《百面机器学习》试读 | AI热门应用之游戏中的人工智能

小编温馨提示
首先掌声恭喜上周第五个留言获得福利的幸运小伙伴 @羊????????????,请通过后台联系我们,我们会将奖品尽快寄出噢~
铛铛铛,本周将会连载《百面机器学习》人工智能领域热门应用相关章节第二期,学习继续,福利继续????
在本周连载中,留言写下你的阅读感想,我们将会继续选取第五位留言的幸运同学,送上有主创团队“签名开光”的《百面机器学习》书籍一本~

AI热门应用之“游戏中的人工智能”

自人类文明诞生起,就有了游戏。游戏是人类最早的集益智与娱乐一体的活动,传说四千年前就有了围棋。几个世纪以来,人们创造出不计其数的各类游戏:象棋,国际象棋、跳棋、扑克、麻将、桌游等。半个多世纪前,电子计算机技术诞生,自此游戏焕发了新貌。1980年前后,电视游戏(Video Game)和街机游戏(Arcade Game)开始进入人们视线,当时还是一个小众活动。随后的90年代,你是否还记得风靡街头的游戏机厅,以及走进千家万户的小霸王学习机。然后,个人计算机的普及将游戏带入了一个崭新的时代。当前,电子游戏不限于电脑,手机、平板等各类带屏平台都被游戏一一拿下。2010年,游戏已是数千亿美元的产业,全球市场利润远超其他娱乐业。
01
游戏AI的历史
早在人工智能处于萌芽期,先驱们就产生用计算机解决一些智力任务的想法。人工智能之父——阿兰·图灵很早就从理论上提出用MiniMax算法来下国际象棋的思路。
第一款成功下棋的软件诞生于1952年,记录在道格拉斯的博士论文中,玩的是最简单的Tic-Tac-Toe游戏(如图1所示)。几年后,约瑟夫塞·缪尔开发出下西洋跳棋(图2)的软件,是第一款应用机器学习算法的程序,现在这个算法被人们称为强化学习。早期的游戏AI都集中在解决经典棋类游戏的问题上,人们相信人类挑战了几百年甚至上千年的游戏,必定是人类智能的精华所在。然后,三十年的努力,人们在树搜集技术上取得突破。1994年,乔纳森·斯卡费尔的西洋跳棋程序Chinook打败了人类冠军马里恩·汀斯雷;2007年,他在《科学》杂志宣布“Checkers is solved(西洋跳棋已被攻克)”。
图1:Tic-Tac-Toe游戏


图2:西洋跳棋
长时间以来,国际象棋被公认为AI领域的实验用“果蝇”,大量的AI新方法被测试于此。直到1997年,IBM的深蓝击败世界级国际象棋大师加里·卡斯帕罗夫(如图3所示),展现出超人般的国际象棋水平,这只“果蝇”终于退休了。当时深蓝运行在一个超级计算机上,现在一台普通的笔记本就能运行深蓝程序。

图3:深蓝击败国际象棋大师加里·卡斯帕罗夫
游戏AI的另一个里程碑事件发生在西洋双陆棋(图4)上。1992年,杰拉尔德·特索罗开发的名叫TD-Gammon的程序,运用了神经网络和时间差分学习方法,达到了顶尖人类玩家的水准。随着AI技术的发展,经历了从高潮到低谷、从低谷到高潮的起起伏伏,时间转移到2010年后,DeepMind、OpenAI等一批AI研究公司的出现,将游戏AI推向一个新纪元。

图4:西洋双陆棋
02
从AlphaGo到AlphaGo Zero
面对古老的中国游戏——围棋,AI研究者们一度认为这一天远未到来。2016年1月,谷歌DeepMind的一篇论文《通过深度神经网络与搜索树掌握围棋》(Mastering the game of Go with deep neural networks and tree search)发表在《自然》杂志上,提到他们的AI算法成功运用有监督学习、强化学习、深度学习与蒙特卡洛树搜索算法解决下围棋的难题。

当年3月,谷歌围棋程序AlphaGo与世界冠军李世石展开五局对战,最终以4:1获胜(如图5所示)。
图5:AlphaGo击败围棋世界冠军李世石
同年年底,一个名为Master的神秘围棋大师在网络围棋对战平台上,通过在线超快棋的方式,以60胜0负的战绩震惊天下,在第59盘和60盘的局间宣布自己就是AlphaGo。
2017年5月,AlphaGo又与被认为世界第一的中国天才棋手柯洁举行三局较量,结果三局全胜。
就在众人尚未回过神来之际,AlphaGo的后继者AlphaGo Zero横空出世,后者根本不需要人类棋谱做预先训练,完全是自己和自己下。算法上,AlphaGo Zero只凭借一个神经网络,进行千万盘的自我对弈。初始时,由于没有人类知识做铺垫,AlphaGo Zero不知围棋为何物;36小时后,AlphaGo Zero达到2016年与李世石对战期AlphaGo的水平;72小时后,AlphaGo Zero以100:0的战绩绝对碾压李世石版的AlphaGo;40天后,AlphaGo Zero超越所有版本的AlphaGo(如图6所示)。研究者们评价AlphaGo Zero的意义,认为它揭示出一个长期以来被人们忽视的真相——数据也许非必要,有游戏规则足够。这恰和人们这几年的观点相左,认为深度学习技术是数据驱动型的人工智能技术,算法的有效性离不开海量规模的训练数据。事实上,深层次探究个中原因,有了游戏的模拟系统,千万盘对弈、千万次试错不也是基于千万个样本数据吗,只是有效数据的定义不一定指人类的知识。
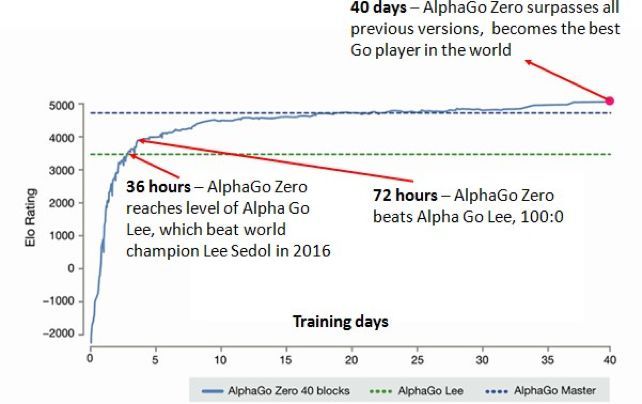
图6:AlphaGo Zero的进化过程
纵观其他经典的棋类游戏,如国际象棋、中国象棋等,无一不是基于确定性规则建立的游戏。这类游戏不仅规则明晰,而且博弈的双方均持有对称的信息,即所谓的“完美信息 ”。游戏AI面对的问题,通常是一个搜索问题,而且是一对一的MiniMax游戏。原理上,记住当前局面并向下进行搜索式推演,可以找到较好的策略。当搜索空间不大时,可以把各种分支情况都遍历到,然后选出最佳方案;当搜索空间太大时,可以用一些剪枝的或概率的办法,减少要搜索的状态数。国际象棋和中国象棋的棋子较少,且不同棋子走子方式固定,用今天的超级计算机穷举不是问题。但是围棋不同,棋盘是19 X 19,有361个落子点,一盘围棋约有10的170次方个决策点,是所有棋类游戏中最多的,需要的计算量巨大,所以穷举方式是不可能的,这也导致围棋成为最后被计算机攻克的棋类游戏。数学上,中国象棋和国际象棋的空间复杂程度大约是10的48次幂,而围棋是10的172次幂,还有打劫的手段可以反复提子,事实上要更复杂。值得一提的是,可观测宇宙的质子数量为10的80次幂。
而在德州扑克、电子竞技及策略类电子游戏(诸如“星际争霸”)等相关领域中,AI均有重要的研究应用,在面临日新月异的巨大挑战同时亦在不断追求卓越。关于这些领域前沿科技的讲解介绍我们在《百面机器学习》书籍中均有详细书写,欢迎各位读者阅读学习。
03
为什么AI需要游戏?
游戏并非只有对弈。自电子游戏诞生起,有了非玩家角色(Non-Player Character)的概念,就有了游戏AI的强需求。引入非玩家角色,或对抗,或陪伴,或点缀,提升了游戏的难度,增强了游戏的沉浸感。与不同难度等级AI的对抗,也让玩家能够不断燃起挑战的欲望,增强游戏的粘性。另一方面,游戏行业也是AI发展最理想的试金石。
游戏提供了定义和构建复杂AI问题的平台。传统学术界的AI问题都是单一、纯粹的,每个问题面向一个特定任务,如:图片分类、目标检测、商品推荐等。走向通用AI,迟早要摆脱单一任务设定,去解决多输入、多场景和多任务下的复杂问题。从这点看,游戏是传统学术问题无法媲美的,即使是规则简单的棋类游戏,状态空间规模也是巨大的,包含各种致胜策略。从计算复杂性角度看,许多游戏都是NP-hard。在由这些难度铺设的爬山道上,研究者们相继攻克了:西洋棋(Checkers)、西洋双陆棋(Backgammon)、国际象棋(Chess)、中国象棋和围棋,以及简单电子游戏Atari系列和超级马里奥等。现在,人们正把目光放在更大型、更具挑战性的星际争霸(StarCraft)。
游戏提供了丰富的人机交互形式。游戏中人机交互是指人的各种操作行为以及机器呈现给人的各种信息,具有快节奏多模态的特征。一方面,游戏要么是回合制的,如:围棋、大富翁,要么是实时的,如:极品飞车、星际争霸,人机交互的频率一般都是秒级,有的稍长(如围棋),有的更短(如极品飞车);另一方面,人们通过键盘、鼠标和触摸板控制游戏中的角色,但不限于此,在一些新出的游戏中,人们还可通过移动身体、改变身体姿态和语音控制的方式参与游戏,如果将交互信息的形态考虑进来,有动作、文本、图片、语音等,如果将交互信息在游戏中的作用考虑进来,可以是以第一人称方式直接控制角色,如各类RPG游戏,可以是以角色切换的方式控制一个群体,如:实况足球,还可以从上帝视角经营一个部落、一个公司或一个国家,如:文明。复杂的人机交互方式,形成了一个认知、行为和情感上的模式闭环——引发(Elicit)、侦测(Detect)和响应(Respond),将玩家置身于一个连续的交互模式下,创造出与真实世界相同的玩家体验。想象一下,AI算法做的不再是拟合数据间的相关性,而是去学习一种认知、行为和情感上的人类体验。
游戏市场的繁荣提供了海量的游戏内容和用户数据。当前大部分AI算法都是数据驱动的,以深度学习为例,欲得到好的实验效果,需要的训练集都在千万级规模以上。在软件应用领域,游戏是内容密集型的。当前游戏市场,每年都会产生很多新游戏,游戏种类五花八门。因此,无论从内容、种类还是数量上,数据都呈爆炸式增长。此外,随着各类游戏社区的壮大,玩家提出了更高的要求,期待获得更好的玩家体验,游戏行业被推向新的纪元。除了游戏内容数据,随着玩家群体延伸到各年龄层、各类职业人群,用户行为数据也爆炸式增长,游戏大数据时代已然来临。
游戏世界向AI全领域发出了挑战。很多电子游戏都有一个虚拟的时空世界,各种实时的多模态的时空信号,在人与机器间频繁传送,如何融合这些信号做出更好的预测,是信号处理科学的一个难题。棋类游戏不涉及虚拟世界,规则简单清晰,没有各类复杂信号,但解决这类问题也不是一件简单的事情,因为状态空间庞大,所以要设计高效的搜索方法,如国际象棋、西洋棋依靠MiniMax树搜索,围棋用到蒙特卡洛树搜索。此外,解决围棋问题更少不了深度学习和强化学习方法。早年的电视游戏和街机游戏,都是通过二维画面和控制杆的方式实现人机交互,如果让AI像人一样在像素级别上操作控制杆玩游戏,就用到深度学习中最火的卷积神经网络,并与强化学习结合为深度强化学习方法。Jeopardy!是美国很流行的一个知识问答类真人秀,AI要解决知识问答,既要用到自然语言处理技术,也要具备一定的通识知识,掌握知识表征和推理的能力。另外,规划、导航和路径选择,也是游戏中常见的AI问题。更大型的游戏如星际争霸,场景更复杂,既是实时的又是策略的,集成了各类AI问题。
当然,游戏也需要AI,升级的AI会大大增加游戏的玩家体验。以前游戏中的AI大都是写死的,资深玩家很容易发现其中的漏洞。刚开始时,玩家找到这些漏洞并借以闯关升级,这带来很大乐趣;慢慢地,玩家厌倦了一成不变的难度和重复出现的漏洞。如果AI是伴随玩家逐步进化的,这就有意思了。还有一点,传统游戏AI属于游戏系统自身,获取的是程序内部数据,和玩家比有不对称优势。现在的AI要在玩家视角下,采用屏幕画面作为AI系统的输入,像一个人类玩家来玩游戏。智能体与人类玩家,不仅存在对抗,还存在协作。我们甚至可以建立一个协作平台,用自然语言的方式,向AI传达指令,或接收来自AI的报告。总之,在游戏这个超级AI试验场上,一切皆有可能。
![]()
《百面机器学习》
《百面机器学习》业已上市
首日荣登京东计算机新书榜第1名
15位一线算法工程师的鼎力佳作
124道基于真实场景的原创面试题
内容丰富,讲解详实
无论是求职面试还是在职学习
这都是一本值得珍藏的技术宝典
现在入手,赢在起跑线
点击原文链接了解书籍详细情况及购买方式
现在下单还可以领券优惠~

更多精彩内容,尽在阅读原文