最详细的语义分割---06mIoU和PA究竟如何计算?
语义分割最常见的评价指标就是mIoU和PA,它们从概念上理解起来比较直观,而且在不同的视觉任务中有很多不同的求法。这两个指标的计算,对于刚学习语义分割的朋友(例如我)还是很有难度的,所以记录一下它们的实现过程,免得以后忘记了。
还是先从原理简单介绍一下,本文使用的方法如何求交并比,不然待会看代码可能有点头疼。
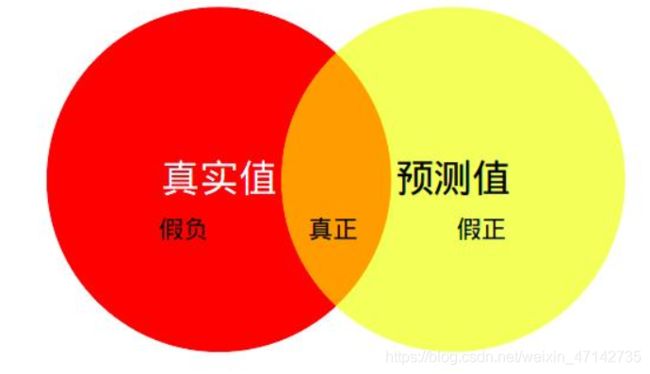
语义分割的交并比其实就是下图中橙色部分比上真实值加预测值。物理意义很直观,理解起来也很方便。具体到语义分割之中,它的含义就是(该类预测正确的总数)比上(预测和标签中所有为该类别像素点的总数减去该类预测正确像素点的总数)。
下面来讲解一下我使用的代码里面对它的实现
主要通过下面三个函数进行实现,看到是不是很恼火呢,别急让我来揭开它的庐山真面目。
seg_metrics = eval_metrics(output, target, self.num_classes)
self._update_seg_metrics(*seg_metrics)
seg_metrics = self._get_seg_metrics()
1.eval_metrics(output, target, self.num_classes)
先来讲第一个函数,它的输入是三个值,分别是网络预测的输出,标签,和数据集的分类总数。点进这个函数里面去,可以看到如下代码:
def eval_metrics(output, target, num_class):
_, predict = torch.max(output.data, 1) # 按通道维度取最大,拿到每个像素点分类的类别
predict = predict + 1 # 每个都加1避免从0开始
target = target + 1
labeled = (target > 0) * (target <= num_class) # 得到一个矩阵,其中,为true的是1,为false的是0
# 标签中同时满足大于0 小于num_classes 的地方为T,其余地方为F 构成了一个蒙版
correct, num_labeled = batch_pix_accuracy(predict, target, labeled) #计算一个batch中预测正确像素点的个数和所有像素点的总数
inter, union = batch_intersection_union(predict, target, num_class, labeled)
return [np.round(correct, 5), np.round(num_labeled, 5), np.round(inter, 5), np.round(union, 5)]
代码都写了注释,再对其进行解释一下。predict 就是我们拿到的预测结果,不过它是一个batch的所有的预测结果**(这个代码都是针对一个batch的,后面就不再进行说明了)。所以这里的predict的size是4x224x224,batch是4 ,h w 都是224。至于为什么只有一个通道,是因为预测的结果只有一个通道,我们看到的彩色图片是因为,我们对这个单通道的图片进行渲染,所以才是彩色的。
labled的变量就是一个和标签图一样的蒙版,相当于如果它和预测值相乘,那么预测值中的所有像素点的值都被限定在我们指定的区间了,大于我们设置的区间的话,其结果都为0。可以发现后面又调用了一个函数,我们点correct, num_labeled = batch_pix_accuracy(predict, target, labeled)** 进去:
def batch_pix_accuracy(predict, target, labeled):
pixel_labeled = labeled.sum() # 计算标签的总和,是一个batch中的所有标签的总数
# 注意 python中默认的T为1 F为0 调用sum就是统计正确的像素点的个数
pixel_correct = ((predict == target) * labeled).sum() # 将一个batch中预测正确的,且在标签范围内的像素点的值统计出来
assert pixel_correct <= pixel_labeled, "Correct area should be smaller than Labeled"
return pixel_correct.cpu().numpy(), pixel_labeled.cpu().numpy()
可以发现,它的输入是预测图,标签和对应的蒙版。通过函数名字可以看到,这个是计算像素准确率的。其中的变量pixel_correct的结果是所有正确的像素点的值统计出来。(predict == target)这一步操作,如果某个位置的像素值与预测值相同 则结果为1 ,不同则说明预测错误,结果为0 ,然后与蒙版相乘,保证结果是在我们设置的区间内。如果这里不理解,我们可以做一个小实验,来验证一下,注意哦,只有同型数组才能这样用哦,直接用列表比较之后返回True或者False

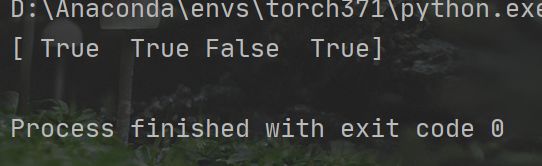
这样得到的一个矩阵大小为4x224x224,其中每个像素点的值要么为1 要么为0,我们把它求和,就能得到所有预测正确像素点的数量。然后返回,这里得到的就是所有标签的像素点的总数,和所有预测正确的像素点的总数。
接下来就会返回,进入**inter, union = batch_intersection_union(predict, target, num_class, labeled)**这个函数,由名字决定命运,可以看出这个是计算交并比的,输入预测图 标签 类别总数 和蒙版,输出交 和 并的区域。
该函数的代码为:
def batch_intersection_union(predict, target, num_class, labeled):
predict = predict * labeled.long() # 返回预测中在指定范围内的像素点,保证分类类别在指定范围
intersection = predict * (predict == target).long() # 过滤掉预测中不正确的像素值
# intersection.size() (4 224 224) 一个batch中只有正确的像素值才在intersection中,不正确的为0
#torch.histc 统计图片中的从0-bins出现的次数,返回一个列表
area_inter = torch.histc(intersection.float(), bins=num_class, max=num_class, min=1)
# area_inter 会得到batch中每个类别 对应像素点(分类正确的)出现了多少次
area_pred = torch.histc(predict.float(), bins=num_class, max=num_class, min=1)
# area_inter 将batch中预测的所有像素点(不管正不正确) 在每个类别的次数统计出来
area_lab = torch.histc(target.float(), bins=num_class, max=num_class, min=1)
# area_lab 将batch中每个类别实际有多少像素点统计出来
area_union = area_pred + area_lab - area_inter # 预测与标签相交的部分 每个类别对应像素点的数量
assert (area_inter <= area_union).all(), "Intersection area should be smaller than Union area"
return area_inter.cpu().numpy(), area_union.cpu().numpy()
其中intersection为batch中相交的部分,通过标签和预测图相比,会得到形状相同,且标签值等于预测值的地方为1 不等的地方为0的一个蒙版,然后与预测图相乘,就会保留正确的预测值,也就是相交的部分。
然后这里有一个比较重要的函数,torch.histc().

还是从代码里讲解比较方便,area_inter = torch.histc(intersection.float(), bins=num_class, max=num_class, min=1)。例如这个代码,我们输入的inersection,bins是类别总数,还记得我们前面对所有的 预测值和标签加1 了嘛,后面这里的最小值就是1。那么这个函数可以实现什么功能呢?先要明白一点,我们intersection中的数据都是每个像素点的类别数,也就是说,它们都是小于等于num_class,这个函数就会返回一个列表,你可以把它理解为一个x和y坐标,不过x轴没有显示,列表中的元素是y轴的信息。y的含义就是当前批次中不同类别像素出现的次数。
可能理解起来还是比较费劲,下面debug说明一下,可以看到它这个是一个列表,而且他的长度是18,就说明有十八个类别。而这个列表中的元素呢,50就表示该batch中预测正确的 属于第1类别的像素点出现了50次,后面的同理
![]()
![]()
在用实际方法验证一下:
import torch
b = torch.as_tensor([[1,2,3],
[2,3,2],
[1,1,2],]).float()
print(b)
o = torch.histc(b,bins=3,max=3,min=1)
print(o)
输出的结果为:
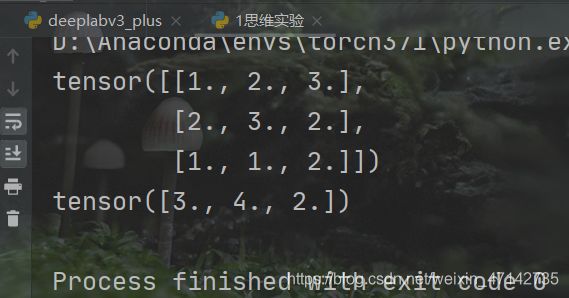
这个tensor中1出现了三次 2 出现了4次 3 出现了2次。
通过同样的函数就会返回三个值:area_inter area_pred area_lab
分别表示相交的部分,预测的部分 标签部分。然后用area_union = area_pred + area_lab - area_inter 就会得到交并比中的分母,这个是每个类别的分母都保存在列表里,也就是最开始图中出了相交部分以外的区域,也就算出来了每个类别的iou。
seg_metrics = eval_metrics(output, target, self.num_classes),最后在开看一下这个函数,他会给我们返回4个值
return [np.round(correct, 5), np.round(num_labeled, 5), np.round(inter, 5), np.round(union, 5)]
依次是正确的像素点的总数,所有像素点的总数,相交像素点的总数(每个类别的),然后相交区域的总数
*2.self._update_seg_metrics(seg_metrics)
现在我们得到了一个batch中每个类别PA和每个类别Iou,那么如何求一个epoch中PA和mIoU呢,那是不是只要把它们在训练的时候依次加起来就可以啦,代码也很简单:
def _update_seg_metrics(self, correct, labeled, inter, union):
self.total_correct += correct
self.total_label += labeled
self.total_inter += inter
self.total_union += union
通过这个方法在每次迭代的时候更新,就可以得到一个epoch的PA和IoU了。
3.seg_metrics = self._get_seg_metrics()
那么如何求一个batch的所有类别的PA和mIoU了,那也很容易,就是取平均嘛
def _get_seg_metrics(self):
pixAcc = 1.0 * self.total_correct / (np.spacing(1) + self.total_label)
IoU = 1.0 * self.total_inter / (np.spacing(1) + self.total_union)
mIoU = IoU.mean()
return {
"Pixel_Accuracy": np.round(pixAcc, 3),
"Mean_IoU": np.round(mIoU, 3),
"Class_IoU": dict(zip(range(self.num_classes), np.round(IoU, 3)))
}
将第二部得到的self.total_correct self.total_label 在一个epoch中求和,然后取平均不就可以了嘛。这里可能有小伙伴会问,np.spacing(1)是干嘛的,我觉得是避免分母为0吧,你把他打印出来会发现是一个非常小的数

整个代码
def eval_metrics(output, target, num_class):
_, predict = torch.max(output.data, 1) # 按通道维度取最大,拿到每个像素分类的类别(1xhxw)
predict = predict + 1 # 每个都加1避免从0开始,方便后面计算PA
target = target + 1
labeled = (target > 0) * (target <= num_class) # 得到一个矩阵,其中,为true的是1,为false的是0
# 标签中同时满足大于0 小于num_classes 的地方为T,其余地方为F 构成了一个蒙版
correct, num_labeled = batch_pix_accuracy(predict, target, labeled) #计算一个batch中预测正确像素点的个数和所有像素点的总数
inter, union = batch_intersection_union(predict, target, num_class, labeled)
return [np.round(correct, 5), np.round(num_labeled, 5), np.round(inter, 5), np.round(union, 5)]
def batch_pix_accuracy(predict, target, labeled):
pixel_labeled = labeled.sum() # 计算标签的总和,是一个batch中的所有标签的总数
# 注意 python中默认的T为1 F为0 调用sum就是统计正确的像素点的个数
pixel_correct = ((predict == target) * labeled).sum() # 将一个batch中预测正确的,且在标签范围内的像素点的值统计出来
assert pixel_correct <= pixel_labeled, "Correct area should be smaller than Labeled"
return pixel_correct.cpu().numpy(), pixel_labeled.cpu().numpy()
def batch_intersection_union(predict, target, num_class, labeled):
predict = predict * labeled.long() # 返回预测中在指定范围内的像素点
intersection = predict * (predict == target).long() # 过滤掉预测中不正确的像素值
# 一个batch中只有正确的像素值才在intersection中,不正确的为0
#torch.histc 统计图片中的从0-bins出现的次数,返回一个列表
area_inter = torch.histc(intersection.float(), bins=num_class, max=num_class, min=1)
# area_inter 会得到batch中每个类别 对应像素点(分类正确的)出现了多少次
area_pred = torch.histc(predict.float(), bins=num_class, max=num_class, min=1)
# area_inter 将batch中预测的所有像素点(不管正不正确) 在每个类别的次数统计出来
area_lab = torch.histc(target.float(), bins=num_class, max=num_class, min=1)
# area_lab 将batch中每个类别实际有多少像素点统计出来
area_union = area_pred + area_lab - area_inter # 预测与标签相交的部分 每个类别对应像素点的数量
assert (area_inter <= area_union).all(), "Intersection area should be smaller than Union area"
return area_inter.cpu().numpy(), area_union.cpu().numpy()
