立体匹配论文笔记(11.5~11.12)
这里写目录标题
- 1.《HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching》CVPR2021
-
- 术语
- 论文理解
- 可取之点
- 2.《SMD-Nets: Stereo Mixture Density Networks》CVPR2021
-
- 术语
- 论文理解
- 可取之处
- 3.《A Decomposition Model for Stereo Matching》CVPR 2021
-
- 术语
- 论文理解
- 可取之处
- 4.《Learning Stereo from Single Images》ECCV 2020
-
- 术语
- 论文理解
- 可取之处
1.《HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching》CVPR2021
术语
end-to-end learning
代价立方体
可微分
2D几何传播
翘曲机制
image tai
前向平行tile假设
leaky Relu
匹配的代价
warp
title:平面
视差
视差梯度
置信度
法线估计的结果图
resolution:分辨率
论文理解
痛点:立体匹配研究集中于:研究准确性(基于3D卷积的立体匹配网络),但是主要局限就是运算速度慢。
主要思想:
没有明确构建代价立方体,而是依赖于快速的多分辨初始化步骤,可微分的2D几何传播和翘曲机制来推断出视差假设;将image tail表示为具有学习紧凑特征表征描述符的平面块。
为了实现高度的精度,该网络不仅是在几何方面得到视差信息,而且还推断倾斜平面假设,从而允许更准确地执行几何扭曲和上采样操作。
该架构本质上是多分辨率的,允许信息跨不同级别传播。
Introduction:
下采样的成本量可以在速度和准确性之间提供一个合理的折衷。然而,对成本量进行下采样是以牺牲准确性为代价的。
最近出现的提升效率的高精度视差预估方案(未融入端对端网络):首先,使用紧凑/稀疏特征进行快速高分辨率匹配成本计算;其次,非常有效的视差优化方案,不依赖于全部成本量;第三,使用倾斜平面的迭代图像扭曲来实现高精度最小化图像差异。所有这些设计选择都是在没有明确操作全3D成本的情况下使用的。
提出HITNet: 通过将图像扭曲、空间传播和快速高分辨率初始化步骤集成到网络架构中,克服了在3D体积上操作的计算缺点,同时保持学习特征的灵活性。
方法:

首先给出tile的描述方式,类似于图片中每个点的特征,每个tile也有一个特征描述。这个描述由两部分组成,分别为表达几何信息的平面描述和通过网络学习到的特征描述。
如下,为tile的视差, [公式] 和 [公式] 分别为视差的水平梯度和竖直梯度,这三个量可以定义一个视差平面。
 d x 和 d y 分 别 为 视 差 的 水 平 梯 度 和 竖 直 梯 度 , 这 三 个 量 可 以 定 义 到 一 个 视 差 平 面 d_x和d_y分别为视差的水平梯度和竖直梯度,这三个量可以定义到一个视差平面 dx和dy分别为视差的水平梯度和竖直梯度,这三个量可以定义到一个视差平面
d x 和 d y 分 别 为 视 差 的 水 平 梯 度 和 竖 直 梯 度 , 这 三 个 量 可 以 定 义 到 一 个 视 差 平 面 d_x和d_y分别为视差的水平梯度和竖直梯度,这三个量可以定义到一个视差平面 dx和dy分别为视差的水平梯度和竖直梯度,这三个量可以定义到一个视差平面
所以整个方法的流程就是对title的视差逐级调优,最终获得视差结果。
一个title代表的是原图像4*4的一个窗口。
既然要逐级调优,首先要有一个初始化。每个tile初始的视差来自暴力匹配。假设我们现在有了来自于U-Net提取的左右图特征,分辨率为H * W。
初始化阶段 :
目标:在不同分辨率下提取每个分块的初始视差数据d和特征向量P
输出:前向平行tile假设
这个描述由两部分组成,分别为表达几何信息的平面描述和通过网络学习的特征描述。
为了保持较高的初始视差分辨率:(注意区别空间分辨率,视差高分辨意味着有着更多的视差等级)
右(次)图像中沿x方向(即宽度)使用重叠的tile
在左(参考)图像中仍使用非重叠的tile以进行有效的匹配
提取tile特征
对每个提取的特征地图eL使用4*4卷积。
左(参考)图像和右(次)图像的步长不同
左边的图像,采用步长4 * 4的卷积得到(H/4) * (W/4)的用于匹配的特征,
对于右图则采用4 * 1的卷积得到(H/4) * W的特征。
这样,以左图为参考进行匹配时,在右图中搜寻的待匹配点就更多了,也即所谓的视差有较高分辨率。
这个卷积之后是一个leaky Relu和一个1×1的卷积
该步骤的输出是一系列拥有每一tile特征的新特征图,左右特征图的宽度此时已不相同。
我们将直接找到L1距离最近的两个点作为匹配点,计算水平坐标之差得到视差。
视差梯度的初始化为0.
描述向量的初始化会通过额外的感知机学习得到,这部分得输入包括用于匹配的左图特征和匹配的代价。
Propagation
在初始化时,我们知道每个tile代表原特征图的一个4 * 4的窗口(?)
tile算出4*4窗口内每个点的视差:
根据视差和梯度,利用title(代表原特征图的一个4 * 4的窗口)算出这个窗口内的视差
计算warp的误差:
利用视差,对特征图进行wrap,可以计算wrap的误差
每个title的点会有16个warp误差,对应4*4窗口的每个点。
这个误差向量会用于更新title的表示
构建cost volume:
不仅用title的d视差wrap,也用d-1和d+1的视差进行wrap。用于更新tile表示的全部特征为:
 更新就是用网络学习,将输出h的残差Δh,和一个额外的置信度w。
更新就是用网络学习,将输出h的残差Δh,和一个额外的置信度w。
如下图。 U为更新模块网络。这里的 [公式] 表示尺度(请参照上网络图,即每个空间分辨率)

我们看到有个 n。他代表可能的tile假设个数。
在最低分辨率,只有一个初始化的title假设,在更高分辨率,拥有初始化的title和来自前一分辨率上采样的title两个title。
两个title将利用预测的置信度进行选择。
得到最高分辨率的title之后,我们知道这里的每个title表示的是原特征44的窗口,随后将再次进行3次更新,从代表44的窗口到22的窗口到11的窗口,title逐渐从对应一个视差平面到对应一个原图像素点,也逐渐实现了视差的细化。
损失函数
约束初始视差估计的对比损失
约束title视差参数的损失(既约束title中的视差,又约束title中的视差梯度,还涉及置信度的约束)
实验结果:
主要是这个预测的倾斜平面,还是能反映一些信息的。这个图感觉和法线估计的结果图很像,说明预测的tile还是很好地拟合了真实的视差平面。
可取之点
-
多尺度(下采样、上采样(Unet))
- 相关多尺度论文:19年的H3D、AnyNet
-
将视差表示为小的平面(4*4?)
- 给平面配备了特征使其在多尺度网络中逐级调优
- 实现了对真实世界中倾斜视差平面的建模
2.《SMD-Nets: Stereo Mixture Density Networks》CVPR2021
术语
代价聚合
D维
双线性插值
多层感知机head
双峰的拉普拉斯分布
最大似然损失LLLS
真值分布
论文理解
痛点:
恢复尖锐边界和高分辨率输出
本文提出:
立体混合密度网络:
利用双峰混合密度作为输出表示,并表明这允许
- 在不连续点附近进行清晰而精确的视差估计
- 对观测中固有的任意不确定性进行建模
估计锐利的边缘:
 图中横坐标是代表像素网格的一条水平线,纵坐标是视差值。
图中横坐标是代表像素网格的一条水平线,纵坐标是视差值。
理想情况下,视差应该有个锋利的跳变。但当前回归网络通常会将边界预测得平滑(如左图),而采取了混合分布的预测策略时,可以通过选择概率最大的视差值避免平滑。(右图中命名为μ的两条曲线分别建模了预测为背景、预测为前景的情况, Π是选择背景视差的概率)
将一个点的视差建模为一个双峰分布(b)
对于边缘处的点,代价聚合后的视差概率分布容易在前景视差值和背景视差值产生两个概率较大的峰。
本文:通过显示地建模这两个峰,
在测试阶段选择概率更高地那个,从而得到锐利地边缘。
获得更高分辨率地视差图
可以估计视差图中任意位置的视差值(打破了只能在规则的像素网格上获得视差的瓶颈)
对于输出视差图的每个点,利用插值找到对应的原图特征,再利用该特征预测视差。
方法:
SMD-Nets的设计模式
输入:左右图
输出:D维的特征图
- 对于输出视差图上的任意一点
- 利用双线性插值找到对应的D维特征
- 这个D维特征经过一个多层感知机预测5个参数
∏ , μ 1 , b 1 , μ 2 , , b 2 \prod, \mu1,b_{1}, \mu2,,b_{2} ∏,μ1,b1,μ2,,b2

训练阶段:采用真值分布和该分布的最大似然损失
测试阶段:直接选择概率最大的视差值
 首先使用卷积骨干(左)将立体对编码为特征图。
首先使用卷积骨干(左)将立体对编码为特征图。
接下来,通过多层感知器head估计任意连续2D位置的混合密度分布的参数
以双线性插值特征向量作为输入
由此,得到了视差和不确定性图(如下图)

如图为SMD-Nets的操作流程,Stereo Backbone可以是任意的匹配网络。
训练策略:从图像中采样N个点,预测该点的双峰拉普拉斯分布,再利用真值分布进行监督。这里采样时作者还专门在视差不连续处多采 了一些点
对输出图的任意位置预测视差
因为是通过插值找到对应的特征
 允许查询视差d在任何连续的 2D 像素位置,可实现具有清晰描绘的对象边界的超高分辨率预测,如上图所示:
允许查询视差d在任何连续的 2D 像素位置,可实现具有清晰描绘的对象边界的超高分辨率预测,如上图所示:
本文模型可以用较小分辨率的RGB图和较大分辨率的视差真值进行训练
提供了一个新的数据集:来印证Stereo Super-Resolution(而主流的数据集都是RGB和视差真值分辨率相同的)
损失函数
通过最小化负对数似然损失来训练我们的模型
结果;

可取之处
预测精确的深度边界
生成高分辨率输出
允许任意位置的视差预测
content-aware:一种动态的插值方法
3.《A Decomposition Model for Stereo Matching》CVPR 2021
术语
mask
cross-correlation:特征相似度
occlusion-aware soft mask
匹配代价
wrap
EPE:终点误差,以像素为单位的平均视差误差
3PX:异常值:视差误差>max(3px,0.05d*)的像素
ground truth:真值
论文理解
引言:
痛点:当前立体匹配模型在输入图像对分辨率比较高时要消耗大量的显存和运算时间。
核心:Decomplosition分解
在一张图中:
- 低分辨率:
一个较大平面内点的视差可以在低分辨率进行估计。
进行致密的匹配。
- 高分辨率:
细节点再高分辨上估计
进行稀疏的匹配 - 从而使模型处理大分辨率的图像。
属于coarse-to-fine方法
- 区别于之前的一些coarse-to-fine的方法(如StereoNet、AnyNet、CSN)
- 本文中,coarse区域和fine区域互不相交,同时二者互补,并集是整张图。
方法:
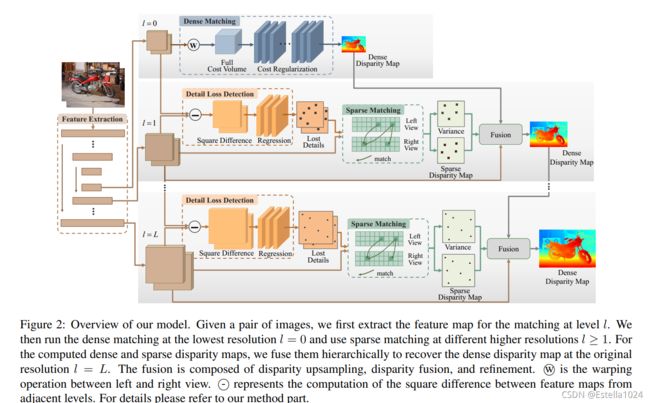
- 低分辨率:
cost volume+3D卷积
- 高分辨率:
- 1.确定要对哪些稀疏点进行匹配。
- 输入:(利用一个由3层卷积+sigmoid组成的小模块,以上采样的特征)-本来提取的高分辨率的特征
直观解释是:如果插值的特征和正常网络提取的高分辨率特征相差较大,这个点则有较大可能属于细节,需要在高分辨率上进行匹配 - 输出:一个mask(掩膜)
mask的值越接近于1越代表这个点在低分辨率上可能丢失,需要在高分辨率上恢复
- 输入:(利用一个由3层卷积+sigmoid组成的小模块,以上采样的特征)-本来提取的高分辨率的特征
- 1.确定要对哪些稀疏点进行匹配。
损失:
利用一个无监督的损失
 其中FA代表图像中的fine区域,即要进行稀疏匹配的区域。
其中FA代表图像中的fine区域,即要进行稀疏匹配的区域。
损失包含两部分:
- 一方面希望不要有太多的点属于FA区域,即强调稀疏性;
- 另一方面就是稀疏点要是那些特征存在差异的点,即哪些点属于稀疏点。
当我们已经检测到左右图的稀疏点时,只需要沿着水平线进行稀疏匹配即可。
对于左图的任意一个点,计算和右图所有可能的匹配点的特征相似度作为(负的)匹配代价
对匹配代价作归一化转化为匹配概率
最终加权平均得到该点视差
融合:
- 低分辨率的插值的致密的视差图(这里插值还用了一种content-aware的动态方法,是学习得到的插值权重,而不是简单的双线性)
- 高分辨率的稀疏视差图
- 进行soft融合:
- 融合的掩膜不是二进制的,是允许有小数
- 通过学习得到
- 3层卷积+sigmoid
- 输入是致密视差和稀疏视差、同分辨率特征、用于预测稀疏匹配点的掩膜、以及一个稀疏匹配的置信度。
调优
以warp的左图特征映射、右图特征映射、初始视差为输入,经过7个卷积层,得到视差残差。
实验
首先是一些关于检测到的细节区域的示意图:
 指标上对比(分别在SceneFlow和KITTI 2015上评测得到),模型兼顾准确性与速度:
指标上对比(分别在SceneFlow和KITTI 2015上评测得到),模型兼顾准确性与速度:


可取之处
多尺度
无code
4.《Learning Stereo from Single Images》ECCV 2020
https://github.com/nianticlabs/stereo-from-mono/
术语
Sobel 边缘算子
消融实验
论文理解
痛点:
真实场景下的立体匹配数据集往往难以进行深度/视差标签的采集或标注,因此已有的真实数据集的规模都很小,例如 KITTI,MiddleBury 和 ETH3D
方法

输出:![]()
构造方法带来的问题:
- 遮挡造成的像素点的缺失
- 像素点冲突:多个像素点可能最终落在右图中的同一个像素点上
- 单目深度估计的不准确会造成深度图的不连续,构造右图时出现很多野点。

解决方法
- 处理遮挡:被遮挡的像素在右图中会成为没有填充的黑洞,因此处理遮挡的方法是将其用合适的纹理填充。
从训练图像中随机选择图像I_b的纹理信息,利用 color transfer 技术将 I_b 的风格迁移到与 I_l保持一致得到I
̃_b,之后利用I ̃_b 对应位置的像素来填充I ̃_r 中缺失的空洞。 - 处理冲突:当多个像素点对应到右图中的同一位置时,作者采用视差值最大的像素点作为最终的选择,因为这些像素点彼此很近,应当保证在两个视角中都是可见的。
- 深度图锐化处理
- 从上图中可以看出,单目深度估计的不准确会产生不连续的深度图,从而在合成的右图
从上图中可以看出,单目深度估计的不准确会产生不连续的深度图,从而在合成的右图
出现如(b)图中的 flying pixels。
作者采用深度锐化技术来解决,即对深度图采用 Sobel 边缘算子进行处理,将响应大于 3 的像素点作为野点而去除。去除后能得到更加锐化的右图(c)。利用锐化后的双目图像得到的视差估计结果会更准确,如(e)和(f)的比较
数据集
Mono for Stereo(MfS)数据集,MfS 数据集包括 COCO 2017,Mapillary Vistas,ADE20K,Depth in the Wild 和 DIODE。而测试数据集是常用的立体匹配数据集 KITTI 2012/2015,MiddleBury 和 ETH3D
立体匹配
采用 PSMNet 作为视差估计的模型
同时也验证了其他模型,如 iResNet 和 GA-Net
通过实验,作者得到出了以下 6 个结论:
-
相比于在合成数据上训练,本文的方法能够获得性能更好,泛化更强的结果;
-
对单目深度估计的结果具有鲁棒性,不论单目数据的来源,均能得到较好的泛化结果;
-
消融实验表明论文中的设计是有效的;
-
在各种立体匹配模型上均能获得性能提升;
-
随着构造的立体匹配数据集规模越大,相应的性能会越高;
-
在 MfS 数据集上预训练再在真实数据集上微调的性能比原来在合成数据集上预训练再微调要好
可取之处
- 立体匹配数据集构造:
通过已有的单目深度估计算法和其他任务中的单目自然图像来构建双目立体匹配数据集