2021-08-27 分割之后mask在原图中提取出来(语义分割—实例分割)
1.生成分割后的mask
原图和mask如下:

2.mask二值化
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 获取图片
def getimg():
return Image.open("2.png")
def showimg(img, isgray=False):
plt.axis("off")
if isgray == True:
plt.imshow(img, cmap='gray')
else:
plt.imshow(img)
plt.show()
im5 = getimg()
im5 = np.array(im5.convert('L'))
im5 = np.where(im5[...,:] < 165, 0, 255) #根据设置的阈值来进行黑白分类
showimg(Image.fromarray(im5), True)
生成如图:

3. mask二值化后取反
import os
from PIL import Image
import numpy as np
def resize(imgPath, savePath):
files = os.listdir(imgPath)
files.sort()
print('****************')
print('input :', imgPath)
print('start...')
for file in files:
fileType = os.path.splitext(file)
if fileType[1] == '.png':
new_png = Image.open(imgPath + '/' + file) # 打开图片
# new_png = new_png.resize((20, 20),Image.ANTIALIAS) #改变图片大小
matrix = 255 - np.asarray(new_png) # 图像转矩阵 并反色
new_png = Image.fromarray(matrix) # 矩阵转图像
new_png.save(savePath + '/' + file) # 保存图片
print('down!')
print('****************')
if __name__ == '__main__':
# 待处理图片地址
dataPath = 'G:\\666\\2\\'
# 保存图片的地址
savePath = 'G:\\666\\2\\'
resize(dataPath, savePath)
如图:

4.把mask分割后的图像提取出来
import os
import cv2
import numpy as np
#im1 原图 im2 mask图(背景是黑色,前景是白色)
im1_path = 'G:/666/1/'
im2_path = 'G:/666/2/'
num = len(os.listdir(im1_path))
for i in range(num):
img1 = cv2.imread(os.path.join(im1_path, os.listdir(im1_path)[i]))
img2 = cv2.imread(os.path.join(im2_path,os.listdir(im2_path)[i]), cv2.IMREAD_GRAYSCALE)
h,w,c = img1.shape
img3 = np.zeros((h,w,4))
img3[:,:,0:3] = img1
img3[:,:,3] = img2
#这里命名随意,但是要注意使用png格式
cv2.imwrite('G:/666/3/' + '%s.png' % os.listdir(im1_path)[i], img3)
生成图像:
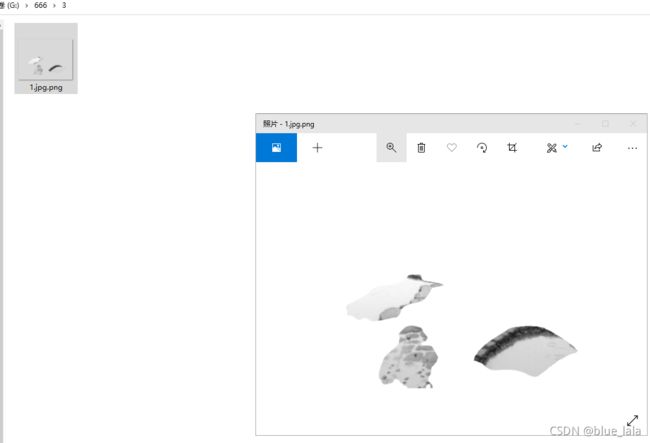
上面这种出来是透明背景32位的,并不是白色!!!!
另一种出来版本是黑色背景:
import cv2
person = cv2.imread("1.png")
# back = cv2.imread("背景图")
#这里将mask图转化为灰度图
mask = cv2.imread("6.png",cv2.IMREAD_GRAYSCALE)
#将背景图resize到和原图一样的尺寸
# back = cv2.resize(back,(person.shape[1],person.shape[0]))
#这一步是将背景图中的人像部分抠出来,也就是人像部分的像素值为0
# scenic_mask =~mask
# scenic_mask = scenic_mask / 255.0
# back[:,:,0] = back[:,:,0] * scenic_mask
# back[:,:,1] = back[:,:,1] * scenic_mask
# back[:,:,2] = back[:,:,2] * scenic_mask
#这部分是将我们的人像抠出来,也就是背景部分的像素值为0
mask = mask / 255.0
person[:,:,0] = person[:,:,0] * mask
person[:,:,1] = person[:,:,1] * mask
person[:,:,2] = person[:,:,2] * mask
#这里做个相加就可以实现合并
# result = cv2.add(back,person)
cv2.imwrite("3.jpg", person)
出图如下:

如果加上背景的话:(像素黑的就是0,随便附加颜色)
import cv2
person = cv2.imread("1.png")
back = cv2.imread("0.png")
#这里将mask图转化为灰度图
mask = cv2.imread("6.png",cv2.IMREAD_GRAYSCALE)
#将背景图resize到和原图一样的尺寸
back = cv2.resize(back,(person.shape[1],person.shape[0]))
#这一步是将背景图中的人像部分抠出来,也就是人像部分的像素值为0
scenic_mask =~mask
scenic_mask = scenic_mask / 255.0
back[:,:,0] = back[:,:,0] * scenic_mask
back[:,:,1] = back[:,:,1] * scenic_mask
back[:,:,2] = back[:,:,2] * scenic_mask
#这部分是将我们的人像抠出来,也就是背景部分的像素值为0
mask = mask / 255.0
person[:,:,0] = person[:,:,0] * mask
person[:,:,1] = person[:,:,1] * mask
person[:,:,2] = person[:,:,2] * mask
#这里做个相加就可以实现合并
result = cv2.add(back,person)
cv2.imwrite("88.jpg", result)
5.把mask分割后的图像可视化出来同步
# 将分割图和原图合在一起
from PIL import Image
import matplotlib.pyplot as plt
# image1 原图
# image2 分割图
image1 = Image.open("1.png")
image2 = Image.open("6.png")
image1 = image1.convert('RGBA')
image2 = image2.convert('RGBA')
# 两幅图像进行合并时,按公式:blended_img = img1 * (1 – alpha) + img2* alpha 进行
image = Image.blend(image1, image2, 0.3)
image.save("test1.png")
image.show()

抠图小结:
1.opencv抠图 (扣出背景是黑色,24位)
###################### opencv抠出来
import cv2
person = cv2.imread(r"G:\666BASNet-master\test_data\1\2.png")
person_ori = person.copy()
# back = cv2.imread("背景图")
#这里将mask图转化为灰度图
mask = cv2.imread(r"G:\666BASNet-master\test_data\2\2.png",cv2.IMREAD_GRAYSCALE)
#将背景图resize到和原图一样的尺寸
# back = cv2.resize(back,(person.shape[1],person.shape[0]))
#这一步是将背景图中的人像部分抠出来,也就是人像部分的像素值为0
# scenic_mask =~mask
# scenic_mask = scenic_mask / 255.0
# back[:,:,0] = back[:,:,0] * scenic_mask
# back[:,:,1] = back[:,:,1] * scenic_mask
# back[:,:,2] = back[:,:,2] * scenic_mask
#这部分是将我们的人像抠出来,也就是背景部分的像素值为0
mask = mask / 255.0
person[:,:,0] = person[:,:,0] * mask
person[:,:,1] = person[:,:,1] * mask
person[:,:,2] = person[:,:,2] * mask
#这里做个相加就可以实现合并
# result = cv2.add(back,person)
diffImg2 = cv2.subtract(person, person_ori)
# cv2.imwrite(r"G:\666BASNet-master\test_data\out\opencv_out.png", person)
# cv2.imwrite(r"G:\666BASNet-master\test_data\out_1.png", diffImg2)
cv2.imwrite(r"G:\666BASNet-master\test_data\4\2.png", person)
效果:
原图:24位
mask:24位
opencv扣出效果:背景是黑色的,24位

2.pillow抠图 (扣出背景是黑色,24位)
###################### pillow抠出来
from PIL import Image
import numpy as np
#目标地址
target=r'G:\666(抠图之后测试)\0.png' #原图24位
#二值图地址
decorate=r'G:\666(抠图之后测试)\6.png' #背景黑 目标白 24位
class ImageCut:
def cover(self, target, decorate):
# 分别打开2张图片
image_target = Image.open(target)
image_decorate = Image.open(decorate)
# todo 校验图片长宽相等
image_target_width = image_target.width
image_target_height = image_target.height
image_decorate_width = image_decorate.width
image_decorate_height = image_decorate.height
# 对比像素点
for h in range(image_target_height):
for w in range(image_target_width):
# 打印该图片的所有点
# print(image_decorate.getpixel((w, h)), end=" ")
# 判断像素点是否为约定好的 255, 255, 255--白色
if (image_decorate.getpixel((w, h)) !=(255, 255, 255)):
# 设定目标图片像素点为 255, 255, 255 & 0, 0, 0
image_target.putpixel((w, h), (0, 0, 0))
print('\n')
# 保存处理后的图片
img = np.array(image_target)
print(img)
# diffImg2 = cv2.subtract(img, target)
# im3 = PIL.ImageChops.subtract(img, target, scale=1.0, offset=0)
# print(im3)
image_target.save(r"G:\666(抠图之后测试)\0608_out.png")
#调用
ImageCut().cover(target,decorate)
原图24位——mask24位-——抠图24位

3.提取白色背景的抠图
import os
from PIL import Image
import numpy as np
import cv2
import time
import warnings
warnings.filterwarnings("ignore")
def koutu24(prediction_dir, savePath): # 获取24位
files = os.listdir(prediction_dir)
files.sort()
print('****************')
print('input :', prediction_dir)
print('start to 24bit...')
for file in files:
fileType = os.path.splitext(file)
if fileType[1] == '.png':
new_png = Image.open(prediction_dir + '/' + file) # 打开图片
# new_png = new_png.resize((20, 20),Image.ANTIALIAS) #改变图片大小
matrix = 255 - np.asarray(new_png) # 图像转矩阵 并反色
# new_png = Image.fromarray(matrix) # 矩阵转图像
img1 = cv2.imread(image_dir + file)
image = cv2.add(img1, matrix)
cv2.imwrite(savePath + '\\' + file, image) # 保存图片
print('down!')
print('****************')
def koutu32(imgPath, savePath): # 获取32位
print('****************')
print('input :', imgPath)
print('start to 32bit...')
num = len(os.listdir(imgPath))
for i in range(num):
img1 = cv2.imread(os.path.join(imgPath, os.listdir(imgPath)[i]))
img2 = cv2.imread(os.path.join(prediction_dir, os.listdir(prediction_dir)[i]), cv2.IMREAD_GRAYSCALE)
h, w, c = img1.shape
img3 = np.zeros((h, w, 4))
img3[:, :, 0:3] = img1
img3[:, :, 3] = img2
a = os.listdir(imgPath)[i]
b = a.split(".")
c = b[0]
cv2.imwrite(savePath + '%s.png' % c, img3)
print('down!')
print('****************')
if __name__ == '__main__':
# --------- 1. get image path and name ---------
image_dir = './test_data/111/' # 待分割图片输入./test_data/1/
mask_dir = './test_data/222/' # mask图 目标白 周围黑./test_data/2/
savePath = './test_data/333/' # 保存图片的地址'./test_data/3/
files = os.listdir(image_dir) # 会按顺序排列[1,2,3,4,.png]格式 刚开始需要把所有图片(1).(2).(3)……的形式,再重新按顺序排名
i = 0
for file in files:
original = image_dir + os.sep + files[i]
new = image_dir + os.sep + str(i + 1) + ".png"
os.rename(original, new)
i += 1
koutu24(mask_dir, savePath)
效果展示:原图24位——mask24位——抠图24位

4. 比较提取出来的地方和原图,是否有差异,是否提取准确
比较图片差异代码:
#####################################比较图片差异 黑背景抠图-原图=像素0就是对的!!
import numpy as np
import cv2
def main():
img1 = cv2.imread(r'G:\666BASNet-master\test_data\333\0608_out.png') # 扣出来的图
img2 = cv2.imread(r'G:\666BASNet-master\test_data\333\1.png') # 原图
diffImg1 = cv2.subtract(img1, img2)
diffImg2 = cv2.subtract(img2, img1)
# diffImg3 = img1 - img2
# diffImg4 = img2 - img1
print(diffImg1) # diffImg1 显示ndarray显示全零就是对的
cv2.imwrite(r'G:\666BASNet-master\test_data\333\opencv_out.png', diffImg1)
# cv2.imshow('subtract(img2,img1)', diffImg2)
print(diffImg1)
# cv2.imshow('img1 - img2', diffImg3)
# cv2.imshow('img2 - img1', diffImg4)
cv2.waitKey(0)
main()
debug看情况:

原图24位——>mask24位——>抠图黑背景+真实目标——>差异对比图(黑背景抠图-原图)全黑像素都为零就是对的
