【自然语言处理】情感分析(三):基于 Word2Vec 的 LSTM 实现
情感分析(三):基于 Word2Vec 的 LSTM 实现
本文是 情感分析 系列的第 3 3 3 篇,前两篇分别是:
- 【自然语言处理】情感分析(一):基于 NLTK 的 Naive Bayes 实现
- 【自然语言处理】情感分析(二):基于 scikit-learn 的 Naive Bayes 实现
本文代码已上传至 我的GitHub,需要可自行下载。
1.数据准备
import sys
sys.path.append("..") # Adds higher directory to python modules path.
from NLPmoviereviews.data import load_data
load_data 函数有一个 percentage_of_sentences 参数。如果一开始就使用全量数据集可能会使计算速度变慢,甚至可能导致 RAM 溢出。因此,应该从 10 % 10\% 10% 的句子开始,看看计算机是否能处理它。否则,以较小的比例重新运行。
X_train, y_train, X_test, y_test = load_data(percentage_of_sentences=10)
2.基线模型
基线是非常基本的模型或解决方案。通常会创建一个基线,然后尝试制作更复杂的解决方案,以获得更好的结果。
我们的基线可以是预测 y_train 中出现最多的标签(如果数据集是平衡的,则基线精度为 1 / n 1/n 1/n,其中 n n n 是类的数量,此处为 2 2 2)。
import pandas as pd
pd.Series(y_test).value_counts()
![]()
baseline_accuracy=1/2
print(f'Baseline accuracy on the test set : {baseline_accuracy:.2f}')
![]()
3.Word2Vec
Gensim 在数据存储库中附带了几个已经预训练的模型:
from gensim.models import Word2Vec
import gensim.downloader as api
print(list(api.info()['models'].keys()))
![]()
对这一块不太理解的可以查看我的这篇博客:【自然语言处理】Gensim中的Word2Vec。
加载其中一个预训练的 Word2Vec 嵌入空间。(glove-wiki-gigaword-100 约 128MB 大小)
word2vec_transfer=api.load('glove-wiki-gigaword-100')
默认的存储路径如下所示:

对 X_train 和 X_test 进行嵌入。
import numpy as np
from NLPmoviereviews.utilities import padding
看一下 padding 的实现过程。
为了实现的简便,keras 只能接受长度相同的序列输入。因此,如果目前序列长度参差不齐,这时需要使用 pad_sequences。该函数是将序列转化为经过填充以后的一个长度相同的新序列新序列。
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# 将句子(单词列表)转换为表示嵌入空间中单词的矩阵
def embed_sentence_with_TF(word2vec, sentence):
"""
Function to convert a sentence (list of words) into a matrix representing the words in the embedding space
"""
embedded_sentence = []
for word in sentence:
if word in word2vec:
embedded_sentence.append(word2vec[word])
return np.array(embedded_sentence)
# 将句子列表转换为矩阵列表
def embedding(word2vec, sentences):
"""
Function that converts a list of sentences into a list of matrices
"""
embed = []
for sentence in sentences:
embedded_sentence = embed_sentence_with_TF(word2vec, sentence)
embed.append(embedded_sentence)
return embed
def padding(word2vec, X, maxlen):
X_embed = embedding(word2vec, X)
X_pad = pad_sequences(X_embed, dtype='float32', padding='post', maxlen=maxlen)
return X_pad
X_train_pad = padding(word2vec_transfer, X_train, maxlen=200)
X_test_pad = padding(word2vec_transfer, X_test, maxlen=200)
X_train_pad.shape, y_train.shape, X_test_pad.shape, y_test.shape
![]()
对 X_train_pad 和 X_test_pad 进行以下测试:
- 它们是 numpy 数组
- 它们是 3 3 3 维的
- 最后一个维度是 Word2Vec 嵌入空间的大小(可以用
word2vec.wv.vector_size得到) - 第一个维度是
X_train和X_test的大小
# TEST
for X in [X_train_pad, X_test_pad]:
assert type(X) == np.ndarray
assert X.shape[-1] == word2vec_transfer.vector_size
assert X_train_pad.shape[0] == len(X_train)
assert X_test_pad.shape[0] == len(X_test)
4.RNN Model:LSTM
如果你此前不了解 LSTM(Long Short-Term Memory),可以查看我的这篇博客【神经网络】图解LSTM和GRU。在我们构建神经网络之前先来了解几个概念。
当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能(generalization performance,即可以很好地拟合数据)。但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。
EarlyStopping(早停法)是 callbacks 的一种,callbacks 用于指定在每个 epoch 开始和结束的时候进行哪种特定操作。callbacks 中有一些设置好的接口,可以直接使用,如 acc、val_acc、loss 和 val_loss等等。
EarlyStopping 则是用于提前停止训练的 callbacks。具体地,可以达到当训练集上的 l o s s loss loss 不再减小(即减小的程度小于某个阈值)的时候停止继续训练。使用 EarlyStopping 也可以加快学习的速度,提高调参效率。
tensorflow.keras.optimizers 提供了以下几种内置优化器类:Adadelta、Adagrad、Adam、Adamax、Ftrl、Nadam、Optimizer、RMSprop、SGD。
keras.layers.Masking(mask_value=0.0) 是用于对值为指定值的位置进行掩蔽的操作,以忽略对应的 timestep。在输入张量的每个时刻(即输入张量的第一个维度),如果输入张量在这一时刻的所有值都等于指定的 mask_value,那么这一时刻将会在接下来的下游层都会被跳过(只要其支持 masking 操作)。如果下游层不支持 masking 操作,那么就会报错。
Bidirectional:双向循环网络包装器。可以将 LSTM,GRU 等层包装成双向循环网络。从而增强特征提取能力。
Dropout:随机置零层。训练期间以一定几率将输入置 0 0 0,一种正则化手段。
Dense:密集连接层。参数个数 = 输入层特征数 × 输出层特征数(weight)+ 输出层特征数(bias)
model.compile 方法用于在配置训练方法时,告知训练时用的 优化器、损失函数、准确率评测标准。
from tensorflow.keras import models, layers
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import RMSprop, Adam, SGD
if 'model' in globals():
del model
model = models.Sequential() # 线性堆叠网络
model.add(layers.Masking(mask_value=0, input_shape=(200,100)))
model.add(layers.Bidirectional(layers.LSTM(200, activation='tanh')))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(100, activation="relu"))
model.add(layers.Dense(20, activation="relu"))
model.add(layers.Dense(1, activation="sigmoid"))
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=0.00001), metrics=['accuracy'])
对整个网络结构进行一个简单的可视化。(注意 tensorflow 版本,本处是 2.0 2.0 2.0)
import tensorflow as tf
tf.keras.utils.plot_model(model, show_shapes=True, show_layer_names=True, rankdir="TB",expand_nested=True, dpi=200)

es = EarlyStopping(patience=15, restore_best_weights=True, verbose=1)
EarlyStopping 参数的含义:

# Fit the model on the train data
history = model.fit(X_train_pad, y_train,
validation_split=0.2,
epochs = 180,
batch_size = 64,
verbose = 0,
callbacks = [es])

拟合的时间可能比较长。
5.预测
res = model.evaluate(X_test_pad, y_test, verbose=0)
print(f'The accuracy evaluated on the test set is of {res[1]*100:.3f}%')
![]()
6.绘制拟合曲线
import matplotlib.pyplot as plt
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 8))
ax1.plot(history.history['loss'], label = 'train')
ax1.plot(history.history['val_loss'], label = 'val')
#ax1.set_ylim(0., 0.5)
ax1.set_title('loss')
ax1.legend()
ax2.plot(history.history['accuracy'], label='train accuracy')
ax2.plot(history.history['val_accuracy'], label='val accuracy')
#ax2.set_ylim(0., 0.015)
ax2.set_title('accuracy')
ax2.legend()
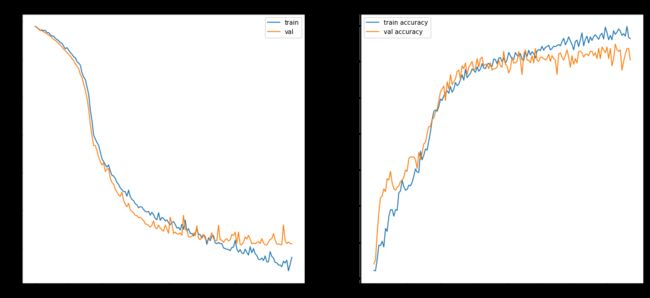
本文提供了一个基线模型,其实可以进一步进行优化,比如利用 C L R CLR CLR(Cyclical Learning Rates for Training Neural Networks, Leslie N. Smith 2017)加速学习过程。