Hive整合Hbase
目 录
简介
实验步骤
1.配置文件
2.复制jar包
3.创建映射表
4.导入数据
5.注意事项
总结
1.优点
2.缺点
简介
Hive是建立在Hadoop之上的数据仓库基础构架、是为了减少MapReduce编写工作的批处理系统,Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce。Hive可以理解为一个客户端工具,将我们的sql操作转换为相应的MapReduce jobs,然后在Hadoop上面运行。
Hbase全称为Hadoop Database,即Hbase是Hadoop的数据库,是一个分布式的存储系统。Hbase利用Hadoop的HDFS作为其文件存储系统,利用Hadoop的MapReduce来处理Hbase中的海量数据。利用zookeeper作为其协调工具。

实验步骤
1.配置文件
cd /opt/software/hive-2.3.3/conf
vi hive-site.xml
hive.zookeeper.quorum node01,node02,node03 hbase.zookeeper.quorum node01,node02,node03 hive.aux.jars.path file:///opt/software/hive/lib/hive-hbase-handler-2.3.3.jar,file:///opt/software/hive/lib/zoo keeper-3.4.10.jar,file:///opt/software/hive/lib/hbase-client-1.3.1.jar,file:///opt/software/hive/lib/hbase-common-1.3.1-tests.jar,file:///opt/software/hive/lib/hbase-server-1.3.1.jar,file:///opt/software/hive/lib/hbase-common-1.3.1.jar,file:///opt/software/hive/lib/hbase-protocol-1.3.1.jar,file:///opt/software/hive/lib/htrace-core-3.1.0-incubating.jar
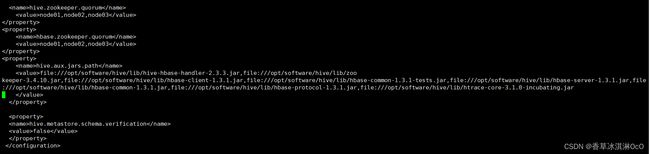
vi hive-env.sh
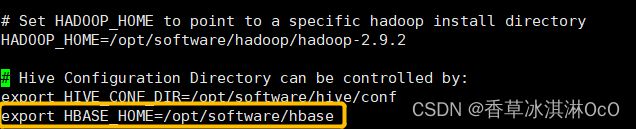
2.复制jar包
将hbase lib目录下的所有文件复制到hive lib目录中
注意:先删除hive/lib目录下hbase开头的jar包
cd /opt/software/hive-2.3.3/lib
rm -rf hbase-*
cd /opt/software/hbase/lib
cp * /opt/software/hive-2.3.3/lib/
3.创建映射表
在hive中创建映射表,创建完成后在hbase中查看是否同时在hbase中也创建成功
创建之前要先启动hbase(一定确定三台虚拟机都启动了hbase)
1.start-hbase.sh
2.
create table hbase_score(id int,name string,score int) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping" = "cf:name,cf:score") tblproperties("hbase.table.name" = "hbase_score");

3.
create table hive_hbase_test(id int,name string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:name") tblproperties("hbase.table.name"="hive_hbase_test");4.
hbse shell
4.导入数据
Hive 导入数据,Hbase查看数据
1.vi hive_hbase.txt

2.在hive中创表,导入数据:
create table test(id int,name string) row format delimited fields terminated by ','; load data local inpath "/opt/software/hive_hbase.txt" into table test; select * from test;
3.将hive的test表中的数据加载到hive_hbase_test表
insert overwrite table hive_hbase_test select * from test;
4.通过Hbase put添加数据,Hive查看添加数据
1)在hbase shell中对表hive_hbase_test添加数据
put 'hive_hbase_test','4','cf1:name','mipeng'2)在hive中查看数据是否添加进来:
select * from hive_hbase_test;
5.注意事项
1.整合完成之后,如果在hive当中创建的为内部表,那么在hive中删除该表时,hbase上对应的表也会删除;
2.如果在hive当中创建的为外部表,那么在hive中删除该表时,不会影响hbase。
3.hive中创建外部映射表步骤:
①在hbase中创建对应名称、对应列簇的表:
create 'hbase_score1','cf'②在hive中创建外部表:
create external table hbase_score1(id int,name string,score int) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping" = "cf:name,cf:score") tblproperties("hbase.table.name" = "hbase_score1");③在hive中向外部表内导入数据:(参考导入数据测试)
④在hbase中添加数据:(参考导入数据测试)
总结
1.优点
1)配置、使用简单,大大提高使用效率。熟悉SQL或熟悉Hive使用的人,可以轻松掌握,学习成本低
2)减少所需编写代码量
3)低耦度整合,对Hive和HBase的依赖度低,没有较大耦合度
4)由Apache官方提供,从Hive0.6开始支持,更新比较及时,bug较少,可以用于生产环境
2.缺点
1)查询速度慢,大部分操作都需要启动MapReduce,查询过程比较耗时
2)对HBase集群的访问压力较大,每个MapReduce任务都需要启动N个Handler连接HBase集群,这样会大量占用HBase连接,造成资源使用紧张
3)列映射有诸多限制。现有版本的列映射以及Rowkey的限制很多,例如无法使用组合主键,无法使用timestamp属性(版本)