ICCV2019-SSF-DAN: Separated Semantic Feature based Domain Adaptation Network for Semantic Segmentati
SSF-DAN: Separated Semantic Feature based Domain Adaptation Network for Semantic Segmentation 基于分离语义特征的域适应网络的语义分割
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.语义分割
- 2.2.领域自适应
- 3.方法
-
- 3.1. 框架概述
- 3.2.领域自适应的目标函数
- 3.3.Semantic-wise分离鉴别器
-
- 3.3.1.类级别的对抗性学习
- 3.3.2.渐进置信策略用于更可靠的伪标签
- 3.4.类级别的对抗性损失重估
- 3.5.网络结构
-
- 3.5.1.语义分割网络
- 3.5.2.鉴别器网络
- 4.实验
-
- 4.1.数据集和实验设置
-
- 4.1.1.数据集
- 4.1.2.实验设置
- 4.2.实现细节
- 4.3.和先进方法的比较
- 4.4.消融实验
-
- 4.4.1.SS-D的有效性
- 4.4.2.CA-R模块的有效性
- 5.总结
- 参考文献
论文地址
代码地址
0.摘要
尽管有监督的完全卷积模型在语义分割方面取得了巨大的成功,但训练模型需要大量的劳动密集型工作来生成像素级注释。最近的研究利用合成数据训练模型进行语义分割,但是真实图像和合成图像之间的域适应仍然是一个具有挑战性的问题。本文提出了一种基于分离语义特征的领域适应网络SSF-DAN,用于语义分割。首先,设计了一个语义可分离鉴别器(SS-D)来独立适应跨目标域和源域的语义特征,解决了类级对抗学习中适应不一致的问题。在SS-D中,为了实现更可靠的分离,引入了渐进置信策略。然后,引入一个有效的类级别上的对抗损失重加权模块(CA-R)来平衡类级别上的对抗学习过程,使生成器更多地关注适应性差的类。该框架展示了健壮的性能,优于基准数据集上的最先进的方法。
1.概述
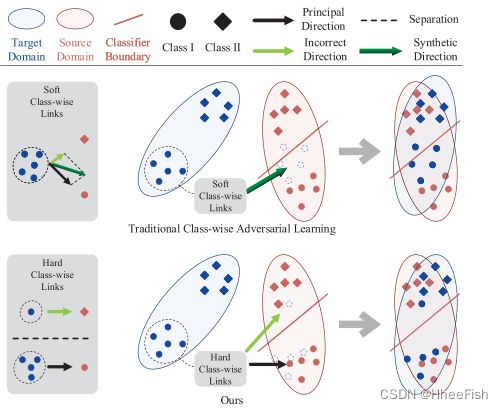
图1:传统的类级对抗性学习方法[6]和我们的。传统的类智适应考虑了特征的所有可能的类智适应方向。对于无监督学习,通常这些方向中的一些是不正确的。因此,这些不正确的方向将影响整个类明智的适应方向。在我们的方法中,对于每个特征,我们将在其各自的预测领域中所占比例最高的类作为主要的适应方向,分离特征进行独立的适应操作。它防止了主自适应受到错误自适应的影响,保持了自适应特征之间清晰的分类器边界。
由于语义分割在自动驾驶[10,40]和医学图像处理[29]方面的潜在应用,它已经得到了广泛的研究。大量基于卷积神经网络的研究[3,4,20 - 22,41,44,45]已经被引入来解决像素级标注图像的问题。然而,为语义分割任务构建大规模的逐像素标记数据集需要大量的人力劳动和足够的专业知识。因此,探索获取特定于语义分段的数据的经济方法很有吸引力,即使用合成数据[11,28],通过这种方法可以以较低的成本自动生成像素级注释。然而,合成数据与真实数据仍然存在很大的领域差异,这导致在将模型应用于真实场景时性能显著下降。针对这一问题,领域适应技术被提出,以缩小目标域和源域之间的差距。先前关于领域适应技术的研究[18,42]试图最小化源和目标特征分布之间的差异,或通过对抗学习明确强制两个数据分布彼此接近。对于图像级分类任务,基于生成式对抗网络,特征在源和目标域之间对齐[9,23],这样自适应特征能够在两个域中泛化。然而,对于语义分割等像素级分类任务,网络需要为不同的语义对象提取和编码各种视觉特征。如[19]中所提到的,对所有区域进行保真度验证的全图像鉴别器容易使原始图像中所有像素的颜色/纹理陷入单调的模式,这将严重阻碍后续视觉感知任务的执行。我们还认为,在对抗性学习中,为了考虑语义的一致性,每个类的特征分布应该不同。[6]引入了一个联合的全局和类的对抗学习框架,但结果受到不一致适应的影响,如图1所示,这将在3.3节进一步解释。基于输出空间的对抗学习由[34]提出并取得了巨大的成功。然而,它并没有充分利用高维特征
在本文中,我们引入一种无监督域适应网络,通过类的对抗学习进行语义分割。我们引入SS-D以一种独立的语义方式评估特征对齐质量,以在不引起不一致适应的情况下弥合每个类的领域差距。分割模型和我们的SS-D以端到端方式联合训练,不利用目标领域数据的先验知识。SS-D在测试阶段直接丢弃。
我们的主要贡献可概括如下:
- 我们提出了一个新颖的端到端语义分割框架,该框架通过独立的分类对抗学习实现,不需要任何全局特征对齐。
- 我们提出了一种智能语义可分离鉴别器(SS-D),以独立适应分离的语义特征从目标领域到源领域的渐进置信策略,以解决类别级别的对抗学习中关键的不一致适应问题。
- 我们提出了一个类别级别对抗性损失重加权模块(CA-R),以加强生成器对弱适应类的关注。
- 我们的框架在基准数据集上实现了最新的性能。
2.相关工作
2.1.语义分割
近年来,随着全卷积网络(FCNs)的发展,语义分割越来越受到学术界和工业界的关注。利用FCN进行像素级分类是Long等人[22]首先提出的。后来探索了许多方法来改进这一模式。在[2,41]中使用了扩张卷积来扩大神经网络的感受野。最近[44]中提出了一个金字塔池模块,用于对全局和局部上下文进行编码。但是,这些前沿方法依赖于大量的像素级注释数据。基于渲染的合成数据集(例如,GTA5[28]和Synthia[30])被构建来缓解注释问题,因为它们的像素级标签可以通过部分自动化的过程生成。然而,由于数据分布中的[26]存在差异,因此不能直接使用合成数据集训练模型以适应实际应用程序。因此,领域适应技术正在被开发。
2.2.领域自适应
对于图像分类等视觉任务,领域自适应方法已被提出,以缩小源数据和目标数据之间的领域差距。通过对源图像与目标图像的特征分布进行对齐[5、8、9、16、23-25、31、32、35、36、38、47],可以提高模型的泛化能力。domain对抗性神经网络(DANN)是由Ganin等人[8,9]首先引入来传递特征分布。对于像素级分类,[15]是第一个以完全卷积的方式应用对抗学习进行特征适应的算法。[37]基于像素预测的熵损失,解决了语义分割中的无监督域适应问题。另一种解决领域自适应问题的方法是应用样式转换技术将带注释的源领域图像格式化为目标领域图像。[19]引入了一个语义感知的Grad-GAN,为合成图像中的不同语义区域转移个性化样式,以基于ground truth语义标签近似真实世界的分布。[27]基于风格传输网络Cycle-GAN[46],阐述了一个循环一致的适应框架,将循环一致损失与对抗损失相结合,最小化特征级和像素级域间隙。其他方法[6,15]则侧重于采用类wise对抗性学习,将合成图像与真实图像或跨城市图像相适应。[6]提出了一个全球性的、分类明智的对抗性学习框架,以适应不同城市的道路场景分割。自我训练[1,48]是对许多视觉任务进行领域适应的另一种方法[33,49]。[49]在语义分割中引入了基于cnn的领域适应自训练框架,将特征空间对齐和任务本身在单一的、统一的损失下统一在一起。
3.方法
3.1. 框架概述

图2:SSF-DAN的概述。源域和目标域中的图像被随机选择并通过生成器得到输出预测。对于源预测,分割损失是基于源地真值计算的。我们根据下采样伪标签从最后一个特征中分离出语义特征,并将它们传递到我们的SS-D中特定的卷积层。然后SS-D区分类级特征是来自源域还是目标域。对抗性损失是在目标预测上计算的,并反向传播到分割器。应用CA-R模块对基于目标预测的分类对抗损失进行加权。渐进置信策略用于更可靠的伪标签。Φ和⊕分别表示按语义的分离和按通道的求和操作。
整个框架如图2所示。我们的SSFDAN由三个主要组件组成:分割器、生成器,包括G和σ,将输入图像转换为高级特征空间,并将特征空间映射到输出标签空间;独立类对齐的SS-D(鉴别器)D;以及用于重估类级对抗损失的CA-R模块
来自源域的图像Is首先通过其注释y传递给分割网络,以优化生成器。然后,网络预测来自目标域的图像It的语义分割输出Pt。我们使用渐进置信度策略过滤伪标签Pt中的低置信度像素,详见3.3节。然后,通过下采样独热输出(根据模式)将语义特征与最后一个特征分离。随后,我们将这些特征块转发到鉴别器对应的卷积层,以区分输入的类特征是来自源域还是目标域。目标预测的对抗性损失使网络从D传播到G,并迫使G生成与源域相似的特征分布。注意,SS-D相关卷积层的特征块在语义上进行了明智的分离,以保证独立自适应,这在3.3节中有进一步解释。最后,CA-R模块根据Pt计算分类权重映射Rt和Rs,并对分类对抗损失重新加权,具体见第3.4节。
3.2.领域自适应的目标函数
为了缩小源数据和目标数据之间的域差距,完成分割任务,目标函数定义如下:

其中Lseg是分割在源域的交叉熵损失;Ladv是对抗损失,它使源和目标域之间的差距最小化;δ为Lseg和Ladv的平衡权重。
3.3.Semantic-wise分离鉴别器
尽管[6]中提出了执行类适应的想法,但我们认为这种类对齐是不一致的,因为它们的多个类鉴别器在最后一个特征中的响应区域方面并不独立,这严重限制了类对抗性学习的潜在能力。
[6]引入了“soft”类级权重映射Wcsoft,并将其中的每个网格作为实例。C表示类。网格是根据输出预测标签上相应字段中所有像素的类比例计算的。将Wcsoft乘到每个鉴别器的输出,计算类级对抗损失。每个鉴别器根据其相关Wcsoft中所有非零像素的接受域,分别关注整个特征的不同语义区域。不同鉴别器的这些区域通常存在重叠。
对于从一个类对象中提取的特征,这些重叠是由错误的非零预测造成的。因此,这些特征可能会对多个鉴别器做出反应,并被不一致地适应。具体来说,生成器中与真实对象类k相关的权重梯度定义如下:

其中wγ(k)G是响应于生成器中第k类的权值集合,γ(k)表示与第k类相关的集合。Li是第i类鉴别器的损失。C表示所有类。对于独立类自适应,∇wγ(k)G应等于(2)的第一部分,而[6]中Wcsoft引入的第二部分为噪声项,会导致自适应不一致。对于一些从多个类对象的边界区域提取的特征,Wcsoft将强制生成器适应不同的特征空间。然而,生成器很难同时将这些特征适应于对应的多个特征空间,这也可能导致不一致的适应或破坏已有的对齐。
在监督学习中,较好的方法是利用“soft”标签,它能获得更多的信息来训练模型。然而,对于无监督域自适应,信息的可靠性不能得到保证。即使某些信息足够可靠,生成器仍然缺乏同时处理多个鉴别器的对抗能力。因此,无监督类智对抗学习的关键是使类级别的适应过程独立,防止其受到模糊信息的影响。
与目前最先进的类自适应方法[6,15]相比,我们的改进如下:(a)我们根据下采样伪标签将不同的语义特征从整个特征空间中分离出来,使类自适应独立。如图1所示,大多数特性将适应于它们的主要类级特征空间,而不会受到不正确信息的影响。(b)逐步信任战略也将减少适应过程中不正确的适应。注意,我们的方法假设预测概率较高的目标样本具有较好的预测精度[49]。
3.3.1.类级别的对抗性学习
图2展示了提议的SS-D的示意图。(1)定义的分割交叉熵损失公式为:
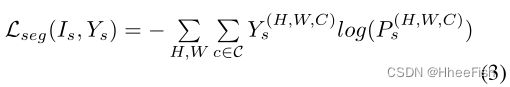
其中Ys为源域图像的ground truth注解;Ps= σ(Fs) = σ(G(Is))为分割输出;F是最后一个feature map;而σ则是包含了卷积运算、上采样运算和softmax运算的解码器。将源域图像转发并计算分割损失后,将目标主图像转发给G,预测得到Pt = σ(Ft) = σ(G(It))。我们将Mt和Ms表示为Pt和Ps的最终独热输出,并通过类通道将类掩码Mct和Mcs与Mt和Ms分开。P, Y, M∈R^H×W ×C^, F∈Rh×w×n,其中n表示特征通道。将Ft按通道乘上下采样的Mct,得到语义特征块Fct。换句话说,对于每个语义特征块,我们保留感兴趣区域的值,并将其他区域设为零。然后,每个特征块被转发到SS-D的相关卷积层。最后,将所有类输出求和为一个单通道输出,将输出与一个全零张量进行比较,计算式(1)中的Ladv,其定义如下:

其中Dc为SS-D中c类的具体卷积运算。通过最大化目标预测作为源预测的概率来优化这种对抗损失,以欺骗鉴别器。
在生成过程结束后,生成器的参数被冻结。对于源类和目标类,我们使用交叉熵损失Ld将Fct和Fcs转发给我们的SS-D。损失函数定义如下:
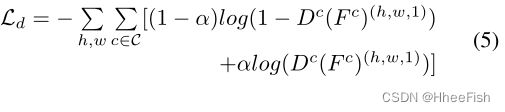
其中,如果样本来自源域,α=0;如果样本来自目标域,α=1。我们优化以下最小-最大准则:

我们的框架的目标是最小化源图像的分割损失,同时最大化目标预测被认为是源图像的概率。
3.3.2.渐进置信策略用于更可靠的伪标签
在训练开始时,每个类别的伪标签的置信度较低,对训练来说不够可靠。随着训练的进行,置信度逐渐增加,可以使用标签中更可靠的像素点。为了在整个训练过程中保持伪标签的可靠性,我们设置了一个超参数ρ来控制伪标签中保留像素的比例。将M按元素乘P,将结果按类通道分开,得到类置信图Ac。在每个Ac中,所有置信值按降序排列。这样,我们就可以根据ρ滤波出每一类中不可靠的低置信度的预测像元。ρ在训练过程中从低到高逐渐变化:
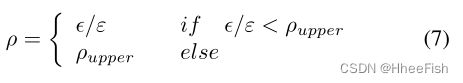
其中ε是迭代的总步骤,€是当前步骤。ρupper是保留标签比例的上界。实验表明ρupper = 0.8的性能最好。不同的ρupper的比较如图4所示。更可靠的依类分布的置信图Ac∗和掩模Mc∗如下所示:

其中,µ(·,ρ)是利用当前ρ的渐进策略过滤低置信像素的操作。被滤过的像素的损失被Mc∗移除。
3.4.类级别的对抗性损失重估
鉴别器各卷积层的参数是独立更新的,而发生器的参数是独立更新的。虽然我们的类级自适应方法提高了鉴别器的能力,但生成器很难欺骗更好的鉴别器。由于我们假设预测概率较高的目标样本具有较好的预测精度,因此预测概率较高的类具有较好的适应性和预测能力。为了使生成器聚焦于适应性差的类来平衡类级对抗学习过程,我们提出了基于Act的CA-R模块来自适应地重估对抗学习损失。按类重权值τct定义如下:

Nc是Ac*t的非零像素数,i是这些像素的索引。首先,我们使用τct替换相关类掩模Mc∗t和Mc∗s。然后,我们将结果合并到一个通道中,向下采样,匹配鉴别器的输出大小,得到重权映射Rt和Rs,如图2所示。Rt和Rs分别作为目标域和源域的对抗损失权重。我们的CA-R降低了平均置信度较高的类的损失权重,因此生成器将更多地关注适应性差的类
3.5.网络结构
3.5.1.语义分割网络
受[34]启发,我们采用DeepLab-v2[3]框架,并在ImageNet[7]上预训练ResNet-101[13]模型作为我们的分割基线网络。与[3,41]类似,去掉最后一层分类,将最后两层卷积的步长由2修改为1,使得输出特征的分辨率映射为输入图像尺寸的八分之一。在conv4层和conv5层中分别以步幅为2和4的[41]扩展卷积层来扩大接收场。最后一层后,使用atrous空间金字塔池(ASPP)[3]作为最终分类器。最后,在softmax输出的同时应用上采样层来匹配输入图像的大小。
3.5.2.鉴别器网络
我们的SS-D使用FCN架构。每个分层卷积模块由5个卷积层组成。内核大小为1、3、3、3、3,通道数为2048、1024、512、256、128、1。除最后一层外,每个卷积层后面都有一个参数为0.2的LeakyReLU[12]。
4.实验
4.1.数据集和实验设置
4.1.1.数据集
我们的分割网络是基于两个源数据集,即GTA5和Synthia进行训练,而模型则是基于目标数据集cityscape进行评估。还在Cross-City数据集[6]上执行了实验。我们在一个有监督的城市(Cityscapes)上训练模型,在另一个没有监督的城市中应用模型
Cityscapes是一个真实世界的数据集,包含50个不同城市的街景,总共有5000个像素级注释图像。数据集分为2993幅图像的训练集、503幅图像的验证集、1531幅图像的测试集以及20021幅辅助图像。数据集中包含34个不同的类别
GTA5是从一款电脑游戏(侠盗猎车手V)中渲染出来的:它包含24966张高分辨率图像,自动划分为19个类别。这些注释与城市景观的注释完全兼容;因此,我们的实验中使用了所有的19个官方训练类别。
Synthia是一个自动生成的用于城市场景语义分割的大型合成数据集。如[10,15],我们使用Synthia-Rand-Cityscapes,它是一个子集,包含9400张与Cityscapes配对的图像,共享12个公共类、一个空白类和一些未命名类。合成图像与城市景观所覆盖的任何真实城市都不相对应。
NTHU是一个真实的数据集,城市之间的领域差距很小。数据集包含4个不同的城市,每个城市共有13个类的城市景观有100对图片标注,3200张图片没有标注。在[6]之后,我们使用Cityscapes训练集作为源域,并使用3200张无注释的图像将模型应用于Cross-City中的每个目标城市。另外100个带注释的图像被用于评估。
4.1.2.实验设置
遵循[34],我们使用cityscape验证集作为测试集。从训练集中随机选取500张验证图像来监测网络的收敛性。在训练过程中,我们从源图像及其标签和目标图像中随机抽取小批样本。
4.2.实现细节
为了与其他方法进行公平的比较,除了ResNet-101,我们使用FCN8s-VGG16作为我们的基础网络在GTA V的Cityscapes和Synthia的Cityscapes。在跨城市设置中,使用ResNet-101作为基础网络,以显示最先进的性能。我们的网络是使用PyTorch框架实现的,并在具有16gb内存的P100 GPU上进行了测试。对于语义分割网络,我们使用带有Nesterov加速的随机梯度下降(SGD)优化器。动量为0.9,重量衰减为1e-4。初始学习率设置为2.5 × 1e-4,并使用[3]中提到的幂次为0.9的多项式衰减来降低初始学习率。对于我们的SS-D,我们使用学习速率为1e-4的Adam优化器和相同的多项式衰减作为分割网络。动量设定为0.9。(1)中的δ设置为0.001的GTA5, Synthia,和0.0005的Cross-City。
4.3.和先进方法的比较

表1:将《GTA5》融入城市景观的结果。我们将我们的结果与基于VGG-16和DeepLab-V2模型的最先进的方法进行了比较。每个方法(只有源代码)的第一行表示没有经过调整的模型。

表2:Synthia适应城市景观的结果
表1和表2分别给出了在格前5位的城市景观和在格前0位的Synthia城市景观设置上用最先进的领域适应方法进行语义分割的比较。我们的方法在几乎所有类的性能都优于最先进的对抗式学习方法,如表1和表2所示。与最先进的自训练方法[49]相比,虽然我们在一些小对象类上稍弱一些,但“SSF-DAN”具有更好的整体性能。对于那些难以区分的区域(如天空和建筑物),“SSF-DAN”的表现明显优于其他方法。如表3所示,对于跨真实世界城市的小领域适应,我们的方法也优于最先进的方法。
4.4.消融实验

图3:gta5对城市景观的细分示例结果。对于每一幅Cityscapes图像,我们展示了适应前的结果,基于[6]中使用的方法(软类级+全局)的结果,基于我们的SS-D和我们的完整方法(SS-D + CA-R)的结果。
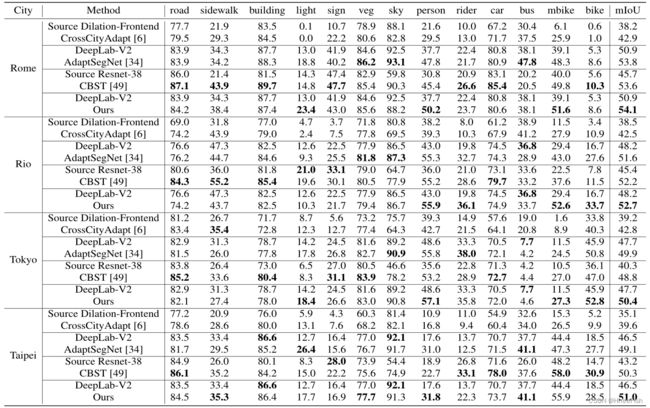
表3:城市景观适应跨城市数据集的结果。我们在[34]中应用DeepLab-V2架构,并比较各种最先进方法的结果。每一种方法的第一行表示不经过调整的模型。
我们研究了我们的方法中不同模块的有效性。我们在五号地块上进行消融实验。我们还利用cityscape数据集中带注释的地面事实来训练模型作为oracle结果,以测量完全监督模型与适应模型之间的差距缩小了多少。
4.4.1.SS-D的有效性
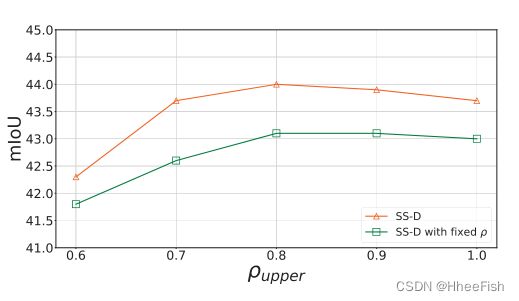
图4:在我们的SS-D中使用不同的ρupper的比较。GTA5适应城市景观的结果。
为了验证我们的类级适应的改进,我们将与最先进的类级适应方法[6]进行比较。不同设置下的实验结果如表4所示。第一行显示没有适应的结果。第二至第四行显示了仅使用全局特征对齐、基于类对齐的“软”权重映射以及[6]中使用的这两种方法的结果。我们的SS-D†(无渐进置信策略的SS-D)比“软”类对齐(具有全球)的表现要好6.5%,这表明在无监督类对齐中,考虑到所有可能的类,独立适应比适应重要得多。为了评估全球特征适应对我们类级适应的影响,我们进一步将全球对齐添加到我们的SS-D†中。由于引入了不一致的适应,结果受全局比对的影响较小。渐进式信心策略使我们的SS-D mIoU上涨2.8%。请注意,我们在渐进策略中设置ρupper = 0.8。我们还进行了在整个适应过程中固定ρ = ρupper的实验,以进一步验证我们的渐进策略的影响。在不同的ρ上限设置下的实验比较如图4所示。更多的烧蚀实验在我们的补充材料中详细介绍。
4.4.2.CA-R模块的有效性
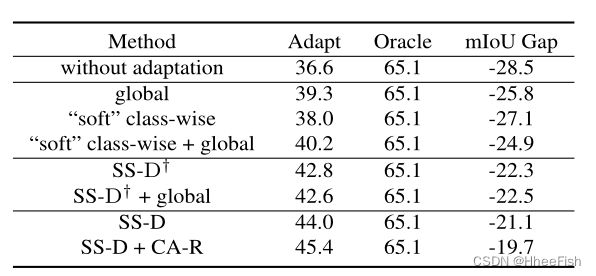
表4:不同环境下的消融研究。基于ResNet-101调整GTA5到城市景观的结果。
如表4所示,我们的CA-R模块仅在SS-D的基础上提高了3.2%,这表明这种自适应分类平衡策略可以提高语义分段任务的分类域适应的整体性能。
图3给出了自适应分割的一些示例结果。当我们使用SS-D而不是“软”类对齐(具有全局)方法时,可以观察到实质性的改进。我们可以看到,由于我们的先进方法,每个类区域都是干净和准确的。CA- R模块进一步提高了通常适应较弱的类(例如,符号和光线)的准确性,这是由于类级适应过程的平衡。
最后,如图3所示,我们的模型在区分高密度和微小对象方面的能力仍然有限。这个问题值得考虑,留给以后的工作。
5.总结
在本文中,我们通过独立的分类对抗学习来解决语义分割的领域适应问题。我们研究了一个SS-D来解决不一致适应的关键问题,并提出了一个CA-R模块来平衡类智对抗学习过程。实验结果表明,我们的方法比最新技术的性能要好得多。对于一些物体密集且较小的场景,我们的模型的识别能力是有限的。在未来的工作中,我们计划研究这个问题,并将我们的方法扩展到更多的应用中。
参考文献
[1] Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning (chapelle, o. et al., eds.; 2006)
[book reviews]. IEEE Transactions on Neural Networks, 20(3):542–542, 2009.
[2] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Y uille. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv preprint arXiv:1412.7062, 2014.
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Y uille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2018.
[4] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017.
[5] Y uhua Chen, Wen Li, and Luc V an Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7892–7901, 2018.
[6] Yi-Hsin Chen, Wei-Y u Chen, Y u-Ting Chen, Bo-Cheng Tsai, Y u-Chiang Frank Wang, and Min Sun. No more discrimination: Cross city adaptation of road scene segmenters. In Proceedings of the IEEE International Conference on Computer Vision, pages 1992–2001, 2017.
[7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. 2009.
[8] Y aroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. arXiv preprint arXiv:1409.7495, 2014.
[9] Y aroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. The Journal of Machine Learning Research, 17(1):2096–2030, 2016.
[10] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361. IEEE, 2012.
[11] Ankur Handa, Viorica Patraucean, Vijay Badrinarayanan, Simon Stent, and Roberto Cipolla. Understanding real world indoor scenes with synthetic data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4077–4085, 2016.
[12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015.
[13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[14] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Y an Zhu, Phillip Isola, Kate Saenko, Alexei A Efros, and Trevor Darrell. Cycada: Cycle-consistent adversarial domain adaptation. arXiv preprint arXiv:1711.03213, 2017.
[15] Judy Hoffman, Dequan Wang, Fisher Y u, and Trevor Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016.
[16] Weixiang Hong, Zhenzhen Wang, Ming Y ang, and Junsong Y uan. Conditional generative adversarial network for structured domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1335–1344, 2018.
[17] Gao Huang, Zhuang Liu, Laurens V an Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
[18] Trung Le, Khanh Nguyen, and Dinh Phung. Theoretical perspective of deep domain adaptation. arXiv preprint arXiv:1811.06199, 2018.
[19] Peilun Li, Xiaodan Liang, Daoyuan Jia, and Eric P Xing. Semantic-aware grad-gan for virtual-to-real urban scene adaption. arXiv preprint arXiv:1801.01726, 2018.
[20] Guosheng Lin, Chunhua Shen, Anton V an Den Hengel, and Ian Reid. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3194–3203, 2016.
[21] Ziwei Liu, Xiaoxiao Li, Ping Luo, Chen-Change Loy, and Xiaoou Tang. Semantic image segmentation via deep parsing network. In Proceedings of the IEEE international conference on computer vision, pages 1377–1385, 2015.
[22] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015.
[23] Mingsheng Long, Y ue Cao, Jianmin Wang, and Michael I Jordan. Learning transferable features with deep adaptation networks. arXiv preprint arXiv:1502.02791, 2015.
[24] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Unsupervised domain adaptation with residual transfer networks. In Advances in Neural Information Processing Systems, pages 136–144, 2016.
[25] Y awei Luo, Liang Zheng, Tao Guan, Junqing Y u, and Yi Y ang. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2507–2516, 2019.
[26] Yishay Mansour, Mehryar Mohri, and Afshin Rostamizadeh. Domain adaptation: Learning bounds and algorithms. 2009.
[27] Batch Normalization. Accelerating deep network training by reducing internal covariate shift. CoRR.–2015.–V ol. abs/1502.03167.–URL: http://arxiv. org/abs/1502.03167, 2015.
[28] Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In European Conference on Computer Vision, pages 102–118. Springer, 2016.
[29] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
[30] German Ros, Laura Sellart, Joanna Materzynska, David V azquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3234–3243, 2016.
[31] Swami Sankaranarayanan, Y ogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3752–3761, 2018.
[32] Kihyuk Sohn, Sifei Liu, Guangyu Zhong, Xiang Y u, MingHsuan Y ang, and Manmohan Chandraker. Unsupervised domain adaptation for face recognition in unlabeled videos. In Proceedings of the IEEE International Conference on Computer Vision, pages 3210–3218, 2017.
[33] Kevin Tang, Vignesh Ramanathan, Li Fei-Fei, and Daphne Koller. Shifting weights: Adapting object detectors from image to video. In Advances in Neural Information Processing Systems, pages 638–646, 2012.
[34] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Y ang, and Manmohan Chandraker. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7472–7481, 2018.
[35] Eric Tzeng, Judy Hoffman, Trevor Darrell, and Kate Saenko. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, pages 4068–4076, 2015.
[36] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7167–7176, 2017.
[37] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Pérez. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2517–2526, 2019.
[38] Zuxuan Wu, Xintong Han, Y en-Liang Lin, Mustafa Gokhan Uzunbas, Tom Goldstein, Ser Nam Lim, and Larry S Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 518– 534, 2018.
[39] Zifeng Wu, Chunhua Shen, and Anton V an Den Hengel. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognition, 90:119–133, 2019.
[40] Guorun Y ang, Hengshuang Zhao, Jianping Shi, Zhidong Deng, and Jiaya Jia. Segstereo: Exploiting semantic information for disparity estimation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 636– 651, 2018.
[41] Fisher Y u and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015.
[42] Jing Zhang, Wanqing Li, and Philip Ogunbona. Transfer learning for cross-dataset recognition: a survey. arXiv preprint arXiv:1705.04396, 2017.
[43] Y ang Zhang, Philip David, and Boqing Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE International Conference on Computer Vision, pages 2020–2030, 2017.
[44] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017.
[45] Shuai Zheng, Sadeep Jayasumana, Bernardino RomeraParedes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, and Philip HS Torr. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE international conference on computer vision, pages 1529–1537, 2015.
[46] Jun-Y an Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 2223– 2232, 2017.
[47] Xinge Zhu, Hui Zhou, Ceyuan Y ang, Jianping Shi, and Dahua Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 568– 583, 2018.
[48] Xiaojin Jerry Zhu. Semi-supervised learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences, 2005.
[49] Y ang Zou, Zhiding Y u, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), pages 289–305, 2018.