【学习笔记】基于元学习的噪声鲁棒网络训练(噪声转移矩阵估计)
这是一篇CVPR2020的论文,论文地址:
Training Noise-Robust Deep Neural Networks via Meta-Learning (thecvf.com) https://openaccess.thecvf.com/content_CVPR_2020/papers/Wang_Training_Noise-Robust_Deep_Neural_Networks_via_Meta-Learning_CVPR_2020_paper.pdf
https://openaccess.thecvf.com/content_CVPR_2020/papers/Wang_Training_Noise-Robust_Deep_Neural_Networks_via_Meta-Learning_CVPR_2020_paper.pdf
1.Abstract 摘要
标签噪声可能会显著降低深度神经网络(DNNs)的性能。为了训练对噪声具有鲁棒性的DNNs,损失校正(LC)方法由此提出。
LC方法假设噪声标签被一个未知的噪声转移矩阵T从干净的(真实的)标签中破坏。主干网络和T可以单独训练,其中T可以由先验知识进行估计。例如,T可以通过叠加每个类样本的最大值或平均预测来构造。
本文提出了一种新的损失校正方法,称为元损失校正(MLC),通过元学习框架直接从数据中学习T,而不是使用先验知识启发式地近似于T。
标签噪声指的是每一个样本的标签有概率损坏,或者转换为其他类的标签。例如由“狗”变为“猫”。
假设样本一共为10类,那么噪声转移(也称混淆矩阵)矩阵T应当是一个10×10的矩阵。
表示第i类样本标签转移到j类的概率。在无噪声的情况下,T应当是n维的单位矩阵。
2.Introduction 简介
深度神经网络的高性能依赖于大规模,高质量的数据集,而现实生活中获得这样的数据集代价往往十分高昂。也因此,日常收集到的数据集经常含有标签噪声。这些噪声会导致神经网络对于噪声的过拟合,降低模型性能。
损失矫正(LC)的目的就是解决这个问题。LC方法假设噪声标签按照一个未知的噪声转移矩阵T从真实标签中转移破坏。因此,LC方法试图准确地学习这个矩阵。
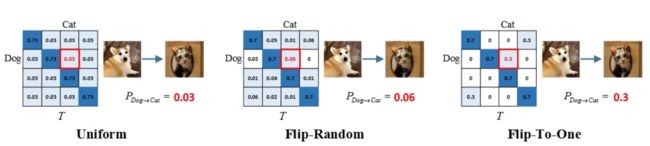 三种不同噪声的转移矩阵示例
三种不同噪声的转移矩阵示例
目前的方法可以分为隐式估计和显式估计两种。隐式估计需要在骨干神经网络后添加一个线性噪声层完成优化,显式估计,如《CVPR2017 Making Deep Neural Networks Robust to Label Noise: a Loss Correction Approach》中提到的,依赖于一种假设,也就是每一个类当中均存在一个“完美样本”,然后通过利用每个“完美样本”的预测来估计T。
利用元学习来估计转移矩阵T是一种从数据中直接学习T的方法,不需要先验知识和网络结构的修正。
由于元学习在超参数优化方面具有优异性能。通俗来讲,元学习就是“学习如何学习”。元学习通常使用一个小的“干净”的数据集来进行元训练。利用元训练的模型优化超参数,进而指导主模型的训练。两个训练过程交替进行。
具体来说,我们进行了交替优化来优化T和主网络权值θ。
- 对虚拟训练过程中对噪声训练集的θ进行一步向前虚拟优化
- 在元训练过程中,以元数据集的损失为指导优化T,固定一步θ
- 最后,在实际训练阶段的噪声训练集上使用更新的T对展开的θ进行优化
3.Related work 相关工作
Robust of loss function 鲁棒损失函数
如果用有噪声和无噪声数据学习的分类器都达到相同的分类精度,则称损失函数具有噪声鲁棒性。
最近的研究包括基于EM算法优化的复合损失函数,基于引导的“软”和“硬”损失函数,广义的交叉熵(GCE)损失,对称交叉熵损失(MAE)等等。这些鲁棒损失函数虽然取得了一定的成功,然而,它们在具有挑战性的噪声数据集上表现并不优秀。
Re-labelling 重标记
Re-labelling是指对有噪声的样本重新分配标签。重新标记包括两个设置:
- 一个小的干净的数据集
- 没有这样的数据集
对于(1),我们可以在干净样本上训练一个清洁模型重新标噪声数据,然后在干净数据和重新标记的数据合并的数据集上训练一个分类模型。或者从知识图和干净标签中提取信息,以指导有噪声数据的重新标记。
对于(2),我们可以采用一种自纠错(SEC)策略,基于CNN的预测/置信度来重新标记噪声数据。
Weighting 加权
加权的目的是学习为带有损坏标签的样本分配小的权重。包括联合教学策略,自步学习等等方法。
Loss correction method 损失矫正
损失校正方法基本上引入了噪声转移矩阵T来校正预测。这类方法的目的是学习最优T。目前的方法有在主干CNN的末端增加了一个额外的线性层,以模拟噪声过渡矩阵。以及使用先验知识来估计T。大多数现有的方法是基于先验知识估计T。相比之下,本文的方法直接从数据中优化T,而不依赖于先验知识和假设。
Methodology 方法
Noisy Label Problem
用![]() 表示有噪声数据集,其中
表示有噪声数据集,其中![]() 是C个类中的噪声标签。用
是C个类中的噪声标签。用![]() 表示无噪声的验证集,其中
表示无噪声的验证集,其中![]() 。
。
用 表示转移矩阵,
表示转移矩阵,![]() 表示样本由第i类(真实类)转移到第j类的概率。
表示样本由第i类(真实类)转移到第j类的概率。
用![]() 表示分类器网络,则交叉熵损失可以如下表示
表示分类器网络,则交叉熵损失可以如下表示

考虑转移矩阵T,修改如上损失函数为
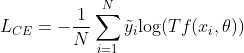
损失修正方法的有效性很大程度上依赖于T的估计。虽然“完美样本”的方法取得了很好的性能,但我们不能保证每个类的“完美样本”总是存在的。本方法采用元学习优化策略,元损失修正(MLC)来学习T。MLC不依赖于“完美样本”假设或样本预测的近似T。相反,MLC直接从数据中优化T。
Optimizing T via Meta Learning
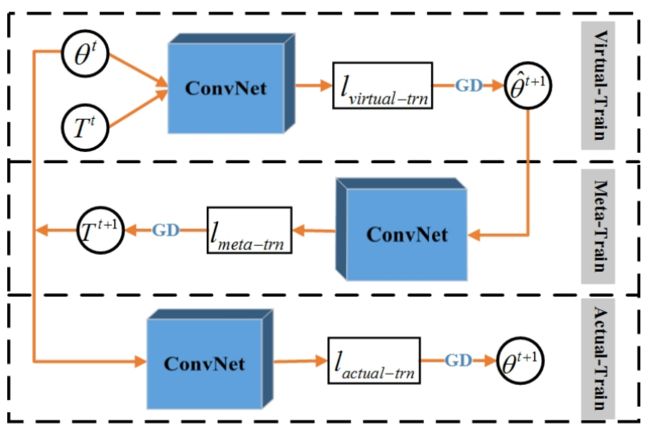 MLC方法框架图
MLC方法框架图
Virtual Train
第t步虚训练的损失函数为:
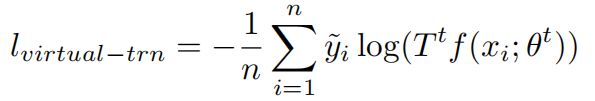
通过梯度下降法来优化θ,学习率为α
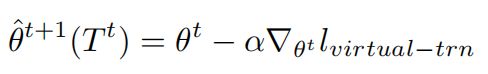
Meta Train
给定虚训练固定的参数![]() ,我们可以在验证集上优化
,我们可以在验证集上优化![]() :
:
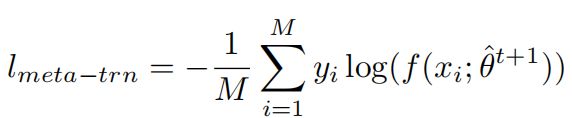
然而,这仍然是消耗耗时间和内存的,所以我们在一个小批量验证集上进行近似估计

通过梯度下降法更新T,学习率为β
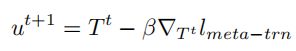
由于![]() 是原始的一步优化的噪声转移矩阵,所以
是原始的一步优化的噪声转移矩阵,所以![]() 未必全都是非负,而且未经过标准化。因此,我们进行如下变换
未必全都是非负,而且未经过标准化。因此,我们进行如下变换
![]()
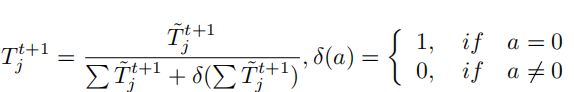
第一步变换保证了转移矩阵非负性,第二步则对T的每一行进行标准化,![]() 保证了分母不为零。
保证了分母不为零。
Actual Train
在对T的优化完毕以后,对主模型进行优化,采用梯度下降法,学习率为
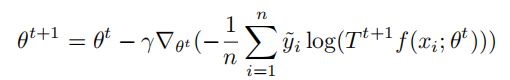
4.Conclusion 结论
在本研究中,当存在一个小型的干净数据集时,提出了一种基于学习的损失校正方法,即元损失校正(MLC),该方法可以通过元学习联合学习噪声转移矩阵T和网络参数。与大多数现有的使用先验知识来估计T的方法不同,MLC直接从数据中学习T。