ABCNet文本识别
代码链接:https://github.com/aim-uofa/AdelaiDet
**
Abstract 摘要
场景文本检测与识别越来越受到研究者的关注。现有的方法大致可以分为两类:基于字符的方法和基于分割的方法。这些方法要么用于字符注释,要么需要维护复杂的管道,这通常不适合实时应用。在这里,我们通过提出自适应Bezier曲线网络(ABCNet)来解决这个问题。我们的贡献有三个方面:
1) 我们首次通过参数化的Bezier曲线自适应地拟合任意形状的文本。
2) 我们设计了一个新的BezierAlign层来精确提取任意形状文本实例的卷积特征,与以往的方法相比,显著提高了精度。
3) 与标准的边界盒检测方法相比,我们的Bezier曲线检测方法的计算开销可以忽略不计,从而使我们的方法在效率和精度上都具有优势。在任意形状的基准数据集Total Text和CTW1500上的实验表明,ABCNet达到了最先进的精度,同时显著提高了速度。特别是在总文本上,我们的实时版本比最新的最新方法快10倍以上,并且具有竞争性的识别精度。代码可在AdelaiDet包中找到。
1.介绍
**
场景文本检测与识别由于其在计算机视觉中的广泛应用而受到越来越多的关注。尽管最近取得了巨大的进展[10,41,27,35,26,42],但由于文本在大小、纵横比、字体样式、透视失真和形状等方面的多样性,在野外检测和识别文本仍然是一个悬而未决的问题。虽然深度学习的出现大大提高了场景文本识别任务的性能,但是目前的方法在实际应用中仍然存在着相当大的差距,尤其是在效率方面。
最近,许多端到端的方法[30、36、33、23、43、20]都显著提高了任意形状场景文本定位的性能。然而,这些方法要么使用基于分段的方法来维护复杂的管道,要么需要大量昂贵的字符级注释。除此之外,这些应用程序的部署速度几乎都很慢—此外,这些方法的部署速度也很慢。因此,我们的动机是设计一个简单而有效的端到端框架,用于在图像中定位定向或弯曲的场景文本[5,26],这确保了快速的推理时间,同时实现了与最先进方法不相上下甚至更好的性能。
为了实现这一目标,我们提出了自适应贝塞尔曲线网络(ABCNet),一个端到端可训练的框架,用于任意形状的场景文本定位。ABCNet通过简单而有效的Bezier曲线自适应实现任意形状的场景文本检测,与标准的矩形边界框检测相比,可以忽略不计的计算开销。此外,我们设计了一个高级的特征对齐层BezierAlign来精确计算曲线形状文本实例的卷积特征,从而在几乎可以忽略的计算开销下获得较高的识别精度。第一次 同时,我们用参数化的Bezier曲线来表示有向文本或曲线文本,结果表明了该方法的有效性。图1显示了我们发现结果的示例。
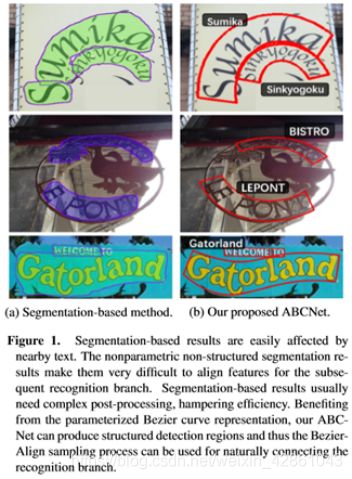
图1。基于分割的结果很容易受到邻近文本的影响。非参数的非结构化分割结果使得后续的识别分支很难对特征进行对齐。基于分割的结果通常需要复杂的后处理,影响了效率。利用参数化的Bezier曲线表示,我们的ABCNet可以产生结构化的检测区域,从而可以使用Bezier对齐采样过程来自然连接识别分支。
注意,以前的方法如TextAlign[11]和FOTS[24]可以看作是ABCNet的一个特例,因为四边形边界框可以看作是最简单的具有4条直线边界的任意形状的边界框。此外,ABCNet还可以避免2D-attention等复杂的变换[19],使得识别分支的设计大大简化。
我们的主要贡献总结如下。
•为了精确定位图像中的定向和弯曲场景文本,我们首次引入了一种新的使用贝塞尔曲线的弯曲场景文本的简明参数化表示。与标准的边界框表示相比,它引入了可忽略的计算开销。 •我们提出了一种采样方法,即a.k.a.Bezier对齐,用于精确的特征对齐,因此识别分支可以自然地连接到整个结构。通过共享主干特征,识别分支可以设计成轻量级结构。 •我们方法的简单性允许它实时进行推理。ABCNet在Total Text和CTW1500这两个具有挑战性的数据集上实现了最先进的性能,展示了在效率和效率方面的优势。
1.1相关工作
场景文本识别需要同时检测和识别文本,而不是只涉及一个任务。近年来,基于深度学习的方法的出现极大地提高了文本识别的性能。检测和识别的性能都有了很大的提高。我们将几种典型的基于深度学习的场景文本识别方法归纳为以下两类。图2显示了典型工程的概述。
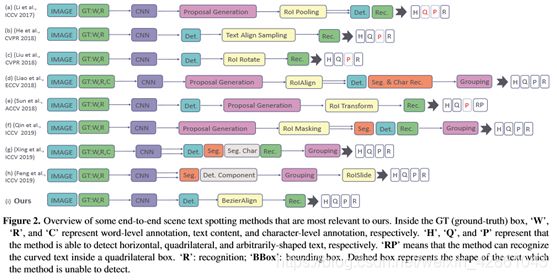
图2。一些与我们最相关的端到端场景文本定位方法的概述。在GT(基本真相)框中,“W”、“R”和“C”分别表示单词级注释、文本内容和字符级注释。“H”、“Q”和“P”表示该方法能够分别检测水平、四边形和任意形状的文本。“RP”表示该方法可以识别四边形方框内的曲线文本。“R”:识别;“BBox”:边界框。虚线框表示方法无法检测的文本形状。
常规的端到端场景文本识别。[18] 提出了第一种基于深度学习的端到端可训练场景文本定位方法。该方法成功地使用RoI池[34]通过两阶段框架来联合检测和识别特征,但它只能识别水平和聚焦文本。它的改进版本[19]显著提高了性能,但速度有限。他等。[11] 刘等。[24]采用无锚机制,提高训练和推理速度。它们使用相似的采样策略,即文本对齐采样和RoI旋转,从四边形检测结果中提取特征。请注意,这两种方法都不能识别任意形状的场景文本。
任意形状端到端场景文本定位,检测任意形状场景文本,廖等。[30]提出了一种掩模文本识别器,它对掩模R-CNN进行了精细化,并利用字符级的监督来同时检测和识别字符和实例掩码。该方法显著提高了任意形状场景文本的检测性能。然而,在实际应用中,字符级的真实值代价昂贵,使用自由合成的数据很难为真实数据生成字符级的真实值。它的改进版本[20]显著地减轻了对字符级基本真理的依赖。该方法依赖于一个区域建议网络,这在一定程度上限制了算法的速度。Sun等人。[36]提出预先生成四边形检测边界框的文本网,然后使用区域建议网络将检测特征输入识别。虽然该方法可以从四边形检测中直接识别任意形状的文本,但其性能仍然有限。
最近,秦等。[33]建议使用RoI掩蔽来关注任意形状的文本区域。然而,结果很容易受到异常像素的影响。另外,分割分支增加了计算负担;多边形拟合过程也带来了额外的时间消耗;分组结果往往参差不齐,不平滑。文献[23]中的工作是第一个单阶段任意形状场景文本定位方法,需要字符级的地面真实数据进行训练。[43]的作者提出了一种新的抽样方法RoISlide,它使用文本实例预测片段的融合特征,并且因此,它对任意形状的长文本是健壮的。
2. Adaptive Bezier Curve Network (ABCNet)
ABCNet是一个端到端的可训练框架,用于识别任意形状的场景文本。直观的管道如图3所示。受[47,37,12]的启发,我们采用了单点无锚卷积神经网络作为检测框架。移除锚定箱可以简化我们任务的检测。该算法在检测头输出特征图上进行密集预测,检测头由4个步长为1、填充为1、3×3核的叠层卷积层构成。接下来,我们分两部分介绍拟议的ABCNet的关键组成部分:
1) 贝塞尔曲线检测
2) bezierralign和识别分支。
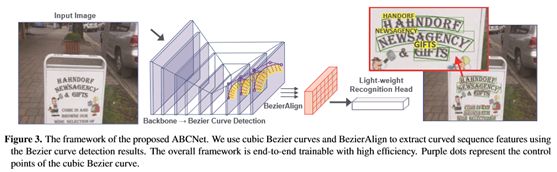
图3。拟议的ABCNet框架。我们使用三次Bezier曲线和BezierAlign来提取曲线序列特征。整个框架是端到端可培训的,效率高。紫色点表示三次贝塞尔曲线的控制点。
2.1贝塞尔曲线检测
与基于分割的方法[40,44,1,38,45,28]相比,基于回归的方法更直接地解决了任意形状的文本检测,例如[26,42]。然而,以往的基于回归的方法需要复杂的参数化预测来拟合文本边界,这在实际应用中对各种文本形状都不是很有效和鲁棒的。
为了简化任意形状场景文本的检测,采用回归方法,我们认为Bezier曲线是曲线文本参数化的理想概念。Bezier曲线表示一个参数曲线c(t),它以Bernstein多项式[29]为基础。定义如式(1)所示。

式中,n表示度数,bi表示第i个控制点,Bi,n(t)表示伯恩斯坦基多项式,如式(2)所示:

其中 ![]() 是二项式系数。为了用贝塞尔曲线确定文本的任意形状,我们从现有的数据集中全面地观察任意形状的场景文本。在现实世界中,我们通过经验证明,三次贝塞尔曲线(即n为3)在实践中对不同类型的任意形状的场景文本是足够的。三次贝塞尔曲线如图4所示。
是二项式系数。为了用贝塞尔曲线确定文本的任意形状,我们从现有的数据集中全面地观察任意形状的场景文本。在现实世界中,我们通过经验证明,三次贝塞尔曲线(即n为3)在实践中对不同类型的任意形状的场景文本是足够的。三次贝塞尔曲线如图4所示。
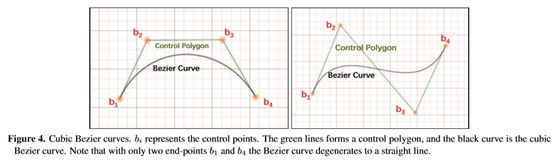
图4。三次贝塞尔曲线。b i代表控制点。绿线形成一个控制多边形,黑色曲线是三次贝塞尔曲线。注意,只有两个端点b1和b4,Bezier曲线退化为一条直线。
基于三次Bezier曲线,我们可以将任意形状的场景文本检测简化为一个共有八个控制点的边界盒回归。请注意,具有四个控制点(四个顶点)的直文本是任意形状场景文本的典型情况。为了保持一致性,我们在每个长边的三个点上加上两个控制点。
为了学习控制点的坐标,我们首先生成2.1.1中描述的Bezier曲线地面真实度,然后按照[25]中类似的回归方法对目标进行回归。对于每个文本实例,我们使用![]()
x min和y min分别表示4个顶点的最小x和y值。预测相对距离的优点是它与Bezier曲线控制点是否超出图像边界无关。在检测头内部,我们只需要一个具有16个输出通道的卷积层来学习∆x和∆y,这几乎是免费的,但结果仍然可以是准确的,这将在第3节中讨论。
2.1.1 Bezier Ground Truth Generation 贝塞尔地面真相生成
在本节中,我们将简要介绍如何基于原始注释生成贝塞尔曲线地面真值。任意形状的数据集,例如Total text[5]和CTW1500[26],对文本区域使用多边形注释。给定曲线边界上的注记点![]() ,其中pi表示第i个注记点,主要目标是获得方程(1)中三次Bezier曲线sc(t)的最佳参数。为此,我们可以简单地应用标准最小二乘法,如等式(4)所示:
,其中pi表示第i个注记点,主要目标是获得方程(1)中三次Bezier曲线sc(t)的最佳参数。为此,我们可以简单地应用标准最小二乘法,如等式(4)所示:

这里m表示曲线边界的注释点数量。对于total-text和ctw1500,m分别为5和7。t是通过使用累积长度与多段线周长的比率来计算的。根据方程(1)和方程(4),我们将原始的多段线注释转换为参数化的贝塞尔曲线。注意,我们直接使用第一个和最后一个注释点分别作为第一个(b0)和最后一个(b4)控制点。可视化比较如图5所示,其结果表明,生成的结果在视觉上甚至比原始地面真实性更好。此外,基于结构化的Bezier曲线边界框,我们可以很容易地使用第2.2节中描述的Bezier对齐将曲线文本扭曲成水平格式,而不会产生明显的变形。贝塞尔曲线生成结果的更多示例如图6所示。我们方法的简单性允许它在实践中推广到不同类型的文本。

图5。Bezier曲线生成方法比较。在图(b)中,对于每个曲线边界,红色虚线形成一个控制多边形,红色圆点表示控制点。翘曲结果如下所示。在图(a)中,我们利用TPS[2]和STN[14]将原始地面真相扭曲成矩形。在图(b)中,我们使用生成的Bezier曲线和BezierAlign来扭曲结果。

图6。贝塞尔曲线生成的示例结果。绿线是最终的贝塞尔曲线结果。红色虚线表示控制多边形,4个红色端点表示控制点。放大以获得更好的可视化效果。
2.1.2 Bezier Curve Synthetic Dataset
对于端到端的场景文本识别方法,总是需要大量的自由合成数据,如表2所示。然而,现有的800k SynText数据集[7]只为大多数直文本提供四边形边界框。为了丰富和丰富任意形状的场景文本,我们尝试用VGG合成方法合成了150k个合成数据集(94723个图像包含大部分直线文本,54327个图像包含大部分曲线文本)。特别地,我们从COCO文本[39]中过滤出40k个无文本背景图像,然后用[32]和[17]准备每个背景图像的分割遮罩和场景深度,用于以下文本渲染。为了扩大合成文本的形状多样性,我们对VGG合成方法进行了改进,将场景文本与各种艺术字体和语料库合成,并对所有文本实例生成多边形标注。然后使用注释通过第2.1.1节中描述的生成方法生成贝塞尔曲线地面真值。综合数据的示例如图8所示。

表2:总文本的场景文本定位结果。这里表示根据原始论文或提供的代码粗略推断出的结果。当输入图像的短尺寸为600时,ABCNet-F速度更快。多尺度测试。数据集:AddF2k[46];IC13[16];IC15[15];TT[4];MLT[31];COCO文本[39]。*

图8。三次Bezier曲线合成数据实例。
2.2. BezierAlign
为了实现端到端的训练,以往的方法大多采用各种采样(特征对齐)方法来连接识别分支。通常,采样方法表示网络区域内的裁剪过程。也就是说,在给定特征图和感兴趣区域(RoI)的情况下,利用采样方法选择感兴趣区域的特征,并有效地输出一个特征图固定尺寸。
然而,以往基于非分割的方法的采样方法,如RoI池[18]、RoI Rotate[24]、Text Align sampling[11]或RoI Transform[36]无法正确对齐任意形状文本的特征(roislaid[43]多个预测片段)。利用紧凑型Bezier曲线边界盒的参数化特性,提出了一种用于特征采样的Bezier-align方法。BezierAlign是从RoAlign[8]扩展而来的。与roAlign不同,BezierAlign的采样网格形状不是矩形。相反,任意形状网格的每一列都与文本的Bezier曲线边界正交。采样点的宽度和高度分别为等距间隔,并对坐标进行双线性插值。
形式化地给出输入特征映射和Bezier曲线控制点,同时处理hout×wout大小的矩形输出特征映射的所有输出像素。以具有位置(giw,gih)的像素gi(来自输出的特征图)为例,通过公式(5)计算t:
![]()
然后用t和方程(1)计算上Bezier曲线的边界点tp和下Bezier曲线的边界点bp。利用tp和bp,我们可以通过方程(6)对采样点op进行线性索引:

利用op的位置,我们可以很容易地应用双线性插值来计算结果。以前的采样方法和Bezier Align之间的比较如图7所示。

图7。比较以前的采样方法和BezierAlign。提出的BezierAlign算法能够准确地提取文本区域的特征,这对于识别训练至关重要。注意,对齐过程是在中间卷积特征中处理的。
认可处。受益于共享主干功能和BezierAlign,我们设计了一个轻量级的识别分支,如表1所示,以便更快地执行。它由6个卷积层、1个双向LSTM[13]层和1个全连通层组成。基于输出分类分数,我们使用经典的CTC Loss[6]进行文本字符串(GT)对齐。注意,在训练过程中,我们直接使用生成的Bezier曲线GT来提取RoI特征。因此,检测分支不影响识别分支。在推断阶段,RoI区域被第2.1节中描述的检测Bezier曲线代替。实验三部分的烧蚀研究表明,所提出的BezierAlign可以显著提高识别性能。

表1:识别分支的结构,它是CRNN的简化版本[35]。对于所有卷积层,填充大小限制为1。n代表批大小。c代表通道尺寸。h和w代表输出的特征图的高度和宽度,n类表示预测类的个数,本文设定为97,包括英文字符、数字、符号的大小写,一个类别代表所有其他符号,最后一个类别的“EOF”。
3.实验
我们对最近引入的两个任意形状的场景文本基准Total text[3]和CTW1500[26]进行了评估,这两个基准还包含大量的纯文本。我们还对全文进行了消融研究,以验证我们提出的方法的有效性。
3.1实施细节
实现细节这篇论文的主干遵循一个共同的设置,如大多数以前的论文,即ResNet-50[9]和一个特征金字塔网络(FPN)[22]。对于检测分支,我们在输入图像的1/8、1/16、1/32、1/64和1/128分辨率的5个特征映射上使用roiallign;对于识别分支,则在1/4、1/8和1/16大小的三个特征映射上进行BezierAlign。预训练后的数据来自公开的英语单词级数据集,包括第2.1.2节中描述的150k个合成数据,从原始COCO-Text中过滤出的15k个图像,以及7k个ICDAR-MLT数据[31]。
然后在目标数据集的训练集上对预训练模型进行微调。此外,我们还采用了数据扩充策略,如随机规模训练,短样本在560-800之间随机选择,长样本小于1333;随机裁剪,我们确保裁剪尺寸大于原尺寸的一半,并且不剪切任何文本(对于一些难以满足条件的特殊情况,我们不应用随机裁剪)。
我们使用4个特斯拉V100 gpu对我们的模型进行训练,图像批大小为32。最大迭代次数为150K,初始学习率为0.01,在第70K次迭代时为0.001,在120K次迭代时为0.0001。整个训练过程大约需要3天。
3.2Total-Text实验结果
数据集。Total-text数据集[3]是2017年提出的最重要的任意形状场景文本基准之一,它是从各种场景中采集的,包括文本类场景复杂度和低对比度背景。它包含1555张图像,其中1255张用于培训,300张用于测试。为了与现实世界中的场景相似,这个数据集的大多数图像都包含大量的常规文本,同时保证每个图像至少有一个曲线文本。文本实例采用基于词级的多边形标注。它的扩展版本[5]改进了训练集的注释,在文本识别序列之后用一个固定的十个点来注释每个文本实例。数据集只包含英文文本。为了评估端到端的结果,我们采用了与以前方法相同的度量,即使用F度量来度量单词的准确性。
消融研究:Bezierralign。为了评价所提出的成分的有效性,我们对这个数据集进行了消融研究。我们首先对取样点的数量如何影响端到端结果进行敏感性分析,如表4所示。从结果中我们可以看出,采样点的数量可以显著影响最终的性能和效率。我们发现(7,32)在F-measure和FPS之间实现了最佳的权衡,这在下面的实验中用作最终设置。通过与图7所示的先前采样方法进行比较,我们进一步评估了Bezierralign。表3所示的结果表明,bezierallign可以显著改善端到端的结果。定性示例如图9所示。

表3:BezierAlign的消融研究。水平采样遵循[18],四边形采样遵循[11]。
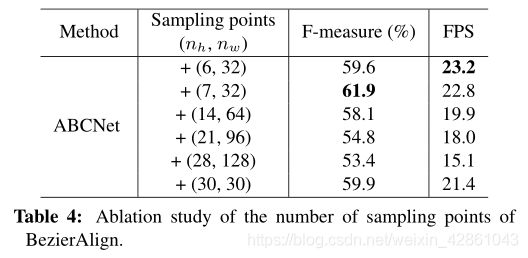
表4:bezierralign采样点数目的烧蚀研究。

图9。四边形抽样法和BezierAlign的定性识别结果。左图:原始图像。右上:结果采用四边形抽样。右下:使用BezierAlign得到的结果。
消融研究:贝塞尔曲线检测。另一个重要的组件是Bezier曲线检测,它支持任意形状的场景文本检测。因此,我们也进行了实验来评估贝塞尔曲线检测的时间消耗。表5的结果表明,与标准包围盒检测相比,贝塞尔曲线检测不会引入额外的计算。

表5:Bezier烧蚀检测时间曲线的研究。
与最新技术的比较。我们进一步比较了我们的方法和以前的方法。从表2可以看出,我们的单尺度结果(短尺度为800)可以在达到实时推理速度的同时达到竞争性的性能,从而在速度和单词准确性之间取得更好的权衡。通过多尺度推理,ABCNet达到了最先进的性能,显著优于所有以前的方法,特别是在运行时间方面。值得一提的是,我们的快速版本可以比以前的最佳方法[20]快11倍以上,精度相当。
定性结果。ABCNet的一些定性结果如图10所示。结果表明,该方法能够准确地检测和识别大部分任意形状的文本。此外,我们的方法还可以很好地处理直文本,具有近似四边形的紧凑包围盒和正确的识别结果。图中还显示了一些错误,这些错误主要是由于错误识别其中一个字符造成的。

图10。ABCNet对全文的定性研究结果。检测结果用红色边框显示。浮点数是预测的置信度。放大以获得更好的可视化效果。
3.3 CTW1500实验结果
数据集。CTW1500[26]是2017年提出的另一个重要的任意形状场景文本基准。与Total-text相比,该数据集同时包含英文和中文文本。此外,注释是基于文本行级别的,它还包括一些文档类的文本,即大量的小文本可以堆叠在一起。CTW1500包含1k训练图像和500个测试图像。
实验。由于该数据集中的中文文本所占的比例很小,在训练过程中我们直接将所有的中文文本视为“看不见的”类,即96级。注意,最后一个类,即第97个类在我们的实现中是“EOF”。我们遵循与[43]相同的评估标准。实验结果如表6所示,这表明在端到端的场景文本识别方面,ABCNet可以显著地超过现有的技术方法。这个数据集的示例结果如图11所示。从图中,我们可以看到一些长文本行实例包含许多单词,这使得完全匹配单词的准确性极为困难。
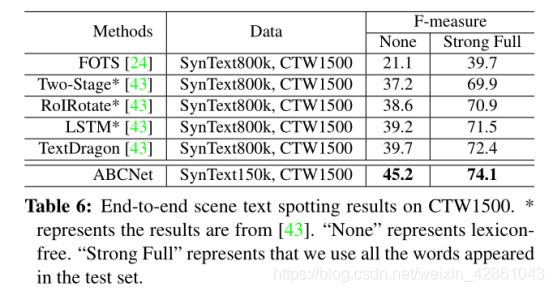
*表6:CTW1500上的端到端场景文本定位结果。表示结果来自[43]。“无”代表无词典。“Strong Full”表示我们使用测试集中出现的所有单词。

图11。CTW1500的定性端到端定位结果。放大以获得更好的可视化效果。
4.结论
我们提出了一种基于Bezier曲线的实时端到端的场景文本识别方法ABCNet。ABCNet利用参数化的Bezier曲线重新构造任意形状的场景文本,可以用Bezier曲线检测任意形状的场景文本,与标准的包围盒检测相比,计算量可以忽略不计。有了这样规则的Bezier曲线包围盒,我们自然可以通过一个新的bezierralign层连接一个轻量级的识别分支。此外,通过使用我们的Bezier曲线合成数据集和公开可用的数据,在两个任意形状的场景文本基准(Total text和CTW1500)上的实验表明,我们的ABCNet可以达到最先进的性能,这也比以前的方法快得多。
致谢
作者要感谢华为技术公司用于捐赠GPU云计算资源。
参考:
[1] Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun,
and Hwalsuk Lee. Character Region Awareness for Text De-
tection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 9365–9374, 2019.
[2] Fred L. Bookstein. Principal warps: Thin-plate splines and
the decomposition of deformations. IEEE Trans. Pattern
Anal. Mach. Intell., 11(6):567–585, 1989.
[3] C.-K Chng and C.-S Chan. Total-text: A comprehensive
dataset for scene text detection and recognition. In Proc.
IAPR Int. Conf. Document Analysis Recog., pages 935–942,
2017.
[4] Chee-Kheng Chng, Yuliang Liu, Yipeng Sun, Chun Chet Ng,
Canjie Luo, Zihan Ni, ChuanMing Fang, Shuaitao Zhang,
Junyu Han, Errui Ding, et al. ICDAR2019 Robust Read-
ing Challenge on Arbitrary-Shaped Text (RRC-ArT). Proc.
IAPR Int. Conf. Document Analysis Recog., 2019.
[5] Chee-Kheng Chng, Chee Seng Chan, and Cheng-Lin Liu.
Total-text: toward orientation robustness in scene text detec-tion. Int. J. Document Analysis Recogn., pages 1–22, 2019.
[6] Alex Graves, Santiago Fernández, Faustino Gomez, and
Jürgen Schmidhuber. Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks. In Proc. Int. Conf. Mach. Learn., pages 369–376.ACM, 2006.
[7] Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman.
Synthetic data for text localisation in natural images. InProc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 2315–2324, 2016.
[8] Kaiming He, Georgia Gkioxari, Piotr Dollr, and Ross Gir-
shick. Mask R-CNN. In Proc. IEEE Int. Conf. Comp. Vis.,
2017.
[9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 770–778, 2016.
[10] Tong He, Weilin Huang, Yu Qiao, and Jian Yao. Text-
attentionalconvolutionalneuralnetworkforscenetextdetec-tion. IEEE Trans. Image Process., 25(6):2529–2541, 2016.
[11] Tong He, Zhi Tian, Weilin Huang, Chunhua Shen, Yu Qiao,
and Changming Sun. An end-to-end textspotter with explicit
alignment and attention. In Proc. IEEE Conf. Comp. Vis.
Patt. Recogn., pages 5020–5029, 2018.
[12] Wenhao He, Xu-Yao Zhang, Fei Yin, and Cheng-Lin Liu.
Deep direct regression for multi-oriented scene text detec-tion. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
[13] Sepp Hochreiter and Jurgen Schmidhuber. Long short-term
memory. In Neural Computation, volume 9, pages 1735–1780, 1997.
[14] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al.
Spatial transformer networks. In Proc. Advances in Neural
Inf. Process. Syst., pages 2017–2025, 2015.
[15] D. Karatzas, L. Gomez-Bigorda, et al. ICDAR 2015 compe-
tition on robust reading. In Proc. IAPR Int. Conf. Document
Analysis Recog., pages 1156–1160, 2015.
[16] D. Karatzas, F. Shafait, S. Uchida, et al. ICDAR 2013 Robust Reading Competition. In Proc. IAPR Int. Conf. Document Analysis Recog., pages 1484–1493, 2013.
[17] Iro Laina, Christian Rupprecht, Vasileios Belagiannis, Fed-erico Tombari, and Nassir Navab. Deeper depth prediction with fully convolutional residual networks. In Proc. Int.Conf. 3D vision (3DV), pages 239–248. IEEE, 2016.
[18] Hui Li, Peng Wang, and Chunhua Shen. Towards end-to-end
text spotting with convolutional recurrent neural networks.InProc. IEEE Int. Conf. Comp. Vis., pages 5238–5246, 2017.
[19] Hui Li, Peng Wang, and Chunhua Shen. Towards end-to-end
text spotting in natural scenes. arXiv: Comp. Res. Reposi-tory, 2019.
[20] Minghui Liao, Pengyuan Lyu, Minghang He, Cong Yao,
Wenhao Wu, and Xiang Bai. Mask textspotter: An end-to-
end trainable neural network for spotting text with arbitrary shapes. IEEE Trans. Pattern Anal. Mach. Intell., 2019.
[21] Minghui Liao, Baoguang Shi, Xiang Bai, Xinggang Wang,
and Wenyu Liu. Textboxes: A fast text detector with a single deep neural network. In Proc. AAAI Conf. Artificial Intell.,2017.
[22] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He,
Bharath Hariharan, and Serge Belongie. Feature pyramid
networks for object detection. In Proc. IEEE Conf. Comp.
Vis. Patt. Recogn., pages 2117–2125, 2017.
[23] Xing Linjie, Tian Zhi, Huang Weilin, and R. Scott Matthew.
Convolutional Character Networks. In Proc. IEEE Int. Conf.
Comp. Vis., 2019.
[24] Xuebo Liu, Ding Liang, Shi Yan, Dagui Chen, Yu Qiao, and
Junjie Yan. Fots: Fast oriented text spotting with a uni-
fied network. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn.,
pages 5676–5685, 2018.
[25] Yuliang Liu and Lianwen Jin. Deep matching prior network:
Toward tighter multi-oriented text detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2017.
[26] Yuliang Liu, Lianwen Jin, Shuaitao Zhang, Canjie Luo, and
Sheng Zhang. Curved scene text detection via transverse
and longitudinal sequence connection. Pattern Recognition,90:337–345, 2019.
[27] Yuliang Liu, Sheng Zhang, Lianwen Jin, Lele Xie, Yaqiang
Wu, and Zhepeng Wang. Omnidirectional scene text detec-
tion with sequential-free box discretization. Proc. Int. Joint Conf. Artificial Intell., 2019.
[28] Shangbang Long, Jiaqiang Ruan, Wenjie Zhang, Xin He,
Wenhao Wu, and Cong Yao. Textsnake: A flexible repre-
sentation for detecting text of arbitrary shapes. In Proc. Eur.Conf. Comp. Vis., pages 20–36, 2018.
[29] George G. Lorentz. Bernstein polynomials. American Math-
ematical Soc., 2013.
[30] Pengyuan Lyu, Minghui Liao, Cong Yao, Wenhao Wu, and
Xiang Bai. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proc. Eur. Conf. Comp. Vis., pages 67–83, 2018.
[31] Nibal Nayef, Yash Patel, Michal Busta, Pinaki Nath Chowd-
hury, Dimosthenis Karatzas, Wafa Khlif, Jiri Matas, Uma-
pada Pal, Jean-Christophe Burie, Cheng-lin Liu, et al.
ICDAR2019 Robust Reading Challenge on Multi-lingual
Scene Text Detection and Recognition–RRC-MLT-2019.
Proc. IAPR Int. Conf. Document Analysis Recog., 2019.
[32] Jordi Pont-Tuset, Pablo Arbelaez, Jonathan T Barron, Fer-
ran Marques, and Jitendra Malik. Multiscale combinatorial
grouping for image segmentation and object proposal gener-
ation. IEEE Trans. Pattern Anal. Mach. Intell., 39(1):128–140, 2016.
[33] Siyang Qin, Alessandro Bissacco, Michalis Raptis, Yasuhisa Fujii, and Ying Xiao. Towards unconstrained end-to-end text spotting. Proc. IEEE Int. Conf. Comp. Vis., 2019.
[34] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Faster R-CNN: Towards real-time object detection with re-
gion proposal networks. In Proc. Advances in Neural Inf.
Process. Syst., pages 91–99, 2015.
[35] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end
trainable neural network for image-based sequence recogni-tionanditsapplicationtoscenetextrecognition. IEEETrans.Pattern Anal. Mach. Intell., 39(11):2298–2304, 2016.
[36] Yipeng Sun, Chengquan Zhang, Zuming Huang, Jiaming
Liu, Junyu Han, and Errui Ding. TextNet: Irregular Text
Reading from Images with an End-to-End Trainable Net-
work. In Proc. Asian Conf. Comp. Vis., pages 83–99.
Springer, 2018.
[37] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS:
Fully Convolutional One-Stage Object Detection. Proc.
IEEE Int. Conf. Comp. Vis., 2019.
[38] Zhuotao Tian, Michelle Shu, Pengyuan Lyu, Ruiyu Li, Chao
Zhou, Xiaoyong Shen, and Jiaya Jia. Learning Shape-Aware
Embedding for Scene Text Detection. In Proc. IEEE Conf.
Comp. Vis. Patt. Recogn., pages 4234–4243, 2019.
[39] Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas,
and Serge Belongie. Coco-text: Dataset and benchmark
for text detection and recognition in natural images. arXiv: Comp. Res. Repository, 2016.
[40] Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu,
Gang Yu, and Shuai Shao. Shape Robust Text Detection with
Progressive Scale Expansion Network. Proc. IEEE Conf.
Comp. Vis. Patt. Recogn., 2019.
[41] Wenhai Wang, Enze Xie, Xiaoge Song, Yuhang Zang, Wen-
jia Wang, Tong Lu, Gang Yu, and Chunhua Shen. Efficient
and Accurate Arbitrary-Shaped Text Detection with Pixel
Aggregation Network. Proc. IEEE Int. Conf. Comp. Vis.,
2019.
[42] Xiaobing Wang, Yingying Jiang, Zhenbo Luo, Cheng-Lin
Liu, Hyunsoo Choi, and Sungjin Kim. Arbitrary Shape
Scene Text Detection with Adaptive Text Region Represen-
tation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages
6449–6458, 2019.
[43] Feng Wei, He Wenhao, Yin Fei, Zhang Xu-Yao, and Cheng-
Liu Liu. TextDragon: An end-to-end framework for arbitrary
shaped text spotting. In Proc. IEEE Int. Conf. Comp. Vis.,
2019.
[44] Yongchao Xu, Yukang Wang, Wei Zhou, Yongpan Wang,
Zhibo Yang, and Xiang Bai. Textfield: Learning a deep di-
rection field for irregular scene text detection. IEEE Trans.
Image Process., 2019.
[45] Chengquan Zhang, Borong Liang, Zuming Huang, Mengyi
En, Junyu Han, Errui Ding, and Xinghao Ding. Look More
Than Once: An Accurate Detector for Text of Arbitrary
Shapes. Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019.
[46] Zhuoyao Zhong, Lianwen Jin, Shuye Zhang, and Ziyong
Feng. Deeptext: A unified framework for text proposal gen-
eration and text detection in natural images. arXiv: Comp.
Res. Repository, 2016.
[47] Zhuoyao Zhong, Lei Sun, and Qiang Huo. An anchor-free
region proposal network for faster r-cnn-based text detection approaches. Int. J. Document Analysis Recogn., 22(3):315–327, 2019.
[48] Yixing Zhu and Jun Du. Sliding line point regression for
shape robust scene text detection. In Proc. Int. Conf. Patt. Recogn., pages 3735–3740. IEEE, 2018.