Point Transformer
Point Transformer
Nico Engel, Vasileios Belagiannis, and Klaus Dietmayer
Institute of Measurement, Control and Microtechnology
Ulm University, 89081 Ulm, Germany
Contributions
PointNet Problems:
problems arise with set pooling when the reduced feature vector lacks the capacity to capture important geometric relations.
- we propose Point Transformer,a neural network that uses the multi-head attention mechanism and operates directly on unordered and unstructured points sets
- we present sortnet ,a key component of Point Transformer,that induces permutation invariance by selecting points based on a learned score
Overview
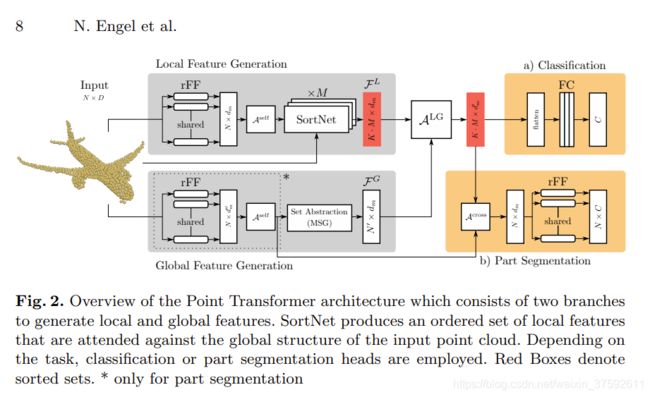
文中使用Point Transformer提取局部和全局特征,并引入局部-全局注意力机制以结合全局局部特征,用于获取点间关系和形状信息。
- SortNet:that extracts ordered local features set from different subspaces.
- Global feature generation of the whole point set
- Local-Global attention,which relates local and global features
Attention
1,self-attention
The attention function A ( ⋅ ) \mathcal{A}(\cdot) A(⋅) describes a maping of N queried Q ∈ R N × d k Q \in \mathbb{R}^{N \times d_{k}} Q∈RN×dk and N k N_k Nk key- value pairs K ∈ R N k × d k , V ∈ R N k × d v K \in \mathbb{R}^{N_{k} \times d_{k}}, V \in \mathbb{R}^{N_{k} \times d_{v}} K∈RNk×dk,V∈RNk×dv to an output R N × d k \mathbb{R}^{N \times d_{k}} RN×dk
计算不同部分的权重(关注点):
score ( Q , K ) = σ ( Q K T ) = s o f t m a x ( Q K T / d k ) \operatorname{score}(Q, K)=\sigma\left(Q K^{T}\right)=softmax(Q K^{T}/ \sqrt{d_{k}}) score(Q,K)=σ(QKT)=softmax(QKT/dk) where score ( ⋅ ) : R N × d q , R N k × d k → R N × N k (\cdot): \mathbb{R}^{N \times d_{q}}, \mathbb{R}^{N_{k} \times d_{k}} \rightarrow \mathbb{R}^{N \times N_{k}} (⋅):RN×dq,RNk×dk→RN×Nk (1)
A ( Q , K , V ) = score ( Q , K ) V \mathcal{A}(Q, K, V)=\operatorname{score}(Q, K) V A(Q,K,V)=score(Q,K)V where A ( Q , K , V ) : R N × d k , R N k × d k , R N k × d v → R N × d k \mathcal{A}(Q, K, V): \mathbb{R}^{N \times d_{k}}, \mathbb{R}^{N_{k} \times d_{k}}, \mathbb{R}^{N_{k} \times d_{v}} \rightarrow \mathbb{R}^{N \times d_{k}} A(Q,K,V):RN×dk,RNk×dk,RNk×dv→RN×dk (2)
其中 Q = X W Q , K = X W K , V = X W V Q=XW^Q,K=XW^K,V=XW^V Q=XWQ,K=XWK,V=XWV, W Q ∈ R d m × d k , W k ∈ R d m × d k , W V ∈ R d m × d k W^Q\in \mathbb{R}^{d_{m} \times d_{k}},W^k \in \mathbb{R}^{d_{m} \times d_{k}},W^V \in \mathbb{R}^{d_{m} \times d_{k}} WQ∈Rdm×dk,Wk∈Rdm×dk,WV∈Rdm×dk 是可学习参数矩阵
2,Multihead- attention
multihead-attention由多个self-attention组成,可以描述不同的特征信息
Multihead ( Q , K , V ) = ( (Q, K, V)=\left(\right. (Q,K,V)=( head 1 ⊕ … ⊕ _{1} \oplus \ldots \oplus 1⊕…⊕ head h ) W O \left._{h}\right) W^{O} h)WO
3,Transformer
由multi-head attention ,a point-wise fully connected layer ,each with a residual connection followed by layer normalization组成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4H8eFZUM-1607778024706)(C:\Users\ZHan\AppData\Local\Temp\1607516806029.png)]
A M H ( X , Y ) = \mathcal{A}^{\mathrm{MH}}(X, Y)= AMH(X,Y)= LayerNorm ( S + rFF ( S ) ) (S+\operatorname{rFF}(S)) (S+rFF(S)), A M H : R N × d m , R N k × d m → R N × d m \mathcal{A}^{\mathrm{MH}}: \mathbb{R}^{N \times d_{m}}, \mathbb{R}^{N_{k} \times d_{m}} \rightarrow \mathbb{R}^{N \times d_{m}} AMH:RN×dm,RNk×dm→RN×dm
$S=LayerNorm ( X + (X+ (X+ Multihead $(X, Y, Y))
4,Point Transformer
1,using a rFF to generate a latent feature P = [ p 1 latent , … , p N latent ] ∈ R N × d m P=\left[p_{1}^{\text {latent }}, \ldots, p_{N}^{\text {latent }}\right] \in \mathbb{R}^{N \times d_{m}} P=[p1latent ,…,pNlatent ]∈RN×dm
2,self multi-head attention: A self ( P ) : = A M H ( P , P ) \mathcal{A}^{\text {self }}(P):=\mathcal{A}^{\mathrm{MH}}(P, P) Aself (P):=AMH(P,P)
3,to attend elements of different sets,define cross multi-head attention:
A cross ( P , Q ) : = A M H ( P , Q ) \mathcal{A}^{\text {cross }}(P, Q):=\mathcal{A}^{\mathrm{MH}}(P, Q) Across (P,Q):=AMH(P,Q) , Q = { q j ∈ R D , j = 1 , … , N k } , Q=\left\{q_{j} \in \mathbb{R}^{D}, j=\right. \left.1, \ldots, N_{k}\right\} ,Q={qj∈RD,j=1,…,Nk}
SortNet
It produces local features from differemt subspaces that are permutation invariant by relying on a learnable score.

Input: the orginal point cloud P ∈ R N X D \mathcal{P}\in R^{NXD} P∈RNXD and the attention output latent feature P = [ p 1 latent , … , p N latent ] ∈ R N × d m P=\left[p_{1}^{\text {latent }}, \ldots, p_{N}^{\text {latent }}\right] \in \mathbb{R}^{N \times d_{m}} P=[p1latent ,…,pNlatent ]∈RN×dm
1,create a learnable scalar score s i ∈ R s_i \in R si∈R for each input point p i p_i pi
2,Select the Top-K point with the highest score value
Q = { q j , j = 1 , … , K } \mathcal{Q}=\left\{q_{j}, j=1, \ldots, K\right\} Q={qj,j=1,…,K} where q j = ⟨ p i j , s i j ⟩ j = 1 K , p i j ∈ P q_{j}=\left\langle p_{i}^{j}, s_{i}^{j}\right\rangle_{j=1}^{K}, p_{i}^{j} \in \mathcal{P} qj=⟨pij,sij⟩j=1K,pij∈P such that s i 1 ≥ … ≥ s i K s_{i}^{1} \geq \ldots \geq s_{i}^{K} si1≥…≥siK
3, Capture localities by grouping all points from P \mathcal{P} P that are within the euclidean distance r of each selected points.the grounded points are then uesd to encode local features,denoted by g j ∈ R d m − 1 − D , j = 1 , … , K g^{j} \in \mathbb{R}^{d_{m}-1-D}, j=1, \ldots, K gj∈Rdm−1−D,j=1,…,K
4,obtain local features which is ordered
F m L = { f i j , j = 1 , … , K } \mathcal{F}_{m}^{L}=\left\{f_{i}^{j}, j=1, \ldots, K\right\} FmL={fij,j=1,…,K} where f i j = p i j ⊕ s i j ⊕ g j , f i j ∈ R d m f_{i}^{j}=p_{i}^{j} \oplus s_{i}^{j} \oplus g^{j}, \quad f_{i}^{j} \in \mathbb{R}^{d_{m}} fij=pij⊕sij⊕gj,fij∈Rdm
5,To capture dependencied and local features from different subspaces.use M separate SortNets to abtain M features sets
F L = F 1 L ∪ … ∪ F M L , F L ∈ R K ⋅ M × d m \mathcal{F}^{L}=\mathcal{F}_{1}^{L} \cup \ldots \cup \mathcal{F}_{M}^{L}, \quad \mathcal{F}^{L} \in \mathbb{R}^{K \cdot M \times d_{m}} FL=F1L∪…∪FML,FL∈RK⋅M×dm
Global Feature Generation
To reduce the total number of points to sava computational time and menory,we employ the set abstraction multi-scale grouping(MSG) layer
- use FPS to subsample the entire point
- find neighboring points to aggregate features of dimension d m d_m dm resulting in a global representation of dimension N ′ × d m N^{\prime} \times d_{m} N′×dm
Local-Global Attention
In oder to relate local and global feature sets
所有的全局特征都是针对每个局部特征进行评分的,从而将局部信息与潜在的形状联系起来
A L G : = A cross ( A s e l f ( F L ) , A s e l f ( F G ) ) ( 11 ) \mathcal{A}^{\mathrm{LG}}:=\mathcal{A}^{\operatorname{cross}}\left(\mathcal{A}^{\mathrm{self}}\left(F^{L}\right), \mathcal{A}^{\mathrm{self}}\left(F^{G}\right)\right) (11) ALG:=Across(Aself(FL),Aself(FG))(11)
A L G : R K ⋅ M × d m , R N ′ × d m → R K ⋅ M × d m ′ \mathcal{A}^{\mathrm{LG}}: \mathbb{R}^{K \cdot M \times d_{m}}, \mathbb{R}^{N^{\prime} \times d_{m}} \rightarrow \mathbb{R}^{K \cdot M \times d_{m}^{\prime}} ALG:RK⋅M×dm,RN′×dm→RK⋅M×dm′
where F L F^{L} FL and F G F^{G} FG are the matrix representations of F L \mathcal{F}^{L} FL and F G \mathcal{F}^{G} FG
Experiments
1,不同方法实验结果对比

2,Rotation robustness of Sort Net

3, Visualizations of learned local regions
