【YOLOX】 相关问题总结
1.YOLOX无法指定gpu,只能指定gpu个数
YOLOX-main/yolox/utils/dist.py在此路径下注释和添加代码:
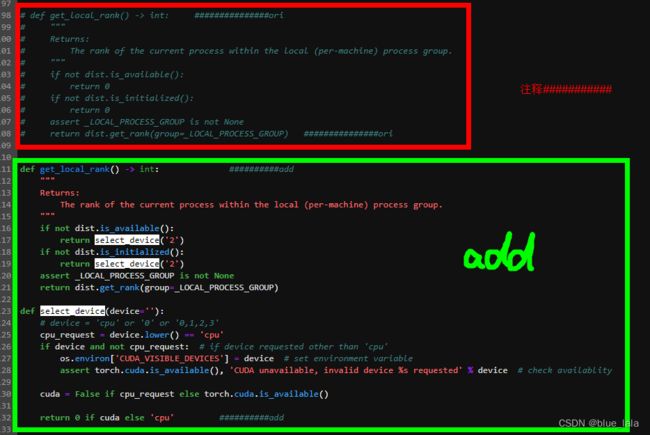
def get_local_rank() -> int: ###############ori
"""
Returns:
The rank of the current process within the local (per-machine) process group.
"""
if not dist.is_available():
return 0
if not dist.is_initialized():
return 0
assert _LOCAL_PROCESS_GROUP is not None
return dist.get_rank(group=_LOCAL_PROCESS_GROUP) ###############ori
def get_local_rank() -> int: ##########add
"""
Returns:
The rank of the current process within the local (per-machine) process group.
"""
if not dist.is_available():
return select_device('2')
if not dist.is_initialized():
return select_device('2')
assert _LOCAL_PROCESS_GROUP is not None
return dist.get_rank(group=_LOCAL_PROCESS_GROUP)
def select_device(device=''):
# device = 'cpu' or '0' or '0,1,2,3'
cpu_request = device.lower() == 'cpu'
if device and not cpu_request: # if device requested other than 'cpu'
os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
assert torch.cuda.is_available(), 'CUDA unavailable, invalid device %s requested' % device # check availablity
cuda = False if cpu_request else torch.cuda.is_available()
return 0 if cuda else 'cpu' ##########add
2.训练时候突然多出其他类别
yolox训练时候突然多出两类,莫名其妙??
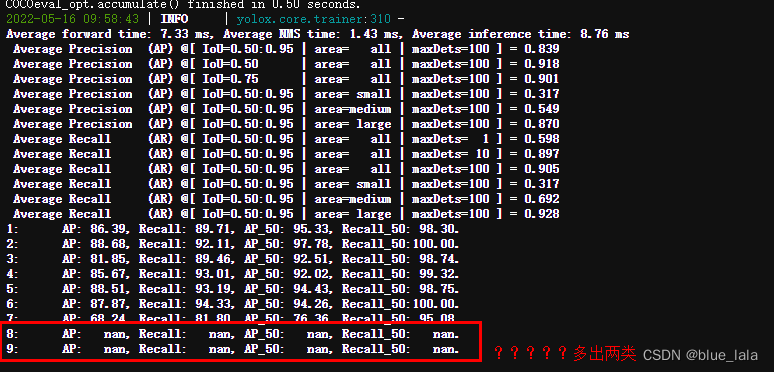
检查标签发现貌似没问题,一共7类

后面查看json文件发现中间的标签,由于中间有空格,所以一类变成三类,突然多出两类
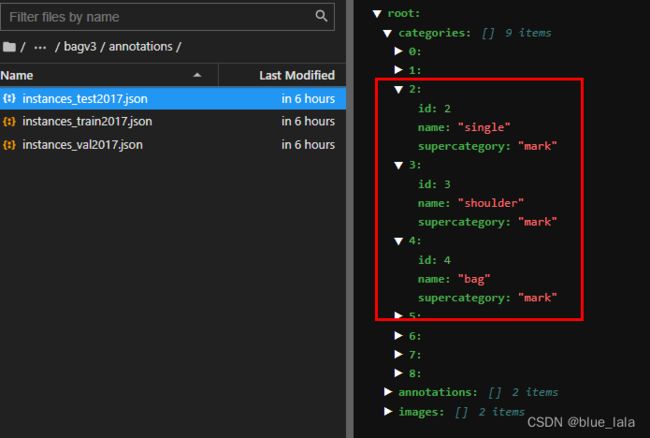
后面修正一下标签如下,加下划线_

3. 负样本生成txt
当加入负样本时候,生成空的txt,放进去训练
import os.path
import cv2
from tqdm import tqdm
path = r"F:\1213bag\bag_all_yolox\add_new_6666\images" #负样本图片文件夹
save_path=r"F:\1213bag\bag_all_yolox\add_new_6666\labels" #生成空的txt文件夹
files = os.listdir(path)
print(files)
for pic in tqdm(files):
# # basename = os.path.basename(image_name)
before_name = os.path.splitext(pic)[0]
txt_name = os.path.splitext(before_name)[0] + ".txt"
txt_name = os.path.join(save_path,txt_name)
if os.path.exists(txt_name) == False:
f = open(txt_name, "w")
4.找出漏检样本
demo.py检测完,会有漏检生成空的txt,查找漏检图片放进另一个文件夹
# 导入os
import os
import shutil
# 让用户自行输入路径
path= r'D:\YOLOX-main\YOLOX_outputs\yolox_m\vis_res\2022_05_17_11_00_00'
save_path = r'F:\1213bag\bag_all_yolox\vis_res\nofind_0517_v2'
if not os.path.isdir(save_path):
os.makedirs(save_path)
# path= input('请输入文件目录路径')
# save_path = input('请输入保存目录路径')
# 获取当前目录下的所有文件夹名称 得到的是一个列表
folders=os.listdir(path)
# # 遍历列表
for folder in folders:
if folder.endswith(".txt"): # endswith() 判断以什么什么结尾
# print(folder)
# 将上级路径path与文件夹名称folder拼接出文件夹的路径
folder_all_path = os.path.join(path,folder)
# print(folder_all_path)
folder_size = os.path.getsize(folder_all_path)
# 若文件夹为空
if folder_size == 0:
# 则打印此空文件的名称
print("空文件夹名称:",folder)
basename = folder.split('.')[0]
save_path1 = save_path + os.sep + basename + ".jpg"
ori_path = path + os.sep + basename + ".jpg"
shutil.move(ori_path, save_path1)
# # 并将此空文件夹删除
os.remove(folder_all_path)
5.划分检测的train.py/val.py
"""
YOLO 格式的数据集转化为 COCO 格式的数据集
--root_dir 输入根路径
--save_path 保存文件的名字(没有random_split时使用)
--random_split 有则会随机划分数据集,然后再分别保存为3个文件。
"""
import os
import cv2
import json
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--root_dir', default='F:\\1213bag\\bag_all_yolox\\bagv3\\', type=str,
help="root path of images and labels, include ./images and ./labels and classes.txt")
parser.add_argument('--save_path', type=str, default='./train.json',
help="if not split the dataset, give a path to a json file")
parser.add_argument('--random_split', action='store_false', help="ratio_train=0.889, ratio_test=0.1, ratio_val=0.001") # store_false = 8:1:1
arg = parser.parse_args() # store_true =train 全部
# test_image = "F:\\advertisement1622+json\\test2017\\" # 新建以下三个文件夹
# val_image = "F:\\advertisement1622+json\\val2017\\"
# train_image = "F:\\advertisement1622+json\\train2017\\"
test_image = os.path.join(arg.root_dir, 'test2017')
val_image = os.path.join(arg.root_dir, 'val2017')
train_image = os.path.join(arg.root_dir, 'train2017')
if not os.path.exists(test_image):
os.makedirs(test_image)
if not os.path.exists(val_image):
os.makedirs(val_image)
if not os.path.exists(train_image):
os.makedirs(train_image)
def train_test_val_split(img_paths, ratio_train=0.889, ratio_test=0.1, ratio_val=0.001,):
# 这里可以修改数据集划分的比例。
assert int(ratio_train + ratio_test + ratio_val) == 1
train_img, middle_img = train_test_split(img_paths, test_size=1 - ratio_train, random_state=233)
ratio = ratio_val / (1 - ratio_train)
val_img, test_img = train_test_split(middle_img, test_size=ratio, random_state=233)
print("NUMS of train:val:test = {}:{}:{}".format(len(train_img), len(val_img), len(test_img)))
return train_img, val_img, test_img
def yolo2coco(root_path, random_split):
originLabelsDir = os.path.join(root_path, 'labels')
originImagesDir = os.path.join(root_path, 'images')
with open(os.path.join(root_path, 'classes.txt')) as f:
classes = f.read().strip().split()
# images dir name
indexes = os.listdir(originImagesDir)
if random_split:
# 用于保存所有数据的图片信息和标注信息
train_dataset = {'categories': [], 'annotations': [], 'images': []}
val_dataset = {'categories': [], 'annotations': [], 'images': []}
test_dataset = {'categories': [], 'annotations': [], 'images': []}
# 建立类别标签和数字id的对应关系, 类别id从0开始。
for i, cls in enumerate(classes, 0):
train_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})
val_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})
test_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})
train_img, val_img, test_img = train_test_val_split(indexes, 0.8999, 0.1, 0.0001) # 这里可以修改数据集划分的比例。
else:
dataset = {'categories': [], 'annotations': [], 'images': []}
for i, cls in enumerate(classes, 0):
dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})
# 标注的id
ann_id_cnt = 0
for k, index in enumerate(tqdm(indexes)):
# 支持 png jpg 格式的图片。
txtFile = index.replace('images', 'txt').replace('.jpg', '.txt').replace('.png', '.txt')
# 读取图像的宽和高
im = cv2.imread(os.path.join(root_path, 'images/') + index)
height, width, _ = im.shape
# index = index.replace('.png', '.jpg')
if random_split:
# 切换dataset的引用对象,从而划分数据集
if index in train_img:
dataset = train_dataset
cv2.imwrite(train_image + os.sep + index, im)
# print(train_image + os.sep + index)
elif index in val_img:
dataset = val_dataset
cv2.imwrite(val_image + os.sep + index, im)
# print(val_image + os.sep + index)
elif index in test_img:
dataset = test_dataset
cv2.imwrite(test_image + os.sep + index, im)
# print(test_image + os.sep + index)
# 添加图像的信息
dataset['images'].append({'file_name': index,
'id': k,
'width': width,
'height': height})
if not os.path.exists(os.path.join(originLabelsDir, txtFile)):
# 如没标签,跳过,只保留图片信息。
continue
with open(os.path.join(originLabelsDir, txtFile), 'r') as fr:
labelList = fr.readlines()
for label in labelList:
label = label.strip().split()
x = float(label[1])
y = float(label[2])
w = float(label[3])
h = float(label[4])
# convert x,y,w,h to x1,y1,x2,y2
H, W, _ = im.shape
x1 = (x - w / 2) * W
y1 = (y - h / 2) * H
x2 = (x + w / 2) * W
y2 = (y + h / 2) * H
# 标签序号从0开始计算, coco2017数据集标号混乱,不管它了。
cls_id = int(label[0])
width = max(0, x2 - x1)
height = max(0, y2 - y1)
dataset['annotations'].append({
'area': width * height,
'bbox': [x1, y1, width, height],
'category_id': cls_id,
'id': ann_id_cnt,
'image_id': k,
'iscrowd': 0,
# mask, 矩形是从左上角点按顺时针的四个顶点
'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]
})
ann_id_cnt += 1
# 保存结果
folder = os.path.join(root_path, 'annotations')
if not os.path.exists(folder):
os.makedirs(folder)
if random_split:
for phase in ['instances_train2017', 'instances_val2017', 'instances_test2017']:
json_name = os.path.join(root_path, 'annotations/{}.json'.format(phase))
with open(json_name, 'w') as f:
if phase == 'instances_train2017':
json.dump(train_dataset, f)
elif phase == 'instances_val2017':
json.dump(val_dataset, f)
elif phase == 'instances_test2017':
json.dump(test_dataset, f)
print('Save annotation to {}'.format(json_name))
else:
json_name = os.path.join(root_path, 'annotations/{}'.format(arg.save_path))
with open(json_name, 'w') as f:
json.dump(dataset, f)
print('Save annotation to {}'.format(json_name))
if __name__ == "__main__":
root_path = arg.root_dir
assert os.path.exists(root_path)
random_split = arg.random_split
print("Loading data from ", root_path, "\nWhether to split the data:", random_split)
yolo2coco(root_path, random_split)