行人属性识别研究综述(二)
文章目录
- 6 PAR(行人属性识别)算法综述
-
- 6.1全局基于图像的模型
-
- 6.1.1 ACN (iccvw-2015)
- 6.1.2 DeepSAR and DeepMAR (ACPR-2015) [6]
-
- 6.1.3 MTCNN (TMM-2015) [7]
- 6.2 基于部件的模型
-
- 6.2.1 Poselets (ICCV-2011)
- 6.2.2 rad (iccv-2013)
- 6.2.3 PANDA (cvp -2014) [10]
- 6.2.4 MLCNN (ICB-2015) [11]
- 6.2.5 AAWP (ICCV-2015) [12]
- 6.2.6 ARAP (BMVC2016) [13]
- 6.2.7 DeepCAMP (CVPR-2016) [14]
- 6.2.8 PGDM (ICME-2018) [15]
- 6.2.9 DHC (eccv-2016) [16]
- 6.2.10 LGNet (BMVC-2018) [17]
- 6.3 基于注意力的模型
-
- 6.3.1 HydraPlus-Net (ICCV-2017)
- 6.3.2 VeSPA (ArXiv-2017) [19]
- 6.3.3 DIAA (ECCV-2018) [20]
- 6.3.4 CAM (PRL-2017) [21]
- 6.4 基于序列预测的模型
-
- 6.4.1 cnn-rnn (cvpr-2016)
- 6.4.2 JRL (ICCV-2017) [23]
- 6.4.3 GRL (IJCAI-2018) [24]
- 6.4.4 JCM (arXiv-2018) [25]
- 6.4.5 RCRA (AAAI-2019) [102]
- 6.5 基于损失函数的模型
-
- 6.5.1 WPAL-network (BMVC-2017)[26]
- 6.5.2 AWMT (MM-2017) [27]
- 6.6 基于算法的课程学习
-
- 6.6.1 MTCT (wacv-2017) [109]
- 6.6.2 CILICIA (ICCV-2017) [110]
- 6.7 基于图模型的算法
-
- 6.7.1 DCSA (ECCV-2012) [28]
- 6.7.2 A-AOG (TPAMI-2018) [29]
- 6.7.3 VSGR (AAAI-2019) [30]
- 6.8 其他算法
-
- 6.8.1 PatchIt (BMVC-2016) [31]
- 6.8.2 FaFS (CVPR-2017)
- 6.8.3 GAM (AVSS-2017) [33]
- 7 应用
- 8 未来研究方向
-
- 8.1更精确高效的局部定位算法
- 8.2用于数据增强的深度生成模型
- 8.3进一步探索视觉注意机制
- 8.4 新设计的损失函数
- 8.5 探索更高级的网络架构
- 8.6 先验知识引导学习
- 8.7 多模态行人属性识别
- 8.8 基于视频的行人属性识别
- 8.9 属性与其他任务的联合学习
- 9 结论
行人属性识别研究综述(一)
欢迎阅读 【AI浩】 的博客 阅读完毕,可以动动小手赞一下 发现错误,直接评论区中指正吧 这是一篇研究行人属性识别综述论文 论文链接: Pedestrian Attribute Recognition: A Survey
6 PAR(行人属性识别)算法综述
在本节中,我们将从以下八个方面综述基于深度神经网络的PAR算法:基于全局的、基于局部部件的、基于视觉注意的、基于序列预测的、基于新设计的损失函数的、基于课程学习的、基于图模型的和其他算法。

6.1全局基于图像的模型
在本节中,我们将回顾只考虑全局图像的PAR算法,如ACN [5], DeepSAR [6], DeepMAR[6], MTCNN[7]。
6.1.1 ACN (iccvw-2015)
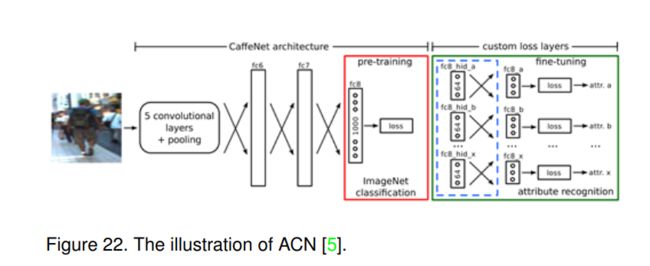
提出了一种基于卷积网络的多分支分类层的属性学习方法。如图22所示,他们采用预训练的AlexNet作为基本特征提取子网络,并使用KL-loss (Kullback-Leibler divergence based loss function)将最后的全连接层替换为每个属性一个损失。具体配方如下:
K L ( P ∥ Q ) = ∑ i N P ( x i ) log Q ( x i ) P ( x i ) (11) K L(P \| Q)=\sum_{i}^{N} P\left(x_{i}\right) \log \frac{Q\left(x_{i}\right)}{P\left(x_{i}\right)} \tag{11} KL(P∥Q)=i∑NP(xi)logP(xi)Q(xi)(11)
其中Q是神经网络的预测,P是二进制属性的实际状态。
此外,他们还提出了一个名为PARSE-27k的新数据集来支持他们的评估。该数据集包含27000名行人,并配有10个属性标注。与普通的行人属性数据集不同,他们提出了一种新的类别标注方法,即,不可判定(N/A)。因为对于大多数输入图像,由于遮挡、图像边界或任何其他原因,一些属性是不可判定的。
6.1.2 DeepSAR and DeepMAR (ACPR-2015) [6]
针对传统行人属性识别方法中存在的2个问题,引入深度神经网络进行行人属性识别:1)现有方法中使用的手工特征,如HOG、颜色直方图、LBP (local binary patterns);2).属性之间的相关性通常被忽略。本文提出了DeepSAR和DeepMAR两种算法,如图23所示。他们采用AlexNet作为骨干网络,通过将最后一个密集层定义的输出类别更改为两个来获得DeepSAR。采用softmax损失计算最终的分类损失。
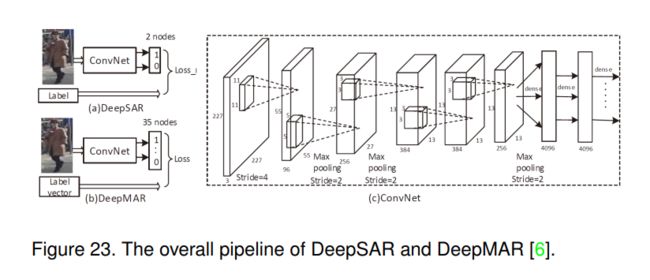
尽管DeepSAR可以使用深度特征进行二分类。然而,它没有对人类属性之间的相关性进行建模,而这可能是进一步提高整体识别性能的关键。因此,他们提出了DeepMAR,同时接收人类图像及其属性标签向量,并通过sigmoid交叉熵损失联合考虑所有属性:
L c e = − 1 N ∑ i = 1 N ∑ l = 1 L y i l log ( P ^ i l ) + ( 1 − y i l ) log ( 1 − p i l ^ ) (12) L_{c e}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{l=1}^{L} y_{i l} \log \left(\hat{P}_{i l}\right)+\left(1-y_{i l}\right) \log \left(1-\hat{p_{i l}}\right) \tag{12} Lce=−N1i=1∑Nl=1∑Lyillog(P^il)+(1−yil)log(1−pil^)(12)
p i l ^ = 1 1 + exp ( − x i l ) (13) \hat{p_{i l}}=\frac{1}{1+\exp \left(-x_{i l}\right)}\tag{13} pil^=1+exp(−xil)1(13)
其中 p i l ^ \hat{p_{i l}} pil^是样本 x i x_i xi第l个属性的估计得分。 y i l y_{il} yil是最真实的标签。
此外,他们还考虑了实际监控场景中的标签分布不平衡问题,提出了一种改进的损失函数如下:
L w c e = − 1 N ∑ i = 1 N ∑ l = 1 L w l ( y i l log ( P i l ^ ) + ( 1 − y i l ) log ( 1 − p i l ^ ) ) (14) L_{w c e}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{l=1}^{L} w_{l}\left(y_{i l} \log \left(\hat{P_{i l}}\right)+\left(1-y_{i l}\right) \log \left(1-\hat{p_{i l}}\right)\right) \tag{14} Lwce=−N1i=1∑Nl=1∑Lwl(yillog(Pil^)+(1−yil)log(1−pil^))(14)
w l = exp ( − p l / σ 2 ) (15) w_{l}=\exp \left(-p_{l} / \sigma^{2}\right) \tag{15} wl=exp(−pl/σ2)(15)
其中 w l w_{l} wl是第l层属性的损失权重。 p l p_l pl表示训练数据集中l层属性的正比率。 σ \sigma σ是一个超参数。
6.1.3 MTCNN (TMM-2015) [7]
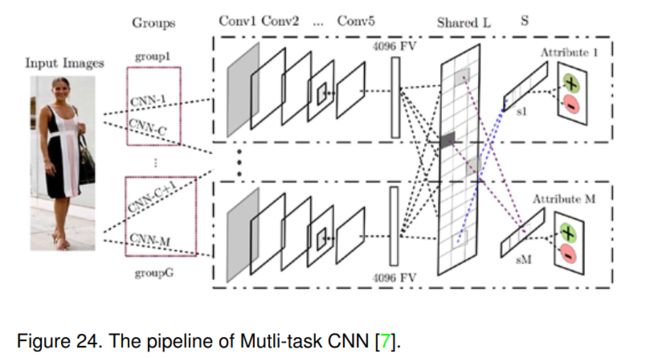
文中提出了一种利用CNN进行属性估计的联合多任务学习算法MTCNN,如图24所示。MTCNN让CNN模型在不同属性类别之间共享视觉知识。通过对CNN特征进行多任务学习来估计相应的属性。在他们的MTL框架中,他们还使用了丰富的信息组,因为知道任何关于特征统计信息的先验信息肯定会帮助分类器。利用分解方法从分类器总权重矩阵W中得到可共享的潜在任务矩阵L和组合矩阵S,通过学习局部特征 W = L S W = LS W=LS实现灵活的组间全局共享和竞争。因此,目标函数(MTL squared maxing hinge loss)表示为:
min L , S ∑ m = 1 M ∑ i = 1 N m 1 2 [ max ( 0 , 1 − Y m i ( L s m ) T X m i ) ] 2 + μ ∑ k = 1 K ∑ g = 1 G ∥ s k g ∥ 2 + γ ∥ L ∥ 1 + λ ∥ L ∥ F 2 (16) \begin{array}{r} \min _{L, S} \sum_{m=1}^{M} \sum_{i=1}^{N_{m}} \frac{1}{2}\left[\max \left(0,1-Y_{m}^{i}\left(L s^{m}\right)^{T} X_{m}^{i}\right)\right]^{2}+ \\ \mu \sum_{k=1}^{K} \sum_{g=1}^{G}\left\|s_{k}^{g}\right\|_{2}+\gamma\|L\|_{1}+\lambda\|L\|_{F}^{2} \end{array} \tag{16} minL,S∑m=1M∑i=1Nm21[max(0,1−Ymi(Lsm)TXmi)]2+μ∑k=1K∑g=1G∥skg∥2+γ∥L∥1+λ∥L∥F2(16)
其中 ( X m i , Y m i ) i = 1 N m \left(X_{m}^{i}, Y_{m}^{i}\right)_{i=1}^{N_{m}} (Xmi,Ymi)i=1Nm为训练数据, N m N_m Nm为第m个属性的训练样本数量。K是总潜在任务维度空间。将第m个属性类别的模型参数记为 L s m Ls^m Lsm。
他们采用加速近端梯度下降(APG)算法交替优化L和S。因此,在得到L和S之后,就可以得到整体的模型权重矩阵W。
总结:根据上述算法[5][6][6][7],我们可以发现这些算法都是将整幅图像作为输入,对PAR进行多任务学习。它们都试图通过特征共享、端到端训练或多任务学习平方最大hinge损失来学习更鲁棒的特征表示。这些模型简单、直观、高效,在实际应用中具有重要意义。然而,由于缺乏对细粒度识别的考虑,这些模型的性能仍然有限。
6.2 基于部件的模型
在本节中,我们将介绍一些基于局部和全局信息的算法,包括:Poselets[8]、RAD[9]、PANDA[10]、MLCNN[11]、AAWP[12]、ARAP[13]、DeepCAMP[14]、PGDM[15]、DHC[16]、LGNet[17]。
6.2.1 Poselets (ICCV-2011)
本文的动机是,如果我们可以从相同的视角分离出对应于相同身体部位的图像块,则可以更简单地训练属性分类器。然而,由于目标检测器能力有限,直接使用目标检测器进行人体部位定位在当时(2011年之前)并不可靠。因此,采用poselets[46]将图像分解为一组部分,每个部分捕捉一个对应于给定视角和局部姿态的显著模式。这提供了一个强大的人的分布式表示,从中可以推断出属性,而无需显式地定位不同的身体部位。
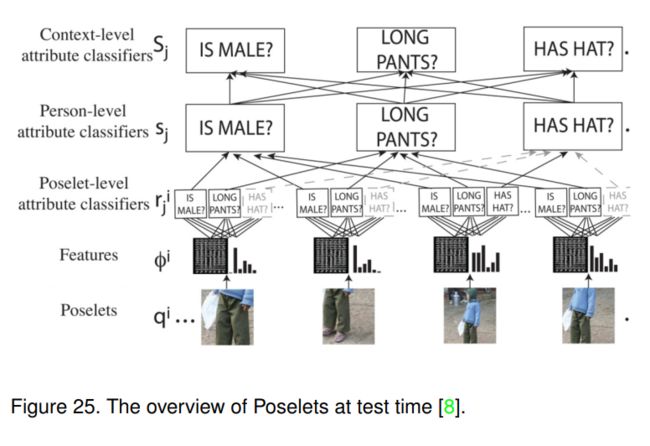
图25展示了Poselets的整体流程。首先,他们检测给定图像上的poselets,并通过连接HOG、颜色直方图和皮肤掩膜特征来获得它们的联合表示。然后训练多个SVM分类器,分别用于poselet级、人级和上下文级的属性分类;poselet级分类器的目标是在给定的视点下,根据人体的给定部位判断某一属性是否存在。其中,个人级分类器用于综合来自人体各部位的证据,上下文级分类器则将所有个人级分类器的输出作为输入,利用各属性之间的相关性。它们的属性预测结果是上下文级分类器的输出。
将poselets与深度神经网络相结合[88],将其思想进行了扩展,命名为deep poselets。它可以用于基于人体部位定位的任务,如人体检测任务[89]。
6.2.2 rad (iccv-2013)
从外观变化的角度出发,提出了一种局部学习算法,以往的工作侧重于处理几何变化,需要人工标注局部,如poselet[8]算法。首先将图像格划分为若干重叠的子区域(称为窗口);如图26 (a)所示,定义大小为W × H的网格,网格上的任何矩形包含一个或多个网格单元格,即为窗口。该方法在局部窗口的形状、大小和位置等方面具有更大的灵活性,而以往的工作(如空间金字塔匹配结构,SPM[90])将区域递归划分为四个象限,并使所有子区域都是在同一层次上互不重叠的正方形。
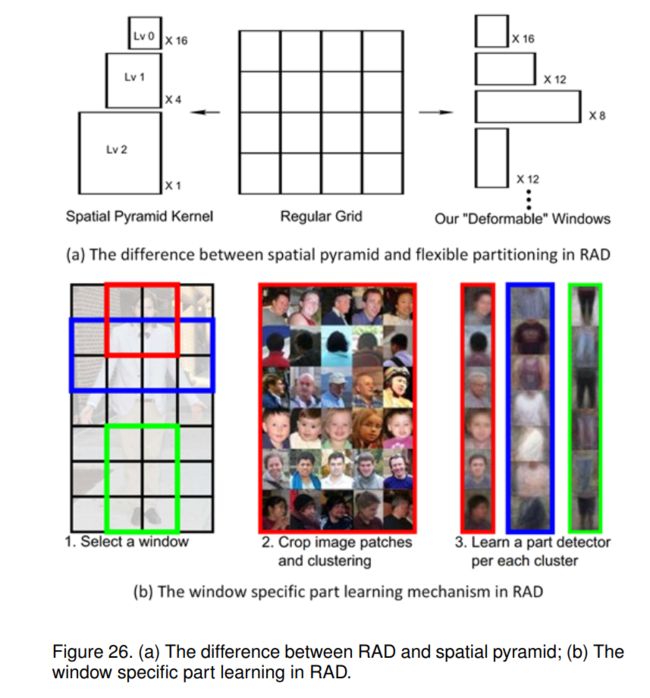
通过所有这些窗口,它们学习一组与该特定窗口在空间上相关联的部件检测器。对于每个窗口,从训练图像中裁剪出所有对应的图像块,并使用HOG[1]和颜色直方图特征描述子表示。然后,基于提取的特征进行K-means聚类;每个得到的簇表示零件的特定外观类型。他们还通过逻辑回归为每个聚类训练一个局部部分检测器作为初始检测器,并通过将其再次应用于整个集合并更新最佳位置和规模来迭代完善它,以处理噪声聚类的问题。
在学习多尺度重叠窗口下的部分后,遵循基于poselet的[8]方法进行属性分类。具体来说,它们将来自这些局部分类器的分数与部分检测分数给出的权重进行聚合,以进行最终预测。
6.2.3 PANDA (cvp -2014) [10]
Zhang等人发现与某些属性相关的信号是细微的,图像受姿态和视角的影响。对于佩戴眼镜的属性,在整个人的尺度上信号较弱,且外观随着头部姿态、框架设计和头发遮挡的变化而显著变化。他们认为准确预测基础属性的关键在于定位对象部件并建立它们与模型部件的对应关系。他们提出联合使用全局图像块和局部块进行行人属性识别,整体流程如图27 (a)和(b)所示。
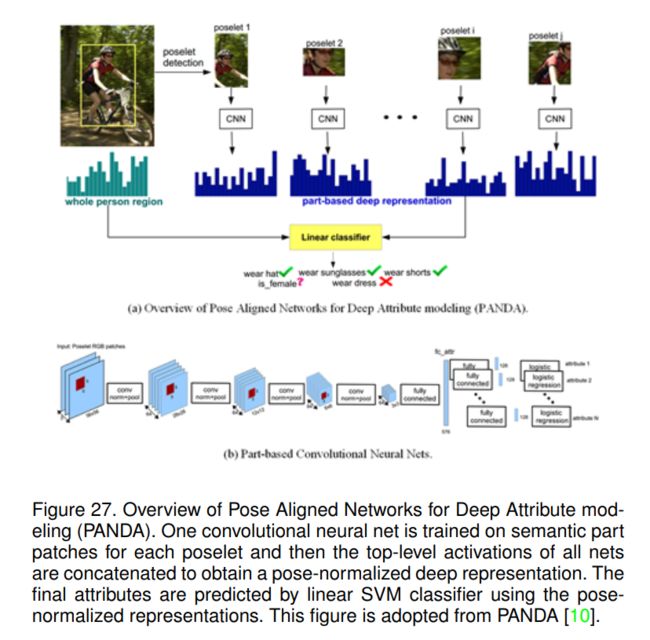
如图27 (a)所示,他们首先检测了poselets[8],获得了人体的部分。然后利用卷积神经网络提取局部图像块和整个图像块的特征表示;对于未检测到的poselet,他们只是将特征设置为0。因此,他们的模型可以利用卷积网络从数据中学习判别特征的能力,以及poselets通过将对象分解为其典型姿态来简化学习任务的能力。它们直接将组合后的局部和全局特征输入线性分类器,即SVM(支持向量机)进行多属性估计。
图27 (b)给出了详细的架构,该网络以poselet RGB patch 56 × 56 × 3作为输入,并输出每个属性对应的全连接层(fc层)的响应分数。特征提取模块包含四组卷积/池化/归一化层,这些组的输出分别是28×28×64, 12×12×64, 6×6×64和3×3×64。然后通过全连接层将输入图像映射为维数为576-D的特征向量;他们为每个输出尺寸为128的属性设置fc层。
该工作的优点是采用了深度特征而不是浅层的低层特征,可以获得比之前工作更强大的特征表示。此外,它还分别从局部图像块和全局图像的角度对人体图像进行处理,比只考虑图像整体的方法能挖掘出更多的细节信息。这两点都显著提高了行人属性的识别率。然而,我们认为以下问题可能会限制他们的最终性能:1)零件的本地化,即poselets的准确性,可能是他们结果的瓶颈;2)它们没有使用端到端的学习框架来学习深度特征;3).它们的poselet还包含背景信息,这些背景信息也会影响特征表示。
6.2.4 MLCNN (ICB-2015) [11]
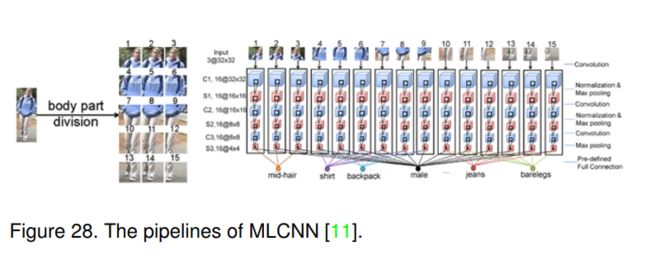
文中提出了一种多标签卷积神经网络,在统一的框架下共同预测多个属性。其网络的整体流程如图28所示。他们将整个图像分成15个重叠的块,并使用卷积网络提取其深度特征。对于特定的属性分类,采用相应的局部部分,如patch 1;2;3用于发型估计。他们使用softmax函数进行每个属性预测。
此外,它们还利用预测属性来辅助行人再识别。具体来说,它们将底层的特征距离和基于属性的距离融合作为最终的融合距离,以区分给定的图像是否具有相同的身份。
6.2.5 AAWP (ICCV-2015) [12]
引入AAWP模型,验证局部对动作识别和属性识别的改进作用。如图29(1)所示,CNN特征是在与实例相关联的一组边界框上计算进行分类的,即整个实例,提供的oracle或person检测器和提供的poselet样部件检测器。作者定义了三个人体部位(头、躯干和腿),并将每个部位的关键点聚类为几个不同的poselets。由于使用了深度特征金字塔,而不是传统poselets[8]中使用的低级梯度方向特征,因此这部分检测器被称为深度版本的poselets[91]。此外,作者还介绍了特定任务的CNN微调,他们的实验表明,经过微调的整体模型(即没有部件)已经可以取得与PANDA[10]等基于部件的系统相当的性能。具体来说,整个管道可以分为两个主要模块,即部件检测模块和细粒度分类模块,分别如图29(2)和(3)所示。
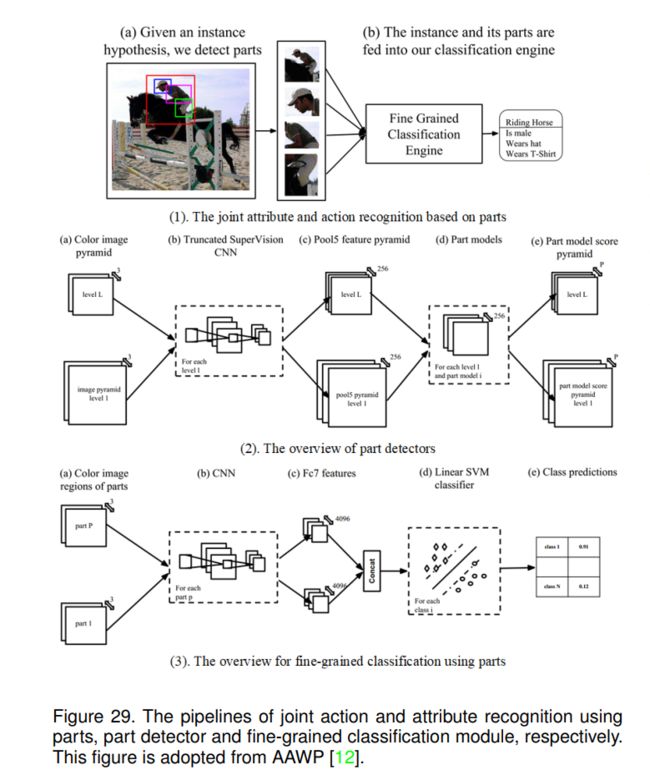
对于局部检测器模块,他们按照目标检测算法RCNN[92]设计网络,该算法包含两个阶段,即特征提取和部件分类。采用多尺度全卷积网络提取图像特征。更具体地说,他们首先构建彩色图像金字塔,并为每个金字塔层获取pool5特征。然后,采用零件模型获得相应的分数,如图29(2)所示。因此,关键问题在于给定这些特征地图金字塔,如何实现精确的零件定位。为了处理部件的定位,作者设计了三个身体区域(头部、躯干和腿部),并用线性svm训练部件检测器。正例训练数据采集自PASCAL VOC 2012,采用聚类算法。在测试阶段,他们将最高得分的部分保留在图像的候选区域框中。
针对他们所讨论的基于局部的分类任务,即动作和属性识别。他们考虑了四种不同的方法来理解哪些设计因素是重要的,即无部件、实例微调、联合微调和三向拆分。细粒度分类的详细流程如图29(3)所示。给定图像和被检测部件,使用CNN获取fc7特征并连接成一个特征向量作为其最终表示。因此,可以利用预训练的线性SVM分类器对行为或属性类别进行估计。在PASCAL VOC action challenge和Berkeley attributes of people数据集[8]上的实验验证了局部的有效性。此外,他们还发现,随着更强大的卷积网络架构的设计,来自显式部分的边际增益可能会消失。他们认为这可能是因为整体网络已经实现了很高的性能。
该工作进一步拓展和验证了部件在更大范围内的有效性和必要性。它还展示了基于深度学习的人体属性识别的更多见解。
6.2.6 ARAP (BMVC2016) [13]
采用一种端到端的学习框架进行联合部位定位和多标签分类的行人属性识别。如图30所示,ARAP包含以下子模块:初始卷积特征提取层、关键点定位网络、每个部件的自适应包围盒生成器和每个部件的最终属性分类网络。他们的网络包含三个损失函数,即回归损失、纵横比损失和分类损失。
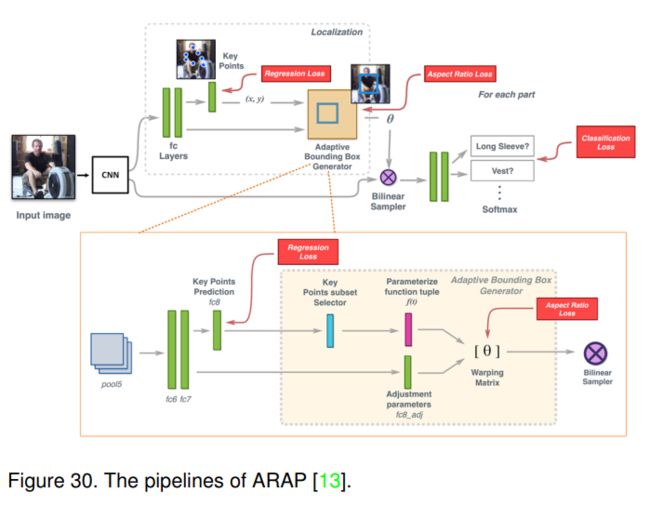
首先提取输入图像的特征图,然后进行关键点定位。给定关键点,将人体划分为三个主要区域(包括硬体、躯干和腿部),并得到一个初始部位边界框。另一方面,他们也将之前fc7层的特征作为输入,并估计边界框调整参数。给定这些边界框,采用双线性采样器提取相应的局部特征。然后,将特征输入到两个fc层进行多标签分类;
6.2.7 DeepCAMP (CVPR-2016) [14]
该文提出了一种新的卷积神经网络,通过挖掘中层图像块来进行细粒度的人体属性识别。具体来说,他们训练一个CNN来学习有区别的patch组,称为DeepPattern。它们利用常规的上下文信息(见图31(2)),并通过特征学习和块聚类的迭代来净化专用块集,如图31(1)所示。
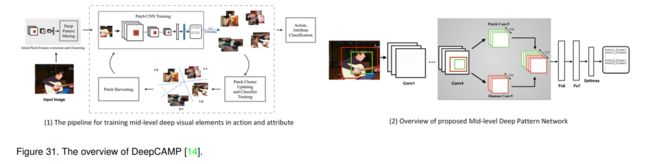
本文的主要观点在于,在模式挖掘算法[93]中,更好的嵌入有助于提高聚类算法的质量。因此,他们提出了一种迭代算法,在每次迭代中,他们训练一个新的CNN对前一次迭代中获得的簇标签进行分类,以帮助改进嵌入。另一方面,它们还连接了来自局部块和全局人体边界框的特征,以改进中层元素的聚类。
6.2.8 PGDM (ICME-2018) [15]
PGDM是第一个尝试探索行人身体结构知识(即行人姿态)进行行人属性学习的工作。他们首先使用预训练的姿态估计模型估计给定人体图像的关键点。然后根据这些关键点提取零件区域;分别提取局部区域和整幅图像的深度特征,独立用于属性识别。然后将这两个分数融合在一起,实现最终的属性识别。姿态估计的可视化和PGDM的整个流程分别如图32 (a)和(b)所示。
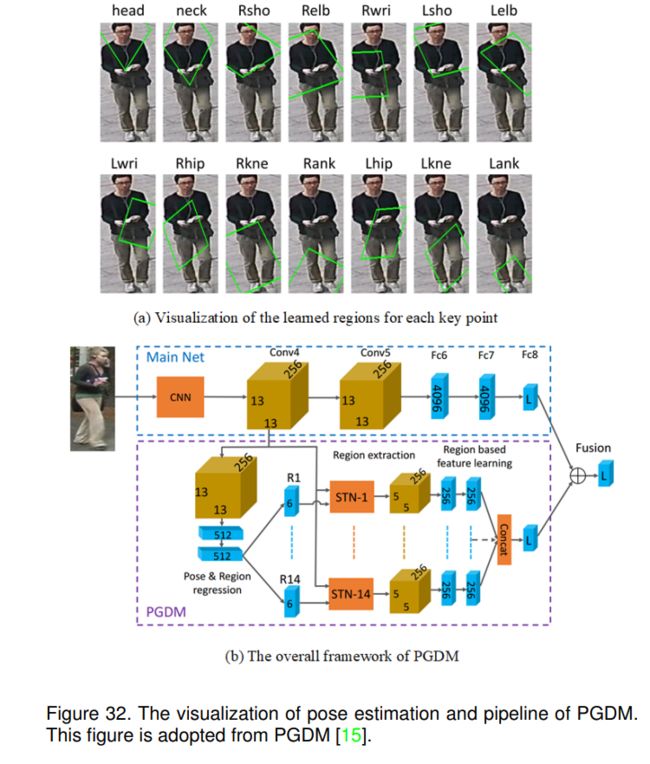
对于PGDM模块,其目标是探索可变形人体结构知识来辅助行人属性识别。作者求助于深度姿态估计模型,而不是重新标注训练数据的人体姿态信息。将现有的姿态估计算法嵌入到其属性识别模型中,而不是将其作为外部模型使用。他们直接训练一个回归网络,用从现有姿态估计模型中获得的粗糙的真实姿态信息来预测行人姿态。一旦获得姿态信息,他们使用空间transformer网络(STN)将关键点转换为信息区域[95]。然后,利用独立的神经网络对每个关键点相关区域进行特征学习;他们联合优化了主网络、PGDM和姿态回归网络。
6.2.9 DHC (eccv-2016) [16]
由于背景有时会提供比目标对象更多的信息,因此提出利用深度层次上下文来帮助行人属性识别。具体地,在其网络架构中引入了以人为中心的上下文和场景上下文。如图33所示,他们首先构建输入图像金字塔,并将其全部通过CNN(本文使用VGG-16网络)得到多尺度特征图。他们提取了四组边界框区域的特征,即整个人、检测到的目标对象部分、图像金字塔的最近邻部分和全局图像场景。前两个分支(整个人和部分)是行人属性识别算法的常规管道。本文的主要贡献在于后两个分支,即以人为中心的上下文和场景级别的上下文,以帮助提高识别效果。一旦得到这四个分支的得分,它们将所有得分相加作为最终的属性得分。
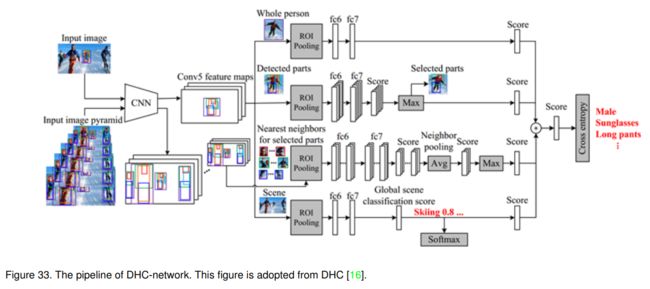
由于使用了上下文信息,该神经网络比常规的行人属性识别任务需要更多的外部训练数据。例如,他们需要检测人体的部分(头部,上下身体区域)并识别给定图像的风格/场景。他们提出了一个名为WIDER的新数据集,以更好地验证他们的想法。虽然通过该流水线可以显著提高人的属性识别结果,但是该模型与其他算法相比显得有些复杂。
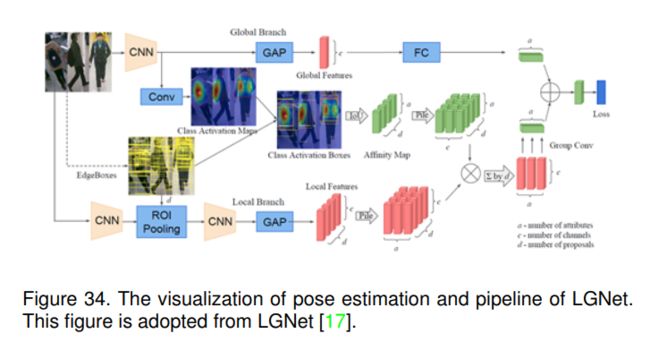
6.2.10 LGNet (BMVC-2018) [17]
提出了一种定位引导网络LGNet,该网络可以定位不同属性对应的区域。它也遵循local-global框架,如图34所示。具体来说,他们采用Inception-v2[96]作为基本的CNN模型进行特征提取。对于全局分支,采用全局平均池化层(GAP)来获取其全局特征;然后,利用全连接层输出其属性预测;对于局部分支,他们使用1 × 1卷积层为每个图像生成c类激活图,其中c是所使用数据集中属性的数量。给定类激活图,它们可以通过裁剪相应激活图的高响应区域来为每个属性捕获激活框。他们还使用EdgeBoxes[97]来生成建议区域,以从输入图像中获取局部特征。此外,它们还考虑了提取的候选框贡献度不同,不同的属性应关注不同的局部特征。因此,他们使用每个属性的类活动映射图作为指导来确定局部特征对不同属性的重要性。更具体地说,他们根据联合交互(IoU)计算建议框和类激活框之间的空间亲和力映射,并进行线性归一化,以对局部特征向量进行加权,以进行进一步的预测。最后采用元素求和的方法融合全局特征和局部特征进行行人属性预测。
摘要:在综述的论文[8][9][10][11][12][13][14][15][16][17]的基础上,不难发现这些算法都采用了全局和细粒度局部特征的联合利用。人体部位的定位是通过外部部位定位模块实现的,如部位检测、姿态估计、poselets或建议生成算法。利用零件信息显著提高了整体识别性能。但也带来了以下不足:首先,作为一个处于中间阶段的操作,最终的识别性能严重依赖于零件定位的准确性。也就是说,不准确的零件检测结果将会带来错误的特征用于最终的分类。其次,由于人体部位的引入,也需要更多的训练或推理时间。第三,部分算法需要人工标注局部位置信息,进一步增加了人力和资金成本。
6.3 基于注意力的模型
在本节中,我们将讨论使用注意力机制的行人属性识别算法,如HydraPlus-Net [18], VeSPA [19], DIAA [20], CAM[21]。
6.3.1 HydraPlus-Net (ICCV-2017)
引入HPNet对来自多个层次的多尺度特征进行编码,使用多方向注意力(MDA)模块进行行人分析。如图35(2)所示,它包含两个主要模块,即主网络(M-net)和注意力特征网络(AF-net),前者是一个常规的CNN,后者包括应用于不同语义特征层次的多方向注意力模块的多个分支。AF-net和M-net共享相同的基本卷积架构,它们的输出通过全局平均池化(GAP)和fc层连接和融合。输出层可以是用于属性识别的属性对数,也可以是用于行人再识别的特征向量。作者采用inceptionv2[98]作为他们的基本网络。
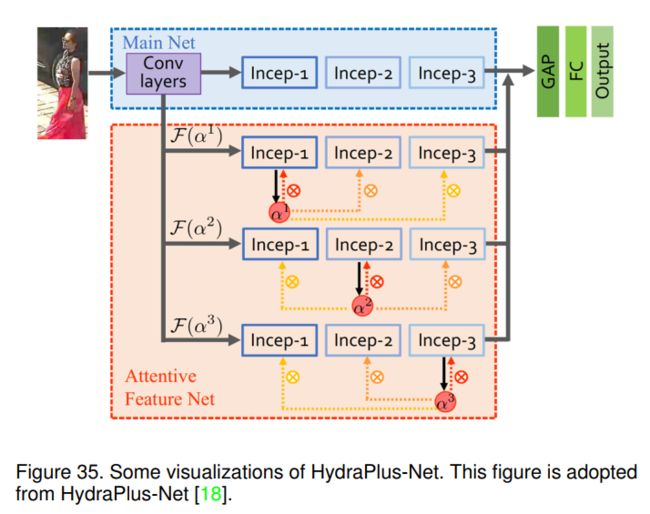
图35(4)给出了AF-net的具体示意图。给定黑色1、2、3的特征图,对特征图2进行1 × 1的卷积运算,得到其注意图α2。值得注意的是,这个注意力模块不同于之前的基于注意力的模型,后者仅将注意图推回到相同的块。他们不仅使用这个注意力图来关注特征图2,还关注相邻的特征,如特征图1和3。将单个注意图应用于多个块,自然地使融合的特征在相同的空间分布中编码多级信息,如图35(3)所示。
HP-net以分阶段的方式进行训练,即M-net、AF-net以及剩余的GAP和fc层以顺序的方式进行训练。输出层用于最小化交叉熵损失和softmax损失,分别进行行人属性识别和行人重识别。
6.3.2 VeSPA (ArXiv-2017) [19]
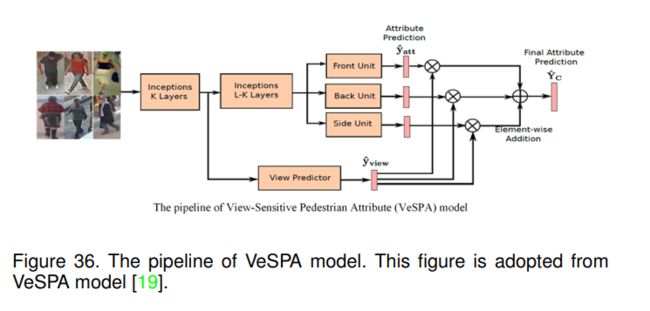
VeSPA将视图信息考虑在内,以更好地估计相应的属性。这是因为作者发现暗示属性的视觉线索具有很强的局部性,可以对人的属性(如头发、背包、短裤等)进行推断。高度依赖于行人获得的视角。如图36所示,将图像输入到inception (K层)并获得其特征表示。引入视图相关单元将特征映射映射为粗属性预测 y ^ a t t = [ y 1 , y 2 , … , y c ] T \hat{y}_{a t t}=\left[y^{1}, y^{2}, \ldots, y^{c}\right]^{T} y^att=[y1,y2,…,yc]T。然后,使用视图预测器估计视图权重y^view。注意力权重用于相乘特定视图的预测,并获得最终的多类属性预测 Y ^ c = [ y 1 , y 2 , … , y C ] T \hat{Y}_{c}=\left[y^{1}, y^{2}, \ldots, y^{C}\right]^{T} Y^c=[y1,y2,…,yC]T。
视图分类器和属性预测器使用单独的损失函数进行训练。整个网络是一个统一的框架,可以以端到端的方式进行训练。
6.3.3 DIAA (ECCV-2018) [20]
DIAA算法可以看作是一种用于行人属性识别的集成方法。如图37所示,他们的模型包含以下模块:用于深度不平衡分类的多尺度视觉注意和加权焦点损失。在多尺度视觉注意方面,从图37中可以看出,作者采用了不同层的特征图。他们提出了加权焦点损失函数[99]来衡量预测属性向量和真实值之间的差异:
L w ( y ^ p , y ) = − ∑ c = 1 C w c ( ( 1 − σ ( y ^ p c ) ) γ log ( σ ( y ^ p c ) ) y c + σ ( y ^ p c ) γ log ( 1 − σ ( y ^ p c ) ) ( 1 − y c ) ) , (17) \begin{array}{r} \mathcal{L}_{w}\left(\hat{y}_{p}, y\right)=-\sum_{c=1}^{C} w_{c}\left(\left(1-\sigma\left(\hat{y}_{p}^{c}\right)\right)^{\gamma} \log \left(\sigma\left(\hat{y}_{p}^{c}\right)\right) y^{c}+\right. \\ \left.\sigma\left(\hat{y}_{p}^{c}\right)^{\gamma} \log \left(1-\sigma\left(\hat{y}_{p}^{c}\right)\right)\left(1-y^{c}\right)\right), \end{array} \tag{17} Lw(y^p,y)=−∑c=1Cwc((1−σ(y^pc))γlog(σ(y^pc))yc+σ(y^pc)γlog(1−σ(y^pc))(1−yc)),(17)
其中 γ \gamma γ是一个参数,用于控制基于当前预测的实例级加权,重点是难分类的错误样本。 w c = e − a c wc = e^{−ac} wc=e−ac, ac是c层属性在[19]之上的先验类分布。
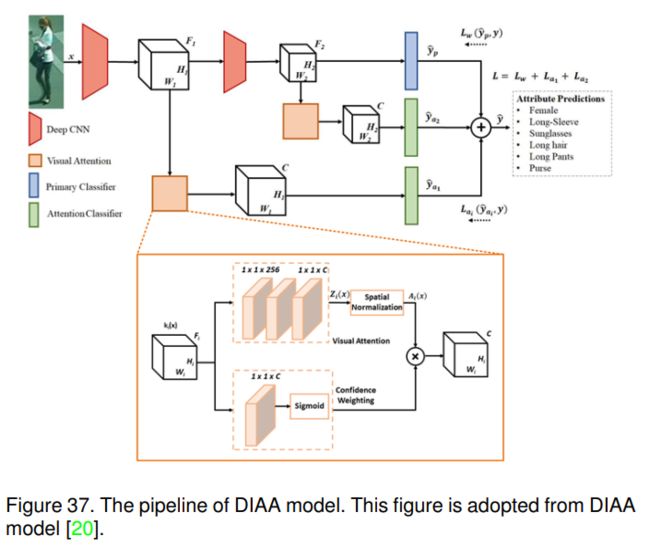
此外,他们还建议以弱监督的方式学习注意力图(只有属性标签,没有特定的边界框注释),通过引导网络将资源集中在那些包含与输入图像相关信息的空间部分,以提高分类性能。如图37右图所示,注意力子网络将特征图Wi×Hi× Fi作为输入,输出维度为Wi×Hi×C的注意力掩码。然后将输出输入注意力分类器以估计行人属性。由于用于注意力模块训练的监督信息有限,作者借助于跟踪的预测方差[100]。随着时间的推移,具有高标准差的注意力掩码预测将被赋予更高的权重,以指导网络学习那些不确定的样本。他们收集sth样本预测的历史H,并计算小批量中每个样本的时间标准差。因此,对每个样本s进行属性级监督的注意力图损失可以得到:
L a i ( y ^ a i , y ) = ( 1 + std s ( H ) ) L b ( y ^ a i , y ) \mathcal{L}_{a_{i}}\left(\hat{y}_{a_{i}}, y\right)=\left(1+\operatorname{std}_{s}(H)\right) \mathcal{L}_{b}\left(\hat{y}_{a_{i}}, y\right) Lai(y^ai,y)=(1+stds(H))Lb(y^ai,y)
其中 L b ( y ^ a i , y ) \mathcal{L}_{b}\left(\hat{y}_{a_{i}}, y\right) Lb(y^ai,y)为二元交叉熵损失, std s ( H ) \operatorname{std}_{s}(H) stds(H)为标准差。
因此,用于端到端训练该网络的总损失是来自主网络和两个注意力模块的损失之和。
6.3.4 CAM (PRL-2017) [21]
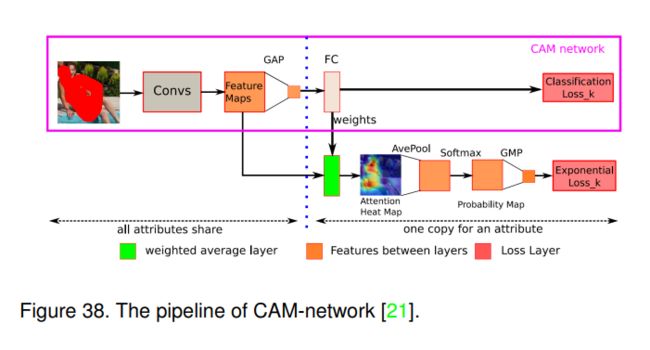
该文提出使用并细化注意力图来提升行人属性识别的性能。如图38所示,他们的模型包含两个主要模块:多标签分类子网络和注意力力图细化模块。所采用的CAM net[101]也遵循特定类别的框架,即不同的属性分类器对于全连接(FC)层具有不同的参数。他们使用FC层中的参数作为权重,线性组合最后一个卷积层中的特征图,以获得每个目标类别的注意力图。然而,由于分辨率低、过拟合训练等原因,这种简单的注意力机制实现无法始终专注于正确的区域。
为了解决上述问题,他们探索通过调优CAM网络来优化注意力图。他们根据注意力图的集中度来衡量注意力图的适当性,并试图使注意力图突出一个较小但集中的区域。首先,引入加权平均层来获取注意力图;然后,他们使用平均池化对其分辨率进行下采样,以捕获所有潜在相关区域的重要性。之后,他们还采用Softmax层将注意力图转换为概率图。最后,通过全局平均池化层得到最大概率。
在最大概率的基础上,作者提出了一种新的损失函数(称为指数损失函数)来衡量注意热图的适当性,可以表示为:
L = 1 N e α ( P i j M + β μ ) L=\frac{1}{N} e^{\alpha\left(P_{i j}^{M}+\beta \mu\right)} L=N1eα(PijM+βμ)
其中 P i j M P_{i j}^{M} PijM是图像i的最大概率,属性 j . α j . \alpha j.α和 β \beta β是超参数, μ = 1 / H 2 \mu=1 / H^{2} μ=1/H2是概率图的平均值。H × H是注意力(和概率)图的大小。在网络训练方面,首先仅通过最小化分类损失对CAM网络进行预训练;然后,采用联合损失函数对整个网络进行微调。
总结:视觉注意力机制已被引入行人属性识别中,但现有工作仍存在局限性。如何设计新的注意模型或直接借鉴其他领域的注意模型仍有待探索。
6.4 基于序列预测的模型
在本节中,我们将回顾基于序列预测的行人属性识别模型,包括CNNRNN[22]、JRL[23]、GRL[24]、JCM[25]和RCRA[102]。
6.4.1 cnn-rnn (cvpr-2016)
常规的多标签图像分类框架为每个类别学习独立的分类器,并对分类结果采用排序或阈值,未能显式地利用图像中的标签依赖性。首先采用循环神经网络来解决这个问题,并结合卷积神经网络学习一个联合的图像标签嵌入来表征语义标签的依赖关系以及图像标签的相关性。如图39所示,红点为标签,蓝点为图像嵌入。将图像和递归神经输出嵌入相加并用黑点表示。该机制通过顺序链接标记嵌入,对联合嵌入空间中的标记共现依赖关系进行建模。它可以根据图像嵌入I和递归神经元输出xt来计算标签的概率,可以表示为:
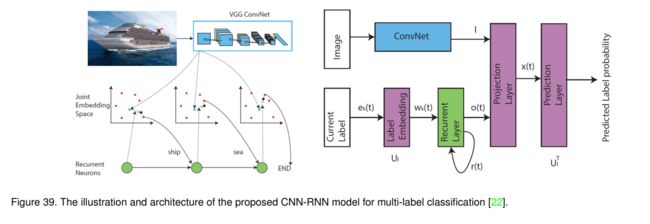
s ( t ) = U l T x t s(t)=U_{l}^{T} x_{t} s(t)=UlTxt
其中 x t = h ( U o x o ( t ) + U I x I ) x_{t}=h\left(U_{o}^{x} o(t)+U_{I}^{x} I\right) xt=h(Uoxo(t)+UIxI), U o x U_{o}^{x} Uox和 U I x U_{I}^{x} UIx分别是输出和图像表示的递归层的投影矩阵。 U l U_l Ul是标签嵌入矩阵。 O ( t ) O (t) O(t)是循环层在时间步t的输出。
对于CNN-RNN模型的推理,他们试图找到最大化先验概率的标签序列:
l 1 , … , l k = arg max l 1 , … , l k P ( l 1 , … , l k ∣ I ) = arg max l 1 , … , l k P ( l 1 ∣ I ) × P ( l 2 ∣ I , l 1 ) … P ( l k ∣ I , l 1 , … , l k − 1 ) (21) \begin{array}{r} l_{1}, \ldots, l_{k}=\arg \max _{l_{1}, \ldots, l_{k}} P\left(l_{1}, \ldots, l_{k} \mid I\right) \\ =\arg \max _{l_{1}, \ldots, l_{k}} P\left(l_{1} \mid I\right) \times P\left(l_{2} \mid I, l_{1}\right) \ldots P\left(l_{k} \mid I, l_{1}, \ldots, l_{k-1}\right) \end{array} \tag{21} l1,…,lk=argmaxl1,…,lkP(l1,…,lk∣I)=argmaxl1,…,lkP(l1∣I)×P(l2∣I,l1)…P(lk∣I,l1,…,lk−1)(21)
他们对排名靠前的预测路径采用波束搜索算法[103]作为估计结果。CNNRNN模型的训练可以通过交叉熵损失函数和时间反向传播(BPTT)算法来实现。
CNN-RNN模型与图像描述任务[104][105]中使用的深度模型非常相似。它们都将一张图像作为输入,并在编码器-解码器框架下输出一系列单词。主要的区别在于,caption模型输出一句话,而CNN-RNN模型生成属性(但这些属性也相互关联)。因此,可以借鉴图像描述社区的一些技术来帮助提高行人属性识别的性能。
6.4.2 JRL (ICCV-2017) [23]
本文首先分析了行人属性识别任务中存在的学习问题,如图像质量差、外观变化大、标注数据少等。他们提出探索属性与视觉环境之间的相互依赖和相关性,作为额外的信息源来辅助属性识别。因此,提出了JRL模型,顾名思义,用于属性上下文和相关性的联合循环学习。JRL的整个流程如图40所示。
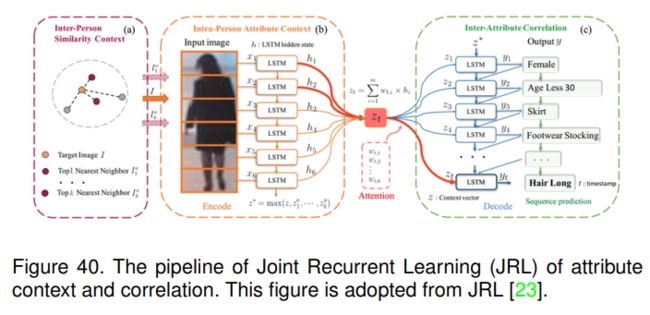
为了更好地挖掘这些额外信息,实现准确的人属性识别,本文采用序列-序列模型来处理上述问题。他们首先将给定的人物图像I分成m个水平条状区域,形成一个区域序列 S = ( s 1 , s 2 , … , s m ) S=\left(s_{1}, s_{2}, \ldots, s_{m}\right) S=(s1,s2,…,sm)从上到下的顺序。得到的区域序列S可以看作是自然语言处理中的输入句子,可以用LSTM网络按顺序进行编码。编码器LSTM的隐藏状态 h e n h^{en} hen可以根据常规的LSTM更新过程进行更新,如式6所示。最终的隐藏状态 h m e n h_{m}^{e n} hmen可以看作是整个人图像的汇总表示 z = h m e n z=h_{m}^{e n} z=hmen(称为上下文向量)。该特征提取过程可以在每个人物图像I中建模人内属性上下文。
挖掘更多的辅助信息来处理目标图像中的外观模糊和图像质量差的问题。利用视觉相似的样本训练图像,引入这些样本来建立人与人之间相似度上下文约束的模型。他们首先基于L2距离度量搜索带有CNN特征的与目标图像相似的top-k样本,并计算其自身的上下文向量 z i a z_i^a zia。然后,通过最大池化操作,将所有上下文向量表示集合为人与人之间的上下文 z ∗ z^* z∗。
在解码阶段,解码器LSTM将人内属性上下文(z)和人间相似性上下文( z ∗ z^∗ z∗)作为随时间步长输入和输出的变长属性。本文中的属性预测也可以看作是一种生成方案。为了更好地关注特定属性的人物形象局部区域,获得更准确的表示,他们还引入了注意机制来参与人物内部属性上下文。对于最终的属性估计顺序,他们采用集成思想来合并不同顺序的互补好处,从而在上下文中捕获属性之间更多的高阶相关性。
6.4.3 GRL (IJCAI-2018) [24]
GRL是在JRL的基础上发展起来的,它也采用RNN模型对人的属性进行顺序预测。与JRL不同的是,GRL是以群体为单位逐步识别人的属性,同时关注群体内和群体间的关系。如图41(1)所示,由于组内属性互斥且组间存在关系,作者将整个属性列表划分为多个组。例如,BoldHair和BlackHair不能出现在同一个人图像上,但它们都与一个人的头肩区域有关,可以在同一组中一起被识别。它是一种不需要预处理的端到端单模型算法,同时利用了分组行人属性之间更多潜在的组内和组间依赖关系。整体算法如图41(2)所示。
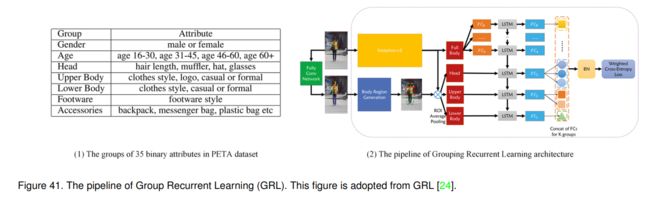
如图41(2)所示,给定人体图像,他们首先检测关键点,利用身体区域生成模块定位头部、上半身和下半身区域。利用Inception-v3网络提取图像整体特征,利用ROI平均池化操作获取局部特征。值得注意的是,同一组中的所有属性共享相同的全连接特性。考虑到属性组的全局和局部特征,采用LSTM对属性组的空间和语义相关性进行建模。然后将各LSTM单元的输出输入全连通层,得到预测向量。此向量与相关组中的属性数量具有相同的维数。他们还使用批处理规范化层来平衡该网络的正负输出。
6.4.4 JCM (arXiv-2018) [25]
现有的基于序列预测的人属性识别算法,如JRL[23]、GRL[24],由于RNN的对齐能力较弱,容易受到不同的人工划分和属性顺序的影响。本文提出了一种联合CTCAttention模型(JCM)来进行属性识别,该模型可以同时预测任意长度的多个属性值,避免了映射表中属性顺序的影响。
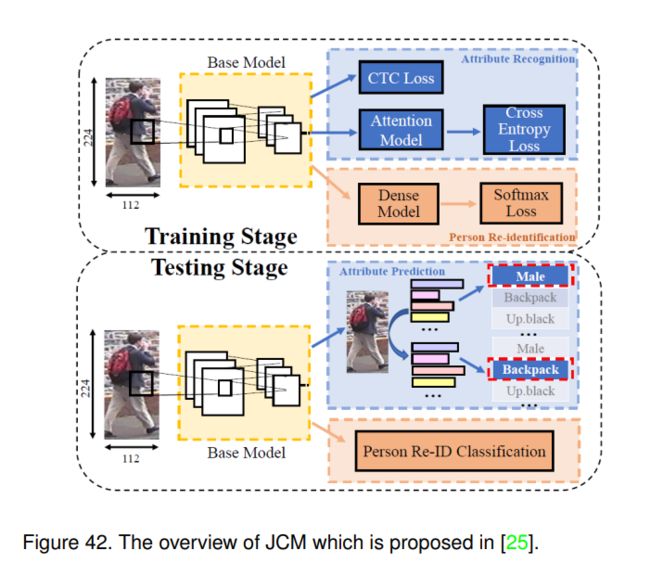
如图42所示,JCM实际上是一个多任务网络,它包含两个任务,即属性识别和人员再识别。他们使用ResNet-50作为基本模型来提取这两项任务的特征。对于属性识别,他们采用Transformer[106]作为长属性序列对齐的注意模型。使用连接主义时间分类(CTC)损失[107]和交叉熵损失函数对网络进行训练。对于person re-ID,他们直接使用两个全连通层(即稠密模型)获取特征向量,并使用softmax损失函数对该分支进行优化。
在测试阶段,JCM可以同时预测人物身份和一组属性。他们还使用波束搜索来解码属性序列。同时,他们从基本模型的CNN中提取特征,对行人进行分类,用于重新识别行人。
6.4.5 RCRA (AAAI-2019) [102]
本文提出了两种行人属性识别模型,即循环卷积(Recurrent Convolutional, RC)和循环注意(Recurrent Attention, RA),如图43所示。RC模型使用Convolutional-LSTM模型来探索不同属性组之间的相关性[108],RA模型利用组内空间局部性和组间注意相关性来提高最终性能。
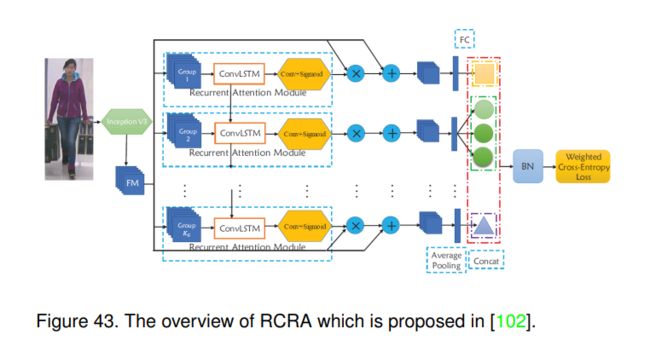
具体来说,他们首先将所有属性划分为多个属性组,类似于GRL[24]。对于每个行人图像,他们使用CNN提取其特征图,并逐组馈送到ConvLSTM层。然后,在ConvLSTM后添加卷积网络,得到每个时间步的新特征图。最后,利用该特征对当前属性组进行属性分类。
在上述RC模型的基础上,他们还引入了视觉注意模块来突出特征图上感兴趣的区域。已知每个时间步t的图像特征图F和关注热图 H t H_t Ht,则可以得到当前属性组的参与特征图 F t F_t Ft:
F t = sigmoid ( H t ) ⊗ F + F (22) F_{t}=\operatorname{sigmoid}\left(H_{t}\right) \otimes F+F \tag{22} Ft=sigmoid(Ht)⊗F+F(22)
其中⊗表示空间逐点乘法。参与的特征图用于最终分类。该网络的训练也是基于wpal网络[26]中提出的加权交叉熵损失函数。
总结:从这一小节我们可以看到,这些算法都采用了顺序估计过程。因为属性是相互关联的,它们也有不同的难度。因此,采用RNN模型逐个估计属性是一个有趣而直观的想法。在这些算法中,他们将不同的神经网络、属性组、多任务学习集成到这个框架中。与基于CNN的方法相比,这些算法更加优雅和有效。这些算法的缺点是由于属性估计是连续的,时间效率高。在未来的工作中,需要更有效的序列属性估计算法。
6.5 基于损失函数的模型
在本节中,我们将回顾一些改进损失函数的算法,包括WPAL [26], AWMT[27]。
6.5.1 WPAL-network (BMVC-2017)[26]
WPAL被提议以弱监督的方式同时识别和定位人员属性(即只有人员属性标签,没有特定的边界框注释)。如图44所示,他们采用GoogLeNet作为特征提取的基本网络。它们融合了来自不同层的特征(即来自Conv3−E的特征;Conv2−E和Conv1−E层),并馈入柔性空间金字塔池化层(FSPP)。与常规的全局max-pooling相比,FSPP的优势主要体现在两个方面:1)可以对帽子等属性增加空间约束;2).该结构位于网络的中间阶段,而不是顶部,使得检测器与目标类之间的相关性一开始不受约束,在训练过程中可以自由学习。每个FSPP的输出被馈送到全连接层,并输出一个维度与行人属性数量相同的向量。
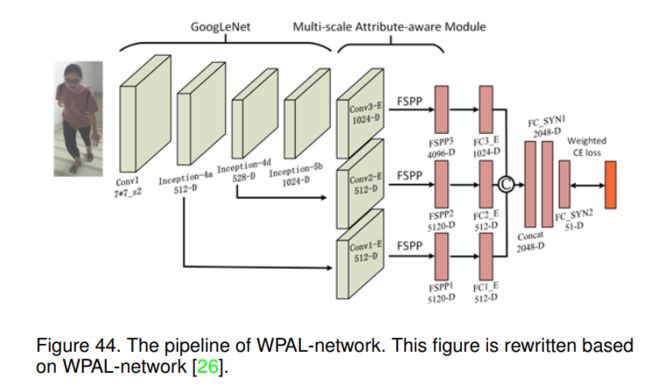
在训练过程中,网络可以同时学习拟合以下两个目标:一是学习属性与随机初始化的中层检测器之间的相关性,二是适应检测器的目标中层特征来拟合相关属性。利用学习到的相关性,对中层特征的检测结果进行定位。
此外,作者还引入了一种新的加权交叉熵损失函数,以处理大多数属性类别的正、负样本的极度不平衡分布。数学公式可以写成:
Loss w c e = ∑ i = 1 L 1 2 w i ∗ p i ∗ log ( p ^ i ) + 1 2 ( 1 − w i ) ( 1 − p i ) ∗ log ( 1 − p ^ i ) (23) \operatorname{Loss}_{w c e}=\sum_{i=1}^{L} \frac{1}{2 w_{i}} * p_{i} * \log \left(\hat{p}_{i}\right)+\frac{1}{2\left(1-w_{i}\right)}\left(1-p_{i}\right) * \log \left(1-\hat{p}_{i}\right) \tag{23} Losswce=i=1∑L2wi1∗pi∗log(p^i)+2(1−wi)1(1−pi)∗log(1−p^i)(23)
其中L表示属性的数量,p是基本真相属性向量, p ^ \hat{p} p^是估计的属性向量,w是一个权重向量,表示训练数据集中正面标签在所有属性类别中的比例。
6.5.2 AWMT (MM-2017) [27]
众所周知,各种属性的学习难度是不同的。然而,现有的大多数算法忽略了这种情况,并在多任务学习框架中共享相关信息。这将导致负迁移,换句话说,当两个任务不同时,不充分的暴力迁移可能会损害学习者的表现。AWMT提出了一种能够动态自适应协调学习不同人属性任务关系的共享机制。具体而言,他们提出了一种自适应加权多任务深度框架来联合学习多人属性,以及一种验证损失趋势算法来自动更新加权损失层的权重。他们的网络管道可以在图45中找到。
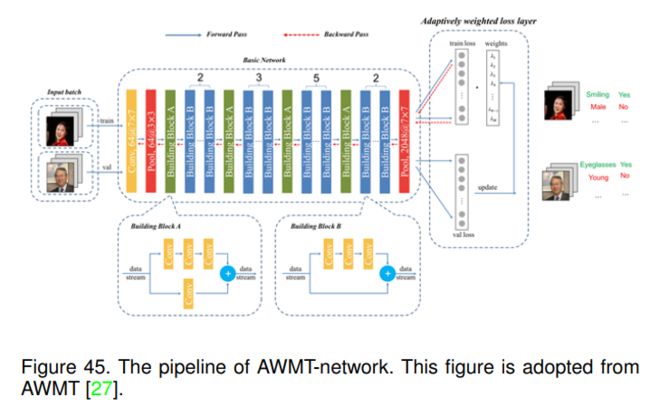
如图45所示,他们采用ResNet-50作为基本网络,同时以train和val图像作为输入。基本网络将输出其对train和val图像的预测属性向量。因此,可以同时得到列车损耗和val损耗。利用val损失来更新权重向量 λ j ( j = 1 , … , M ) \lambda_{j}(j=1, \ldots, M) λj(j=1,…,M),然后用它来加权不同属性学习。自适应加权损失函数可表示为:
Θ = arg min Θ ∑ j = 1 M ∑ i = 1 N < λ j , L ( ψ j ( I i ; Θ ) − L i j ) > (24) \Theta=\arg \min _{\Theta} \sum_{j=1}^{M} \sum_{i=1}^{N}<\lambda_{j}, \mathcal{L}\left(\psi_{j}\left(\mathbf{I}_{i} ; \Theta\right)-\mathbf{L}_{i j}\right)> \tag{24} Θ=argΘminj=1∑Mi=1∑N<λj,L(ψj(Ii;Θ)−Lij)>(24)
其中 Θ \Theta Θ为神经网络参数, λ j λ_j λj为衡量学习 j j j层属性任务重要性的标度值。 I i I_i Ii为mini-batch中的第i张图像, L i j L_{ij} Lij为图像 i i i的属性 j j j的ground truth标签。 ψ j ( I i ; Θ ) \psi_{j}\left(\mathbf{I}_{i} ; \Theta\right) ψj(Ii;Θ)为神经网络参数 Θ \Theta Θ下输入图像Ii的预测属性。 < ⋅ > <·> <⋅>为内积运算。
其中的关键问题是如何自适应调整公式24中的权值向量 λ j λ_j λj。他们提出了验证损失趋势算法来实现这一目标。他们的算法背后的直觉是,在同时学习多个任务时,应给予"重要"任务较高的权重(即 λ j λ_j λj),以增加相应任务的损失规模。但问题是我们如何知道哪个任务更“重要”,换句话说,我们如何衡量一个任务的重要性?
在这篇文章中,作者提出使用泛化能力作为一个客观的度量。具体来说,他们认为一个任务的生成能力较低的训练模型应该比其他任务的模型设置更高的权重。每k次迭代更新权重向量 λ j λ_j λj,并用于计算训练数据的损失和在反向传递中更新网络参数 Θ \Theta Θ。在多个属性数据集上的实验验证了该自适应权重机制的有效性。
总结:很少有工作关注于设计新的损失函数用于行人属性识别。WPAL-network[26]考虑了数据的不平衡分布,根据训练数据集中正标签占所有属性类别的比例提出了加权交叉熵损失函数。这种方法看起来有点棘手,但已经在许多PAR算法中广泛使用。AWMT[27]提出了一种自适应权重机制对每个属性进行学习,使网络更专注于处理"难"任务。这些工作充分证明了设计新的损失函数以更好地训练PAR网络的必要性。
6.6 基于算法的课程学习
在本节中,我们将介绍基于课程学习的算法,该算法考虑以“容易”到“困难”的方式学习人的属性,如:MTCT [109], CILICIA [110]。
6.6.1 MTCT (wacv-2017) [109]
针对缺乏人工标注训练数据的问题,提出一种多任务课程迁移网络。如图46所示,他们的算法主要包括多任务网络和课程迁移学习。
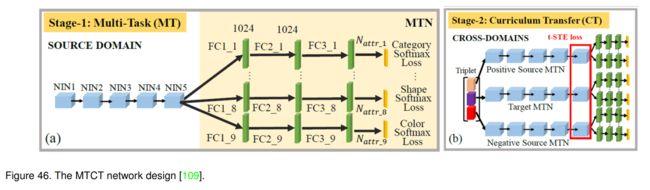
对于多任务网络,他们采用5个堆叠的网络-网络(network -network, NIN)卷积单元[111]和N个平行分支,每个分支代表3层全连接的子网络,分别用于建模N个属性中的一个。采用Softmax损失函数进行模型训练。
受认知研究的启发,人类和动物采用的更好的学习策略是先学习更容易的任务,然后逐渐增加任务的难度,而不是盲目地学习随机组织的任务。因此,采用课程迁移学习策略进行服装属性建模。具体来说,它由两个主要阶段组成。在第一阶段,他们使用干净(即更容易)的源图像及其属性标签来训练模型。在第二阶段,嵌入跨域图像对信息,同时将较难的目标图像加入到模型训练过程中,以捕获较难的跨域知识。他们采用t-STE (t-distribution stochastic triplet embedding)损失函数来训练网络,可以描述为:
L t − S T E = ∑ I t , I p s , I n s ∈ T log ( 1 + ∥ f t ( I t ) − f s ( I p s ) ∥ 2 α ) β ( 1 + ∥ f t ( I t ) − f s ( I p s ) ∥ 2 α ) β + ( 1 + ∥ f t ( I t ) − f s ( I n s ) ∥ 2 α ) β (25) \begin{array}{r} L_{t-S T E}=\sum_{I_{t}, I_{p s}, I_{n s} \in T} \\ \log \frac{\left(1+\frac{\left\|f_{t}\left(I_{t}\right)-f_{s}\left(I_{p s}\right)\right\|^{2}}{\alpha}\right)^{\beta}}{\left(1+\frac{\left\|f_{t}\left(I_{t}\right)-f_{s}\left(I_{p s}\right)\right\|^{2}}{\alpha}\right)^{\beta}+\left(1+\frac{\left\|f_{t}\left(I_{t}\right)-f_{s}\left(I_{n s}\right)\right\|^{2}}{\alpha}\right)^{\beta}} \end{array} \tag{25} Lt−STE=∑It,Ips,Ins∈Tlog(1+α∥ft(It)−fs(Ips)∥2)β+(1+α∥ft(It)−fs(Ins)∥2)β(1+α∥ft(It)−fs(Ips)∥2)β(25)
其中 β = − 0.5 ∗ ( 1 + α ) \beta=-0.5 *(1+\alpha) β=−0.5∗(1+α), α \alpha α是学生核的自由度。 f t ( ⋅ ) f_{t}(\cdot) ft(⋅)和 f s ( ⋅ ) f_{s}(\cdot) fs(⋅)分别为目标和源多任务网络的特征提取函数。
6.6.2 CILICIA (ICCV-2017) [110]
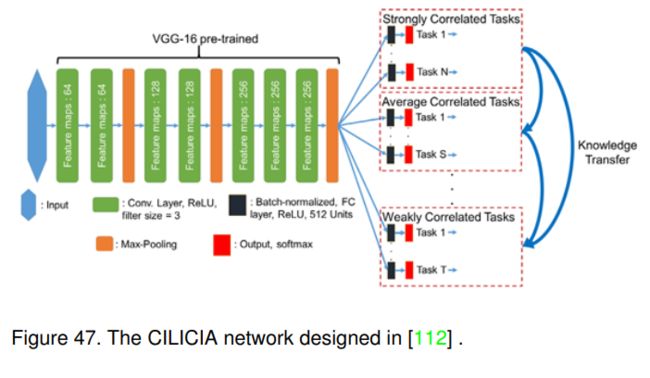
与MTCT[109]类似,CILICIA[110]也将课程学习的思想引入到人的属性识别任务中,实现属性由易到难的学习。CILICIA的流程可以在图47中找到。他们探索了不同属性学习任务之间的相关性,并将这种相关性分为强相关和弱相关任务。具体来说,在多任务学习框架下,他们使用各自的Pearson相关系数来衡量强相关的任务,可以表示为:
p i = ∑ j = 1 , j ≠ i T cov ( y t i , y t j ) σ ( y t i σ ( y t j ) ) , i = 1 , … , T (26) p_{i}=\sum_{j=1, j \neq i}^{T} \frac{\operatorname{cov}\left(y_{t_{i}}, y_{t_{j}}\right)}{\sigma\left(y_{t_{i}} \sigma\left(y_{t_{j}}\right)\right)}, i=1, \ldots, T \tag{26} pi=j=1,j=i∑Tσ(ytiσ(ytj))cov(yti,ytj),i=1,…,T(26)
其中 σ ( y t i ) \sigma(y_{t_i}) σ(yti)是任务 t i t_i ti的标签y的标准差。 p i p_i pi中任务相关度最高的50%与rest强相关,可以划分为强相关组。其余任务属于弱相关组,将在强相关组知识的指导下进行学习。
对于多任务网络,他们采用预测和目标之间的分类交叉熵函数[113],可以定义如下(对于单个属性t):
L t = 1 N ∑ i = 1 N ∑ j = 1 M ( 1 / M j ∑ n = 1 M 1 / M n ) ⋅ 1 [ y i = j ] ⋅ log ( p i , j ) (27) L_{t}=\frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{M}\left(\frac{1 / M_{j}}{\sum_{n=1}^{M} 1 / M_{n}}\right) \cdot \mathbb{1}\left[y_{i}=j\right] \cdot \log \left(p_{i, j}\right) \tag{27} Lt=N1i=1∑Nj=1∑M(∑n=1M1/Mn1/Mj)⋅1[yi=j]⋅log(pi,j)(27)
其中,如果样本 i i i的目标属于类别 j j j,则 1 [ y i = j ] \mathbb{1}\left[y_{i}=j\right] 1[yi=j]为1,否则为0。 M j M_j Mj是属于类别 j j j的样本数量,M和N分别是类别和样本的数量。
为了给不同的属性学习任务赋权,一种直观的思路是学习另一个分支网络进行权重学习。然而,作者并没有看到这种方法的显著改进。因此,他们采用监督迁移学习技术[114]来帮助弱相关组的属性学习:
L w = λ ⋅ L s + ( 1 − λ ) ⋅ L w f (28) L_{w}=\lambda \cdot L_{s}+(1-\lambda) \cdot L_{w}^{f} \tag{28} Lw=λ⋅Ls+(1−λ)⋅Lwf(28)
其中 L w f L_{w}^{f} Lwf是仅在弱相关任务上使用公式27进行正向传递时获得的总损失。
他们还提出了CILICIA-v2 [112],提出了一种使用层次凝聚聚类获得任务组的有效方法。它可以是任何数字,而不仅仅是两个组(即强/弱相关)。更具体地说,他们使用计算出的皮尔逊相关系数矩阵,使用Ward方差最小化算法执行层次凝聚聚类。ward方法偏向于生成相同大小的簇,并分析所有可能的连接簇对,识别出哪个连接产生的簇内平方和(WCSS)误差最小。因此,我们可以通过WCSS阈值操作得到属性组。对于每一组,他们通过仅在簇内对获得的各自皮尔逊相关系数进行排序来计算簇的学习序列。一旦所有簇的依赖关系形成,就可以按降序开始课程学习过程。
总结:受认知科学最新进展的启发,研究人员也考虑对PAR采用这种"容易"到"难"的学习机制。他们将现有的课程学习算法引入到他们的学习过程中,对每个属性之间的关系进行建模。其他一些算法,如自步学习[115],也用于多标签分类问题[116]或其他计算机视觉任务[117]建模。也值得引入更多认知科学的先进成果来指导PAR的学习。
6.7 基于图模型的算法
在许多应用中,图形模型通常用于建模结构学习。同样,也有一些工作将这些模型融合到行人属性识别任务中,例如:DCSA [28], A-AOG [29], VSGR[30]。
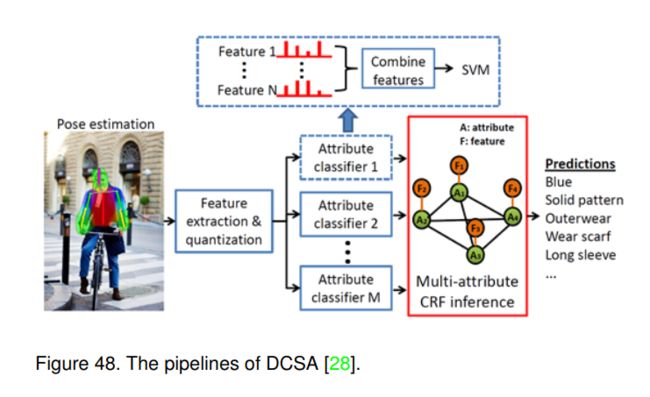
6.7.1 DCSA (ECCV-2012) [28]
该文提出使用条件随机场(conditional random field, CRF)对人类属性之间的相关性进行建模。如图48所示,他们首先使用现成的算法估计姿态信息[118],只定位上半身的局部部位(由于遮挡问题忽略下半身)。然后,从这些区域中提取四类基本特征,包括SIFT[2]、纹理描述子[119]、LAB空间颜色和肤色概率。通过SVM融合这些特征训练多个属性分类器。其核心思想是利用全连接CRF来探索属性间的相互依赖关系。将每个属性函数看作CRF的一个节点,连接两个属性节点的边反映了这两个属性的联合概率。采用置信传播[120]对属性标签成本进行优化。
6.7.2 A-AOG (TPAMI-2018) [29]
A-AOG模型(attribute and - or grammar)显式地表示了人体各部位的分解和连接,并考虑了姿态和属性之间的关联。该算法基于and- or图[121],and-节点表示分解或依赖;or节点表示分解或部件类型的可选选择。具体来说,它主要整合了三种语法:短语结构语法、依存语法和一个属性语法。
形式上,A-AOG定义为一个五维元组:
A − A O G = ⟨ S , V , E , X , P ⟩ (29) A-A O G=\langle S, V, E, X, \mathcal{P}\rangle \tag{29} A−AOG=⟨S,V,E,X,P⟩(29)
其中V为顶点集合,主要包含与节点集合、或节点集合和终端节点集合: V = V and ∪ V o r ∪ V T V=V_{\text {and }} \cup V_{o r} \cup V_{T} V=Vand ∪Vor∪VT;E是边集,它由两个子集 E = E p s g ∪ E d g E=E_{p s g} \cup E_{d g} E=Epsg∪Edg:具有短语结构语法的边集 E p s g E_{p s g} Epsg和依存语法 E d g E_{d g} Edg。 X = { x 1 , x 2 , … , x N } X=\left\{x_{1}, x_{2}, \ldots, x_{N}\right\} X={x1,x2,…,xN}是V中与节点相关联的属性集。 P \mathcal{P} P是图形表示的概率模型。
根据上述定义,解析图可以表述为:
p g = ( V ( p g ) , E ( p g ) , X ( p g ) ) (30) p g=(V(p g), E(p g), X(p g)) \tag{30} pg=(V(pg),E(pg),X(pg))(30)
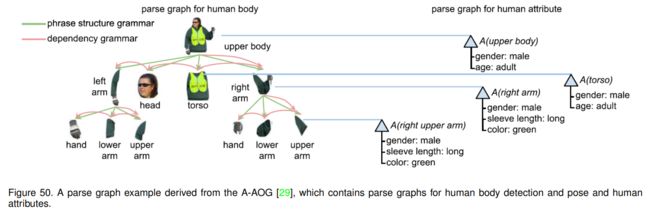
图50给出了从A-AOG得到的解析图的一个例子。给定一个图像I,目标是从他们的语法模型中找到最可能的解析图 p g pg pg。他们采用贝叶斯框架,将联合后验计算为似然概率和先验概率的乘积,在解析图上构建概率模型如下:
P ( p g ∣ I ; λ ) ∝ P ( I ∣ p g ; λ ) P ( p g ; λ ) = 1 Z exp { − E ( I ∣ p g ; λ ) − E ( p g ; λ ) } (31) \begin{aligned} & P(p g \mid I ; \lambda) \propto P(I \mid p g ; \lambda) P(p g ; \lambda) \\ = & \frac{1}{Z} \exp \{-\mathcal{E}(I \mid p g ; \lambda)-\mathcal{E}(p g ; \lambda)\} \end{aligned} \tag{31} =P(pg∣I;λ)∝P(I∣pg;λ)P(pg;λ)Z1exp{−E(I∣pg;λ)−E(pg;λ)}(31)
其中 λ \lambda λ是模型参数。能量函数E可以分解为一组势函数。式31中的两项可分解为部分关系和属性关系,因此式31可改写为:
P ( p g ∣ I ; λ ) = 1 Z exp { − E a p p V ( I ∣ p g ; λ ) − E a p p X ( I ∣ p g ; λ ) − E rel V ( p g ; λ ) − E rel X ( p g ; λ ) } (32) \begin{array}{r} P(p g \mid I ; \lambda)=\frac{1}{Z} \exp \left\{-\mathcal{E}_{a p p}^{V}(I \mid p g ; \lambda)-\mathcal{E}_{a p p}^{X}(I \mid p g ; \lambda)\right. \\ \left.-\mathcal{E}_{\text {rel }}^{V}(p g ; \lambda)-\mathcal{E}_{\text {rel }}^{X}(p g ; \lambda)\right\} \end{array} \tag{32} P(pg∣I;λ)=Z1exp{−EappV(I∣pg;λ)−EappX(I∣pg;λ)−Erel V(pg;λ)−Erel X(pg;λ)}(32)
其中 E a p p V ( I ∣ p g ; λ ) \mathcal{E}_{a p p}^{V}(I \mid p g ; \lambda) EappV(I∣pg;λ), E a p p X ( I ∣ p g ; λ ) \mathcal{E}_{a p p}^{X}(I \mid p g ; \lambda) EappX(I∣pg;λ), E r e l V ( p g ; λ ) \mathcal{E}_{r e l}^{V}(p g ; \lambda) ErelV(pg;λ) and E rel X ( p g ; λ ) \mathcal{E}_{\text {rel }}^{X}(p g ; \lambda) Erel X(pg;λ) 分别是部件的外观术语和属性的关系术语。
那么,能量项可以表示为以下评分函数:
S ( p g ∣ I ) = − E a p p V ( I ∣ p g ) − E app X ( I ∣ p g ) − E rel V ( p g ) − E rel X ( p g ) = S a p p V ( I , p g ) + S a p p X ( I , p g ) + S rel V ( p g ) + S rel X ( p g ) (33) \begin{aligned} S(p g \mid I) & =-\mathcal{E}_{a p p}^{V}(I \mid p g)-\mathcal{E}_{\text {app }}^{X}(I \mid p g)-\mathcal{E}_{\text {rel }}^{V}(p g)-\mathcal{E}_{\text {rel }}^{X}(p g) \\ & =S_{a p p}^{V}(I, p g)+S_{a p p}^{X}(I, p g)+S_{\text {rel }}^{V}(p g)+S_{\text {rel }}^{X}(p g) \end{aligned} \tag{33} S(pg∣I)=−EappV(I∣pg)−Eapp X(I∣pg)−Erel V(pg)−Erel X(pg)=SappV(I,pg)+SappX(I,pg)+Srel V(pg)+Srel X(pg)(33)
因此,可以通过最大化评分函数33找到最可能的解析图pg∗:
p g ∗ = arg max p g P ( I ∣ p g ) P ( p g ) = arg max p g [ S a p p V ( p g , I ) + S a p p X ( p g , I ) + S r e l V ( p g ) + S r e l X ( p g ) ] ≈ arg max p g [ S a p p ( p g , I ) + S rel ( p g ) ] (34) \begin{array}{r} p g^{*}=\arg \max _{p g} P(I \mid p g) P(p g) \\ =\arg \max _{p g}\left[S_{a p p}^{V}(p g, I)+S_{a p p}^{X}(p g, I)+S_{r e l}^{V}(p g)+S_{r e l}^{X}(p g)\right] \\ \approx \arg \max _{p g}\left[S_{a p p}(p g, I)+S_{\text {rel }}(p g)\right] \end{array}\tag{34} pg∗=argmaxpgP(I∣pg)P(pg)=argmaxpg[SappV(pg,I)+SappX(pg,I)+SrelV(pg)+SrelX(pg)]≈argmaxpg[Sapp(pg,I)+Srel (pg)](34)
他们使用深度CNN来生成每个部分的建议,并采用基于束搜索的贪婪算法来优化上述目标函数。具体的学习和推理过程请参考原文[122][29]。
6.7.3 VSGR (AAAI-2019) [30]
该文提出了一种基于视觉语义图推理(VSGR)的行人属性估计方法。他们认为行人属性识别的准确率受以下因素的影响:1)只有局部属性与某些属性相关;2)具有挑战性的因素,如姿态变化、视角和遮挡;3)属性与不同局部区域之间的复杂关系。因此,他们提出了一种基于图的推理框架来联合建模区域-区域、属性-属性和区域属性的空间和语义关系。其算法的整体流程如图51所示。
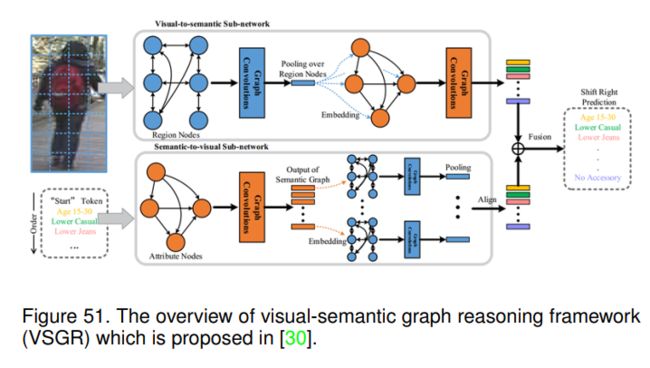
如图51所示,该算法主要包含两个子网络,即视觉到语义子网络和语义到视觉子网络。对于第一个模块,首先将人体图像划分为固定数量的局部部分 X = ( x 1 , x 2 , … , x M ) T \mathbf{X}=\left(x_{1}, x_{2}, \ldots, x_{M}\right)^{T} X=(x1,x2,…,xM)T。它们构造了一个图,其中节点是局部部分,边是不同部分的相似性。与常规关系建模不同,该模型同时利用部件间的相似关系和拓扑结构来连接部件与相邻区域。相似邻接矩阵可以表示为:
A s a ( i , j ) = exp ( F s ( x i , x j ) ) ∑ j = 1 M exp ( F s ( x i , x j ) ) (35) \mathbf{A}_{s_{a}}(i, j)=\frac{\exp \left(\mathbf{F}_{s}\left(x_{i}, x_{j}\right)\right)}{\sum_{j=1}^{M} \exp \left(\mathbf{F}_{s}\left(x_{i}, x_{j}\right)\right)} \tag{35} Asa(i,j)=∑j=1Mexp(Fs(xi,xj))exp(Fs(xi,xj))(35)
其中 F s ( x i , x j ) \mathbf{F}_{s}\left(x_{i},x_{j}\right) Fs(xi,xj)表示两个部分区域之间的两两相似度,也可以用神经网络进行建模。
局部部件之间的拓扑关系可以通过:
A s l ( i , j ) = exp ( − d i j / Δ ) ∑ j = 1 M exp ( − d i j / Δ ) (36) \mathbf{A}_{s_{l}}(i, j)=\frac{\exp \left(-d_{i j} / \Delta\right)}{\sum_{j=1}^{M} \exp \left(-d_{i j} / \Delta\right)} \tag{36} Asl(i,j)=∑j=1Mexp(−dij/Δ)exp(−dij/Δ)(36)
其中 d i j d_{i j} dij是两部分之间的像素距离, Δ \Delta Δ是缩放因子。
将两个子图结合起来,通过下面的公式计算空间图的输出:
G s = A s a X W s a + A s l X W s l (37) \mathbf{G}_{s}=\mathbf{A}_{s_{a}} \mathbf{X} \mathbf{W}_{s_{a}}+\mathbf{A}_{s_{l}} \mathbf{X} \mathbf{W}_{s_{l}} \tag{37} Gs=AsaXWsa+AslXWsl(37)
其中 W s a \mathbf{W}_{s_{a}} Wsa和 W s l \mathbf{W}_{s_{l}} Wsl是两个子图的权重矩阵。
因此,可以通过卷积后的平均池化操作获得空间上下文表示gs。在对区域间关系进行编码后,采用相似的操作对基于空间上下文的语义属性间关系进行建模。新图的节点是属性,将其转化为嵌入矩阵 R = ( r 0 , r 1 , … , r K ) \mathbf{R}=\left(r_{0}, r_{1}, \ldots, r_{K}\right) R=(r0,r1,…,rK),其中 r 0 r_{0} r0表示“开始”标记,每列 r i r_{i} ri是一个嵌入向量。位置编码[78]也被认为利用了属性顺序信息 P = ( p 0 , p 1 , … , p K ) \mathbf{P}=\left(p_{0}, p_{1}, \ldots, p_{K}\right) P=(p0,p1,…,pK)。将嵌入矩阵和位置编码相结合,得到有序预测路径 E = ( e 0 , e 1 , … , e K ) \mathbf{E}=\left(e_{0}, e_{1}, \ldots, e_{K}\right) E=(e0,e1,…,eK),其中 e k = r k + p k e_{k}=r_{k}+p_{k} ek=rk+pk。
最后,空间上下文和语义上下文可以通过:
C = E + ( U s g s ) (38) \mathbf{C}=\mathbf{E}+\left(\mathbf{U}_{s} g_{s}\right) \tag{38} C=E+(Usgs)(38)
其中 U U U是可学习的投影矩阵。对于边,只将第i个节点与下标≤i的节点连接起来,以保证当前属性的预测仅与已知输出有关。连通边的权值可以通过以下方式计算:
F e ^ ( c i , c j ) = ϕ e ^ ( c i ) T ϕ e ^ ′ ( c j ) \mathbf{F}_{\hat{e}\left(\mathbf{c}_{i}, \mathbf{c}_{j}\right)}=\phi_{\hat{e}}\left(\mathbf{c}_{i}\right)^{T} \phi_{\hat{e}^{\prime}}\left(\mathbf{c}_{j}\right) Fe^(ci,cj)=ϕe^(ci)Tϕe^′(cj)
其中, ϕ e ^ ( ∗ ) \phi_{\hat{e}}(*) ϕe^(∗)和 ϕ e ^ ′ ( ∗ ) \phi_{\hat{e}^{\prime}}(*) ϕe^′(∗)是线性变换函数。对每行的连通边权值进行归一化,得到邻接矩阵 A e ^ \mathbf{A}_{\hat{e}} Ae^。语义图上的卷积运算可以计算为:
G e ^ = A e ^ C T W e ^ (39) \mathbf{G}_{\hat{e}}=\mathbf{A}_{\hat{e}} \mathbf{C}^{T} \mathbf{W}_{\hat{e}} \tag{39} Ge^=Ae^CTWe^(39)
对语义图进行卷积后得到输出表示 G e ^ \mathbf{G}_{\hat{e}} Ge^,然后用于序列属性预测。
语义到视觉的子网络也可以以类似的方式处理,并输出顺序属性预测。这两个子网络的输出被融合作为最终的预测,并可以以端到端的方式进行训练。
总结:由于多个属性之间存在关系,许多算法被提出来挖掘PAR的这些信息。因此,图模型是首先考虑的,并被引入到学习管道中,如马尔可夫随机场[123],条件随机场[124],and - or -Graph[121]或图神经网络[125]。本小节所回顾的工作是将图形模型与PAR结合得到的结果。为了获得更好的识别效果,PAR也可以使用其他图形模型。虽然这些算法有很多优点,但是它们似乎比其他算法更复杂。在实际应用中,效率问题也是需要考虑的。
6.8 其他算法
本小节用于演示不适合上述类别的算法,包括:PatchIt[31]、FaFS[32]、GAM[33]。
6.8.1 PatchIt (BMVC-2016) [31]
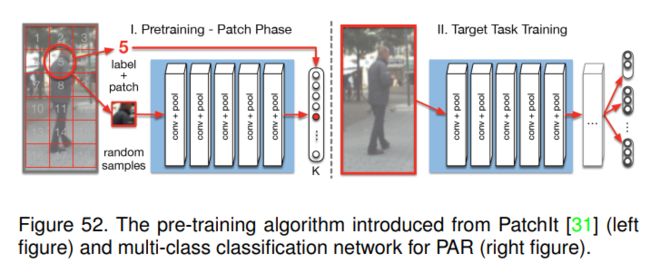
常规卷积网络通常在辅助任务上采用预训练模型进行权值初始化。然而,它限制了设计的网络与现有架构相似,如AlexNet, VGG或ResNet。与这些算法不同,本文提出了一种自监督预训练方法PatchTask,以获取PAR的权重初始化。其关键见解是利用与目标任务相同域的数据进行预训练,它仅依赖于自动生成而不是人工标注的标签。此外,我们更容易找到大量的无标签数据。
对于PatchTask,作者将其定义为k类分类问题。如图52所示,他们首先将图像划分为多个不重叠的局部patch,然后让网络预测给定patch的来源。他们使用PatchTask来获得VGG16卷积层的初始化,并应用于PAR。
6.8.2 FaFS (CVPR-2017)
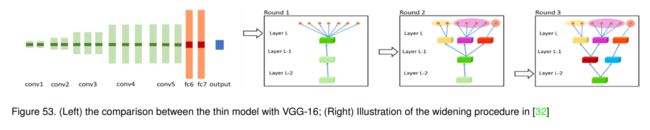
多任务学习的目标是在这些任务之间共享相关信息,以帮助提高最终的泛化性能。大多数人工设计的深度神经网络都进行共享和特定任务的特征学习。与现有工作不同,提出FaFS[32]自动设计紧凑的多任务深度学习架构。该算法从一个薄的多层网络开始,并在训练过程中以贪婪的方式动态扩展它。这将通过重复上面的扩展过程创建一个树状的深度架构,类似的任务位于同一个分支,直到位于顶层。图53(右子图)说明了这一过程。图53(左图)给出了薄网络与VGG-16模型的对比。利用同步正交匹配追踪(simultaneous orthogonal matching pursuit, SOMP)最小化目标函数初始化瘦网络的权值参数[126]:
A ∗ , ω ∗ ( l ) = arg min A ∈ R d × d ′ , ∣ w ∣ = d ′ ∥ W p , l − A W w : p , l ∥ F , (41) A^{*}, \omega^{*}(l)=\arg \min _{A \in \mathbb{R}^{d \times d^{\prime}},|w|=d^{\prime}}\left\|W^{p, l}-A W_{w:}^{p, l}\right\|_{F}, \tag{41} A∗,ω∗(l)=argA∈Rd×d′,∣w∣=d′min Wp,l−AWw:p,l F,(41)
其中 W p , l W^{p, l} Wp,l是第l层d行预训练模型的参数。$ W_{w:}^{p, l} 表示一个截断的权重矩阵,仅保留集合 表示一个截断的权重矩阵,仅保留集合 表示一个截断的权重矩阵,仅保留集合\omega$索引的行。这个初始化过程是逐层完成的,适用于卷积层和全连接层。
然后,采用逐层扩大模型来扩大薄网络,如图53(右子图)所示。该操作从输出层开始,以自顶向下的方式递归地到更低的层。值得注意的是,每个分支都与一组任务相关联。它们还根据任务之间的亲和度将相似和不相似的任务划分为不同的组。
6.8.3 GAM (AVSS-2017) [33]
提出使用深度生成模型来解决行人属性分辨率低和遮挡问题。具体而言,其整体算法包含三个子网络,即属性分类网络、重建网络和超分辨率网络。
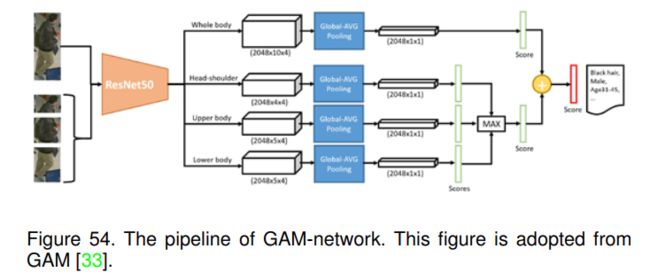
对于属性分类网络,也采用全局和局部联合的方式进行最终属性估计,如图54所示。他们采用ResNet50提取深度特征并使用全局平均池化来获得相应的评分。融合这些得分作为最终的属性预测得分。为了处理遮挡和低分辨率问题,他们引入深度生成对抗网络[87]来生成重建和超分辨率图像。并将预处理后的图像作为多标签分类网络的输入进行属性识别。
7 应用
视觉属性可以看作是一种中层特征表示,可以为与人体相关的高层任务提供重要信息,如行人再识别[128],[129],[130],[131],[132],行人检测[133],行人跟踪[134],行人检索[135],[136],人体行为识别[137],场景理解[138]。由于篇幅所限,本文仅对其余部分的一些作品进行综述。
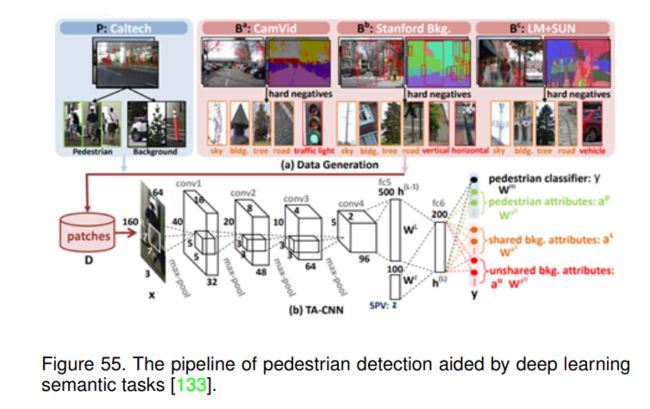
行人检测。与普通的行人检测算法将其视为单一的二分类任务不同,Tian等人提出将行人检测与语义任务联合优化,以解决正样本和难负样本的混淆问题。它们使用现有的场景分割数据集来迁移属性信息,以从多个任务和数据集来源学习高层特征。它们的总体流程如图55所示。
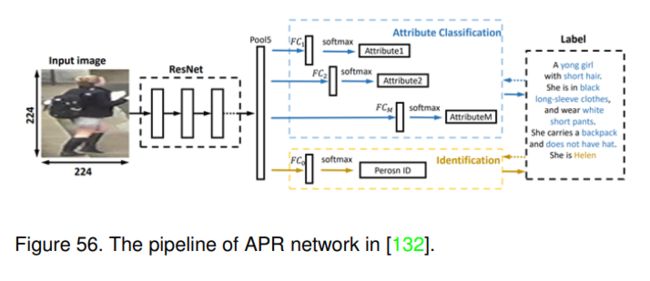
行人重识别。如[132]所述,行人重识别和属性识别在行人描述上有一个共同的目标。PAR侧重于挖掘局部信息,而行人再识别通常捕捉一个人的全局表示。如图56所示,Lin等人提出了多任务网络来同时估计行人属性和行人ID。他们的实验验证了更具判别力的表示学习的有效性。
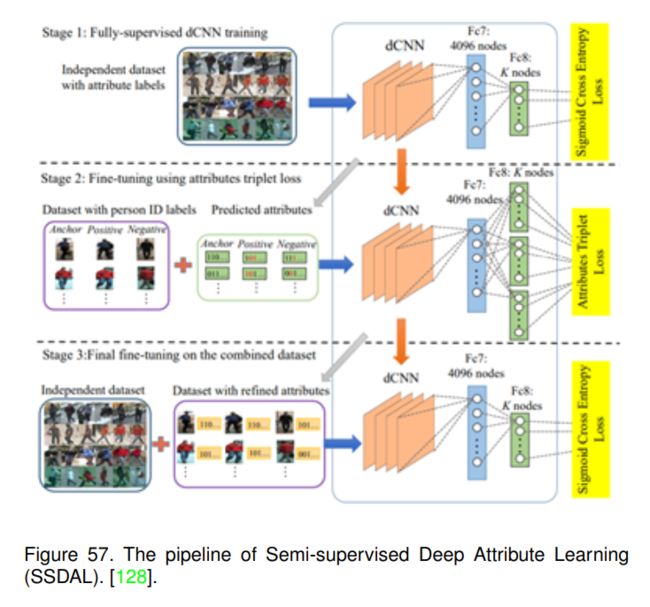
Su等人在[128]中也提出将中层人类属性融入行人再识别框架。它们以半监督的方式训练属性模型,主要包括三个阶段,如图57所示。他们首先在一个独立的属性数据集上预训练深度CNN,然后在另一个仅用人物id标注的数据集上进行微调。之后,他们使用更新后的深度CNN模型估计目标数据集的属性标签。利用简单余弦距离的深度属性可以在多个行人重识别数据集上取得较好的效果。Sameh Khamis等人[130]建议将语义方面集成到常规的基于外观的方法中。它们共同学习一个到外观-属性联合子空间的有判别力的投影,可以有效地利用属性和外观之间的相互作用进行匹配。Li等人也在[131]中对服装属性辅助行人re-ID进行了全面的研究。他们首先提取身体部位及其局部特征,以缓解姿态失调问题。然后,提出一种基于潜在SVM的行人重识别方法,对行人的低级部位特征、中级服装属性和高级重识别标签之间的关系进行建模。它们将服装属性作为实值变量而不是离散变量,以获得更好的行人重识别性能。
8 未来研究方向
在本节的其余部分,我们讨论了行人属性识别未来工作的几个有趣方向。我们还在表2中列出了一些已发布的PAR源代码。
8.1更精确高效的局部定位算法
由于人们可以只关注特定的区域,并根据局部和全局信息对属性进行推理,因此可以非常高效地识别出详细的属性信息。因此,设计能够像人类一样检测局部部件进行精确属性识别的算法是一种直观的思路。
根据6.2节不难发现,研究者确实对挖掘人体局部部位更感兴趣。它们使用人工标注或检测到的人体或姿态信息进行部件定位。基于零件的属性识别总体框架如图58所示。也有一些算法试图以弱监督的方式提出统一的框架来共同处理属性识别和定位问题。我们认为这也是一个很好的有用的行人属性识别的研究方向。
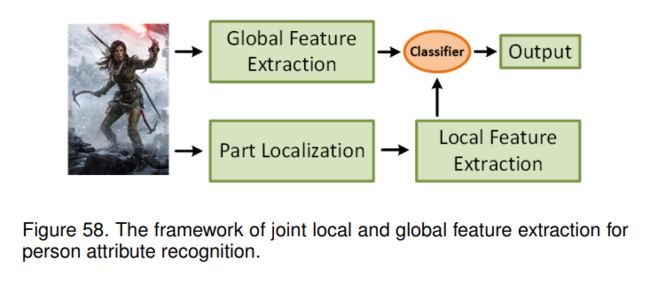
8.2用于数据增强的深度生成模型
近年来,深度生成模型取得了很大的进展,提出了许多算法,如:pixel-CNN[139], pixel-RNN [140], VAE [85], GAN[86]。最近的工作,如progressive GAN[141]和bigGAN[142],甚至让人们对这些算法生成的图像感到震惊。一个直观的研究方向是我们如何使用深度生成模型来处理低质量的人物图像或不平衡数据分布的问题?
已经有很多研究集中在文本、属性或姿态信息[143]、[144]、[145]、[146]、[147]指导下的图像生成。生成的图像可以用于许多其他任务中进行数据增强,例如,目标检测[148],行人再识别[149],视觉跟踪[150]等。GAM[33]还尝试生成用于行人属性识别的高分辨率图像。设计新的算法根据给定的属性生成行人图像以扩充训练数据也是值得研究的问题。
8.3进一步探索视觉注意机制
近年来,视觉关注引起了越来越多研究者的关注[151]。它仍然是当今最流行的技术之一,并在许多任务中与各种深度神经网络集成。正如[151]所指出的,人类感知的一个重要特性是,人们不倾向于一次性处理整个场景。相反,人类有选择地将注意力集中在视觉空间的某些部分,以便在需要的时候和地方获取信息,并随着时间的推移结合来自不同凝视的信息,以建立场景的内部表示[152],指导未来的眼球运动和决策。它还大大降低了任务复杂度,因为感兴趣的对象可以放在注视的中心,而注视区域之外的视觉环境的无关特征(“杂波”)自然被忽略。
8.4 新设计的损失函数
近年来,有许多损失函数被提出用于深度神经网络优化,如(加权)交叉熵损失、contrast损失、Center损失、Triplet损失、Focal损失等。研究人员还为PAR设计了新的损失函数,如WPAL[26]、AWMT[27]等,以进一步提高其识别性能。研究不同损失函数对PAR的影响是一个非常重要的方向。
8.5 探索更高级的网络架构
现有的PAR模型采用大规模数据集上现成的预训练网络(如ImageNet)作为其骨干网络架构。很少有人考虑PAR的特点,设计新颖的网络。近年来提出了一些新的网络,如:胶囊网络[71][72],外部记忆网络[81]。然而,仍然没有尝试将这种网络用于PAR。也有工作[153]表明,网络架构越深,我们可以获得更好的识别性能。如今,自动机器学习解决方案(AutoML)受到越来越多的关注[154][155][156],许多开发工具也发布用于开发,如:AutoWEKA [157], Autosklearn[158]。因此,利用上述方法设计特定的行人属性识别网络将是未来工作的一个很好的选择。
8.6 先验知识引导学习
不同于常规的分类任务,行人属性识别由于人类的偏好或自然的约束,往往具有自身的特点。挖掘人们在不同季节、不同温度、不同场合穿不同衣服等情况下的先验知识或常识是一个重要的研究方向。另一方面,一些研究人员试图使用历史知识(如:Wikipedia k)来帮助提高他们的整体性能,如图像描述[159],[160],目标检测[161]。因此,如何利用这些信息探索人物属性之间的关系或帮助机器学习模型进一步理解人物属性仍然是一个未研究的问题。
8.7 多模态行人属性识别
尽管现有的单模态算法已经在一些基准数据集上取得了较好的性能。然而,众所周知,RGB图像对光照、恶劣天气(如:雨、雪、雾)、夜间时间等非常敏感。实现全天候、全天候的行人属性准确识别似乎是不可能的。但智能监控的实际需求远远不止于此。我们如何弥合这一差距?
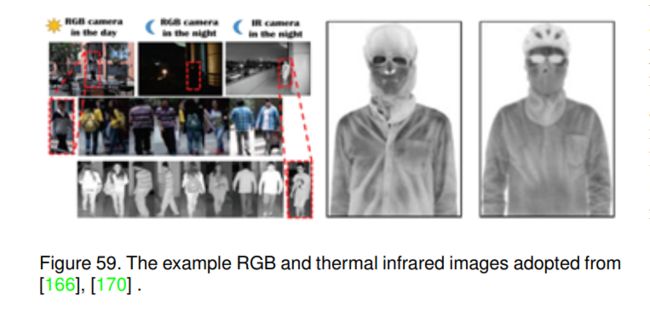
一种直观的想法是从其他模态(如热传感器或深度传感器)中挖掘有用的信息,与RGB传感器集成。已经有许多工作试图融合这些多模态数据并显著提高其最终性能,如rgb -热跟踪[162],[163],[164],运动目标检测[165],行人再识别[166],rgb -深度目标检测[167],[168],分割[169]。我们认为多模态融合的思想也有助于提高行人属性识别的鲁棒性。如图59所示,这些热图像可以突出人体和其他一些穿戴或携带物体的轮廓,如[170],[171]所示。
8.8 基于视频的行人属性识别
现有的行人属性识别多基于单幅图像,而在实际应用场景中,往往需要获取摄像机拍摄的视频序列。虽然在每个视频帧上运行现有算法是一种直观、简单的策略,但效率可能会成为实际应用的瓶颈。Chen等人通过重新标注最初为基于视频的行人再识别而构建的MAR数据集[173],提出了基于视频的PAR数据集[172]。一般来说,基于图像的属性识别只能利用给定图像的空间信息,由于信息有限,增加了PAR的难度。相比之下,给定基于视频的PAR,可以联合利用空间和时间信息。其好处如下:1)通过定义更动态的人属性,将属性识别扩展到更一般的情况,如“跑男”;2)利用运动信息可以推理出单幅图像中难以识别的属性;3)从视频中学习到的一般人物属性可以为其他基于视频的任务提供更有帮助的信息,如视频字幕、视频目标检测等。因此,如何高效、准确地识别实际视频序列中的人体属性是一个值得研究的问题。
8.9 属性与其他任务的联合学习
将人属性学习融入到与他人相关的任务流水线中也是一个有趣而重要的研究方向。目前已经有很多将行人属性纳入相应任务的算法被提出,如:基于属性的行人检测[174]、视觉跟踪[175]、行人再识别[25][176]、[177]、[178]、社会活动分析[179]等。在未来的工作中,如何更好地探索细粒度的人物属性用于其他任务,同时也利用其他任务更好地进行人物属性识别是一个重要的研究方向。
9 结论
文中从传统的行人属性识别方法到基于深度学习的行人属性识别方法,对近年来行人属性识别的研究进展进行了综述。据我们所知,这是第一篇关于行人属性识别的综述论文。首先介绍了PAR的背景信息(定义和挑战因素);然后列出了现有的PAR基准,包括流行的数据集和评估标准;然后,从多任务学习和多标记学习两个方面对用于PAR的算法进行了综述;然后,对PAR算法进行了简要回顾,首先回顾了一些在其他任务中广泛应用的流行的神经网络;然后,从不同角度分析了PAR的深度算法,包括:基于全局、基于局部、基于视觉注意、基于序列预测、基于新设计的损失函数、基于课程学习、基于图模型等算法;然后,对结合人员属性学习和其他与人员相关任务的研究工作进行了简要介绍;最后,对全文进行总结,并从9个方面指出了未来可能的研究方向。
