catboost参数详解及实战(强推)
目录
一 参数详解
二 实战
1 导包
2 数据读取
3 贷后y标签分布,逾期率20%
4 预处理
5 特征分布
6 特征分组
7 初始参数
8 catboost建模函数
9 初始模型
10 特征重要性
11 贝叶斯调参
一 参数详解
由于catboost参数较多,本文仅列出重要及常用参数(如需直接使用,可将 :替换为 # )
'''
公共参数
'''
params={
'loss_function': , : 损失函数,取值RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE, Poisson。默认Logloss。
'custom_loss': , : 训练过程中计算显示的损失函数,取值Logloss、CrossEntropy、Precision、Recall、F、F1、BalancedAccuracy、AUC等等
'eval_metric': , : 用于过度拟合检测和最佳模型选择的指标,取值范围同custom_loss
'iterations': , : 最大迭代次数,默认500. 别名:num_boost_round, n_estimators, num_trees
'learning_rate': , : 学习速率,默认0.03 别名:eta
'random_seed': , : 训练的随机种子,别名:random_state
'l2_leaf_reg': , : l2正则项,别名:reg_lambda
'bootstrap_type': , : 确定抽样时的样本权重,取值Bayesian、Bernoulli(伯努利实验)、MVS(仅支持cpu)、Poisson(仅支持gpu)、No(取值为No时,每棵树为简单随机抽样);默认值GPU下为Bayesian、CPU下为MVS
'bagging_temperature': , : bootstrap_type=Bayesian时使用,取值为1时采样权重服从指数分布;取值为0时所有采样权重均等于1。取值范围[0,inf),值越大、bagging就越激进
'subsample': , : 样本采样比率(行采样)
'sampling_frequency': , : 采样频率,取值PerTree(在构建每棵新树之前采样)、PerTreeLevel(默认值,在子树的每次分裂之前采样);仅支持CPU
'random_strength': , : 设置特征分裂信息增益的扰动项,用于避免过拟合。子树分裂时,正常会寻找最大信息增益的特征+分裂点进行分裂,此处对每个特征+分裂点的信息增益值+扰动项后再确定最大值。扰动项服从正态分布、均值为0,random_strength参数值会作为正态分布的方差,默认值1、对应标准正态分布;设置0时则无扰动项
'use_best_model': , : 让模型使用效果最优的子树棵树/迭代次数,使用验证集的最优效果对应的迭代次数(eval_metric:评估指标,eval_set:验证集数据),布尔类型可取值0,1(取1时要求设置验证集数据)
'best_model_min_trees': , : 最少子树棵树,和use_best_model一起使用
'depth': , : 树深,默认值6
'grow_policy': , : 子树生长策略,取值SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)
'min_data_in_leaf': , : 叶子结点最小样本量
'max_leaves': , : 最大叶子结点数量
'one_hot_max_size': , : 对唯一值数量二 实战
1 导包
import re
import os
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import matplotlib.pyplot as plt
import gc
from bayes_opt import BayesianOptimization
from catboost import Pool, cv2 数据读取
df=pd.read_csv('E:/train.csv',engine='python').head(80000)
print(df.shape)
df.head()3 贷后y标签分布,逾期率20%
pd.concat([df_copy['isDefault'].value_counts()
,df_copy['isDefault'].value_counts(normalize=True)],axis=1)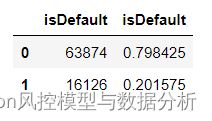
4 预处理
employmentLength字段为工作年限,提取出年数
df_copy['employmentLength']=df_copy['employmentLength'].replace(' years','')
dic={'< 1':0,'10+':20}
df_copy['employmentLength']=df_copy['employmentLength'].map(dic).astype('float')5 特征分布
import seaborn as sns
sns.pairplot(df_copy.loc[:,'loanAmnt':'isDefault'].drop(['issueDate'],axis=1)
, kind="scatter",hue="isDefault"
, plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))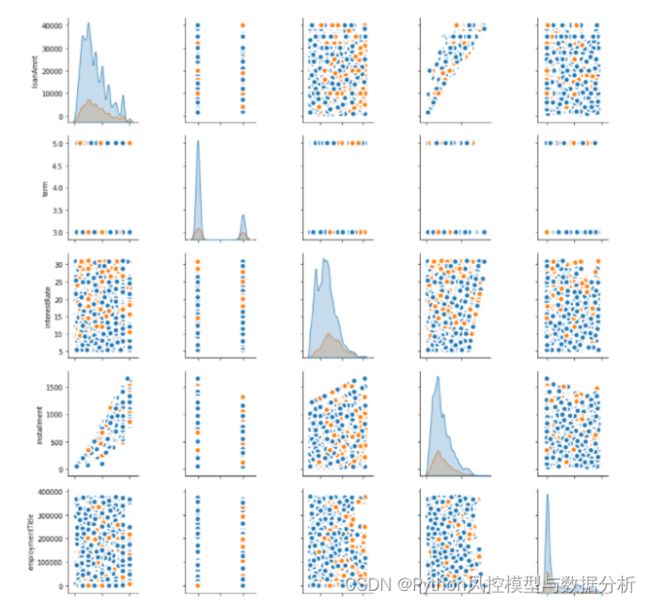
6 特征分组
float_col=list(df_copy.select_dtypes(exclude=['string','object']).drop(['id','isDefault'],axis=1).columns).copy()
cate_col=['grade', 'subGrade']
all_fea=float_col+cate_col7 初始参数
params={
'loss_function': 'Logloss', # 损失函数,取值RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE, Poisson。默认Logloss。
'custom_loss': 'AUC', # 训练过程中计算显示的损失函数,取值Logloss、CrossEntropy、Precision、Recall、F、F1、BalancedAccuracy、AUC等等
'eval_metric': 'AUC', # 用于过度拟合检测和最佳模型选择的指标,取值范围同custom_loss
'iterations': 50, # 最大迭代次数,默认500. 别名:num_boost_round, n_estimators, num_trees
'learning_rate': 0.1, # 学习速率,默认0.03 别名:eta
'random_seed': 123, # 训练的随机种子,别名:random_state
'l2_leaf_reg': 5, # l2正则项,别名:reg_lambda
'bootstrap_type': 'Bernoulli', # 确定抽样时的样本权重,取值Bayesian、Bernoulli(伯努利实验)、MVS(仅支持cpu)、Poisson(仅支持gpu)、No(取值为No时,每棵树为简单随机抽样);默认值GPU下为Bayesian、CPU下为MVS
# 'bagging_temperature': 0, # bootstrap_type=Bayesian时使用,取值为1时采样权重服从指数分布;取值为0时所有采样权重均等于1。取值范围[0,inf),值越大、bagging就越激进
'subsample': 0.6, # 样本采样比率(行采样)
'sampling_frequency': 'PerTree', # 采样频率,取值PerTree(在构建每棵新树之前采样)、PerTreeLevel(默认值,在子树的每次分裂之前采样);仅支持CPU
'use_best_model': True, # 让模型使用效果最优的子树棵树/迭代次数,使用验证集的最优效果对应的迭代次数(eval_metric:评估指标,eval_set:验证集数据),布尔类型可取值0,1(取1时要求设置验证集数据)
'best_model_min_trees': 50, # 最少子树棵树,和use_best_model一起使用
'depth': 4, # 树深,默认值6
'grow_policy': 'SymmetricTree', # 子树生长策略,取值SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)
'min_data_in_leaf': 500, # 叶子结点最小样本量
# 'max_leaves': 12, # 最大叶子结点数量
'one_hot_max_size': 4, # 对唯一值数量8 catboost建模函数
import catboost
from catboost import CatBoostClassifier
def catboost_model(df,y_name,params,cate_col=[]):
x_train,x_test, y_train, y_test =train_test_split(df.drop(y_name,axis=1),df[y_name],test_size=0.2, random_state=123)
model = CatBoostClassifier(**params)
model.fit(x_train, y_train,eval_set=[(x_train, y_train),(x_test,y_test)],cat_features=cate_col)
train_pred = [pred[1] for pred in model.predict_proba(x_train)]
train_auc= roc_auc_score(list(y_train),train_pred)
test_pred = [pred[1] for pred in model.predict_proba(x_test)]
test_auc= roc_auc_score(list(y_test),test_pred)
result={
'train_auc':train_auc,
'test_auc':test_auc,
}
return model,result9 初始模型
model,model_result=catboost_model(df_copy[all_fea+['isDefault']]
,'isDefault',params,cate_col)
![]()
10 特征重要性
def feature_importance_catboost(model):
result=pd.DataFrame(model.get_feature_importance(),index=model.feature_names_,columns=['FeatureImportance'])
return result.sort_values('FeatureImportance',ascending=False)
feature_importance_catboost(model) 
11 贝叶斯调参
(1)自定义调参目标,此处使用测试集的AUC值为调参目标
def catboost_cv(iterations,learning_rate,depth,subsample,rsm):
params={
'loss_function': 'Logloss', # 损失函数,取值RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE, Poisson。默认Logloss。
'custom_loss': 'AUC', # 训练过程中计算显示的损失函数,取值Logloss、CrossEntropy、Precision、Recall、F、F1、BalancedAccuracy、AUC等等
'eval_metric': 'AUC', # 用于过度拟合检测和最佳模型选择的指标,取值范围同custom_loss
'iterations': 50, # 最大迭代次数,默认500. 别名:num_boost_round, n_estimators, num_trees
'learning_rate': 0.1, # 学习速率,默认0.03 别名:eta
'random_seed': 123, # 训练的随机种子,别名:random_state
'l2_leaf_reg': 5, # l2正则项,别名:reg_lambda
'bootstrap_type': 'Bernoulli', # 确定抽样时的样本权重,取值Bayesian、Bernoulli(伯努利实验)、MVS(仅支持cpu)、Poisson(仅支持gpu)、No(取值为No时,每棵树为简单随机抽样);默认值GPU下为Bayesian、CPU下为MVS
# 'bagging_temperature': 0, # bootstrap_type=Bayesian时使用,取值为1时采样权重服从指数分布;取值为0时所有采样权重均等于1。取值范围[0,inf),值越大、bagging就越激进
'subsample': 0.6, # 样本采样比率(行采样)
'sampling_frequency': 'PerTree', # 采样频率,取值PerTree(在构建每棵新树之前采样)、PerTreeLevel(默认值,在子树的每次分裂之前采样);仅支持CPU
'use_best_model': True, # 让模型使用效果最优的子树棵树/迭代次数,使用验证集的最优效果对应的迭代次数(eval_metric:评估指标,eval_set:验证集数据),布尔类型可取值0,1(取1时要求设置验证集数据)
'best_model_min_trees': 50, # 最少子树棵树,和use_best_model一起使用
'depth': 4, # 树深,默认值6
'grow_policy': 'SymmetricTree', # 子树生长策略,取值SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)
'min_data_in_leaf': 500, # 叶子结点最小样本量
# 'max_leaves': 12, # 最大叶子结点数量
'one_hot_max_size': 4, # 对唯一值数量(2)调参
param_value_dics={
'iterations':(20, 50),
'learning_rate':(0.02,0.2),
'depth':(3, 6),
'subsample':(0.6, 1.0),
'rsm':(0.6, 1.0)
}
cat_bayes = BayesianOptimization(
catboost_cv,
param_value_dics
)
cat_bayes.maximize(init_points=1,n_iter=20) #init_points-调参基准点,n_iter-迭代次数
cat_bayes.max.get('params')
(3)设置最优参数并重新训练模型
cat_bayes.max.get('params')
params.update(
{
'depth': 5,
'iterations': 45,
'learning_rate': 0.189,
'rsm': 0.707,
'subsample': 0.890
}
)
model,model_result=catboost_model(df_copy[all_fea+['isDefault']],'isDefault',params,cate_col)
model_result![]()