ubuntu16.04完美测试yolo v3—darknet模型
本文只记录测试过程中的报错问题和测试的预测结果
yolo v3——darknet模型C源码:
https://github.com/arnoldfychen/darknet
权重:下载原版作者的权重文件
wget https://pjreddie.com/media/files/yolov3.weights
单独用GPU编译darknet源码时出现如下错误:
Makefile:92: recipe for target ‘obj/convolutional_kernels.o’ failed
解决方法: 修改Makefile
NVCC = /usr/local/cuda-11.1/bin/nvcc
重新编译,错误解决
make
解决pjreddie版darknet不能使用cudnn8编译的问题
之前在RTX3090 GPU server上使用pjreddie版的darknet面临一个左右为难的问题,RTX3090 GPU只能使用CUDA11.x才能跑得正常,但是没有与CUDA11.x对应的cudnn7.x,而pjreddie版的darknet的代码比较老旧了,依赖于cudnn7.x,所以在一个CUDA11.1+cudnn8.x的环境下编译pjreddie版的darknet的话,修改Mafile,设置:
GPU=1
CUDNN=1
OPENCV=1
后,一执行make就报错:
./src/convolutional_layer.c:153:13: error: 'CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT' undeclared (first use in this function);
did you mean 'CUDNN_CONVOLUTION_FWD_ALGO_DIRECT'?
cudnn8.x里是没有CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT这个宏定义的,而CUDA11.x又不能配套使用cudnn7.x,但是RTX30序列的GPU又必须使用CUDA11.x才能正常跑,感觉进了死胡同。后来找了比较久搜到NVIDIA给出了一个针对cudnn8的解决方案代码,就是修改出错的文件src/convolutional_layer.c的代码,增加针对CUDNN_MAJOR>=8的处理:
#if CUDNN_MAJOR >= 8
int returnedAlgoCount;
cudnnConvolutionFwdAlgoPerf_t fw_results[2 * CUDNN_CONVOLUTION_FWD_ALGO_COUNT];
cudnnConvolutionBwdDataAlgoPerf_t bd_results[2 * CUDNN_CONVOLUTION_BWD_DATA_ALGO_COUNT];
cudnnConvolutionBwdFilterAlgoPerf_t bf_results[2 * CUDNN_CONVOLUTION_BWD_FILTER_ALGO_COUNT];
cudnnFindConvolutionForwardAlgorithm(cudnn_handle(),
l->srcTensorDesc,
l->weightDesc,
l->convDesc,
l->dstTensorDesc,
CUDNN_CONVOLUTION_FWD_ALGO_COUNT,
&returnedAlgoCount,
fw_results);
for(int algoIndex = 0; algoIndex < returnedAlgoCount; ++algoIndex){
#if PRINT_CUDNN_ALGO > 0
printf("^^^^ %s for Algo %d: %f time requiring %llu memory\n",
cudnnGetErrorString(fw_results[algoIndex].status),
fw_results[algoIndex].algo, fw_results[algoIndex].time,
(unsigned long long)fw_results[algoIndex].memory);
#endif
if( fw_results[algoIndex].memory < MEMORY_LIMIT ){
l->fw_algo = fw_results[algoIndex].algo;
break;
}
}
cudnnFindConvolutionBackwardDataAlgorithm(cudnn_handle(),
l->weightDesc,
l->ddstTensorDesc,
l->convDesc,
l->dsrcTensorDesc,
CUDNN_CONVOLUTION_BWD_DATA_ALGO_COUNT,
&returnedAlgoCount,
bd_results);
for(int algoIndex = 0; algoIndex < returnedAlgoCount; ++algoIndex){
#if PRINT_CUDNN_ALGO > 0
printf("^^^^ %s for Algo %d: %f time requiring %llu memory\n",
cudnnGetErrorString(bd_results[algoIndex].status),
bd_results[algoIndex].algo, bd_results[algoIndex].time,
(unsigned long long)bd_results[algoIndex].memory);
#endif
if( bd_results[algoIndex].memory < MEMORY_LIMIT ){
l->bd_algo = bd_results[algoIndex].algo;
break;
}
}
cudnnFindConvolutionBackwardFilterAlgorithm(cudnn_handle(),
l->srcTensorDesc,
l->ddstTensorDesc,
l->convDesc,
l->dweightDesc,
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_COUNT,
&returnedAlgoCount,
bf_results);
for(int algoIndex = 0; algoIndex < returnedAlgoCount; ++algoIndex){
#if PRINT_CUDNN_ALGO > 0
printf("^^^^ %s for Algo %d: %f time requiring %llu memory\n",
cudnnGetErrorString(bf_results[algoIndex].status),
bf_results[algoIndex].algo, bf_results[algoIndex].time,
(unsigned long long)bf_results[algoIndex].memory);
#endif
if( bf_results[algoIndex].memory < MEMORY_LIMIT ){
l->bf_algo = bf_results[algoIndex].algo;
break;
}
}
#else
然后再编译,这个问题就过了,然后继续报个小错误:
nvcc fatal : Unsupported gpu architecture ‘compute_30’
这个很好解决,把Makefile里的配置修改一下,去掉ARCH配置中的 -gencode arch=compute_30,code=sm_30 \ 这行,改成下面这样即可:
ARCH= -gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52] \
-gencode arch=compute_70,code=[sm_70,compute_70] \
-gencode arch=compute_75,code=[sm_75,compute_75]\
-gencode arch=compute_86,code=[sm_86,compute_86]
然后编译顺利完成。
./src/image_opencv.cpp:5:10: fatal error: opencv2/opencv.hpp: No such file or directory
解决办法:
sudo apt install libopencv-dev
安装好这个库,make一下就ok了。
darknet: ./src/cuda.c:36: check_error: Assertion `0’ failed.
Aborted
训练时
打开yolov3.cfg,把其中的batch 和subdvisions属性值调小,但最好都是2的指数,并且要保证batch是subdivisions的整数倍。
gedit darket/cfg/yolov3.cfg
测试时
一个很大的可能是,忘记把配置文件darket/cfg/yolov3.cfg的训练配置改到测试配置上。
解决办法是打开yolov3.cfg,注释掉Training配置,同时Testing配置取消注释。
Makefile:92: recipe for target ‘obj/convolutional_kernels.o’ failed
进入darknet目录,编辑Makefile,修改NVCC路径。
解决方法:
修改makefile
NVCC = /usr/local/cuda-11.1/bin/nvcc
并将makefile中带有cuda的路径都改为自己的cuda版本。
再次出现Makefile:177: recipe for target ‘obj/convolutional_kernels.o‘ failed
在Makefile文件的NVCC=nvcc处,将nvcc改为系统中nvcc的路径/usr/local/cuda-11.0/bin/nvcc还是不行,最后仔细看了看上面的nvcc,。。。。。。。原来是cuda版本高,不支持运算,所以解决方法是 删除
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
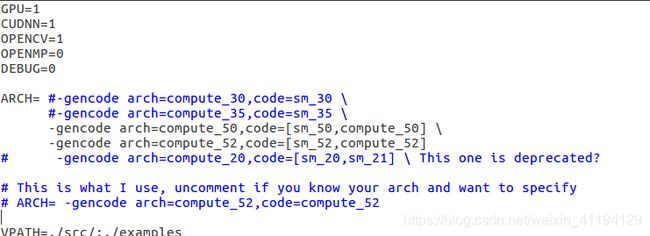 修改的时候要全部修改cuda相关路径:
修改的时候要全部修改cuda相关路径:

还有一种不常见的问题:被锁
 去除文件夹下所有被锁文件:
去除文件夹下所有被锁文件:
sudo chmod -R 777 darknet

测试图片:
注意问题:每一次修改makefile都要编译一下:
make clean
make -j32
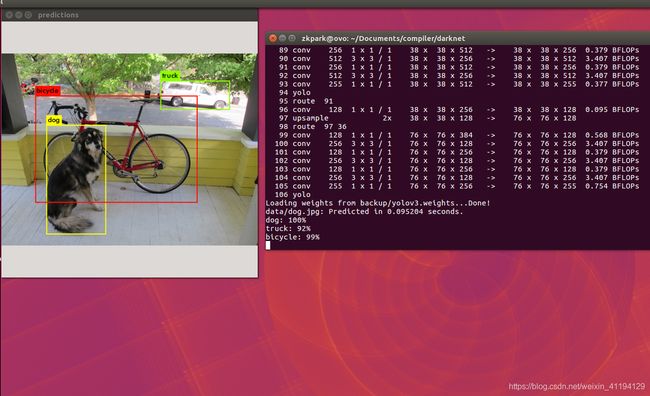
sudo ./darknet detect cfg/yolov3.cfg backup/yolov3.weights data/dog.jpg
备注:注选对权重文件的路径。
测试结果:
batch=1
subdivisions=1
 解释用make -j32的原因(加快编译速度)
解释用make -j32的原因(加快编译速度)
既然IO不是瓶颈,那CPU就应该是一个影响编译速度的重要因素了。
用make -j带一个参数,可以把项目在进行并行编译,比如在一台双核的机器上,完全可以用make -j4,让make最多允许4个编译命令同时执行,这样可以更有效的利用CPU资源。
还是用Kernel来测试:
用make: 40分16秒
用make -j4:23分16秒
用make -j8:22分59秒
由此看来,在多核CPU上,适当的进行并行编译还是可以明显提高编译速度的。但并行的任务不宜太多,一般是以CPU的核 心数目的两倍为宜。
测试视频【摄像头】
测试实时摄像头中的目标
在darknet目录下运行终端:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg backup/yolov3.weights
./darknet detector demo cfg/coco.data cfg/yolov3.cfg backup/yolov3.weights 自己的视频
附录命令简介
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
darknet :一个可执行的程序,类似win下的exe
detector:是第一个参数,执行detector.c
test:detector.c里面的一个函数test_detector(),用来测试图片
cfg/coco.data:"cfg/"是训练的配置文件所在路径,coco.data是.data配置文件名
cfg/yolov3.cfg:"cfg/"是训练的配置文件所在路径,yolov3.cfg是.cfg配置文件名
yolov3.weights:训练好的模型,yolov3.weights在darknet根目录
data/dog.jpg:“data/”是要测试图片所在路径,dog.jpg是测试图片文件名
测试命令解释
./darknet -i 0 detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0.25
# -i 0 指定GPU0 detector test cfg/coco.data=detect thresh(阈值)默认0.25
./darknet -nogpu detect cfg/yolov3.cfg yolov3.weights data/dog.jpg #无gpu,运算会失准
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg #简化版
./darknet detect cfg/yolov3.cfg yolov3.weights #多次检测 二次输入路径
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg #简化版yolov3,有点不准
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights #动态检测,需要安装opencv
cfg配置文件修改位置参数解释
[net]
# Testing ### 测试模式
# batch=1
# subdivisions=1
# Training ### 训练模式,每次前向的图片数目 = batch/subdivisions
batch=64
subdivisions=16
width=416 ### 网络的输入宽、高、通道数
height=416
channels=3
momentum=0.9 ### 动量
decay=0.0005 ### 权重衰减
angle=0
saturation = 1.5 ### 饱和度
exposure = 1.5 ### 曝光度
hue=.1 ### 色调
learning_rate=0.001 ### 学习率
burn_in=1000 ### 学习率控制的参数
max_batches = 5000 ### 迭代次数
policy=steps ### 学习率策略
steps=40000,45000 ### 学习率变动步长
scales=.1,.1 ### 学习率变动因子
[convolutional]
batch_normalize=1 ### BN
filters=32 ### 卷积核数目
size=3 ### 卷积核尺寸
stride=1 ### 卷积核步长
pad=1 ### pad
activation=leaky ### 激活函数
......
[convolutional]
size=1
stride=1
pad=1
filters=30 #3*(5+4+1)
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=5 #类别
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0 #1,如果显存很小,将random设置为0,关闭多尺度训练;
......
[convolutional]
size=1
stride=1
pad=1
filters=30 #3*(5+4+1)
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=5 #类别
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0 #1,如果显存很小,将random设置为0,关闭多尺度训练;
......
[convolutional]
size=1
stride=1
pad=1
filters=30 #3*(5+4+1)
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=5 #类别
num=9
jitter=.3 # 数据扩充的抖动操作
ignore_thresh = .5 #文章中的阈值1
truth_thresh = 1 #文章中的阈值2
random=0 #1,如果显存很小,将random设置为0,关闭多尺度训练;
参考文献
https://blog.csdn.net/weixin_41813620/article/
https://blog.csdn.net/qq_36780295/article/details/108010344
https://blog.csdn.net/qq_36417014/article/details/88533803
https://blog.csdn.net/public669/article/details/98020800