Pytorch 实践 —— 乳腺癌预测

欢迎关注 “小白玩转Python”,发现更多 “有趣”
1. 数据集
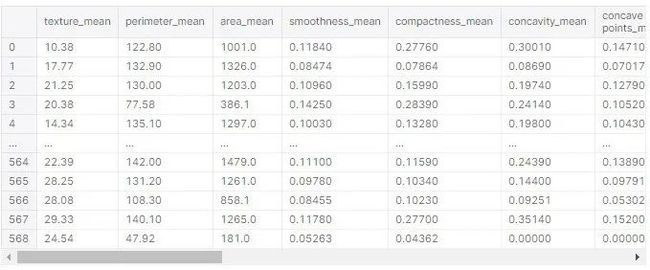
检测乳腺癌一般有30项特征,加载数据集来了解一下这些特征变量:

数据的尺寸

变量及其类型
在检查重复数据和空数据并确认数据集不受此限制之后,是时候检查不必要的数据了。从数据集的33列中,id 和 Unnamed:32 被删除了:
df.drop(['id','Unnamed: 32'],axis=1,inplace=True)
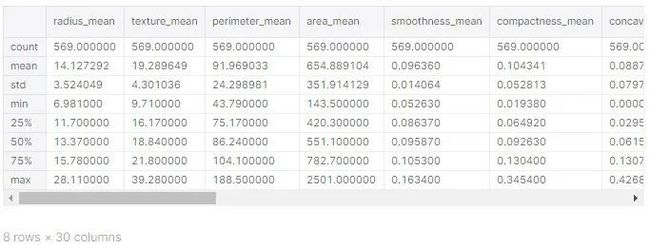
完成第一部分,用 .describe() 函数来了解统计学:
2. 可视化
检查良恶性肿瘤的数量:
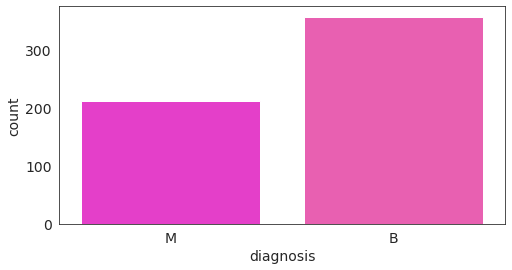
有357例良性肿瘤诊断和212例恶性肿瘤诊断,这似乎是一个相当平衡的数据集。
现在可视化其他变量的分布:
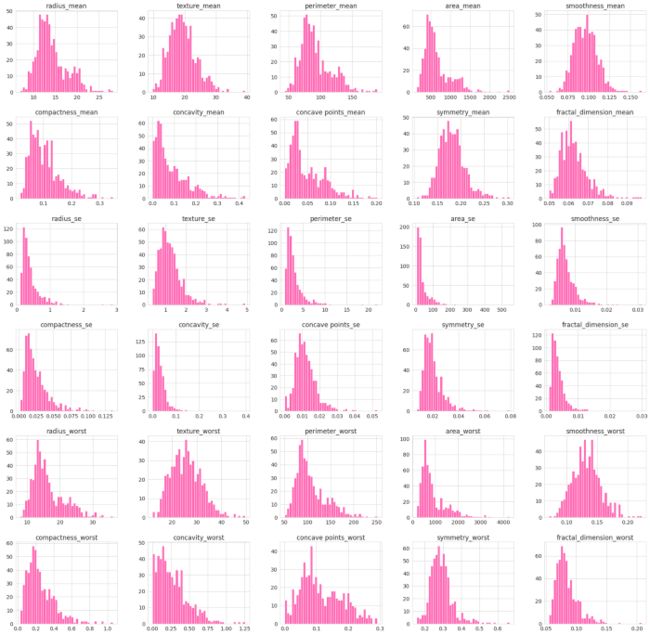
每个变量的分布

变量之间的相关性
从上面的数据情况我们可以得到以下的结论:
这是一个相当复杂的模型,能够可视化的相关性
肿瘤平均半径为14.12,最小为6.98,最大为28.11
维度相关的变量是正相关的(例如 area_se 和 perimeter_se)
数据集中62.7% 的肿瘤是良性的,37.3% 是恶性的
3. 为机器学习准备数据
更换标签
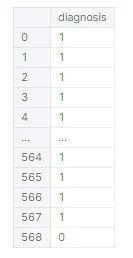
我们想要预测的数值在“diagnosis”一栏中ーー这些是标签。我们想预测一个肿瘤是恶性的(M)还是良性的(B)。数据框架中的所有其他列都是模型的预测变量:
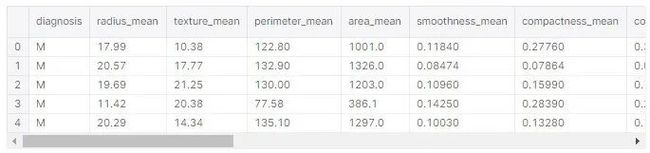
标签由字母 M(恶性)和 B(良性)表示。第一步是将这些信息转换成数值型的数据,良性的数据为0,恶性的数据为1:
lab ={'B':0,'M':1}
df = df.replace({'diagnosis':lab})
df.head()

现在,数据可以分为两个部分:
预测变量:我们将提供的数据作为模型的输入,以作出预测
predictors = df.iloc[:, 2:31]
predictors
标签:我们要预测的信息,即根据预测数据集中的信息,预测该肿瘤是恶性的还是良性的
labels = df.iloc[:, 0:1]
labels
转换为张量,并将数据分割为训练和测试子集
使用 scikit learn 库,使用20% 的比例将数据集分成训练和测试数据:
predictors_train, predictors_test, labels_train, labels_test = train_test_split(predictors,labels,test_size = 0.20)
到目前为止,这些数据都存储在 pandas 的数据帧中。由于我们将使用张量流来实现深度学习模型,因此必须将数据转换为张量。首先,将 pandas 数据帧转换为数组:
type(np.array(predictors_train))
Out[20]:
type(np.array(labels_train))
Out[21]:
numpy.ndarray
该模型将使用 PyTorch 实现,因此下一步是将该数组转换为一个 torch 元素:
predictors_train = torch.tensor(np.array(predictors_train), dtype=torch.float)
labels_train = torch.tensor(np.array(labels_train), dtype = torch.float)
df_tf = torch.utils.data.TensorDataset(predictors_train, labels_train)
type(df_tf)
Pytorch 对模型进行了小批量的训练。有一个名为 DataLoader 的类用于在数据集上执行迭代。批量大小参数给出了在调整模型权重时考虑的样本数:
train_loader = torch.utils.data.DataLoader(df_tf, batch_size=15, shuffle=True)
4. 模型的实现与评估
在本项目中,将实现一个具有两个隐藏层的神经网络。要实现这个模型,我们需要:
定义模型的结构(定义层数,神经元,激活函数)
选择一个训练策略
选择一个优化器
由于问题的复杂性和未知性,这种类型的实现被建模为一个最佳化问题。因此,选择一个优化器是整个过程的一部分。
在最佳化问题中,我们有目标函数(称为成本函数或损失函数)。这就是我们要优化的函数。在神经网络的目标是最小化的误差,因此最小化的损失(或成本)函数。
构建模型
神经网络模型的定义如下:
classifier = nn.Sequential(
nn.Linear(in_features=29, out_features=15),
nn.ReLU(),
nn.Linear(15, 15),
nn.ReLU(),
nn.Linear(15, 1),
nn.Sigmoid()
)
Input features = 29(我们在预测数据集中有29个特性)
2个隐藏层,每层有15个神经元
输出层有一个神经元,输出标记0(良性肿瘤)和1(恶性肿瘤)
ReLu:内部层的非线性激活函数
Sigmoid:输出层的非线性激活函数,返回的概率介于0和1之间
ReLu 是一种非线性激活函数,它的优点是不会同时激活所有的神经元。ReLu 被选中做第一次尝试,以建立更有效的计算成本方面的模型。
据报道,Sigmoid 在分类问题上效果很好。因为我们有一个输出层分类肿瘤良性或恶性,Sigmoid 被选为激活函数。
训练策略
现在,我们必须选择神经网络的训练策略。由于这是一个二元分类任务,选择二元交叉熵准则是:
criterion = nn.BCELoss()
优化器
第三步,也是最后一步:选择优化器。Adam 优化算法是深度学习问题中一种非常流行的选择算法。这是随机梯度下降算法的扩展,但与 SGD 算法不同,Adam 优化器在训练期间并不保持相同的学习速率。
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001, weight_decay=0.0001)
训练模型
更新后的权重将运行100次,如下面的 for 循环所示:
for epoch in range(100):
#To store the error:
run_loss = 0.
for data in train_loader:
inputs, labels = data
optimizer.zero_grad()
outputs = classifier(inputs) error = criterion(outputs, labels)
error.backward()
optimizer.step()
run_loss += error.item()
print('Epoch %3d: loss %.5f' % (epoch+1, run_loss/len(train_loader)))
训练数据加载器将训练数据分批加载(这个模型选择的批量大小是15个样本)
zero_grad() 在反向传播过程之前,将梯度设置为零
outputs 计算对模型的预测
error 计算出计算中的误差,并将预测结果与实际数据进行比较
error.backward() 是神经网络中的反向传播过程来更新权值
optimizer.step() 更新权重
评估模型
这个模型的准确率达到了94.73% ,在我们的混淆矩阵中可以看到这一点:
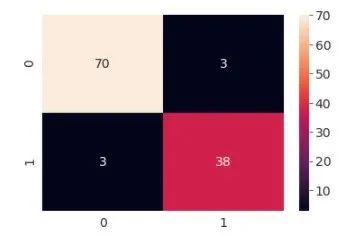
分类器总共做出了114个预测,从中可以看出:
70例标本被正确估计为良性肿瘤
38例标本正确诊断为恶性肿瘤
有3个样本被估计为假阴性,这些应该被分类为恶性肿瘤,但被分类为良性
3个样本被估计为假阳性
· END ·
HAPPY LIFE
