SQL学习笔记-分组聚合、子查询、关联操作与窗口函数
聚合函数(aggregation function)---也就是组函数
一、基础知识
MySQL最常用分组聚合函数
在一个行的集合(一组行)上进行操作,对每个组给一个结果。
常用的组函数:
| AVG([distinct] expr) |
求平均值 |
| COUNT({*|[distinct] } expr) |
统计行的数量 |
| MAX([distinct] expr) |
求最大值 |
| MIN([distinct] expr) |
求最小值 |
| SUM([distinct] expr) |
求累加和 |
①每个组函数接收一个参数
②默认情况下,组函数忽略列值为null的行,不参与计算
③有时,会使用关键字distinct剔除字段值重复的条数
注意:
1)当使用组函数的select语句中没有group by子句时,中间结果集中的所有行自动形成一组,然后计算组函数;
2)组函数不允许嵌套,例如:count(max(…));
3)组函数的参数可以是列或是函数表达式;
4)一个SELECT子句中可出现多个聚集函数。
1、count函数
①count(*):返回表中满足where条件的行的数量
mysql> select count(*) from salary_tab where salary='1000'; #salary为列名 +----------+ | count(*) | +----------+ | 2 | +----------+ mysql> select count(*) from salary_tab; #没有条件,默认统计表数据行数 +----------+ | count(*) | +----------+ | 5 | +----------+
②count(列):返回列值非空的行的数量
mysql> select count(salary) from salary_tab; #返回salary列非空 +---------------+ | count(salary) | +---------------+ | 4 | +---------------+
③count(distinct 列):返回列值非空的、并且列值不重复的行的数量
mysql> select count(distinct salary) from salary_tab; #distinct剔除salary列重复的 +------------------------+ | count(distinct salary) | +------------------------+ | 3 | +------------------------+
④count(expr):根据表达式统计数据
mysql> select * from TT;
+------+------------+
| UNIT | DATE |
+------+------------+
| a | 2018-04-03 |
| a | 2017-12-12 |
| b | 2018-01-01 |
| b | 2018-04-03 |
| c | 2016-06-06 |
| d | 2018-03-03 |
+------+------------+
6 rows in set (0.00 sec)
mysql> select UNIT as '单位',
-> COUNT(TO_DAYS(DATE)=TO_DAYS(NOW()) or null) as '今日统计',
-> COUNT(YEAR(DATE)=YEAR(NOW()) or null) as '今年统计'
-> from v_jjd
-> group by JJDW;
+------+----------+----------+
| 单位 | 今日统计 | 今年统计 |
+------+----------+----------+
| a | 1 | 1 |
| b | 1 | 2 |
| c | 0 | 0 |
| d | 0 | 1 |
+------+----------+----------+
4 rows in set (0.00 sec)
2、max和min函数---统计列中的最大最小值
mysql> select max(salary) from salary_tab;
+-------------+
| max(salary) |
+-------------+
| 3000.00 |
+-------------+
mysql> select min(salary) from salary_tab;
+-------------+
| min(salary) |
+-------------+
| 1000.00 |
+-------------+注意:如果统计的列中只有NULL值,那么MAX和MIN就返回NULL
3、sum和avg函数---求和与求平均
!!表中列值为null的行不参与计算
mysql> select sum(salary) from salary_tab;
+-------------+
| sum(salary) |
+-------------+
| 7000.00 |
+-------------+
mysql> select avg(salary) from salary_tab;
+-------------+
| avg(salary) |
+-------------+
| 1750.000000 |
+-------------+
mysql> select avg(ifnull(salary,0)) from salary_tab; #ifnull函数将salary列为空的对应值填充为0
+-----------------------+
| avg(ifnull(salary,0)) |
+-----------------------+
| 1400.000000 |
+-----------------------+注意:要想列值为NULL的行也参与组函数的计算,必须使用IFNULL函数对NULL值做转换。
二、分组SELECT
SELECT select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
分组SELECT的基本格式:
select [聚合函数] 字段名 from 表名
[where 查询条件]
[group by 字段名]
[having 过滤条件]
1、group by子句
根据给定列或者表达式的每一个不同的值将表中的行分成不同的组,使用组函数返回每一组的统计信息
规则:
①出现在SELECT子句中的单独的列,必须出现在GROUP BY子句中作为分组列
②分组列可以不出现在SELECT子句中
③分组列可出现在SELECT子句中的一个复合表达式中
④如果GROUP BY后面是一个复合表达式,那么在SELECT子句中,它必须整体作为一个表达式的一部分才能使用。
1)指定一个列进行分组
mysql> select salary,count(*) from salary_tab
-> where salary>=2000
-> group by salary;
+---------+----------+
| salary | count(*) |
+---------+----------+
| 2000.00 | 1 |
| 3000.00 | 1 |
+---------+----------+
2)指定多个分组列,‘大组中再分小组’
mysql> select userid,count(salary) from salary_tab
-> where salary>=2000
-> group by salary,userid;
+--------+---------------+
| userid | count(salary) |
+--------+---------------+
| 2 | 1 |
| 3 | 1 |
+--------+---------------+
3)根据表达式分组
mysql> select year(payment_date),count(*)
-> from PENALTIES
-> group by year(payment_date);
+--------------------+----------+
| year(payment_date) | count(*) |
+--------------------+----------+
| 1980 | 3 |
| 1981 | 1 |
| 1982 | 1 |
| 1983 | 1 |
| 1984 | 2 |
+--------------------+----------+
5 rows in set (0.00 sec)
4)带有排序的分组:如果分组列和排序列相同,则可以合并group by和order by子句
mysql> select teamno,count(*)
-> from MATCHES
-> group by teamno
-> order by teamno desc;
+--------+----------+
| teamno | count(*) |
+--------+----------+
| 2 | 5 |
| 1 | 8 |
+--------+----------+
2 rows in set (0.00 sec)
mysql> select teamno,count(*)
-> from MATCHES
-> group by teamno desc; #可以把desc(或者asc)包含到group by子句中简化
+--------+----------+
| teamno | count(*) |
+--------+----------+
| 2 | 5 |
| 1 | 8 |
+--------+----------+
2 rows in set (0.00 sec)
对于分组聚合注意:
通过select在返回集字段中,这些字段要么就要包含在group by语句后面,作为分组的依据,要么就要被包含在聚合函数中。我们可以将group by操作想象成如下的一个过程:首先系统根据select语句得到一个结果集,然后根据分组字段,将具有相同分组字段的记录归并成了一条记录。这个时候剩下的那些不存在与group by语句后面作为分组依据的字段就很有可能出现多个值,但是目前一种分组情况只有一条记录,一个数据格是无法放入多个数值的,所以这个时候就需要通过一定的处理将这些多值的列转化成单值,然后将其放在对应的数据格中,那么完成这个步骤的就是前面讲到的聚合函数,这也就是为什么这些函数叫聚合函数了。
2、GROUP_CONCAT()函数
函数的值等于属于一个组的指定列的所有值,以逗号隔开,并且以字符串表示。
例1:对于每个球队,得到其编号和所有球员的编号
mysql> select teamno,group_concat(playerno)
-> from MATCHES
-> group by teamno;
+--------+------------------------+
| teamno | group_concat(playerno) |
+--------+------------------------+
| 1 | 6,6,6,44,83,2,57,8 |
| 2 | 27,104,112,112,8 |
+--------+------------------------+
2 rows in set (0.01 sec)
如果没有group by子句,group_concat返回一列的所有值
例2:得到所有的罚款编号列表
mysql> select group_concat(paymentno)
-> from PENALTIES;
+-------------------------+
| group_concat(paymentno) |
+-------------------------+
| 1,2,3,4,5,6,7,8 |
+-------------------------+
1 row in set (0.00 sec)
3、with rollup子句:用来要求在一条group by子句中进行多个不同的分组
用的比较少点,但是有时可以根据具体的需求使用
如果有子句GROUP BY E1,E2,E3,E4 WITH ROLLUP
那么将分别执行以下分组:[E1,E2,E3,E4]、[E1,E2,E3]、[E1,E2]、[E1]、[]
注意:[ ]表示所有行都分在一组中
示例:按照球员的性别和居住城市,统计球员的总数;统计每个性别球员的总数;统计所有球员的总数
mysql> select sex,town,count(*)
-> from PLAYERS
-> group by sex,town with rollup;
+-----+-----------+----------+
| sex | town | count(*) |
+-----+-----------+----------+
| F | Eltham | 2 |
| F | Inglewood | 1 |
| F | Midhurst | 1 |
| F | Plymouth | 1 |
| F | NULL | 5 |
| M | Douglas | 1 |
| M | Inglewood | 1 |
| M | Stratford | 7 |
| M | NULL | 9 |
| NULL | NULL | 14 |
+-----+-----------+----------+
10 rows in set (0.00 sec)
4、HAVING子句:对分组结果进行过滤
注意:
不能使用WHERE子句对分组后的结果进行过滤
不能在WHERE子句中使用组函数,仅用于过滤行
mysql> select playerno
-> from PENALTIES
-> where count(*)>1
-> group by playerno;
ERROR 1111 (HY000): Invalid use of group function
因为WHERE子句比GROUP BY先执行,而组函数必须在分完组之后才执行,且分完组后必须使用having子句进行结果集的过滤。
基本语法:
SELECT select_expr [, select_expr ...]
FROM table_name
[WHERE where_condition]
[GROUP BY {col_name | expr} [ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
!!!having子语句与where子语句区别:
where子句在分组前对记录进行过滤;
having子句在分组后对记录进行过滤
mysql> select salary,count(*) from salary_tab
-> where salary>=2000
-> group by salary
-> having count(*)>=0;
+---------+----------+
| salary | count(*) |
+---------+----------+
| 2000.00 | 1 |
| 3000.00 | 1 |
+---------+----------+
1)HAVING可以单独使用而不和GROUP BY配合,如果只有HAVING子句而没有GROUP BY,表中所有的行分为一组
2)HAVING子句中可以使用组函数
3)HAVING子句中的列,要么出现在一个组函数中,要么出现在GROUP BY子句中(否则出错)
mysql> select town,count(*)
-> from PLAYERS
-> group by town
-> having birth_date>'1970-01-01';
ERROR 1054 (42S22): Unknown column 'birth_date' in 'having clause'
mysql> select town,count(*)
-> from PLAYERS
-> group by town
-> having town in ('Eltham','Midhurst');
+----------+----------+
| town | count(*) |
+----------+----------+
| Eltham | 2 |
| Midhurst | 1 |
+----------+----------+
2 rows in set (0.00 sec)
三、集合查询操作
union用于把两个或者多个select查询的结果集合并成一个
SELECT ... UNION [ALL | DISTINCT] SELECT ... [UNION [ALL | DISTINCT] SELECT ...]
默认情况下,UNION = UNION DISTINCT
①进行合并的两个查询,其SELECT列表必须在数量和对应列的数据类型上保持一致;
②默认会去掉两个查询结果集中的重复行;默认结果集不排序;
③最终结果集的列名来自于第一个查询的SELECT列表
UNION ALL不去掉结果集中重复的行
注:联合查询结果使用第一个select语句中的字段名
mysql> select * from t1;
+------+------+
| num | addr |
+------+------+
| 123 | abc |
| 321 | cba |
+------+------+
2 rows in set (0.00 sec)
mysql> select * from t2;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | A |
+------+------+
2 rows in set (0.00 sec)
mysql> select * from t1
-> union
-> select * from t2;
+------+------+
| num | addr |
+------+------+
| 123 | abc |
| 321 | cba |
| 1 | a |
| 2 | A |
+------+------+
4 rows in set (0.00 sec)
如果要对合并后的整个结果集进行排序,ORDER BY子句只能出现在最后面的查询中
注意:
在去重操作时,如果列值中包含NULL值,认为它们是相等的
四、分组聚合函数练习题
1、SQL86 返回每个订单号各有多少行数
select order_num,count(order_num) as order_lines #order_num列的count改名为order_lines
from OrderItems
group by order_num
order by order_lines #默认asc升序知识点:
1、count(*),count(列名)都可以,区别在于,count(列名)是统计非NULL的行数
2、order by最后执行,所以可以使用列别名
3、分组聚合一定不要忘记加上 group by ,不然只会有一行结果
2、SQL87 每个供应商成本最低的产品
常规解题思路:
select vend_id, min(prod_price) cheapest_item from Products group by vend_id order by cheapest_item
利用函数思路: 先用函数生成一个符合vend_id分组并根据prod_price的新表 然后嵌套查询这个新表+ where条件找到想要检索的结果
over(partition by )函数使用 1、partition by 字段名字A:子句进行分组,partition by是固定的分组语法; 2、order by 字段名字B:子句进行排序,order by 是固定的排序语法。 3、OVER()函数不能单独使用,必须跟在 排名函数( ROW_NUMBER、DENSE_RANK、RANK、NTILE) 或 5种聚合函数(SUM、MAX、MIN、AVG、COUNT)后边。
select vend_id,cheapest_item from (select vend_id,prod_price as cheapest_item,row_number() over(partition by vend_id order by prod_price) as rk from Products) as vind_min where rk=1 order by cheapest_item
3、SQL88 返回订单数量总和不小于100的所有订单的订单号
select order_num
from OrderItems
group by order_num
having sum(quantity)>=100
order by order_num三个方法 还是直接用聚合比较方便
```# 子查询
select order_num
from ( select order_num, sum(quantity) as sum_num
from OrderItems group by order_num having sum_num >= 100
) a
order by order_num;
# 直接使用聚合
select order_num
from OrderItems
group by order_num
having sum(quantity) >= 100
# order by order_num
# 窗口函数
select order_num
from (
select order_num,sum(quantity)
over (partition by order_num order by quantity ) as sum_1
from OrderItems
) as tb1
where sum_1 >= 100
order by order_num;4、计算总和
OrderItems表代表订单信息,包括字段:订单号order_num和item_price商品售出价格、quantity商品数量。
| order_num | item_price | quantity |
| a1 | 10 | 105 |
| a2 | 1 | 1100 |
| a2 | 1 | 200 |
| a4 | 2 | 1121 |
| a5 | 5 | 10 |
| a2 | 1 | 19 |
| a7 | 7 | 5 |
【问题】编写 SQL 语句,根据订单号聚合,返回订单总价不小于1000 的所有订单号,最后的结果按订单号进行升序排序。
提示:总价 = item_price 乘以 quantity
【示例结果】
| order_num | total_price |
| a1 | 1050 |
| a2 | 1319 |
| a4 | 2242 |
解题代码:
SELECT order_num, SUM(quantity*item_price) AS total_price
FROM OrderItems
GROUP BY order_num
HAVING SUM(quantity*item_price) >= 1000
ORDER BY order_num ASC;注:如果把item_price移到括号外面会报错,因为聚合函数的结果乘以一个item_price,它并不知道要乘以哪个item_price。
子查询
一、基础知识
子查询的定义:
子查询是将一个查询语句嵌套在另一个查询语句中;
在特定情况下,一个查询语句的条件需要另一个查询语句来获取,内层查询(inner query)语句的查询结果,可以为外层查询(outer query)语句提供查询条件。
特点(规范):
①子查询必须放在小括号中
②子查询一般放在比较操作符的右边,以增强代码可读性
③子查询(小括号里的内容)可出现在几乎所有的SELECT子句中(如:SELECT子句、FROM子句、WHERE子句、ORDER BY子句、HAVING子句……)
(相关、不相关)子查询分类:
①标量子查询(scalar subquery):返回1行1列一个值
②行子查询(row subquery):返回的结果集是 1 行 N 列
③列子查询(column subquery):返回的结果集是 N 行 1列
④表子查询(table subquery):返回的结果集是 N 行 N 列
可以使用的操作符:= > < >= <= <> ANY IN SOME ALL EXISTS
注意:一个子查询会返回一个标量(就一个值)、一个行、一个列或一个表,这些子查询称之为标量、行、列和表子查询
1、如果子查询返回一个标量值(就一个值),那么外部查询就可以使用:=、>、<、>=、<=和<>符号进行比较判断;
2、如果子查询返回的不是一个标量值,而外部查询使用了比较符和子查询的结果进行了比较,那么就会抛出异常。
一、不相关子查询
不相关,主查询和子查询是不相关的关系。也就是意味着在子查询中没有使用到外部查询的表中的任何列。
先执行子查询,然后执行外部查询
1、标量子查询(scalar subquery):返回1行1列一个值
因为是标量子查询,结果是一个值,所以可用来进行算数运算。
可以使用 = > < >= <= <> 操作符对子查询的结果进行比较:
mysql> select num,name
-> from employee
-> where d_id=(
-> select d_id
-> from department
-> where d_name='科技部');
+------+--------+
| num | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
+------+--------+
mysql> select num,name
-> from employee
-> where d_id=(
-> select d_id
-> from department
-> where d_name='财务部');
Empty set (0.00 sec)
注意:如果子查询返回空值,可能导致外部查询的where条件也为空,从而外部查询的结果集为空。
mysql> SELECT playerno,town,sex
-> FROM PLAYERS
-> WHERE (town,sex) = ((SELECT town FROM PLAYERS WHERE playerno=7),
-> (SELECT sex FROM PLAYERS WHERE playerno=44));
+----------+-----------+-----+
| playerno | town | sex |
+----------+-----------+-----+
| 2 | Stratford | M |
| 6 | Stratford | M |
| 7 | Stratford | M |
| 39 | Stratford | M |
| 57 | Stratford | M |
| 83 | Stratford | M |
| 100 | Stratford | M |
+----------+-----------+-----+
7 rows in set (0.01 sec)
注意: (列,列,…)叫做行表达式,比较时是比较列的组合。
2、行子查询(row subquery):返回的结果集是 1 行 N 列
使用行表达式进行比较,可以使用 = > < >= <= <> in操作符
mysql> select d_id from department;
+------+
| d_id |
+------+
| 1001 |
| 1002 |
| 1003 |
+------+
mysql> select * from employee
-> where d_id in
-> (select d_id from department);
+------+------+--------+------+------+--------------------+
| num | d_id | name | age | sex | homeaddr |
+------+------+--------+------+------+--------------------+
| 1 | 1001 | 张三 | 26 | 男 | 北京市海淀区 |
| 2 | 1001 | 李四 | 24 | 女 | 上海市黄浦区 |
| 3 | 1002 | 王五 | 25 | 男 | 江西省赣州市 |
+------+------+--------+------+------+--------------------+
解析:此处首先查询出department表中所有d_id字段的信息,并将结果作为条件,接着查询employee表中以d_id为条件的所有字段信息;NOT IN的效果与上面刚好相反。
3、列子查询(column subquery):返回的结果集是 N 行 1列
必须使用 IN、ANY 和 ALL 操作符对子查询返回的结果进行比较
注意:ANY 和 ALL 操作符不能单独使用,其前面必须加上单行比较操作符= > < >= <= <>
1)带ANY关键字的子查询:ANY关键字表示满足其中任一条件
mysql> select * from employee
-> where d_id !=any
-> (select d_id from department);
+------+------+--------+------+------+--------------------+
| num | d_id | name | age | sex | homeaddr |
+------+------+--------+------+------+--------------------+
| 1 | 1001 | 张三 | 26 | 男 | 北京市海淀区 |
| 2 | 1001 | 李四 | 24 | 女 | 上海市黄浦区 |
| 3 | 1002 | 王五 | 25 | 男 | 江西省赣州市 |
| 4 | 1004 | Aric | 15 | 男 | England |
+------+------+--------+------+------+--------------------+
2)带ALL关键字的子查询:ALL关键字表示满足其中所有条件
mysql> select * from employee
-> where d_id >=all
-> (select d_id from department);
+------+------+------+------+------+----------+
| num | d_id | name | age | sex | homeaddr |
+------+------+------+------+------+----------+
| 4 | 1004 | Aric | 15 | 男 | England |
+------+------+------+------+------+----------+
注意:如果子查询的结果集中有null值,使用>ALL 和not in操作符时,必须去掉子查询结果集中的null值,否则查询结果错误
mysql> select * from department
-> where d_id >all #>all背后执行and操作
-> (select d_id from employee);
Empty set (0.01 sec)
结果为空:子查询的结果集中包含null值(子查询结果集中没有主查询里的1004行,则为空)
4、表子查询(table subquery):返回的结果集是 N 行 N 列
必须使用 IN、ANY 和 ALL 操作符对子查询返回的结果进行比较
示例:在committee_members表中,得到任职日期和卸任日期与具有Secretary职位的一行相同的所有行
mysql> select *
-> from COMMITTEE_MEMBERS
-> where (begin_date,end_date) in
-> (
-> select begin_date,end_date
-> from COMMITTEE_MEMBERS
-> where position='Secretary'
-> );
+----------+------------+------------+-----------+
| PLAYERNO | BEGIN_DATE | END_DATE | POSITION |
+----------+------------+------------+-----------+
| 6 | 1990-01-01 | 1990-12-31 | Secretary |
| 8 | 1990-01-01 | 1990-12-31 | Treasurer |
| 8 | 1991-01-01 | 1991-12-31 | Secretary |
| 27 | 1990-01-01 | 1990-12-31 | Member |
| 27 | 1991-01-01 | 1991-12-31 | Treasurer |
| 57 | 1992-01-01 | 1992-12-31 | Secretary |
| 112 | 1992-01-01 | 1992-12-31 | Member |
+----------+------------+------------+-----------+
7 rows in set (0.05 sec)
二、相关子查询(correlated subquery)
在子查询中使用到了外部查询的表中的任何列。
先执行外部查询,然后执行子查询

相关子查询的执行步骤:
①先执行外部查询,得到的行叫做候选行
②使用某个候选行来执行子查询
③使用子查询的返回值来决定该候选行是出现在最终的结果集中还是被丢弃
④重复以上步骤2和3,将所有的候选行处理完毕,得到最终的结果
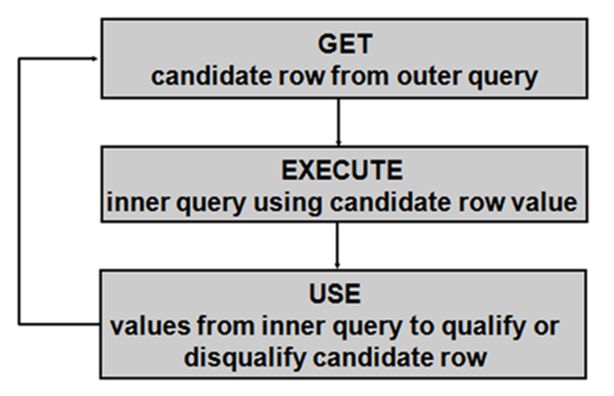
示例:得到项目是‘研发产品’的雇员的编号
mysql> select num
-> from employee
-> where '研发产品'=(
-> select function
-> from department
-> where d_id=employee.d_id);
+------+
| num |
+------+
| 1 |
| 2 |
+------+
解析:
1)主查询得到候选行,一行一行的拿去执行子查询;
2)主查询表employee的候选行的d_id和子查询的d_id匹配,返回值进行where过滤;
3)符合,加入最终结果集;
4)不符合,将候选行丢弃,接着进行处理下一个候选行。
带EXISTS关键字的相关子查询(EXISTS存在)
专门判断子查询的结果集是否不为空:
非空空返回true
空返回false
当返回的值为true时,外层查询语句将进行查询,否则不进行查询
mysql> select * from employee
-> where exists
-> (select d_name from department where d_id=1004);
Empty set (0.00 sec)
此处内层循环并没有查询到满足条件的结果,因此返回false,外层查询不执行
EXISTS关键字可以与其他的查询条件一起使用,条件表达式与EXISTS关键字之间用AND或者OR来连接
mysql> select * from employee
-> where age>24 and exists
-> (select d_name from department where d_id=1003);
+------+------+--------+------+------+--------------------+
| num | d_id | name | age | sex | homeaddr |
+------+------+--------+------+------+--------------------+
| 1 | 1001 | 张三 | 26 | 男 | 北京市海淀区 |
| 3 | 1002 | 王五 | 25 | 男 | 江西省赣州市 |
+------+------+--------+------+------+--------------------+
三、子查询练习题
1.SQL94 返回每个顾客不同订单的总金额
我们需要一个顾客 ID 列表,其中包含他们已订购的总金额。
OrderItems表代表订单信息,OrderItems表有订单号:order_num和商品售出价格:item_price、商品数量:quantity。
| order_num | item_price | quantity |
| a0001 | 10 | 105 |
| a0002 | 1 | 1100 |
| a0002 | 1 | 200 |
| a0013 | 2 | 1121 |
| a0003 | 5 | 10 |
| a0003 | 1 | 19 |
| a0003 | 7 | 5 |
Orders表订单号:order_num、顾客id:cust_id
| order_num | cust_id |
| a0001 | cust10 |
| a0002 | cust1 |
| a0003 | cust1 |
| a0013 | cust2 |
【问题】
编写 SQL语句,返回顾客 ID(Orders 表中的 cust_id),并使用子查询返回total_ordered 以便返回每个顾客的订单总数,将结果按金额从大到小排序。
提示:你之前已经使用 SUM()计算订单总数。
【示例结果】返回顾客id cust_id和total_order下单总额
| cust_id | total_ordered |
| cust2 | 2242 |
| cust1 | 1300 |
| cust10 | 1050 |
| cust2 | 104 |
【示例解析】cust2在Orders里面的订单a0013,a0013的售出价格是2售出数量是1121,总额是2242,最后返回cust2的支付总额是2242。
答案:
select
cust_id, #返回的列1
(select
SUM(item_price*quantity)
FROM OrderItems as a
WHERE a.order_num=b.order_num) #返回的两列对应
as total_ordered #返回的列2
from Orders as b
ORDER BY total_ordered DESC