吴恩达机器学习课后作业5——怎么通过观察偏差和方差(bias vs variance)来调参
1. 问题和数据
在本练习中,您将实现正则化线性回归,并使用它来研究具有不同偏差-方差特性的模型。
在练习的前半部分,您将实现正则化线性回归,利用水库水位的变化来预测从大坝流出的水量。在后半部分中,您将对调试学习算法进行一些诊断,并检查偏差和偏差的影响。
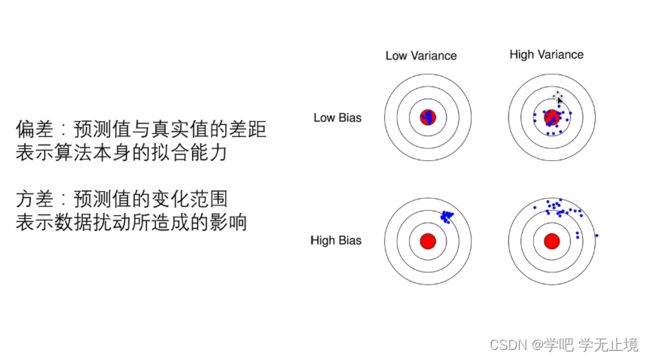
之前的题目中我们只用到了训练集,用训练集来训练模型,又用训练集来验证模型,这样的泛化能力就比较差。
正常做法一般是先用训练集进行模型训练,训练好几个模型;然后用验证集来验证哪个模型效果好,选择好的模型并进行优化;最后是通过测试集对优化好的模型来进行最终的测试。
其实感觉可以一直重复,如果测试集效果不好那就再优化,再用新的测试集来测试,然后一直循环下去。主要思想是要将数据切割成好几份,保证在不同情况下用的数据不一样,相当于学生(模型)平时做的练习题(训练集)、测验(验证集)、高考(测试集)不能一模一样。

2. 解决步骤与分析
导入包,numpy和pandas是做运算的库,matplotlib是画图的库。
数据集是在MATLAB的格式,所以要加载它在Python,我们需要使用一个SciPy工具。

import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
from scipy.optimize import minimize
导入数据集
data = loadmat('ex5data1.mat')
再取出X和y,给X插入一列,打印X的shape出来看一看
data.keys()
print("data.keys():", data.keys()) # 'X', 'y'为训练集; 'Xtest', 'ytest'为测试集;'Xval', 'yval'为验证集
输出结果:
data.keys(): dict_keys(['__header__', '__version__', '__globals__', 'X', 'y', 'Xtest', 'ytest', 'Xval', 'yval'])
指定训练集
X_train, y_train = data['X'], data['y']
print("X_train.shape, y_train.shape:", X_train.shape, y_train.shape)
输出shape
X_train.shape, y_train.shape: (12, 1) (12, 1)
指定验证集
X_val, y_val = data['Xval'], data['yval']
print("X_val.shape, y_val.shape:", X_val.shape, y_val.shape)
输出shape
X_val.shape, y_val.shape: (21, 1) (21, 1)
指定测试集
X_test, y_test = data['Xtest'], data['ytest']
print("X_test.shape, y_test.shape:", X_test.shape, y_test.shape)
输出shape
X_test.shape, y_test.shape: (21, 1) (21, 1)
给每一种数据集前面都插入一列名字为X_…,index为0,值全是1,axis=1表示为列
X_train = np.insert(X_train, 0, 1, axis=1)
X_val = np.insert(X_val, 0, 1, axis=1)
X_test = np.insert(X_test, 0, 1, axis=1)
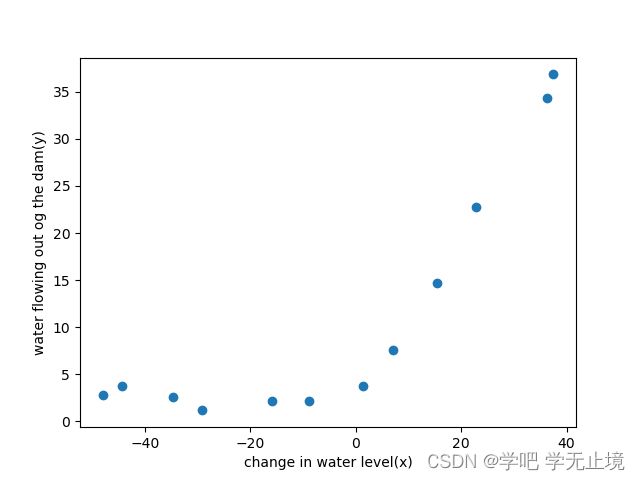
把X_train画出来看看
def plot_data():
fig, ax = plt.subplots()
ax.scatter(X_train[:, 1], y_train)
ax.set(xlabel='change in water level(x)', ylabel='water flowing out og the dam(y)')
plot.data()
公式和以前一样:

定义成本函数
def reg_cost(theta, X, y, lamda):
cost = np.sum(np.power((X @ theta - y.flatten()), 2))
reg = theta[1:]@theta[1:]*lamda # 因为j>=1,所以theta[0]不参与运算
return (cost + reg) / (2*len(X))
theta = np.ones(X_train.shape[1]) # 创造一个np.ones(数字)数字维数组,shape[1]表示输出列数
lamda = 1
print("reg_cost(theta, X_train, y_train, lamda):", reg_cost(theta, X_train, y_train, lamda))
输出:
reg_cost(theta, X_train, y_train, lamda): 303.9931922202643
定义梯度矩阵
def reg_gradient(theta, X, y, lamda):
grad = (X@theta - y.flatten()) @ X
reg = lamda * theta
reg[0] = 0 # 因为j>=1,所以第一列不参与运算,直接设置为0
return (grad + reg) / (len(X))
print("reg_gradient(theta, X_train, y_train, lamda):", reg_gradient(theta, X_train, y_train, lamda))
输出:
reg_gradient(theta, X_train, y_train, lamda): [-15.30301567 598.25074417]
定义训练模型
def train_model(X, y, lamda):
theta = np.ones(X.shape[1])
res = minimize(fun=reg_cost, # 要优化的函数
x0=theta, # 参数初始值,theta一开始是零数组
args=(X, y, lamda),
method='TNC', # 选择‘TNC’的优化方法,好像是牛顿迭代法,具体原理不用管
jac=reg_gradient) # 梯度向量
return res.x # res.x就是优化好的theta
theta_final = train_model(X_train, y_train, lamda=0) # 因为目前只是线性模型,所以lamda=0,不会过拟合
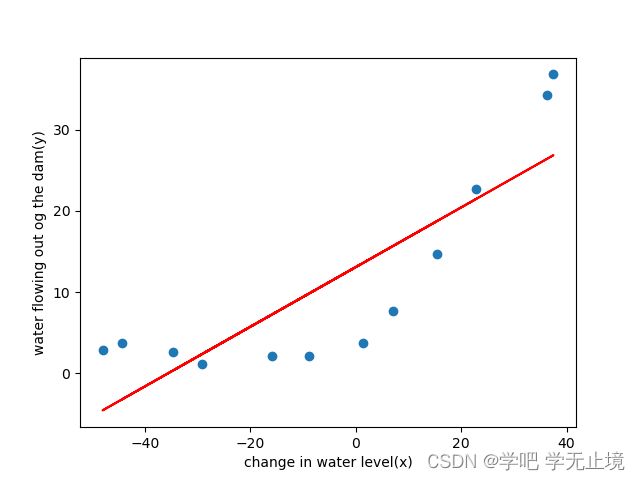
画出一次函数拟合图像
def plot_data():
fig, ax = plt.subplots()
ax.scatter(X_train[:, 1], y_train)
ax.set(xlabel='change in water level(x)', ylabel='water flowing out og the dam(y)')
plot.data()
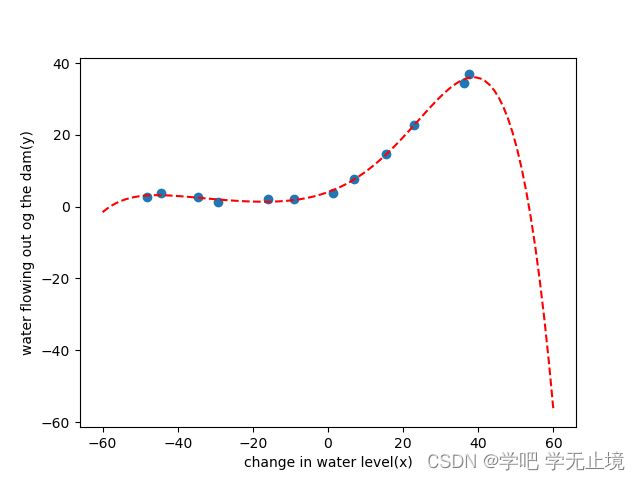
输出图像:
可以看出,明显欠拟合了,很多数据点离拟合的线段其实还是有不小差距。
画出随着样本数量增加,训练集成本和验证集成本的学习误差的曲线
def plot_learning_curve(X_train, y_train, X_val, y_val, lamda):
x = range(1, len(X_train)+1) # 取样本X_train
training_cost = [] # 用来存放训练集的损失函数
cv_cost = [] # 用来存放验证集的损失函数
for i in x: # 遍历样本X_train
res = train_model(X_train[:i, :], y_train[:i, :], lamda) # X_train和y_train都有取到i行
training_cost_i = reg_cost(res, X_train[:i, :], y_train[:i, :], lamda) # 计算取到i时的训练集成本
cv_cost_i = reg_cost(res, X_val, y_val, lamda) # 计算取到i时的验证集成本
training_cost.append(training_cost_i) # 追加到训练集成本的列表
cv_cost.append(cv_cost_i) # 追加到验证集成本的列表
plt.plot(x, training_cost, label='train cost')
plt.plot(x, cv_cost, label='cv cost')
plt.legend()
plt.xlabel('number of training examples')
plt.ylabel('error')
plt.show()
plot_learning_curve(X_train, y_train, X_val, y_val, lamda=0) # 调用画成本曲线的函数,lamda传0
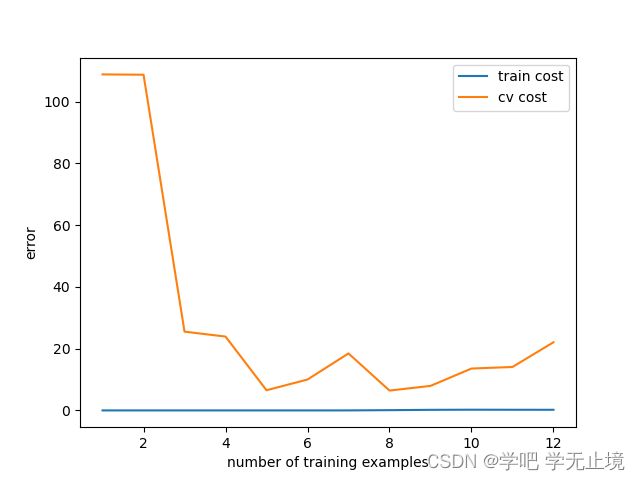
输出图像:
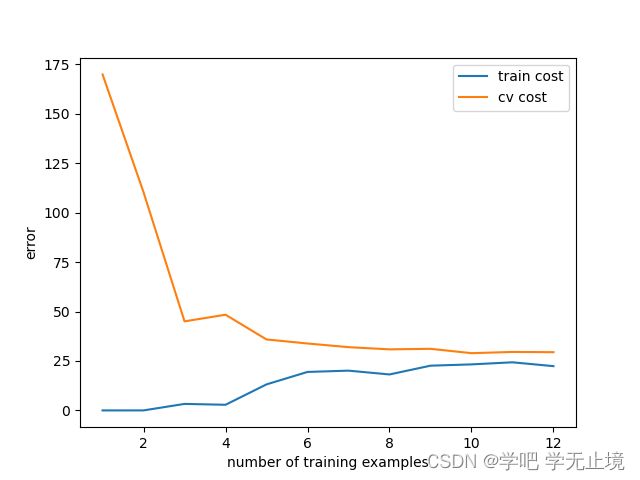
从图中可以看出,随着样本数量增加,训练集成本的误差逐渐升高,而验证集成本的误差逐渐下降。目前的训练集成本和验证集成本的误差都还比较大,属于高偏差模型,对应的模型问题就是欠拟合。
这与吴恩达机器学习课程里的知识点是对应的:
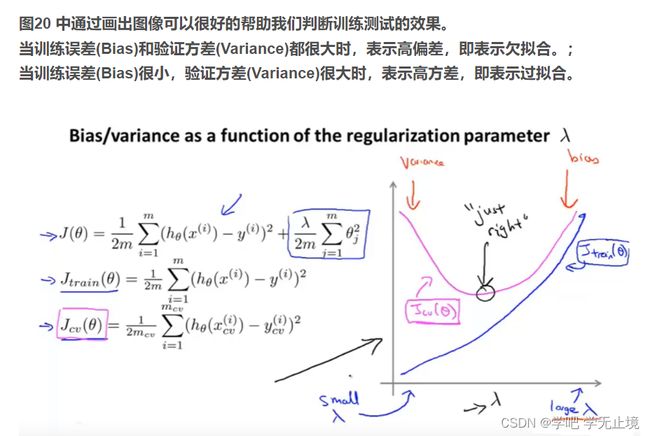
针对解决高偏差模型的过拟合问题,有几种方法:1.引入更多的相关特征 2.采用多项式特征 3.减小正则化参数theta
因为我目前没用theta,所以法3不可用;又因为只有一列特征X,所以法1也不可用;只能在法2上想办法

即构造多项式特征,将原本只有一列的特征x通过不断的次方,创造出多个特征。

# 构造多项式特征,进行多项式回归
def poly_feature(X, power):
for i in range(2, power+1): # 从2次开始取,最高取到power+1
X = np.insert(X, X.shape[1], np.power(X[:, 1], i), axis=1) # 插入一列名字为X,index为X.shape[1],值
# 是np.power(X[:, 1], i),axis = 1表示为列
return X
# 获取均值,方差
def get_means_stds(X):
means = np.mean(X, axis=0) # 对数据X,按行去获取均值
stds = np.std(X, axis=0) # 对数据X,按行去获取方差
return means, stds
# 构造正规化函数,相当于把训练集验证集和测试集的数据都通过减去X的平均值再除以标准差,来处理一遍数据
def feature_normalize(X, means, stds):
X[:, 1:] = (X[:, 1:] - means[1:]) / stds[1:] # 第一列都不取
return X
# 调用构造多项式特征函数,分别对训练集、测试集和验证集进行多项式特征构造
power =6
X_train_poly = poly_feature(X_train, power)
X_val_poly = poly_feature(X_val, power)
X_test_poly = poly_feature(X_test, power)
train_means, train_stds = get_means_stds(X_train_poly) # 获取train_ploy的平均
X_train_norm = feature_normalize(X_train_poly, train_means, train_stds) # 进行正规化
X_val_norm = feature_normalize(X_val_poly, train_means, train_stds)
X_test_norm = feature_normalize(X_test_poly, train_means, train_stds)
theta_fit = train_model(X_train_norm, y_train, lamda=0) # 将正规化处理后的X数据集X_train_norm代入训练模型,得到训练后的theta_fit
# ---------------------------
# ---------------------------
# 画出加入特征多项式后的拟合图像
def plot_poly_fit():
plot_data()
x = np.linspace(-60, 60, 100) # (-60,60)的区间是观察之间打印的图来估计的范围
xx = x.reshape(100, 1)
xx = np.insert(xx, 0, 1, axis=1) # 插入一列名字为XX,index为0,值是1,axis = 1表示为列
xx = poly_feature(xx, power)
xx = feature_normalize(xx, train_means, train_stds)
plt.plot(x, xx@theta_fit, 'r--') # 将横坐标x与代入xx(比x多一列全是1)到原目标函数得出的纵坐标画出来,r--是红色的虚线的意思
plt.show()
plot_poly_fit() # 画出新的拟合图像
看起来是拟合得很好,但这只是针对我们的训练集。
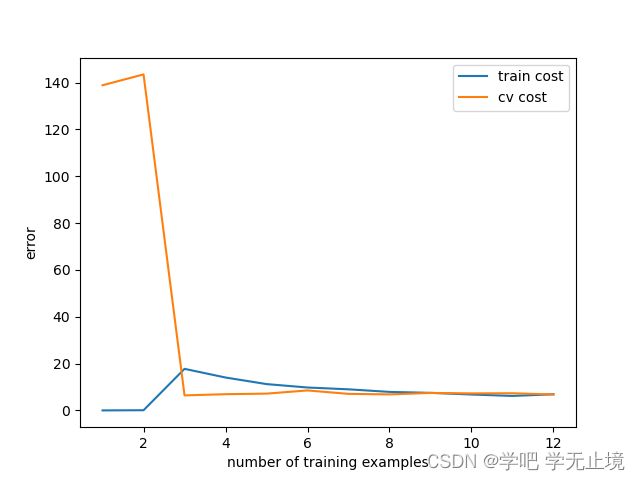
通过画出学习曲线的误差函数,来看出它在训练集和验证集上的表现
plot_learning_curve(X_train_norm, y_train, X_val_norm, y_val, lamda=0)
可以看出训练集的误差几乎为0,而验证集的误差还比较高,这表示目前模型状态为高方差,表现为过拟合。
使用正则化是解决过拟合的好办法。通过使用lamda,将它从0变成1,即为开启正则化。
plot_learning_curve(X_train_norm, y_train, X_val_norm, y_val, lamda=1)
画出使用正则化之后的学习曲线误差函数。可以看出,此时训练集的误差仍然很低,但不是0了,而验证集的误差也降低到一个很低的状态。
同样,我们可以来试试把lamda调整为很大时,这时训练集和验证集的误差会很接近,但是都会很大,此时是欠拟合的状态,也是不好的。
# 调整lamda为100来看看,正则化很大,欠拟合
plot_learning_curve(X_train_norm, y_train, X_val_norm, y_val, lamda=100) # lamda太大时容易发生欠拟合
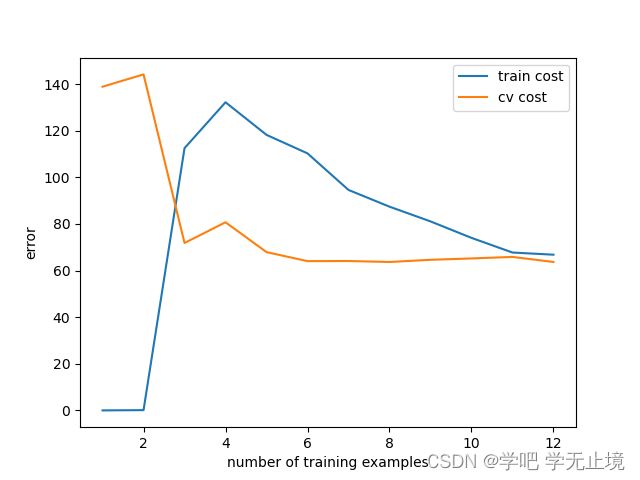
那lamda应该要取多少才合适呢,下面进行正则化参数lamda值的选取
lamdas = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]
training_cost = []
cv_cost = []
for lamda in lamdas:
res = train_model(X_train_norm, y_train, lamda)
tc = reg_cost(res, X_train_norm, y_train, lamda=0) # 这里的lamda还是0,因为调用的reg_cost这一步还没有正则化,后面才用的
cv = reg_cost(res, X_val_norm, y_val, lamda=0) # 这里的lamda还是0,因为调用的reg_cost这一步还没有正则化,后面才用的
training_cost.append(tc)
cv_cost.append(cv)
plt.plot(lamdas, training_cost, label='training cost') # x轴是lamdas, y轴是training_cost,标签为training cost
plt.plot(lamdas, cv_cost, label='cv cost') # x轴是lamdas, y轴是training_cost,标签为training cost
plt.legend()
plt.show()
画出的图像:
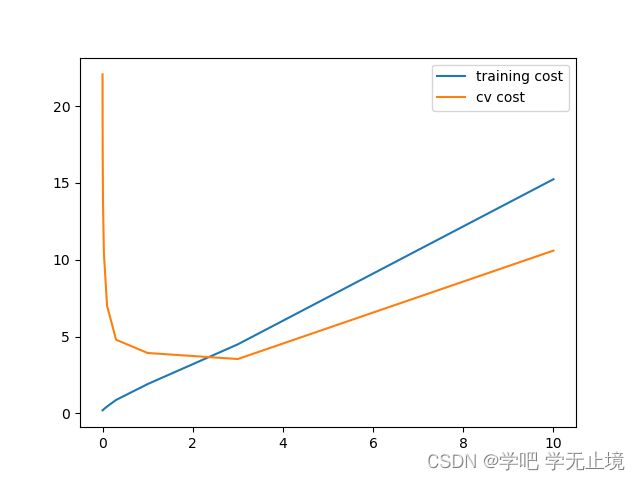
从图中可以看出lamda=2~4之间时的cv cost最小
找出最小的cv_cost对应的lamda
print('lamdas[np.argmin(cv_cost):', lamdas[np.argmin(cv_cost)])
输出最小的cv_cost对应的lamda
lamdas[np.argmin(cv_cost): 3
将最优结果代回原目标函数:
res = train_model(X_train_norm, y_train, lamda=3) # 将lamda=3,X_train_norm代入训练模型中,得到最优结果
print('res:', res)
test_cost = reg_cost(res, X_test_norm, y_test, lamda=0) # 再将最优的结果res和X_test_norm代入测试集,得到对测试集的成本值结果
print('test_cost:', test_cost)
对测试集的最终结果是4.3976161577441975
test_cost: 4.3976161577441975
3.完整代码
# -*- coding: utf-8 -*-
"""
Created on Sat June 11 10:14:26 2022
@author: wzj
python version: python 3.9
Title: 了解算法性能中偏差和方差(bias vs variance)的概念
案例:利用水库水位变化预测大坝出水量(带正则化的线性回归)
数据集:数据文件是ex5data1.mat
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
from scipy.optimize import minimize
data = loadmat('ex5data1.mat')
data.keys()
print("data.keys():", data.keys()) # 'X', 'y'为训练集; 'Xtest', 'ytest'为测试集;'Xval', 'yval'为验证集
# 训练集
X_train, y_train = data['X'], data['y']
print("X_train.shape, y_train.shape:", X_train.shape, y_train.shape)
# 验证集
X_val, y_val = data['Xval'], data['yval']
print("X_val.shape, y_val.shape:", X_val.shape, y_val.shape)
# 测试集
X_test, y_test = data['Xtest'], data['ytest']
print("X_test.shape, y_test.shape:", X_test.shape, y_test.shape)
# 给每一种数据集前面都插入一列名字为X_...,index为0,值全是1,axis=1表示为列
X_train = np.insert(X_train, 0, 1, axis=1)
X_val = np.insert(X_val, 0, 1, axis=1)
X_test = np.insert(X_test, 0, 1, axis=1)
# 把X_train画出来看看
def plot_data():
fig, ax = plt.subplots()
ax.scatter(X_train[:, 1], y_train)
ax.set(xlabel='change in water level(x)', ylabel='water flowing out og the dam(y)')
plot_data()
# 可以看出,明显欠拟合了,很多数据点离拟合的线段其实还是有不小差距
# ---------------------------
# ---------------------------
# 定义成本函数
def reg_cost(theta, X, y, lamda):
cost = np.sum(np.power((X @ theta - y.flatten()), 2))
reg = theta[1:]@theta[1:]*lamda # 因为j>=1,所以theta[0]不参与运算
return (cost + reg) / (2*len(X))
theta = np.ones(X_train.shape[1]) # 创造一个np.ones(数字)数字维数组,shape[1]表示输出列数
lamda = 1
print("reg_cost(theta, X_train, y_train, lamda):", reg_cost(theta, X_train, y_train, lamda))
# ---------------------------
# ---------------------------
# 定义梯度矩阵
def reg_gradient(theta, X, y, lamda):
grad = (X@theta - y.flatten()) @ X
reg = lamda * theta
reg[0] = 0 # 因为j>=1,所以第一列不参与运算,直接设置为0
return (grad + reg) / (len(X))
print("reg_gradient(theta, X_train, y_train, lamda):", reg_gradient(theta, X_train, y_train, lamda))
# ---------------------------
# ---------------------------
# 定义训练模型
def train_model(X, y, lamda):
theta = np.ones(X.shape[1])
res = minimize(fun=reg_cost, # 要优化的函数
x0=theta, # 参数初始值,theta一开始是零数组
args=(X, y, lamda),
method='TNC', # 选择‘TNC’的优化方法,好像是牛顿迭代法,具体原理不用管
jac=reg_gradient) # 梯度向量
return res.x # res.x就是优化好的theta
theta_final = train_model(X_train, y_train, lamda=0) # 因为目前只是线性模型,所以lamda=0,不会过拟合
# 画出一次函数拟合图像
plot_data()
# print("X_train[:, 1].shape:", X_train[:, 1].shape)
# print("X_train.shape:", X_train.shape)
# print("theta_final:", theta_final.shape)
plt.plot(X_train[:, 1], X_train@theta_final, c='r')
plt.show()
print('len(X_train):', len(X_train))
# ---------------------------
# ---------------------------
# 画出随着样本数量增加,训练集成本和验证集成本的学习误差的曲线
def plot_learning_curve(X_train, y_train, X_val, y_val, lamda):
x = range(1, len(X_train)+1) # 取样本X_train
training_cost = [] # 用来存放训练集的损失函数
cv_cost = [] # 用来存放验证集的损失函数
for i in x: # 遍历样本X_train
res = train_model(X_train[:i, :], y_train[:i, :], lamda) # X_train和y_train都有取到i行
training_cost_i = reg_cost(res, X_train[:i, :], y_train[:i, :], lamda) # 计算取到i时的训练集成本
cv_cost_i = reg_cost(res, X_val, y_val, lamda) # 计算取到i时的验证集成本
training_cost.append(training_cost_i) # 追加到训练集成本的列表
cv_cost.append(cv_cost_i) # 追加到验证集成本的列表
plt.plot(x, training_cost, label='train cost')
plt.plot(x, cv_cost, label='cv cost')
plt.legend()
plt.xlabel('number of training examples')
plt.ylabel('error')
plt.show()
plot_learning_curve(X_train, y_train, X_val, y_val, lamda=0) # 调用画成本曲线的函数,lamda传0
# 从图中可以看出,随着样本数量增加,训练集成本的误差逐渐升高,而验证集成本的误差逐渐下降。目前的训练集成本和验证集成本的误差都还比较大,属于高偏
# 差模型,对应的模型问题就是欠拟合
# ---------------------------
# ---------------------------
# 针对解决高偏差模型的过拟合问题,有几种方法:1.引入更多的相关特征 2.采用多项式特征 3.减小正则化参数theta
# 因为我目前没用theta,所以法3不可用;又因为只有一列特征X,所以法1也不可用;只能在法2上想办法
# 构造多项式特征,进行多项式回归
def poly_feature(X, power):
for i in range(2, power+1): # 从2次开始取,最高取到power+1
X = np.insert(X, X.shape[1], np.power(X[:, 1], i), axis=1) # 插入一列名字为X,index为X.shape[1],值
# 是np.power(X[:, 1], i),axis = 1表示为列
return X
# 获取均值,方差
def get_means_stds(X):
means = np.mean(X, axis=0) # 对数据X,按行去获取均值
stds = np.std(X, axis=0) # 对数据X,按行去获取方差
return means, stds
# 构造正规化函数,相当于把训练集验证集和测试集的数据都通过减去X的平均值再除以标准差,来处理一遍数据
def feature_normalize(X, means, stds):
X[:, 1:] = (X[:, 1:] - means[1:]) / stds[1:] # 第一列都不取
return X
# 调用构造多项式特征函数,分别对训练集、测试集和验证集进行多项式特征构造
power =6
X_train_poly = poly_feature(X_train, power)
X_val_poly = poly_feature(X_val, power)
X_test_poly = poly_feature(X_test, power)
train_means, train_stds = get_means_stds(X_train_poly) # 获取train_ploy的平均
X_train_norm = feature_normalize(X_train_poly, train_means, train_stds) # 进行正规化
X_val_norm = feature_normalize(X_val_poly, train_means, train_stds)
X_test_norm = feature_normalize(X_test_poly, train_means, train_stds)
theta_fit = train_model(X_train_norm, y_train, lamda=0) # 将正规化处理后的X数据集X_train_norm代入训练模型,得到训练后的theta_fit
# ---------------------------
# ---------------------------
# 画出加入特征多项式后的拟合图像
def plot_poly_fit():
plot_data()
x = np.linspace(-60, 60, 100) # (-60,60)的区间是观察之间打印的图来估计的范围,取100个值作为x
xx = x.reshape(100, 1) # 将取的x再reshape为(100,1),成xx
xx = np.insert(xx, 0, 1, axis=1) # 插入一列名字为XX,index为0,值是1,axis = 1表示为列
xx = poly_feature(xx, power) # 调用poly_feature函数,将xx增加特征多项式
xx = feature_normalize(xx, train_means, train_stds)
plt.plot(x, xx@theta_fit, 'r--') # 将横坐标x与代入xx(比x多一列全是1)到原目标函数得出的纵坐标画出来,r--是红色的虚线的意思
plt.show()
plot_poly_fit() # 画出新的拟合图像
# 通过画出学习曲线的误差函数,来看出它在训练集和验证集上的表现为过拟合
plot_learning_curve(X_train_norm, y_train, X_val_norm, y_val, lamda=0)
# 使用正则化是解决过拟合的好办法。通过使用lamda,将它从0变成1,即为开启正则化
plot_learning_curve(X_train_norm, y_train, X_val_norm, y_val, lamda=1) # 画出使用正则化之后的学习曲线误差函数
# 调整lamda为100来看看,正则化很大,欠拟合
plot_learning_curve(X_train_norm, y_train, X_val_norm, y_val, lamda=100) # lamda太大时容易发生欠拟合
# ---------------------------
# ---------------------------
# 那lamda应该要取多少才合适呢,下面进行正则化参数lamda值的选取
lamdas = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]
training_cost = []
cv_cost = []
for lamda in lamdas:
res = train_model(X_train_norm, y_train, lamda)
tc = reg_cost(res, X_train_norm, y_train, lamda=0) # 这里的lamda还是0,因为调用的reg_cost这一步还没有正则化,后面才用的
cv = reg_cost(res, X_val_norm, y_val, lamda=0) # 这里的lamda还是0,因为调用的reg_cost这一步还没有正则化,后面才用的
training_cost.append(tc)
cv_cost.append(cv)
plt.plot(lamdas, training_cost, label='training cost') # x轴是lamdas, y轴是training_cost,标签为training cost
plt.plot(lamdas, cv_cost, label='cv cost') # x轴是lamdas, y轴是training_cost,标签为training cost
plt.legend()
plt.show()
# 从图中可以看出lamda=2~4之间时的cv cost最小
print('lamdas[np.argmin(cv_cost):', lamdas[np.argmin(cv_cost)]) # 找出最小的cv_cost对应的lamda
res = train_model(X_train_norm, y_train, lamda=3) # 将lamda=3,X_train_norm代入训练模型中,得到最优结果
print('res:', res)
test_cost = reg_cost(res, X_test_norm, y_test, lamda=0) # 再将最优的结果res和X_test_norm代入测试集,得到对测试集的成本值结果
print('test_cost:', test_cost) # 对测试集的最终结果是4.3976161577441975
参考文献:
[1] https://www.bilibili.com/video/BV1p4411o7sq?p=6&spm_id_from=pageDriver&vd_source=72e4369cf6b54497a1e04f2071a47a1e