(窗口计算)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第118张图片](http://img.e-com-net.com/image/info8/fe30ce3adc7e4c10af71a1ab31809425.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第119张图片](http://img.e-com-net.com/image/info8/6a6eaabf3b504644a6d582412a9b55aa.jpg)
数据的相关分析
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第120张图片](http://img.e-com-net.com/image/info8/5580fbff1de64e2196c1c0ff0e4f3f53.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第121张图片](http://img.e-com-net.com/image/info8/5d371a3c28d34706a364dec6e4029865.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第122张图片](http://img.e-com-net.com/image/info8/6eb41e228d0d4b3eba5526863198e4de.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第123张图片](http://img.e-com-net.com/image/info8/b9ddb0b2101d4e40bf185b00a8ad4d9e.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第124张图片](http://img.e-com-net.com/image/info8/b9cfd830ae874f32b2cba2c9f4a153b0.jpg)
![python数据分析与展示 嵩天_[Python学习笔记]Python数据分析与展示(北理工 嵩天)-站长资讯中心..._第125张图片](http://img.e-com-net.com/image/info8/de1099d13bf04158a655caab4bce9c5a.jpg)
版权申明:本站文章部分自网络,如有侵权,请联系:[email protected]
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有