推荐系统-协同过滤CF算法/RF学习笔记
一、协同过滤推荐算法
1.1 概念与原理
协同过滤,从字面上理解,包括协同和过滤两个操作。所谓协同就是利用群体的行为来做决策(推荐),生物上有协同进化的说法,通过协同的作用,让群体逐步进化到更佳的状态。对于推荐系统来说,通过用户的持续协同作用,最终给用户的推荐会越来越准。而过滤,就是从可行的决策(推荐)方案(标的物)中将用户喜欢的方案(标的物)找(过滤)出来。
具体来说,协同过滤的思路是通过群体的行为来找到某种相似性(用户之间的相似性或者标的物之间的相似性),通过该相似性来为用户做决策和推荐。
协同过滤分为基于用户的协同过滤和基于标的物(物品)的协同过滤两类算法。下面我们对协同过滤的算法原理来做详细的介绍。
基于协同过滤的两种推荐算法,核心思想是很朴素的”物以类聚、人以群分“的思想。所谓物以类聚,就是计算出每个标的物最相似的标的物列表,我们就可以为用户推荐用户喜欢的标的物相似的标的物,这就是基于物品(标的物)的协同过滤。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的标的物的标的物推荐给该用户(而该用户未曾操作过),这就是基于用户的协同过滤。具体思想可以参考下面的图1。

图1:”物以类聚,人以群分“的朴素协同过滤推荐
协同过滤的核心是怎么计算标的物之间的相似度以及用户之间的相似度。我们可以采用非常朴素的思想来计算相似度。我们将用户对标的物的评分(或者隐式反馈,如点击、收藏等)构建如下用户行为矩阵(见下面图2),矩阵的某个元素代表某个用户对某个标的物的评分(如果是隐式反馈,值为1),如果某个用户对某个标的物未产生行为,值为0。其中行向量代表某个用户对所有标的物的评分向量,列向量代表所有用户对某个标的物的评分向量。有了行向量和列向量,我们就可以计算用户与用户之间、标的物与标的物之间的相似度了。具体来说,行向量之间的相似度就是用户之间的相似度,列向量之间的相似度就是标的物之间的相似度。
为了避免误解,这里简单解释一下隐式反馈,只要不是用户直接评分的操作行为都算隐式反馈,包括浏览、点击、播放、收藏、评论、点赞、转发等等。有很多隐式反馈是可以间接获得评分的,后面会讲解。如果不间接获得评分,就用0、1表示是否操作过。
在真实业务场景中用户数和标的物数一般都是很大的(用户数可能是百万、千万、亿级,标的物可能是十万、百万、千万级),而每个用户只会操作过有限个标的物,所以用户行为矩阵是稀疏矩阵。正因为矩阵是稀疏的,会方便我们进行相似度计算及为用户做推荐。

图2:用户对标的物的操作行为矩阵
相似度的计算可以采用cosine余弦相似度算法来计算两个向量
(可以是上图的中行向量或者列向量)之间的相似度:
![]()
计算完了用户(行向量)或者标的物(列向量)之间的相似度,那么下面说说怎么为用户做个性化推荐。
1.基于用户的协同过滤
根据上面算法思想的介绍,我们可以将与该用户最相似的用户喜欢的标的物推荐给该用户。这就是基于用户的协同过滤的核心思想。
用户u对标的物s的喜好度sim(u,s)可以采用如下公式计算,其中U是与该用户最相似的用户集合(我们可以基于用户相似度找到与某用户最相似的K个用户),
![]()
是用户ui
对标的物s的喜好度(对于隐式反馈为1,而对于非隐式反馈,该值为用户对标的物的评分),
sim(u,ui)是用户ui与用户u的相似度。
![]()
有了用户对每个标的物的评分,基于评分降序排列,就可以取topN推荐给用户了。
2.基于标的物的协同过滤
类似地,通过将用户操作过的标的物最相似的标的物推荐给用户,这就是基于标的物的协同过滤的核心思想。
用户u对标的物s的喜好度sim(u,s)可以采用如下公式计算,其中S是所有用户操作过的标的物的列表,score(u,si)是用户u对标的物si的喜好度,
![]()
是标的物si与s的相似度。
![]()
有了用户对每个标的物的评分,基于评分降序排列,就可以取topN推荐给用户了。
从上面的介绍中我们可以看到协同过滤算法思路非常直观易懂,计算公式也相对简单,并且后面两节我们也会说明它易于分布式实现,同时该算法也不依赖于用户及标的物的其他metadata信息。协同过滤算法被Netflix、Amazon等大的互联网公司证明效果也非常好,也能够为用户推荐新颖性内容,所以一直以来都在工业界得到非常广泛的应用。
虽然协同过滤算法原理非常简单,但是在大规模用户及海量标的物的场景下,单机是难以解决计算问题的,我们必须借助分布式技术来实现,让整个算法可以应对大规模数据的挑战。
1.2 离线协同过滤算法的工程实现-以Spark分布式计算平台
为了简单起见,我们可以将推荐过程拆解为2个阶段,先计算相似度,再为用户推荐。下面分别介绍这两个步骤怎么工程实现。
- 计算topK相似度
本步骤我们计算出任意两个标的物之间的相似度,有了任意两个标的物之间的相似度,那么我们就可以为每个标的物计算出与它最相似的K个标的物了。
假设有两个标的物vi,vj它们对应的向量(即图2中矩阵的列向量,分别是第i列和第j列)如下,其中n是用户数。
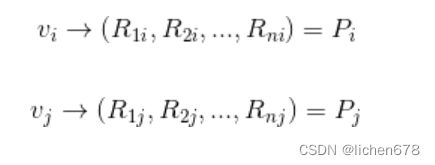
那么,vi,vj的相似度计算可以细化如下:
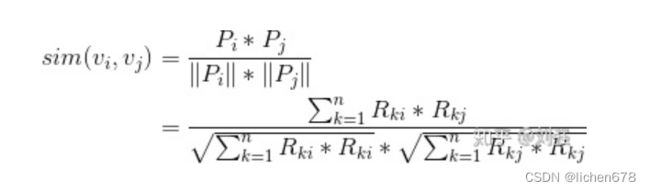
我们仔细看一下上述公式,公式的分子就是下图矩阵中对应的i列和j列中同一行中的两个元素(红色矩形中的一对元素)相乘,并且将所有行上第i列和第j列的元素相乘得到的乘积相加(这里其实只需要考虑同一行对应的i列和j列的元素都非零的情况,如果只要第i列和第j列中有一个为零,乘积也为零)。公式中分母是第i行与第i行按照上面类似的方法相乘再相加后开根号的值,再乘以第j行与第j行按照上面类似的方法相乘再相加后开根号的值。

图3:计算两个列向量的cosine余弦可以拆解为简单的加减乘及开根号运算
有了上面的简单分析,就容易分布式计算相似度了。下面我们就来讲解,在Spark上怎么简单地计算每个标的物的topK相似度。在Spark上计算相似度,最主要的目标是怎么将上面巨大的计算量(前面已经提到在互联网公司,往往用户数和标的物数都是非常巨大的)通过分布式技术实现,这样就可以利用多台服务器的计算能力,解决大计算问题。
首先将所有用户操作过的标的物”收集“起来,形成一个用户行为RDD,具体的数据格式如下:
![]()
其中uid是用户唯一识别编码,sid是标的物唯一识别编码,R是用户对标的物的评分(即矩阵中的元素)。
对于
![]()
中的某个用户来说,他操作过的标的物vi和vj一定在该用户所在的行对应的列i和列j的元素非零,根据上面计算相似度的公式,需要将该用户对应的
的评分乘起来。这个过程可以用下面的图4来说明。
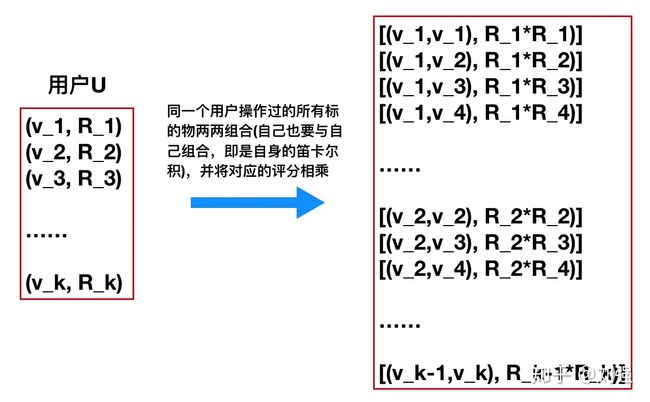
图4:对用户U来说,将他所有操作过的标的物做笛卡尔积
当所有用户都按照图4的方式转化为标的物对及得分(图4中右边的
![]()
)时,我们就可以对标的物对Group(聚合),将相同的对合并,对应的得分相加,最终得到的RDD为:
![]()
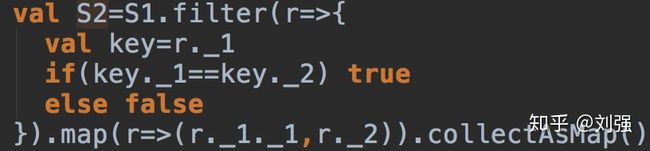
这样,公式1中分子就计算出来了(上式中的Score即是公式1中的分子)。现在我们需要计算分母,这非常简单,只要从上面的RDD中将标的物sid1等于标的物sid2的列过滤出来就可以了, 通过下图的操作,我们可以得到一个map
![]()
详见知乎专栏:协同过滤推荐算法 - 知乎
python实现案例:经典协同过滤算法的Python实现:ItemCF+UserCF - 墨天轮
二、基于RF随机森林的推荐算法
随机森林(Random Forest,简称RF)是一种基于决策树基模型的集成学习方法,其核心思想是通过特征采样来降低训练方差,提高集成泛化能力。sklearn.ensemble.RandomForestClassifier