深度学习于推荐系统综述:Deep Learning based Recommender System: A Survey and New Perspectives
前言
论文链接:https://arxiv.org/abs/1707.07435
部分内容参考于https://blog.csdn.net/w5688414/article/details/78651121系列博客
主要整理与MLP及AE相关内容,仅用于自己学习笔记之用
基于深度学习的推荐系统
1. 基于多层感知机的推荐系统
多层感知器(Multi-Layer Perceptron,MLP)也叫人工神经网络(Artificial Neural Network,ANN),除了输入输出层,它中间可以有多个隐层。最简单的MLP需要有一层隐层,即输入层、隐层和输出层才能称为一个简单的神经网络。习惯原因我之后会称为神经网络。通俗而言,神经网络是仿生物神经网络而来的一种技术,通过连接多个特征值,经过线性和非线性的组合,最终达到一个目标进行输出完成具体任务。

多层感知机是一个简单而高效的模型。广泛应用于许多领域,特别是工业领域。多层前馈网络被证明可以以任意精度逼近一个可测函数(measurable function),它是许多高级模型的基础。
1.1 仅依赖于MLP的推荐
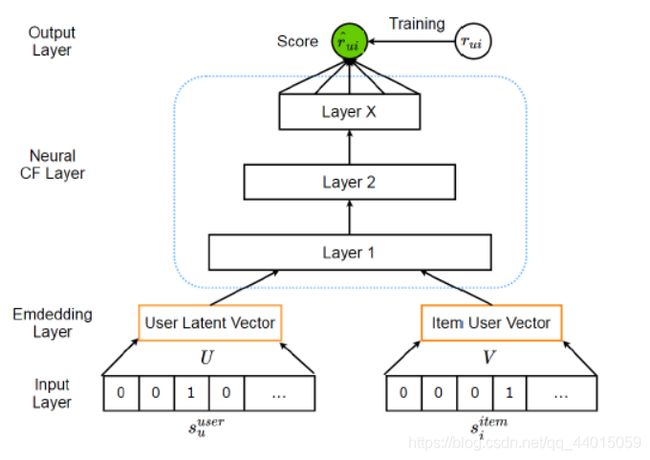
神经协同过滤(Neural Collaborative Filtering)
在大多数情况,推荐是用户偏好和物品特征这两种方式的交互。例如,矩阵分解把评分矩阵分为一个低维的隐式用户空间和一个低维的隐式物品空间。基于内容的推荐系统产生了基于用户画像和物品特征的相似度的推荐列表。因此,很自然的我们就可以建立一个对偶网络,对用户和物品两种交互方式进行建模。神经协同过滤(Neural Collaborative Filtering, NCF)就是这样一个框架,它旨在捕获用户和物品的非线性关系。
有人提出把NCF模型拓展为交叉域的社交推荐,例如,推荐信息域的物品给社交网络的潜在用户,提出了一个神经社交协同等级推荐系统,另一个拓展是CCCFNet(Cross-domain Content-boosted Collaborative Filtering neural Network),CCCFNet的基本组件也是一个对偶的网络(分别对用户和物品),在最后一层用内积对用户-物品交互进行建模,为了嵌入内容信息,作者进一步把对偶的每个网络分解为两个成分:协同过滤因子(用户和物品潜在因素)和内容信息(物品特征的用户偏好和物品特征)。多视角神经框架建立在这个基本模型的基础上,用来进行交叉域推荐。
Wide & Deep Learning

如上图,这个一般的模型既可以解决回归问题又可以解决分类问题。最开始它是用于Google Play的App推荐,wide learning组件是一个单层感知机,这可以被看做一个一般的线性模型,deep learning组件是一个多层感知机,结合这两个学习技术的依据是它使得推荐系统能同时捕获记忆memorization和generalization。Memorization是从wide learning组件获得的,它代表抓住从历史数据直接特征的的能力。与此同时,deep learning组件能抓住generalization,它产生了更多一般和抽象的表达。这个模型能够提高精度且实现推荐的多样性。
部署wide & deep learning的一个很重要的步骤就是选择宽度和深度部分的特征,换句话说,系统应该可以决定哪个特征该记忆或者被泛化。另外,交叉内积转换也需要手工设计,这些预步骤对模型的效果影响很大,为了缓解特征工程中的手工处理,Guo等人提出了深度因子分解机(Deep Factorization Machine, DeepFM)。
Deep Factorization Machine
DeepFM是一个端到端的模型,它无缝的整合了因子分解机和MLP.它可以通过深度神经网络进行高阶特征交互,通过因子分解机进行低阶交互。因子分解机利用额外操作和内积操作去捕获特征间的线性和成对的交互。MLP均衡了非线性激励和深度解构,用来对高阶交互进行建模。和wide & deep模型相比,DeepFM不需要枯燥的特征工程,它把wide组件替换成了一个因子分解机的神经解释。
1.2 整合MLP和传统的推荐系统
注意力的协同过滤(Attentive Collaborative Filtering)
注意力机制是受人类视觉注意力的启发。例如,人们只需要关注视觉输入的特定部分就可以理解和识别它们。注意力机制可以从输入中过滤掉无信息的特征,减少噪声数据的副作用。基于attention的模型在一些任务上表现出了可喜的效果,例如语音识别,机器翻译。最近的工作证明他可以增强推荐的性能,把它和深度学习技术结合起来用于推荐系统。Chen等人提出了一个注意力的协同过滤模型,对隐式因子模型引入了一个两级注意力机制。注意力模型是一个MLP,由物品级别和部件级别的注意力组成。物品级别的注意力用于选择最有代表性的物品来描述用户,组件级别的注意力旨在给用户从多媒体辅助信息中捕获最有信息的特征。
Alashkar等人提出了一个基于MLP的模型用于化妆品推荐。这个工作使用了两个相同的MLPs去分别对标记的样例和专家规则进行建模,这两个网络的参数同时更新,最小化他们的输出的差别。它证明了采用专业知识的功效,用它去指导推荐系统在MLP框架中的学习过程。但是,专业知识的获取需要大量的人力参与,代价很高。
Covington把MLP应用到YouTube推荐上。这个系统把推荐任务分为两个阶段:
候选产生(candidate generation)和候选排序(candidate ranking)
候选产生网络从所有的视频语料库中检索一个子集(几千)。候选排序网络用基于最近邻分数的方法从候选项中产生top-n列表。我们注意到工业领域关注的是特征工程和推荐模型的可拓展性,特征工程例如例如转换,规范化,交叉。
2. 基于Autoencoder的推荐系统
Autoencoder相关内容:https://blog.csdn.net/qq_44015059/article/details/106504960
现存的两种把autoencoder运用到推荐系统上的方法为:(1)使用autoencoder在bottleneck层学习低维特征表达;(2)直接在重构层填充评分矩阵的空白。
2.1 仅仅依赖于Autoencoder的推荐
AutoRec
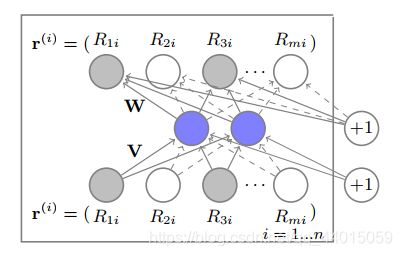
AutoRec把用户部分向量 r ( u ) r^{(u)} r(u)或者物品部分向量 r ( i ) r^{(i)} r(i)作为输入,旨在在输出层重构它们。明显的,它有两个变体:基于物品的AtuoRec(Item-based AutoRec, I-AutoRec)和基于用户的AutoRec(User-based AutoRec, U-AutoRec)。对应两种类型的输入。这里,我们只介绍I-AutoRec, U-AutoRec可以很容易的推导出来。
AutoRec在部署前有四个值得注意的点:
- I-AutoRec比U-AutoRec表现得更好,这可能是由于用户部分观测向量的偏差过大造成的。
- 不同激励函数的结合会对结果影响很大。
- 增加隐藏单元的大小会提升结果,因为拓展隐藏层的维度会给予AutoRec对输入特征(the characteristics of the input)更多的建模能力。
- 增加更多的层来构造更深的网络会有效的提升性能。
Collaborative Filtering Neural network(CFN)
它是AutoRec的一个拓展,有两个优点:
(1)它利用了降噪的技术,使得CFN更加的鲁棒;
(2)它融合了边信息来缓解稀疏性和冷启动的影响,例如用户画像和物品描述。
CFN的输入是部分观察向量,它有两个变体:I-CFN和U-CFN,分别把 r ( i ) r^{(i)} r(i)和 r ( u ) r^{(u)} r(u)作为输入。
作者用了三种corruption的方法来corrupt输入:Gaussian noise,masking Noise和salt-and-pepper noise。为了处理丢失的元素(它们的值为0),我们强加了masking noise,作为在CFN中的强正则项。
Autoencoder-based Collaborative Filtering(ACF)
ACF是第一个基于Autoencoder的协同推荐模型。和以前使用部分观察向量不同,它把向量分解为整数评级。例如,如果评级分数是整数,在[1,5]的范围内,每个 r ( i ) r^{(i)} r(i)被分为5部分向量。
上图是一个ACF的例子,评级范围是[1,5],阴影的条目表示用户已经对电影进行了相应的评级,例如用户给物品i评级为1,给物品2评级为4。和AutoRec以及CFN相似,ACF的代价函数旨在减少均方平方损失,ACF的评级预测的计算是对每个条目的五个向量的求和,在这个样例中,评级的最大值为5。它使用RBM去预训练参数以避免局部最优值,堆叠一些autoencoder在一起也可以稍稍提高精度。可是,ACF有两个缺点:
- (1)它不能解决非整数评级;
- (2)部分观察向量的分解会增加输入数据的稀疏性,导致精度的降低。
Collaborative Denoising Auto-Encoder(CDAE)
回顾的这三个模型早期主要是为评级预测而设计的,CDAE主要用于排序预测(ranking prediction)。CDAE的输入是用户部分观察的隐式反馈 r p r e f ( u ) r_{pref}^{(u)} rpref(u),如果用户喜欢电影,输入的值为1,否则为0。它也可以被认为是一个偏好向量,用来把用户的兴趣映射到物品上。

2.2 把传统的推荐系统和Autoencoder整合
紧耦合模型(Tightly coupled model)同时学习autoencoder和推荐模型的参数,这使得推荐模型为autoencoder提供指导,以学习更多的语义特征。松耦合模型分两步来做的:通过autoencoder来学习突出的特征,然后把这些特征用于推荐系统。这两种形式都有其优点和缺点。例如,紧耦合模型需要精心的设计和优化,以避免局部最优,但是推荐和特征学习可以同时进行;松耦合方法可以很容易地拓展现有的先进的模型(advanced models),但是需要更多的训练步。
紧耦合模型
协同深度学习(Collaborative Deep Learning, CDL)
CDL是一个层级的贝叶斯模型,它把SDAE(stacked denoising autoencoder)融入到了概率矩阵分解中;为了无缝的结合深度学习和推荐模型,作者提出了一个一般的贝叶斯深度学习框架,框架由两个紧铰链组件组成:感知组件(深度神经网络)和特定任务组件。特别地,CDL的感知组件是一个序数的SDAE的概率解释,PMF扮演的是特定任务的组件。这种紧耦合可是使CDL平衡边信息和评级的影响。
Collaborative Deep Ranking(CDR)
CDR是一个特别为top-n推荐的成对的框架,CDL是一个point-wise模型,最初是为评分预测而提出来的。可是,研究证明成对的模型对评分列表产生更合适。实验结果也证明CDR在评分预测上超过了CDL的表现。
3. 未来的研究方向和公开问题
当前的深度学习技术帮助建立实体基础,以增强推荐系统。涌现的大量的应用于推荐系统的深度学习技术会使得现在传统的推荐系统向深度推荐系统转变,这里,对于未来基于深度学习的演化,我们确定了几个新兴的研究趋势。
3.1 用户和物品的深度理解
做精确的推荐需要对物品的特点和用户的需求做深度的理解,这可以通过利用大量丰富的辅助信息来获得。例如,上下文信息(context information)会根据用户的环境和周围的事物来调整服务和产品,缓解冷启动的影响;隐式反馈意味着用户的隐式意图,并且很容易筹集,而收集显式反馈是一个资源需求任务(resource-demanding task)。尽管现在的工作已经调查了深度学习在挖掘用户和物品画像,隐式反馈,上下文信息,评论文本应用到推荐的效果,但是他们没有以全面的方式来利用这些边信息,未能完全利用现有的数据。另外,从社交网络和真实世界(Internet of things)来调查用户的足迹(Tweets or Facebook posts)的工作很少。我们可以从这些边数据源来推断用户的时序兴趣和意图,而深度学习是一个能融合这些信息的强有力的工具,深度学习处理异构数据源的能力也对推荐的多样性带来了更多的机会,这些物品往往是非结构化数据,例如文本,视觉,声音和视频特征。
对用户和物品的深度理解的另一方面是通过特征工程。特征工程还没有在推荐社区被完全研究,但是在工业应用中应用很普遍。可是,大多数现有的模型手工制作和选择的特征,但这是非常耗时且枯燥的。深度神经网络是一个减少人工干预的很理想的工具。加强深度特征工程在推荐系统反面的研究能够节省人力,也改进了推荐的质量。
3.2 深度复合模型(Deep Composite Models)
deep composite model结合了多种深度神经网络,能有效的对推荐系统中的决定因子(例如,用户,物品,上下文等等)的异构特征进行建模,但是把多种深度学习技术结合在一起来增强性能的研究很少。尽管如此,和可能的拓展相比,这些尝试是非常有限的,例如,autoencoder可以和DSSM融合,用来捕获特征之间的相似度。注意到,遵循的一般规则为,模型应该以敏感的方式设计,而不是随意的,并且要为实际的需要调整。
3.3 Temporal Dynamics
在推荐的时间动态上的第一个拓展是对session进行建模,尽管基于session的推荐系统不是一个新的研究领域,但是还有很多没有研究。和基于传统推荐的静态偏好相比,基于session的推荐系统更适合动态的时序的用户的需求。追踪用户的长时交互对许多网站和移动应用来说是不适用的,但是,短时的session通常可以得到,并且可用于辅助推荐过程。最近几年,RNN已经被证明它对于session的建模的优越性,拓展的工作,例如把辅助信息融入到RNN,把其它深度学习技术应用到基于session的推荐可以进一步进行。
第二,用户和物品的进化和共同进化是时序影响的重要方面。因为用户和物品的进化可以是单独的也可以是共同的。例如,app随着时间改变,新版本的更替等等。深度序列模型是一个对进化和共同进化影响建模的理想化工具,也是一个映射潜在时序本质建模的理想化工具。
3.4 Cross Domain Recommendation
现今,许多大公司为消费者提供多样化的产品和服务。例如,Google为我们提供网页搜索,手机应用和新闻服务;我们可以从Amazon买书,电器和衣服。单域推荐系统只关注一个域,而忽略了其它域的用户兴趣,这也使得稀疏性和冷启动问题更加严重。交叉域推荐系统为这些问题提供了一个很好的解决方案,它用源域学来的知识来辅助目标域推荐。在交叉域推荐中的一个被广泛研究的话题是迁移学习,它旨在用其它域学来的知识来提升原域的内容。深度学习非常适合迁移学习,因为它学习到了高级抽象,这摆脱了不同域的变化性。一些现有的工作表明深度学习在捕获不同域的一般性和差别的功效很好,以及在交叉域平台上产生了更好的推荐。因此,这是一个有前景,还有很多未开发的领域,在这方面期望有更多的研究。
3.5 Multi-Task Learning
多任务学习已经在许多深度学习任务上取得了成功,从计算机视觉到自然语言处理。在这些回顾的研究中,一些工作也把多任务学习应用到了深度神经框架下的推荐系统,并且在单个任务学习上取得了一些进步,应用基于深度神经网络的多任务学习的有点有三点:(1)一次学习多个任务,通过泛化共享的隐藏表示,可以阻止过拟合;(2)辅助数据为推荐提供了可解释的输出;(3)多任务提供了隐式的数据增强,这能缓解稀疏问题。多任务可以用于传统的推荐,而深度学习使得他们以一种激励的方式来集成。除了介绍边任务,我们也把多任务学习用于交叉域推荐,每个特定的任务产生特定域的推荐。
3.6 Attention Mechanism
注意力机制是一个凭直觉的但是有效的技术,它可以应用到MLP,RNN,CNN,和其它许多深度神经网络中。例如,把Attention机制融入到RNN中,它可以使得RNN能够长的有噪声的输入。尽管LSTM可以理论上解决长记忆问题,但是当处理长范围的依赖的时候,它是有问题的。Attention机制提供了一个更好的解决方案,它帮助网络能更好的记忆输入。基于Attention的CNN能够捕获输入中有信息的部分。通过把Attention机制应用到推荐系统,它可以用attention机制来过滤掉没有信息的内容,选择最有代表性的物品,提供更好的解释性。
3.7 Scalability
大数据时代数据量的增加对真实世界的应用构成了挑战。结果,可拓展性是推荐模型在真实世界应用的关键所在,时间复杂度也是选择模型的时候考虑最重要的部分。幸运的是,深度学习已经被证明在大数据分析上非常有效且有前景。可是,未来的研究应该研究怎样高效的推荐,通过探索下面的问题:
(1)非平稳流数据的增量学习,例如大量的涌来的用户和物品;
(2)高维张量和多媒体数据源的计算效率;
(3)随着参数指数性的曾展个,需要均衡模型复杂度和可拓展性。
3.8 Novel Evaluation Metrics
大多数前面的研究关注的都是准确性,要么旨在改进recall/precision,要么减少预测误差。可是,准确性对于长时高质量的推荐系统远远不够,甚至导致过于专一化。除了准确度,其它评估尺度,例如多样性,新颖性,机缘凑巧(serendipity)和范围(coverage),信赖(trustworthiness),隐私,可解释性,等等也同等重要。通过鼓励多样性和惊喜度,推荐系统会给那些意图不明确不确定的顾客带来跟多的价值;增加信任和隐私会减少用户的担忧,给予他们更多利用他们感兴趣物品的自由;好的解释性为每个推荐提供证据,展示更多可信任的结果给用户。因此,推荐系统不仅要对历史精确建模,也要给用户提供一个很好的体验。
这里解释一下serendipity:推荐和用户历史兴趣不相似但又让用户满意的(定性描述)
稀疏问题
数据稀疏问题严重制约着协同过满推荐系统的发展。对于大型商务网站来说,由于产品和用户数量都很庞大,用户评分产品一般不超过产品总数的1%,两个用户共同评分的产品更是少之又少,解决数据稀疏问题是提高推荐质量的关键。
为了提高推荐质量,许多研究人员都试图缓和数据稀疏问题。他们从不同的角度对用户和产品信息进行分析、处理,降低数据的稀疏程度。这些算法各有利弊。
1.基于项目的协同过滤推荐算法
传统的协同过滤推荐算法是通过计算用户之间的相似性,寻找与目标用户兴趣相似的一组用户,作为目标用户的最近邻居。然而,由于数据的极端稀疏性,两个用户共同评分的产品非常少,得到用户之间的相似性很有可能为0。因此,出现了基于项目的协同过滤推荐技术。
基于项目的协同过滤推荐算法,从产品角度进行分析,寻找与目标产品相似的产品集合,然后进行预测和推荐。它基于一个假设,即用户对与其感兴趣产品相似的产品也感兴趣。由于项目间的相似性相对稳定,而通常项目的数量比用户数量少,这样可以减少计算量,降低数据稀疏性。
2.降低矩阵维数的技术
降低矩阵维数的技术可对原始稀疏数据直接进行数据处理,降低数据稀疏性。主要算法有单值分解、聚类等。
2.1单值分解
单值分解算法利用矩阵的单值分解原理,对用户—产品矩阵进行分解,从而降低矩阵的维数,抽取出主要信息。
2.2聚类
单值分解通过矩阵运算降低数据稀疏性,聚类则是通过一些聚类算法将产品或用户聚成若干具有共同性质的类;然后在小的聚类数据中产生推荐。聚类算法有很多,如用K-means对用户的聚类算法。K-means算法是目前最通用的快速聚类算法。
3.基于内容的协同过滤算法
以上介绍的算法都是建立在用户对产品评分的基础上,在一定程度上都缓和了数据稀疏带来的问题。基于产品内容的协同过滤算法与前面介绍的几种算法的不同之处,是考虑到了产品本身的信息。由于增加了信息量,可以有效提高推荐质量。
冷启动问题
如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题。
冷启动问题主要分为三类:
(1) 用户冷启动:如何给新用户做个性化推荐的问题,新用户刚使用网站的时候,系统并没有他的行为数据;
(2) 物品冷启动:解决如何将新的物品推荐给可能对它感兴趣的用户;
(3) 系统冷启动:如何在新开发网站设计个性化推荐系统,此时网站上用户很少,用户行为也少,只有一些商品的信息。
协同过滤推荐基于这样的假设:为用户找到他真正感兴趣的内容的方法是,首先找与他兴趣相似的用户,然后将这些用户感兴趣的东西推荐给该用户。所以该推荐技术最大的优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影等,并能发现用户潜在的兴趣点。协同过滤推荐算法主要是利用用户对项目的评分数据,通过相似邻居查询,找出与当前用户兴趣最相似的用户群,根据这些用户的兴趣偏好为当前用户提供最可能感兴趣的项目推荐列表。为更进一步地说明协同过滤推荐算法的推荐原理,本文以用户对电影的推荐为例进行阐述。表1 是用户对电影评分数据的一个简单矩阵的例子,其中每一行代表一个用户,每一列代表一部电影,矩阵中的元素表示用户对所看电影的评分,评分值一般是从1到5 的整数,评分值越大表明用户喜欢该电影。

对表1 中的数据利用协同过滤推荐算法,系统查找到用户Alice、Bob 和Chris 具有相似的兴趣爱好,因为他们对后3 部电影的评分相同,那么系统会推荐电影Snow white 给Chris,因为与其兴趣偏好相似的用户Alice 和Bob 对该电影的评分值较高。在表2 中,对于新用户Amy,没有评分信息,根据协同过滤推荐算法,无法根据评分信息查找与其兴趣偏好相似的用户,所以系统无法为该用户推荐电影,同样对于新电影Shrek,因缺乏评分信息系统无法感知它的存在,所以也无法将其推荐出去。这就是协同过滤推荐算法所存在的新用户和新项目问题。
