【Pytorch学习笔记】7.继承Module类构建模型时,子模块的构建原理(基于OrderedDict)以及关于Python类的属性赋值机制
本文继续探究学Pytorch时,涉及到的python底层的一些知识。
文章目录
-
- 问:继承Module类构造模型时,背后是如何把自定义的子模块组装起来的?
- 1 Module初始化时会构建多个OrderedDict(有序字典)存放子模块
- 2 Python的魔法方法__setattr__()定义了 类实例的属性赋值 时的行为
- 3 Module类实例在属性赋值时会判断属性的类型存入对应的OrderedDict
- 总结
问:继承Module类构造模型时,背后是如何把自定义的子模块组装起来的?
我们学习模型构造时,是基于继承nn.Module类定义模型来实现模型的构造的。
最简单的构造方法一般就是2个:
①重写父类的__init__构造函数,写上自己想要的子模块;②定义forward()正向传播函数,将子模块拼接起来。
比如我们构造一个多层感知机MLP模型:
import torch
from torch import nn
class MLP(nn.Module):
# __init__中声明带有模型参数的自定义层,这里定义了两个全连接层
def __init__(self, **kwargs):
# 调用父类Module的__init__进行必要的初始化。
super(MLP, self).__init__(**kwargs)
# 定义自己的子模块。
self.hidden = nn.Linear(784, 256) # 隐藏层
self.act = nn.ReLU()
self.output = nn.Linear(256, 10) # 输出层
# 定义模型的前向计算,即如何根据输入X计算返回所需要的输出。即拼接子模块。
def forward(self, x):
a = self.act(self.hidden(x))
return self.output(a)
# 测试一下
X = torch.rand(2, 784)
net = MLP()
print(net)
net(X)
结果:
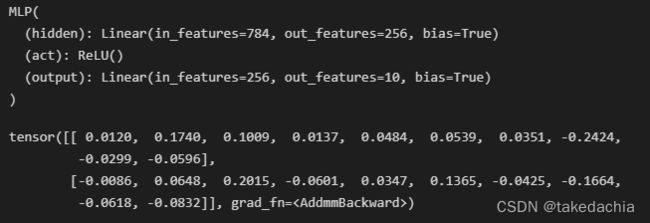
可以看到我们在__init__中定义的属性hidden、act、output所指定的子模块被读取到了模型net的信息中。
这也是重写Module的__init__构造函数时的常用方法,在Pytorch的文档中,Module部分开头便指出了继承Module构建模型的写法:

即前面提到的:1.重写__init__构造函数,添加子模块;2.定义forward()正向传播。
那么继承Module类构造模型时,背后是如何把自定义的子模块组装起来的?
为什么在__init__中 以类属性的形式 添加子模块就可以自动被读取为模型的组成部分呢?
1 Module初始化时会构建多个OrderedDict(有序字典)存放子模块
我们看Module的源码,可以看到__init__时会 _construct 许多OrderedDict(有序字典):
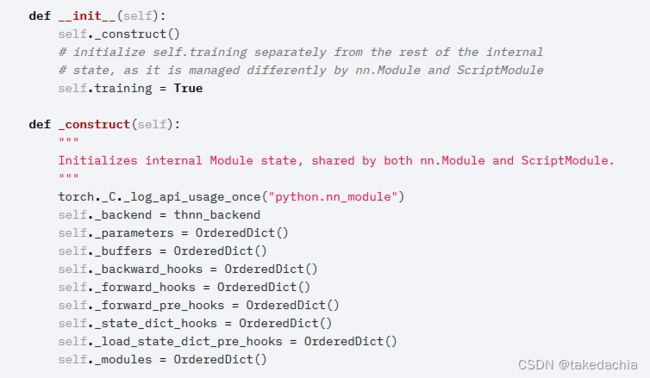
有序字典顾名思义就是有先后顺序的Dict。这里创建了许多类别的属性,有我们认识的 parameters、buffers 和 modules,我们就可以推断 _module 属性就存放了我们未来自定义的子模块,如Linear()等。
我们还看到 add_module 方法可以手动添加module:
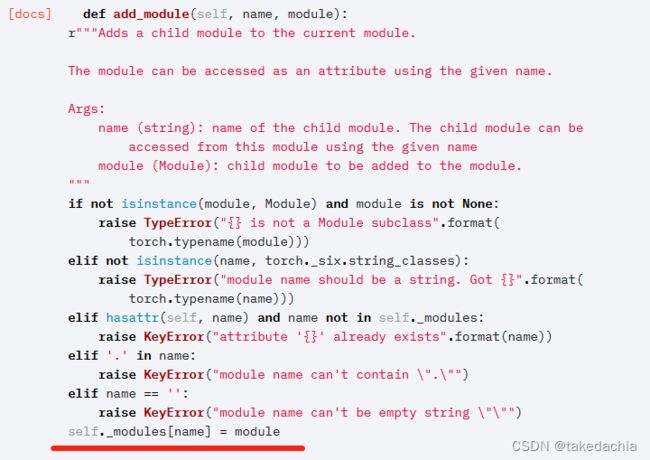
那么我们可以推断,初始化Module时__init__中自定义的子模块肯定也有方法,将它们添加进生成的空OrderedDict中。
那么是什么方法来把这些变量初始存入这个 _modules 属性中的呢?
这就和Python本身的类属性的赋值机制有关了。
2 Python的魔法方法__setattr__()定义了 类实例的属性赋值 时的行为
在Python的Object基类中,我们定义类的时候自带了魔法方法__setattr__()。
它的作用:当对类的实例 的各个属性进行赋值时,首先自动调用__setattr__()方法,在该方法中实现将属性名和属性值添加到类实例的__dict__属性中。
一般情况下我们不用重写__setattr__(),实例化后的类当触发属性赋值事件时,会自动调用该方法,并存入__dict__属性。举个栗子:
class MyInfo:
ai = 'hello'
def __init__(self):
print(self.__dict__)
self.name = "Chopper"
print(self.__dict__)
self.age = 32
print(self.__dict__)
self.male = True
print(self.__dict__)
print(self.ai)
myinfo = MyInfo()
print('-----------------')
myinfo.female = False
myinfo.age = 20
print(myinfo.__dict__)
# 输出:
{}
{'name': 'Chopper'}
{'name': 'Chopper', 'age': 32}
{'name': 'Chopper', 'age': 32, 'male': True}
hello
-----------------
{'name': 'Chopper', 'age': 20, 'male': True, 'female': False}
# 这里 ai 没有触发属性赋值机制,所以不会存在于__dict__中。
3 Module类实例在属性赋值时会判断属性的类型存入对应的OrderedDict
在Module中,我们定义子模块的过程就是给Module定义属性并赋值的过程(如self.hidden = nn.Linear(784, 256)),因此触发__setattr__()。
在Module中,__setattr__()被重写,属性的值会被先拿来判断一次,如被判断为 Module、Parameter 或 Buffer,便存入__dict__事先建起来的有序字典_module、 _parameters 和 _buffers中。剩下未分类属性信息存入__dict__的末尾。
具体源码可参考Module的__setattr__()部分,这里不展示了。
我们把开头的代码修改一下,我们一次次地观察__dict__的变化,可以看到:
import torch
from torch import nn
class MLP(nn.Module):
# __init__中声明带有模型参数的自定义层,这里定义了两个全连接层
def __init__(self, **kwargs):
# 调用父类Module的__init__进行必要的初始化。
super(MLP, self).__init__(**kwargs)
# 定义自己的子模块。
print(self.__dict__ ,'\n')
self.hidden = nn.Linear(784, 256)
print(self.__dict__ ,'\n')
self.act = nn.ReLU()
print(self.__dict__ ,'\n')
self.output = nn.Linear(256, 10)
print(self.__dict__ ,'\n')
self.origin = 1.0
print(self.__dict__ ,'\n')
# 定义模型的前向计算,即如何根据输入X计算返回所需要的输出。即拼接子模块。
def forward(self, x):
a = self.act(self.hidden(x))
return self.output(a)
# 测试一下
net = MLP()
print(net)
print(net._modules['hidden']._parameters)
结果:

可以看到net中的各个OrderedDict类别属性和其他的属性,子module模块 Linear()、ReLU()等 被分类到了_module属性中。
而打印net会显示各个module的信息(由另一个魔法方法__str__定义)。
同时,module被存为了OrderedDict后,还可以方便通过标签访问该有序字典的子module中的信息(比如上面代码最后一行)。
每个Module类都有这一套的OrderedDict,关系上层层套叠,也方便维护和管理。
不仅是Module本身,Module的Parameter、Buffer等也都可以在这个基于OrderedDict嵌套的树形结构中维护,也体现了Module这个框架的精密性。
总结
- 我们基于继承nn.Module构建模型时,一般实现以下2个步骤:
①重写父类的__init__构造函数,写上自己想要的子模块;②定义forward()正向传播函数,将子模块拼接起来。 - Module初始化时会构建多个OrderedDict(有序字典)存放不同类别的模块,如:子module、parameters、buffers等。
- Module重写了魔法方法__setattr__(),类实例的属性赋值后先判断属性类型,将 子module、parameter、buffer等存入__dict__(属性信息)对应的OrderedDict中。OrderedDict类似树形结构,方便维护和管理。