#Paper Reading# Pre-trained Language Model based Ranking in Baidu Search
论文题目: Pre-trained Language Model based Ranking in Baidu Search
论文地址: https://dl.acm.org/doi/abs/10.1145/3447548.3467147
论文发表于: KDD 2021
论文所属单位: Baidu
论文大体内容:
本文主要提出了一个Pre-trained的模型,通过引入类似BERT的预训练模型到百度搜索引擎的Ranking模块,来提升Ranking的效果。
Motivation
应用预训练语言模型在搜索当中,面临着三个方面的挑战[1]:
①long document modeling(长文本建模)
②expensive computation(昂贵的计算)
③rank-agnostic pre-training(预训练模型与搜索排序无关)
Contribution
①提出了金字塔结构的ERNIE,能高效且有效的提升搜索中的ranking效果;
②相关的pre-training,引入用户点击数据反馈;
③线上系统里使用人工标记数据进行fine-tuning;
④在offline和online上都取得收益;
1. 搜索引擎发展历程:
①关键词匹配(显式匹配)
-倒排索引
②语义匹配(隐式匹配)
-LDA
-DSSM(基于深度网络的语义模型),第一次将NN用于解决语义匹配的问题
2. 本文想研究2个问题:
①是否BERT也可以来帮助解决信息检索中的语义相关性问题?
②在工业搜索引擎这种超大规模的系统里,如何将BERT等预训练语言模型应用,提升搜索质量?
3. 搜索领域,与推荐类似,也分为检索(触发/召回)和排序阶段,而检索阶段应用BERT也是很自然的事情(query-document embedding进行ANN,相比倒排索引就是语义的检索)。
4. 应用预训练语言模型在搜索当中,面临着三个方面的挑战[1]:(Motivation)
①long document modeling(长文本建模)
②expensive computation(昂贵的计算)
③rank-agnostic pre-training(预训练模型与搜索排序无关)
5. 挑战1:长文本建模
本文提出QUery-WeIghted Summary ExTraction (QUIET)算法,使用原理有点类似MMR的方式,可以快速高效的从document里提取出3-5句sentence组成的摘要

6. 挑战2:昂贵的计算
本文提出了Pyramid-ERNIE结构,按复杂度进行计算,相比直接Transformer(E(q,t,s))可以节约30%的计算复杂度开销。
金字塔ERNIE包括3部分
①E(q, t) = Transformer(query-title)
②E(s) = Transformer(summary)
③Transformer(E(q,t), E(s))

7. 挑战3:预训练模型与搜索排序无关
本文使用用户的行为日志,预训练出一个tree-based结构的多分类模型,然后使用triplet-loss套入Pyramid-ERNIE中,提升了下游排序任务的效果。
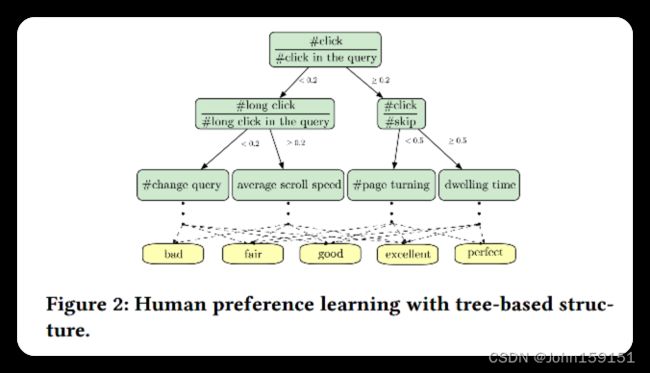

8. 在搜索领域,用户的行为日志,有几个问题:
①false-positive样本:噪音信号/虚假点击,可以通过类似视频推荐的长播放来解决;
②曝光偏差:使用click-skip ratio来解决;
③relevance:使用人工标注数据来解决;
9. 搜索有效的feature
①用户停留时间;
②用户滚动速度;
③query rewriting;
④long-click的数量;
10. 同时使用pairwise loss和pointwise loss来提升模型效果
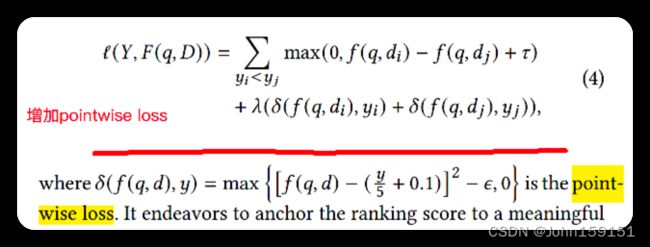
实验
11. 本文使用提出的Pyramid-ERNIE进行了离线和在线实验来验证其有效性。
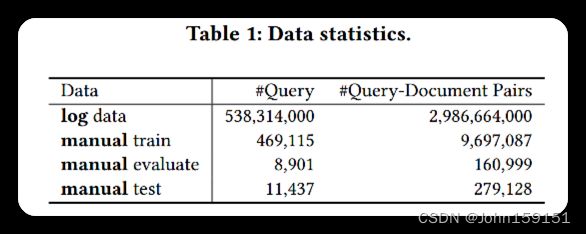
12. Dataset
①百度内部人工标注的相关性测试集;
13. Metric
搜索常用metric
①DCG/NDCG
②PNR,Positive Negative Rate = 正序对数 / 逆序对数
③ACC
④Interleaving观察线上效果[2]
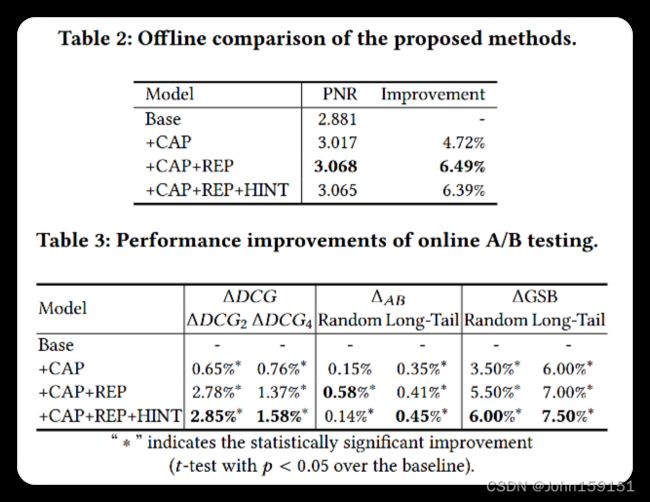
14. 实验结果
①离线实验:验证PNR的提升;
②在线实验:通过AB实验验证,DCG、interleaving,GSB上的提升。
15. 下一步[1]
①基于预训练语言模型的方法一方面能有效解决语义的模糊匹配问题,但是另一方面却引入了一些丢失核心词的问题,例如 基于预训练语言模型的方法会给“小熊猫” 和 “熊猫”判定为非常匹配,但是实际上“小熊猫” 和 “熊猫”完全不同。如何提升基于预训练语言模型的方法在精确匹配上的效果,是一个值得深入研究的问题。一种潜在的方法可以是对抗学习,主动学习的方法,比如收集类似的样本来解决。
②如何有效的选取的核心摘要的问题也是一个值得进一步探索的问题,本文的摘要选取策略是启发式的方法,后续可以采用更加合理设计进一步提升性能。
③模型小型化的技术,比如蒸馏,压缩等等也是很重的方向。超大模型在各NLP问题显示了的潜力,主要应用瓶颈依然是成本,后续模型小型化技术可以使得这种超大模型部署成为可能。
参考资料
[1] 沈向洋对话殷大伟:预训练语言模型如何提升搜索效果 https://mp.weixin.qq.com/s/it38yJoq0Mbu0wCYbpVDNQ
[2] 新的abtest方法: Innovating Faster on Personalization Algorithms at Netflix Using Interleaving https://blog.csdn.net/John159151/article/details/103759833
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!