搞明白 WebSocket 与 TCP/IP
我们用websocket来研究一下TCP/IP协议的一些特性,在《https 连接的前几毫秒发生了什么》一文里我们已经研究了https建立的过程。
在《https 连接的前几毫秒发生了什么》一文里是用的wireshark的抓包工具,这一篇将用tcpdump命令行工具。
01、tcpdump
Linux系的系统有一个很好用的抓包工具,叫tcpdump,可以用来抓取网络上的tcp包,例如我要抓取8080端口的包,可以执行以下命令:
sudo tcpdump port 8080 –n
-n的意思是端口号用数字表示,还可以加上-v -vv显示更详细的信息:
sudo tcpdump port 8080 –n -v
再如我要抓取来自特定源IP和发往特定目的IP的包,可以用以下命令:
sudo tcpdump src host 10.2.200.11 or dst host 10.2.200.11
指定src host和dst host,并用or/and做条件的交集和并集。
在建立一个网页的websocket之前先要建立一个http连接,为此我们简单写一个小demo。
02、 hello, world的http连接
(1)首先写以下的html文件:

(2)然后再装一个http-server的node包,监听在8080端口,如下所示:

(3)电脑开tcpdump命令,抓取通过8080端口通讯的包:
sudo tcpdump port 8080 –n
(4)用手机访问:http://10.2.200.140.8080,tcpdump就会打出所有传输的tcp包,如下图所示。
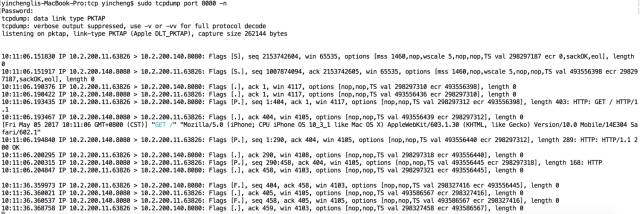
我们拿它打印的这些TCP报文做一个研究。在建立一个http连接之前,先要建立一个TCP连接,即上图的头3个报文。下面研究一下这个HTTP连接是怎么进行的。
03、 一个完整的HTTP连接
(1)TCP三次握手
第一个报文:11 -> 140
10:11:06.151830 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [S], seq 2153742604, win 65535, options [mss 1460,nop,wscale 5,nop,nop,TS val 298297187 ecr 0,sackOK,eol], length 0
在10点11分的时候,IP为10.2.200.11(以后简称11)的63826端口向IP为10.2.200.140(以后简称140)的8080端口发了一个TCP的包,带上了标志位SYN,表示要建立一个连接,并指明包开始的序列号seq(单位为字节),以后传送的字节编号都是以这个做为起点,并告知能接收的最大报文段长度mss为1460,一般mss都为1460.
第二个报文:140 -> 11
10:11:06.151917 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [S.], seq 1007874094, ack 2153742605, win 65535, options [mss 1460,nop,wscale 5,nop,nop,TS val 493556398 ecr 298297187,sackOK,eol], length 0
在过了87微秒之后,140进行了回复,发送了一个SYN + ACK的报文段,表示同意和11建立连接。
第三个报文:11 -> 140
10:11:06.190376 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [.], ack 1, win 4117, options [nop,nop,TS val 298297310 ecr 493556398], length 0
11收到SYN之后向140发送一个ACK,同时改变接收窗口为4117 * 2 ^ 5 = 131kb,完成三次握手。
什么是接收窗口呢?
(2)接收窗口
第四个报文里面,140也向11修改了它的接收窗口大小:
10:11:06.190422 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [.], ack 1, win 4117, options [nop,nop,TS val 493556436 ecr 298297310], length 0
大小为4117 * 2 ^ 5 = 131kb,为什么接收窗口是这个数呢?因为如下TCP的报文(头):

窗口大小只有2个字节16位,最大只能表示2 ^ 16 – 1 = 65535即16Kb,当初设计TCP的人并没有想到现在的网速会提升这么快,16Kb是不够用的,所以在可选项里面加了一个wscale(window scale factor)的指数字段,最大值为14,所以最大的接收窗口大概为1GB.
说了这么多,接收窗口是用来做什么的呢?它根据自身网络情况设置不同大小的值用来控制对方发送速度,避免对方发送太快,导致网络拥塞。下面讲到拥塞控制会更进一步地讨论。
(3)发送数据
建立好TCP连接后,11向140发送了一个http请求:
10:11:06.193435 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [P.], seq 1:404, ack 1, win 4117, options [nop,nop,TS val 298297312 ecr 493556398], length 403: HTTP: GET / HTTP/1.1
这里,它带上了一个PUSH的标志位,表示它是一个比较紧急的报文,要求对方立即把数据从缓存里面发送给应用程序,不能再继续缓存了。
它发送的字节号为[1, 404),这个数字是tcpdump显示的相对于握手的协议初始序列号显示的偏移,它是一个左闭右开的表示,所以这个报文总共发送了403个字节的数据。它是一个GET请求。
然后后140收到后给11回复了一个ACK:
10:11:06.193467 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [.], ack 404, win 4105, options [nop,nop,TS val 493556439 ecr 298297312], length 0
ACK 404表示期待收到第404字节的数据,也就是说前面403个字节的数据已经都确认收到。
然后140进行了http响应:
10:11:06.194840 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [P.], seq 1:290, ack 404, win 4105, options [nop,nop,TS val 493556440 ecr 298297312], length 289: HTTP: HTTP/1.1 200 OK
10:11:06.200295 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [.], ack 290, win 4108, options [nop,nop,TS val 298297318 ecr 493556440], length 0
10:11:06.200315 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [P.], seq 290:458, ack 404, win 4105, options [nop,nop,TS val 493556445 ecr 298297318], length 168: HTTP
10:11:06.204847 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [.], ack 458, win 4103, options [nop,nop,TS val 298297321 ecr 493556445], length 0
140总共发送了457个字节的数据,分成了两个包发送。而本地的html文件大小为:
![]()
所以可以认为http报文头占用了457 – 168 = 289字节。
(4)关闭连接
第一个报文:11 -> 140 FIN
10:11:36.359973 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [F.], seq 404, ack 458, win 4103, options [nop,nop,TS val 298327416 ecr 493556445], length 0
11等了30s后觉得不用再请求数据了,于是要把连接关闭了,它向140发送一个FIN的报文。为什么要等30s才关闭呢?这是HTTP请求的Connection: keep-alive字段影响的,因为同一个域可能要请求多个资源,不能一个请求完了就把连接关闭了。如果不关闭又占用端口号资源,我们知道端口号最多只有65535个。
第二个报文:140 -> 11 ACK
10:11:36.360021 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [.], ack 405, win 4105, options [nop,nop,TS val 493586567 ecr 298327416], length 0
140收到这个包后向11发送一个ACK,这个时候连接处于半关闭状态,即11不可再向140发送数据了,但140还可以向11发送。
第三个报文:140 -> 11 FIN
10:11:36.360537 IP 10.2.200.140.8080 > 10.2.200.11.63826: Flags [F.], seq 458, ack 405, win 4105, options [nop,nop,TS val 493586567 ecr 298327416], length 0
140也要把连接关闭了,于是它向11发送FIN
第四个报文:11 -> 140 ACK
10:11:36.368758 IP 10.2.200.11.63826 > 10.2.200.140.8080: Flags [.], ack 459, win 4103, options [nop,nop,TS val 298327458 ecr 493586567], length 0
11收到后,向它发了一个ACK,此时连接完全关闭。然后主动关闭方11将进入TIME_WAIT状态
(5)MSS和TIME_WAIT
TIME_WAIT时间为2MSL,MSL的意思是maximum segment livetime,即报文段的最大生存时间,标准建议为2分钟,实际实现有的为30s。在TIME_WAIT状态下,上一次建立连接的套接字(socket)将不可再重新启用,也就是同一个网卡/IP不可再建立同样端口号的连接,如上面是10.2.200.11.63826,如果再重新创建系统将会报错。
为什么要等待这个时间呢?主要是为了避免有些报文段在网络上滞留,被对方收到的时候如果刚好又启用了一个完全一样的套接字,那么就会被认为是这个连接的数据。因此为了让所有“迷路”的报文彻底消失后,才能启用相同的套接字。
但是有时候你会觉得两分钟不能重新启动相同的socket,有点麻烦,所以要把它禁了,可以在创建socket的时候,指定SO_REUSEADDR的选项,这样就不用等待TIME_WAIT的时间了。
另外还有一个时间叫RTT(round trip time),即一个报文段的往返时间,可以理解为我发一个数据给你,你再回我一个ACK这个往返过程的时间,这个时间是动态计算的,在下面讲拥塞控制的时候将会提及这个时间。
接下来讨论两个问题。
04、 为什么TCP握手要三次?
为什么不是两次、四次呢?有人说三次是建立一个可靠连接最少的次数,那为什么不是两次呢?两次好像也可以啊,就像打电话:
甲:喂,你听得到吗?
乙:我听得到
然后甲就可以开始说话了。再举另外一个例子做说明,假设有三个山头:A、B、C,A山头想要联合B山头的人晚上六点去攻打
C山头的人,因为如果只有一个山头的人去攻打C的话会阵亡,所以A和B需要进行握手。
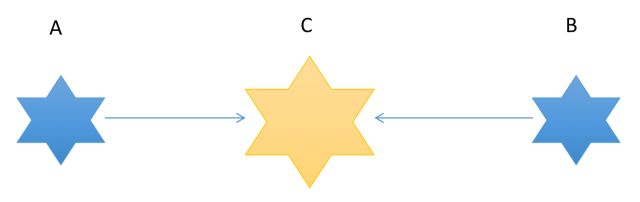
于是:
-
A就派了只鸽子带上SYN的消息过去找B
-
B收到后又派了只鸽子带上ACK + SYN的消息回复A
-
A收到后又派了只鸽子带上ACK去回复B
这个就好像我们的三次握手,但是三次就够了吗?假设第三次A发的ACK B没有收到,这时候B就要犹豫了:会不会A不知道我同意了,如果A不知道我同意那么它可能不会去攻打了,然后我去了就得被灭了。由于A不知道它的回复有没有被收到,所以它可能会想到B可能会怕它不会出击,所以A也犹豫了。
因此三次握手并不能保证双方完全地信任对方,即使是四次、五次也是同样道理,至少有一方无法信任另一方,另外一方一想到对方可能不信它,它也会变得不信对方。
但是这个例子并不是说TCP连接建立是不可靠的,实际的场景往往是只要双方确认对方都在就好了,如下:
甲:你活着吗?我想和你通话
乙:我活着呢,我们开始通话吧
因此最少的握手次数应该是两次,三次可以提高可靠性,四次、五次就没必要了,就会陷入上面山头攻打无限循环确认的漩涡。如下:
甲:你活着吗?我想和你通话
乙:我活着呢,我们开始通话吧
甲:好的
最后的“好的”可能有点多余,但是它显得比较有“人情味”。
难道两个山头通信真的没有办法解决吗?有办法,我们将在下面的拥塞控制提到。
05 、为什么挥手要四次
分析了握手次数的原因,很容易可以知道为什么挥手要四次了。前两次挥手让连接处于半关闭状态,此时主动关闭方不可再向被动关闭方发送数据,而被动关闭可继续向主动关闭方发送数据。如下图所示:
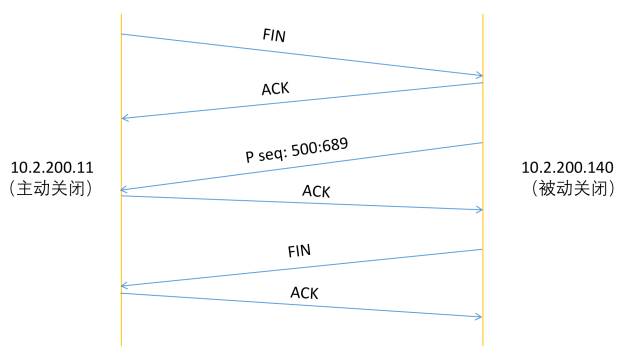
所以四次的原因是可以有一个处于半关闭的状态。
接下来看一下四层网络协议。
06、 四层网络协议
如下图所示,我们从发送数据的角度看四层网络协议:
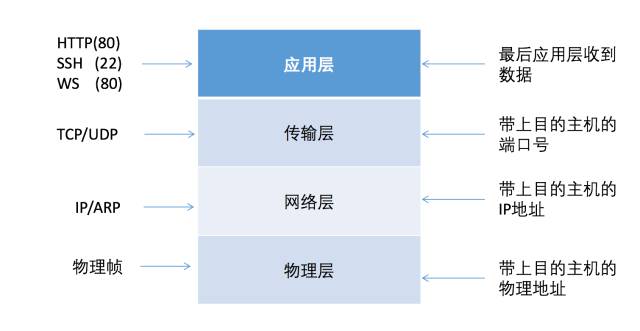
假设我要用HTTP发送一个文本,那么它会最后会被层层包装成这样一个报文
![]()
在广域网是用的IP地址进行报文转发,而到了局域网需要靠物理地址发送给对应的主机。IP是点到点,负责发送给对应的主机,而TCP是端到端,即根据端口号,负责发送给对应的应用程序。
(1)物理地址
每个网卡都有全球唯一的物理地址,路由器向同一个局域网所有主机发送收到的数据包,本机的网卡比较一下包里指明的物理地址和本机的物理地址是否一致,如果一致则接收,否则则丢弃。所以可以在局域网监听发给其它人的数据包,当然也有一些反监听的手段。
(2)网际层ARP
ARP是一个地址解析协议,当我访问10.2.200.140的时候我需要知道它的物理地址是多少,因为它已经是一个局域网的IP地址了。我怎么知道它的物理地址是多少呢?我就向局域网的机器广播一个ARP请求:
09:51:32.966852 ARP, Request who-has 10.2.200.140 tell 10.2.200.11, length 28
过了33微秒一小会的功夫就有人告诉我了:
09:51:32.966885 ARP, Reply 10.2.200.140 is-at 98:5a:eb:89:a5:7e (oui Unknown), length 28
这个很可能是路由器告诉我的,上面的tcpdump输出没有打印源IP。
可以通过arp -an的命令,查看电脑上的arp表,如下图所示:

(3)网际层traceroute
有一个很好用的命令叫traceroute,它可以追踪路由路径,它的原理是向目的主机发送ICMP报文,发送第一个报文时,设置TTL为0,TTL即Time to Live,是报文的生存时间,由于它是0,所以下一个路由器由到这个报文后,不会再继续转发了,会给源主机发送ICMP出错的报文,就可以知道第一个路由的IP地址,同理,设置TTL为1,就可以知道第二个路由的IP地址,依次类推。
如在北京traceroute广东电信,运行命令:
>traceroute gd.189.cn
控制台将不断地打印经过的路由,traceroute每次都会发三个报文:

可以看到为了到广东电信官网的服务器,经过了这么一个过程——首先发给了直接路由器进行转发,然后又在局域网的路由转发了几次,最后出来到了北京联通,中间又经过了北京电信和上海电信的路由器,最后到了广州电信的路由器。我们会发现每次走的路由可能会不一样,它是活的。这里又涉及到路由转发,本文不继续探讨。
每个报文都有一个TTL最大跳数,每经过一个路由就会把它减1,当减到0的时候,就不再继续转发了。避免某些报文被无限循环转发,造成网络资源的浪费。TTL位于IP报文的第9个字节。
(3)网际层Ping
另外一个很常用的命令是Ping,如Ping一下127.0.0.1可以看一下本机的网络协议是否工作正常,Ping一下某个服务器,看这个服务器有没有开,Ping一下某个域名,看它的IP地址是多少。Ping还可以这么用,例如Ping一下baidu:

可以看到要到百度服务器中间经过了64 – 49 = 15跳,所以可推测百度用的是Linux服务器,为什么呢,因为Linux默认的最大TTL = 64,而49和64最为接近。
Ping一下美国亚马逊:

到美国亚马逊,经过了255 – 217 = 38跳,所以推测亚马逊用的Unix服务器,Unix服务器默认的最大TTL为255.
再Ping一下中国版的w3school:

到中国版的w3school用了128 – 107 = 21跳,Windows的默认最大跳数为128,所以w3school用的是windows操作系统 ,因为它用的是ASP,所以它必定是windows系统。
继续回到demo实验的讨论,下面分析一些异常的情况。
07 、Reset报文
假设现在我把8080端口的http-server给杀了,然后再访问,会怎么样呢?会抓取到以下报文:
11:38:09.120488 IP 10.2.200.11.57049 > 10.2.200.140.8080: Flags [S], seq 1663158265, win 65535, options [mss 1460,nop,wscale 5,nop,nop,TS val 822068310 ecr 0,sackOK,eol], length 0
11:38:09.120524 IP 10.2.200.140.8080 > 10.2.200.11.57049: Flags [R.], seq 0, ack 1663158266, win 0, length 0
第一个报文还是SYN的报文,但是第二个报文服务器直接返回了RST,告诉对方不可建立连接。服务返回异常RST报文可能有以原因:
-
服务器没开服务
-
请求超时
-
服务程序突然挂了
-
在一个已关闭的socket上收到数据
08、 拥塞控制
现在我要上传一个文件,观察报文发送的情况,如下图所示:

上面0.70s的时间内,发送了1448 * 9 = 17k的数据(Mss 1460)
这个时候突然网卡了,又会怎么样呢?如下图所示:

上面1.45s的时间内,总共发送了9个包,5kb数据。
正常情况经常一次连续发送1448 * 6 = 8k数据,网卡即带宽下降的时候是如何控制发送速度的呢?先来看一下什么是接收窗口和拥塞窗口。
(1)接收窗口和拥塞窗口
在上传的过程中,服务器可能会不断地调整它的接收窗口大小:
14:03:38.479417 IP ec2-54-153-103-33.us-west-1.compute.amazonaws.com.https > 10.2.200.140.56342: Flags [.], ack 59651, win 850, options [nop,nop,TS val 954992962 ecr 598512063,nop,nop,sack 1 {61099:62547}], length 0
如收到上面的ACK报文后,服务器的接收窗口rwnd为:
rwnd = 850 * 2 ^ 5 = 27200 B
我本机自己有一个拥塞窗口cwnd,这个窗口用来控制我的发送速度,避免网络拥塞,这个拥塞窗口是动态变化的,下面会提到。实际的发送窗口大小为:
发送窗口 = min(cwnd, rwnd)
当cwnd > rwnd的时候是对方的接收能力限制了我的发送速度,而当rwnd > cwnd的时候,是我的网络情况造成了发送比较慢的情况。
发送窗口又是如何决定发送速度的呢:
(2)发送窗口
假设现在要发送hello, world这个文本,已经知道发送窗口为5B,最大报文段MSS减掉报文头占用的空间之后还剩下2B,那么发送如下图所示:
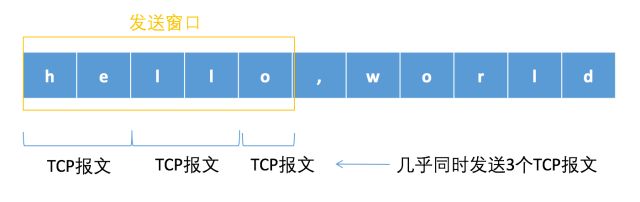
当我收到ACK报文之后,如ACK:3,那么就可以将我的发送窗口向右移动两个字节,然后继续发送发送窗口里未发送的报文,如下图所示:

如果没有收到对方的ACK,那么发送窗口将不可向右移动,也就是说不会发送了,如果ACK回复得慢,或者发送窗口本身比较比小,那么发送的速度就没那么快了。这就是发送窗口控制发送速度的原理。当对方的带宽下降时,它减少它的接收窗口来控制我的发送速度,而当我的网卡的时候我减少我的拥塞窗口控制发送速度。
但是怎么知道网卡了呢?
(3)慢启动和拥塞避免
由于建立完连接后,发送方不知道当前的网络情况怎么样,所以它会非常地谨慎,先慢慢地发,如果对方的ACK回复很及时,那么说明可以继续加大发送的量,并且指数位地增加,这个就是慢启动。如下访问一个Linux服务器的网址:

可以看到,服务在收到一个GET请求后进行响应,第一次同时只发3个包,并且从时间间隔上我们可以肯定它是故意的。也就是说它是一个慢启动,为什么第一次是3个呢,因为Linux 2的系统的初始化拥塞窗口initcwnd为3MSS,3MSS说明第一次只能发3个包(每个包不能超过最大报文段的长度),不同操作系统的initcwnd值如下所示,参考:
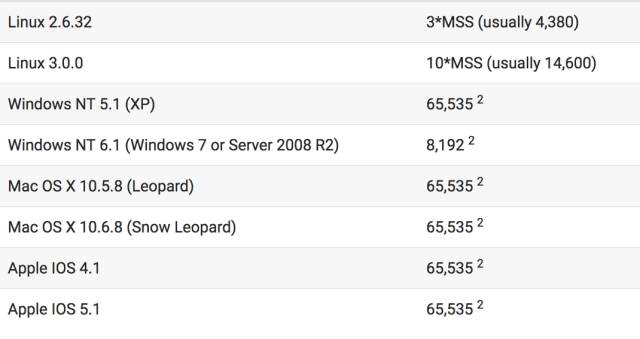
Linux3据说是因为接受了谷歌的建议,所以改成了10MSS。
具体慢启动的过程如下图表所示:
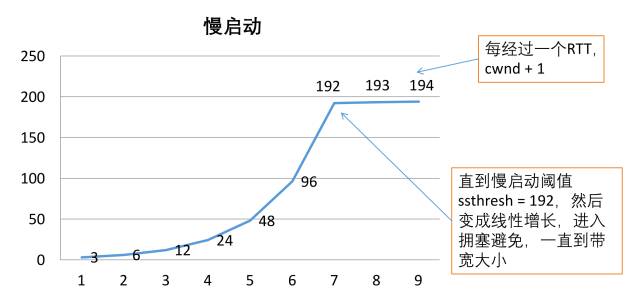
拥塞窗口会以指数倍增长,一直增长到拥塞阈值ssthresh,假设这个值为192。然后再以递增的方式增加拥塞窗口,这个阶段叫拥塞避免。也就说当cwnd < ssthresh时是慢启动的过程,而当cwnd > ssthresh时是拥塞避免。一直增长到合适的带宽大小。
在慢启动和拥塞避免过程中,可能会遇到网络拥塞的情况,造成丢包的情况,具体表现为很长时间没有收到对方的ACK,或者收到重复的ACK。
(4)超时重传
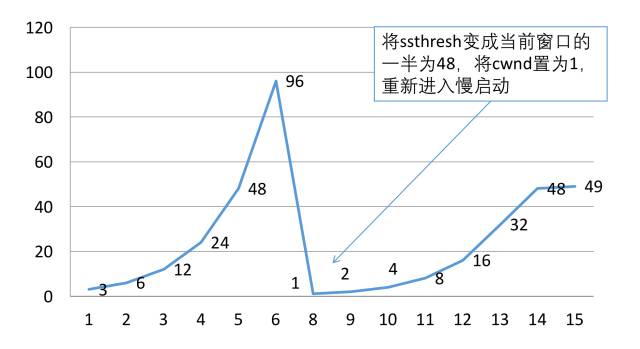
假设很长时间没有收到对方发送的ACK,这个时间超过了定时器的范围,导致进行重传,如下图所示:

上图总共重传了三次,第一次重传隔了约1.2s,第二次隔了2.4s,第三次隔了3.5s,我们观察到超时重传的时间间隔会增加,并且发生超时之后最多只会发送一个报文,这个时候它进入了慢启动的过程,如下图表所示:
当本机收到上传服务器的ACK之后,又继续发了两个报文:

这个与上面的描述一致,即重新进入了慢启动。
到这里我们就可以解决两个山头如何可靠地通信、保证同时去攻打另一个山头的问题了。很简单,A派了只鸽子发一个消息给B之后,B给他回了一个ACK,假设一只鸽子从B飞到A需要1个小时,B派出去鸽子之后如果过了两个小时,B没有收到A发送的一个重复的消息给它,即没有进行超时重传,就可以认为B派出去的那只鸽子A已经收到了。那要是刚好不巧A派出去的第二只鸽子不见了呢,那A又再继续超时重传,如果需要重传很多次的话,那就放弃吧,就像TCP一样。客观条件不允许,没有办法。
有一种情况不用等超时,可以马上进行重传。
(5)快速重传和快速恢复
假设本机向服务器按顺序发了三个包,但是这三个包可能并没有按顺序到达,有可能第三个包先到了,这个时候服务器收到了乱序的数据,于是它马上产生一个重复的ACK,要求重新获取从第一个包开始的数据。收到重复ACK时,不应该马上进行重传,因为可能很快乱序的另外两个又及时到了。但是当收到三个重复的ACK时就可以认为那个包已经丢了,需要进行重传,不用等到超时,这个就叫做快速重传。如下图所示:
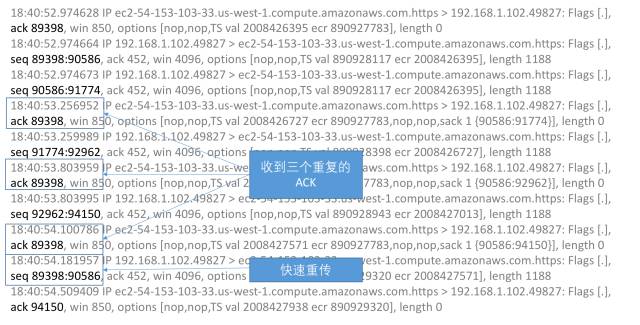
快速重传之后就进入了快速恢复的阶段。和超时重传不一样的地方是,超时重传认为当前的网络情况十分糟糕,所以一下子把拥塞窗口cwnd置成了1,重新进入慢启动。而快速恢复认为当前网络并没有那坏,它把拥塞窗口cwnd置成了当前拥塞窗口的一半加3,ssthresh置成老拥塞窗口的一半:如下图所示:
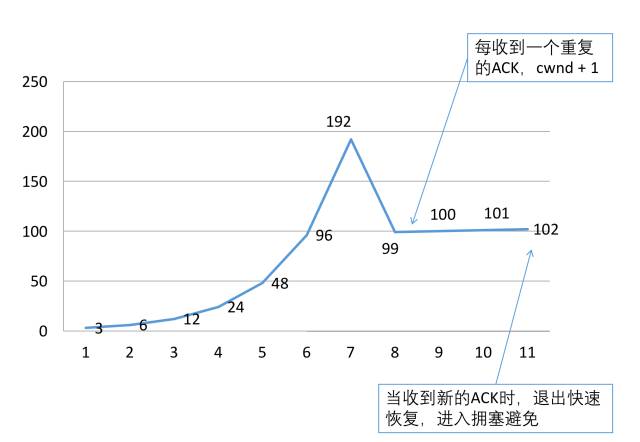
这个过程就叫做快速恢复,当收到一个新数据的ACK时,将退出快速恢复,将cwnd置为ssthresh,进入拥塞避免。
(6)慢启动的缺点
慢启动的优点是在比较拥塞的网络,慢启动可以避免拥塞进一步地加剧,但是它的缺点也是明显的,对于正常的网络,慢启动将降低传输的效率,例如本来一个RTT就可以传完的数据,现在要分成几个RTT(假设发送的数据量刚好是这样),特别是Linux 2的服务器initcwnd只有3MSS,所以可以手动把它改大,如改成10,可执行以下命令:
sudo ip route change default via 192.168.1.1 dev eth0 proto static initcwnd 10
快速恢复的引入也是考虑到了慢启动的缺点。
然后再讨论一个很出名的算法。
09 、Nagle算法
假设要通过http发送hello, world这12个字节,但是实际上要发送多少个字节呢?如下:
12:12:57.091926 IP 10.2.200.140.http-alt > 10.2.200.11.60882: Flags [P.], seq 288:301, ack 378, win 4105, options [nop,nop,TS val 678005709 ecr 845655611], length 13: HTTP
http数据总共发送了300个字节,也就是说http报文头就占用了288个字节,但是这还不包括其它报文头,如下所示:

也就是说为了发送12个字节的数据,总共得发送356个字节,有效内容仅占了4%不到。因此在那个需要用电话拨号上网的年代,这个代价就有点大了,所以Nagle算法的核心思想是:等数据积累多了再一起发出去,大概等待200ms,这样可以提高网络的吞吐率。
但是在现在光纤的时代,带宽和速度已经不是太大的问题了,如果每个请求都要延迟200ms,会造成实时性比较差。所以通常是要把Nagle算法禁掉,可以在创建套接字的时候设置TCP_NODELAY标志位。
10 、HTTP报文头大小限制
(1)请求头大小限制
标准并没有规定http请求头的大小限制,但是在实际的实现上会有限制。如nginx限制为4k – 8k,tomcat最小支持8K。
(2)url长度限制
如下http报文格式所示:

URL是在请求行里面的,并不在请求头里,同样标准也没有规定URL有长度限制,但是实际的实现有限制,如下图所示:

一个比较安全的值应该是8K,这样兼容性最好。同时需要注意的是GET请求,参数是在URL里面,而POST请求参数是在请求数据里面,所以GET请求的数据不能太大。
(3)cookie的长度限制
cookie是在请求头里以普通键值对的方式存在,一般一个domain的cookie不能超过4Kb,50个cookie,不然浏览器可能会不支持。服务可以通常Set-Cookie通知客户端设置cookie,而客户端可以用Cookie字段告知服务现在的cookie数据是怎么样的,如下所示:

上面的一些基础问题讨论完了,我们终于可以来分析websocket了。
11、 Websocket
(1)实现一个web聊天
怎么实现一个http的web的实时聊天呢,怎么知道对方有没有发送消息给我呢?有几种方法。
第一种办法使用轮询,例如每隔2s就发一个请求向服务端查询,但是这种方法会造成资源的浪费。
第二种办法使用Service Worker实现浏览器的Push,这种方法需要先注册FCM账号,获取到一个App Id,用Service Worker监听,服务向https://android.googleapis.com/gcm/send发送消息,谷歌服务器就会向那个App Id发送一个推送,就实现了浏览器的Push。但是这种办法兼容性还不是很好,并且大陆的小伙伴无法在正常网络环境收到谷歌服务器的消息。
所以就有了websocket建立常连接。为此建立一个websocket的demo.
(2)websocket的demo
为了实验,写一个websocket的demo,先装一个websocket的Node包,然后监听在8080端口,接着写客户端html5 websocket代码:
var socket = new WebSocket("ws://10.2.200.140:8080"); socket.onopen = function(){ socket.send("长江长江,我是黄河"); } socket.onmessage = function(event){ document.write("收到来自黄河的消息:" + event.data); }
打开这个页面,浏览器就会显示一个websocket的连接:

然后我们用tcpdump研究websocket连接建立的过程。
(3)Websocket连接建立
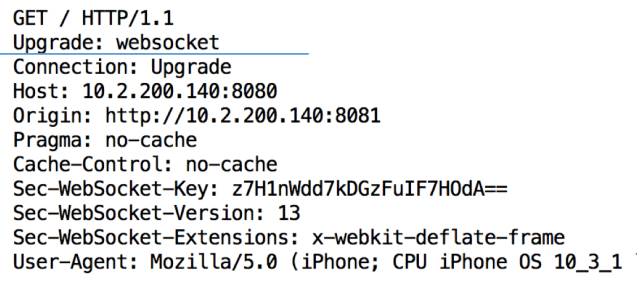
首先还是要先建立tcp连接,完成后客户端发送一个upgrade的http请求:
14:23:36.926775 IP 10.2.200.11.61205 > 10.2.200.140.8080: Flags [P.], seq 1:435, ack 1, win 4117, options [nop,nop,TS val 848067548 ecr 685816156], length 434: HTTP: GET / HTTP/1.1
这个报文的详细内容如下:
服务端收到后同意握手,返回Switching Protocols,连接建立,如下报文:
14:23:36.929714 IP 10.2.200.140.8080 > 10.2.200.11.61205: Flags [P.], seq 1:164, ack 435, win 4104, options [nop,nop,TS val 685816195 ecr 848067548], length 163: HTTP: HTTP/1.1 101 Switching Protocols
详细内容如下所示:

(4)传送数据
发送“hello, world”12字节内容,用ws只需要发送18字节,这比http 300个字节要少了很多:
14:24:36.009503 IP 10.2.200.11.61205 > 10.2.200.140.8080: Flags [P.], seq 492:510, ack 168, win 4112, options [nop,nop,TS val 848126486 ecr 685863159], length 18: HTTP
14:24:36.009556 IP 10.2.200.140.8080 > 10.2.200.11.61205: Flags [.], ack 510, win 4101, options [nop,nop,TS val 685875098 ecr 848126486], length 0
具体可以定义消息的类型,例如type = 1表示心跳消息,type = 2表示用户发送的消息,还可以再定义subtype,并自定义消息内容的格式,再封装一些自定义的消息机制等等。
(5)关闭连接
30s后,双方没有传送数据,websocket连接关闭,进行四次挥手。
14:25:06.017016 IP 10.2.200.140.8080 > 10.2.200.11.61205: Flags [F.], seq 170, ack 510, win 4101, options [nop,nop,TS val 685904974 ecr 848146558], length 0
这样就实现了一个实时的web聊天,需要注意的是websocket是一套协议,任何人只要遵守这套协议就可以使用并和其他人互联,不管你是JS还Android/IOS/C++/Java。ws默认监听在80端口,wss监听在443端口,和http/https一样。
最后再比较一下websocket和webRTC
(6)Websocket和WebRTC
Websocket是为了解决实时传送消息的问题,当然也可以传送数据,但是不保证传送的效率和质量,而WebRTC可用于可靠地传输音视频数据、文件等。并且可建立P2P连接,不需要服务进行转发数据。虚拟电话、在线面试等现在很多都采用WebRTC实现。
最后做个总结。这篇文章介绍了很多通信协议的东西,分析了TCP/IP的三次握手和四次挥手,并讨论了为什么握手是三次,而挥手是四次,还讲了四层网络模型,分析了工作在不同层的协议和工具,后面又重点分析了TCP的拥塞控制,包括超时重传、慢启动和拥塞避免、快速重传和快速恢复,接着还讲了点HTTP的东西,最后简单分析了下Websocket连接的过程和它的特点以及和WebRTC的区别。
上面可以说是TCP/IP协议的核心内容,我们通过一两个demo把它给串了起来,对读者应该有一个启发作用,可以更深刻地理解网络协议,当你在写一个请求的时候,你知道它的背后发生了什么。读者可以根据本文再继续查阅相关资料延伸扩展。如有不正确之处还请指出。