多机多卡技术测试-多节点单GPU(CUDA+MPI平方运算)
目录结构
Makefile
MPICC=/usr/local/mpich/bin/mpicxx
NVCC=/usr/local/cuda-10.2/bin/nvcc
MPI_INCLUDE= -I /usr/local/mpich/include
MPI_LIBS= -L /usr/local/mpich/lib -lmpich
CUDA_INCLUDE= -I /usr/local/cuda-10.2/include
CUDA_LIBS= -L /usr/local/cuda-10.2/lib64 -lcudart
CFILES=simpleMPI.c
CUFILES=simpleCu.cu
OBJECTS=simpleMPI.o simpleCu.o
all:
$(MPICC) -c $(CFILES) -o simpleMPI.o
$(NVCC) -c $(CUFILES) -o simpleCu.o
$(MPICC) $(CUDA_LIBS) $(OBJECTS) -o simpleMPI
# $(NVCC) $(MPI_LIBS) $(OBJECTS) -o simpleMPI
run:
mpirun -n 2 ./simpleMPI
clean:
rm -f simpleMPI *.o
simpleCu.cu
#include simpleMPI.c
#include simpleMPI.h
#ifndef _SIMPLEMPI_H
#define _SIMPLEMPI_H
void initData(float *data, int dataSize);
void printTotalData(const char *name,float *data, int dataSize);
void printNodeData(int commRank,float *data, int dataSize);
void computeGPU(float *hostData, int blockSize, int gridSize);
#endif
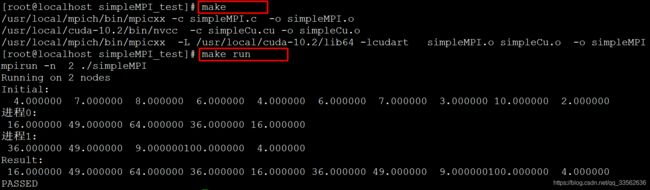
运行结果: