DeepTime,是一个结合使用元学习的深度时间指数模型。通过使用元学习公式来预测未来,以应对时间序列中的常见问题(协变量偏移和条件分布偏移——非平稳)。该模型是时间序列预测的元学习公式协同作用的一个很好的例子。
DeepTime架构
DeepTime组件

DeepTime中有三种类型的层:
- 岭回归
- 多层感知机(MLP)
- 随机傅里叶特征
让我们看看这些层在做什么:
岭回归

多层感知机(MLP)
这些是在神经网络(nn)中使用的线性回归公式。然后使用了一个ReLU函数激活。这些层非常适合将时间指数映射到该时间指数的时间序列值。公式如下:

随机的傅里叶层
随机傅里叶允许mlp学习高频模式。尽管随机傅里叶层需要为每个任务和数据集找到不同的超参数(只是为了不过度拟合或不足拟合),但作者通过将各种傅里叶基函数与各种尺度参数相结合来限制这种计算。
DeepTIME架构

在每个任务中,选择一个时间序列,然后将其分为主干窗口(绿色)和预测窗口(蓝色)两部分。然后,然后他们通过两个彼此共享信息并与元参数关联的元模型。 在上图描述的架构上训练模型后,计算损失函数并尝试将其最小化。
其他时间序列预测模型的区别
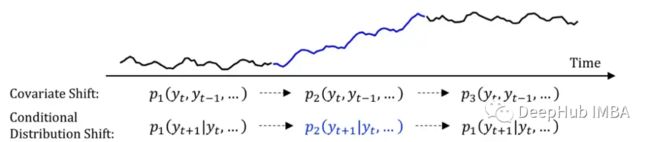
DeepTIME是一个时间指数模型,就像Prophet,高斯过程等,而最近比较突出的模型如N-HiTS, Autoformer, DeepAR, Informer等都是历史价值模型。
当我们说时间序列的时间指数模型时,确切的意思是预测绝对随时间变化(它考虑了当前的时间指数特征)。另一方面,历史价值模型使用以前的事件来预测未来。这个公式能让你更清楚。:)

它包含了元学习公式,这意味着这个模型可以学会如何学习。由于它是一个时间指数模型,可以在元学习中表现出更好的样本效率。
它采用直接多步估计(DMS)的方法(DMS模型一次直接预测几个数据点)。另外通过多步迭代(IMS),它只预测下一个值,然后使用它来预测下一个数据点,这与ARIMA、DeepAR等相同。
元学习给时间序列预测带来了什么?
- 更好的任务泛化
- 符合附近时间步长遵循局部平稳分布的假设。
- 还包含了相似的时间点将具有相似的特征的假设。
![]()
模型如何预测
在每一次训练时,将数据分为两个窗口(通过使用第一个窗口预测第二个窗口)。这里为了简单起见使用PyTorch Lightning简化训练过程。
importnumpyasnp
importgin
importpytorch_lightningaspl
frommodelsimportget_model
importrandom
importtorch
importtorch.nn.functionalasF
fromtorchimportoptim
importmath
fromutilsimportCheckpoint, default_device, to_tensor
@gin.configurable
classDeepTimeTrainer(pl.LightningModule):
def__init__(self,
lr,
lambda_lr,
weight_decay,
warmup_epochs,
random_seed,
T_max,
eta_min,
dim_size,
datetime_feats,
):
gin.parse_config_file('/home/reza/Projects/PL_DeepTime/DeepTime/config/config.gin')
super(DeepTimeTrainer, self).__init__()
self.lr=lr
self.lambda_lr=lambda_lr
self.weight_decay=weight_decay
self.warmup_epochs=warmup_epochs
self.random_seed=random_seed
self.lr=lr
self.lambda_lr=lambda_lr
self.weight_decay=weight_decay
self.T_max=T_max
self.warmup_epochs=warmup_epochs
self.eta_min=eta_min
self.model=get_model(
model_type='deeptime',
dim_size=dim_size,
datetime_feats=datetime_feats
)
defon_fit_start(self):
torch.manual_seed(self.random_seed)
np.random.seed(self.random_seed)
random.seed(self.random_seed)
deftraining_step(self, batch, batch_idx):
x, y, x_time, y_time=map(to_tensor, batch)
forecast=self.model(x, x_time, y_time)
ifisinstance(forecast, tuple):
# for models which require reconstruction + forecast loss
loss=F.mse_loss(forecast[0], x) + \
F.mse_loss(forecast[1], y)
else:
loss=F.mse_loss(forecast, y)
self.log('train_loss', loss, prog_bar=True, on_epoch=True)
return {'loss': loss, 'train_loss': loss, }
deftraining_epoch_end(self, outputs):
avg_train_loss=torch.stack([x["train_loss"] forxinoutputs]).mean()
self.log('avg_train_loss', avg_train_loss, on_epoch=True, sync_dist=True)
defvalidation_step(self, batch, batch_idx):
x, y, x_time, y_time=map(to_tensor, batch)
forecast=self.model(x, x_time, y_time)
ifisinstance(forecast, tuple):
# for models which require reconstruction + forecast loss
loss=F.mse_loss(forecast[0], x) + \
F.mse_loss(forecast[1], y)
else:
loss=F.mse_loss(forecast, y)
self.log('val_loss', loss, prog_bar=True, on_epoch=True)
return {'val_loss': loss}
defvalidation_epoch_end(self, outputs):
returnoutputs
deftest_step(self, batch, batch_idx):
x, y, x_time, y_time=map(to_tensor, batch)
forecast=self.model(x, x_time, y_time)
ifisinstance(forecast, tuple):
# for models which require reconstruction + forecast loss
loss=F.mse_loss(forecast[0], x) + \
F.mse_loss(forecast[1], y)
else:
loss=F.mse_loss(forecast, y)
self.log('test_loss', loss, prog_bar=True, on_epoch=True)
return {'test_loss': loss}
deftest_epoch_end(self, outputs):
returnoutputs
@gin.configurable
defconfigure_optimizers(self):
group1= [] # lambda
group2= [] # no decay
group3= [] # decay
no_decay_list= ('bias', 'norm',)
forparam_name, paraminself.model.named_parameters():
if'_lambda'inparam_name:
group1.append(param)
elifany([modinparam_nameformodinno_decay_list]):
group2.append(param)
else:
group3.append(param)
optimizer=optim.Adam([
{'params': group1, 'weight_decay': 0, 'lr': self.lambda_lr, 'scheduler': 'cosine_annealing'},
{'params': group2, 'weight_decay': 0, 'scheduler': 'cosine_annealing_with_linear_warmup'},
{'params': group3, 'scheduler': 'cosine_annealing_with_linear_warmup'}
], lr=self.lr, weight_decay=self.weight_decay)
scheduler_fns= []
forparam_groupinoptimizer.param_groups:
scheduler=param_group['scheduler']
ifscheduler=='none':
fn=lambdaT_cur: 1
elifscheduler=='cosine_annealing':
lr=eta_max=param_group['lr']
fn=lambdaT_cur: (self.eta_min+0.5* (eta_max-self.eta_min) * (
1.0+math.cos(
(T_cur-self.warmup_epochs) / (self.T_max-self.warmup_epochs) *math.pi))) /lr
elifscheduler=='cosine_annealing_with_linear_warmup':
lr=eta_max=param_group['lr']
fn=lambdaT_cur: T_cur/self.warmup_epochsifT_cur0:
forecasting_mask[:, 0, -self.n_time_out:] =0
Y, Y_hat, z=self.model(Y=Y, mask=forecasting_mask, idxs=None, z_0=z_0)
ifself.n_time_out>0:
Y=Y[:, :, -self.n_time_out:]
Y_hat=Y_hat[:, :, -self.n_time_out:]
sample_mask=sample_mask[:, :, -self.n_time_out:]
returnY, Y_hat, sample_mask, z 作者在合成数据集和真实世界数据集上进行了广泛的实验,表明DeepTime具有极具竞争力的性能,在基于MSE的多元预测基准的24个实验中,有20个获得了最先进的结果。

有兴趣的可以看看源代码:https://avoid.overfit.cn/post/5736b84982b847f991def19a5af4c9a0
作者:Reza Yazdanfar